A Minimal implementation of the Imagen text-to-image model.
See Build Your Own Imagen Text-to-Image Model for a tutorial on how to build MinImagen.
See How Imagen Actually Works for a detailed explanation of Imagen's operating principles.
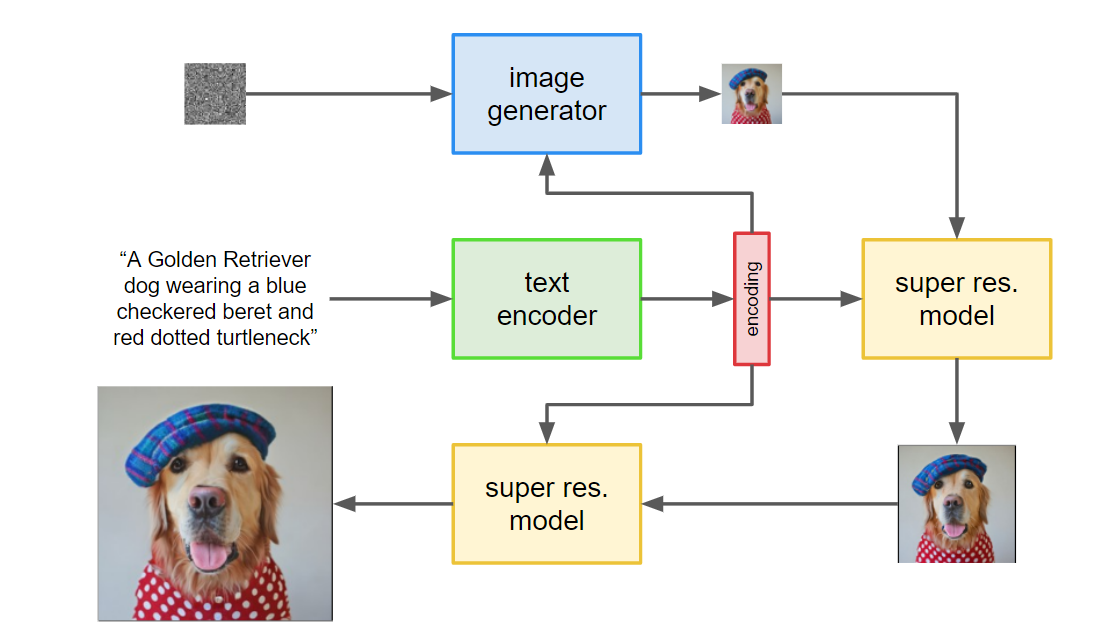
Given a caption of an image, the text-to-image model Imagen will generate an image that reflects the scene described by the caption. The model is a cascading diffusion model, using a T5 text encoder to generate a caption encoding which conditions a base image generator and then a sequence of super-resolution models through which the output of the base image generator is passed.
In particular, two notable contributions are the developments of:
- Noise Conditioning Augmentation, which noises low-resolution conditioning images in the super-resolution models, and
- Dynamic Thresholding which helps prevent image saturation at high classifier-free guidance weights.
N.B. - This project is intended only for educational purposes to demonstrate how Diffusion Models are implemented and incorporated into text-to-image models. Many components of the network that are not essential for these educational purposes have been stripped off for simplicity. For a full-fledged implementation, check out Phil Wang's repo (see attribution note below)
- Attribution Note
- Installation
- Documentation
- Usage - Command Line
main.py- training and image generation in sequencetrain.py- training a MinImagen instanceinference.py- generated images using a MinImagen instance
- Usage - Package
- Modifying the Source Code
- Additional Resources
- Socials
This implementation is largely based on Phil Wang's Imagen implementation.
To install MinImagen, run the following command in the terminal:
$ pip install minimagenNote that MinImagen requires Python3.9 or higher
See the MinImagen Documentation to learn more about the package.
If you have cloned this repo (as opposed to just installing the minimagen package), you can use the provided scripts to get started with MinImagen. This repo can be cloned by running the following command in the terminal:
$ git clone https://github.com/AssemblyAI-Examples/MinImagen.gitFor the most basic usage, simply enter the MinImagen directory and run the following in the terminal:
$ python main.pyThis will create a small MinImagen instance and train it on a tiny amount of data, and then use this MinImagen instance to generate an image.
After running the script, you will see a directory called training_<TIMESTAMP>.
- This directory is called a Training Directory and is generated when training a MinImagen instance.
- It contains information about the configuration (
parameterssubdirectory), and contains the model checkpoints (state_dictsandtmpdirectories). - It also contains a
training_progress.txtfile that records training progress.
You will also see a directory called generated_images_<TIMESTEP>.
- This directory contains a folder of images generated by the model (
generated_images). - It also contains
captions.txtfiles, which documents the captions that were input to get the images (where the line index of a given caption corresponds to the image number in thegenerated_iamgesfolder). - Finally, this directory also contains
imagen_training_directory.txt, which specifies the name of the Training Directory used to load the MinImagen instance / generate images.
main.py simply runs train.py and inference.py in series, the former to train the model and the latter to generate the image.
To train a model, simply run train.py and specify relevant command line arguments. The possible arguments are:
--PARAMETERSor-p, which specifies a directory that specifies the MinImagen configuration to use. It should be structured like aparameterssubdirectory within a Training Directory (example inparameters).--NUM_WORKERS"or-n, which specifies the number of workers to use for the DataLoaders.--BATCH_SIZEor-b, which specifies the batch size to use during training.--MAX_NUM_WORDSor-mw, which specifies the maximum number of words allowed in a caption.--IMG_SIDE_LENor-s, specifies the final side length of the square images the MinImagen will output.--EPOCHSor-e, which specifies the number of training epochs.--T5_NAME-t5, which specifies the name of T5 encoder to use.--TRAIN_VALID_FRACor-f, which specifies the fraction of dataset to use for training (vs. validation).--TIMESTEPSor-t, which specifies the number of timesteps in Diffusion Process.--OPTIM_LRor-lr, which specifies the learning rate for Adam optimizer.--ACCUM_ITERor-ai, which specifies the number of batches to accumulate for gradient accumulation.--CHCKPT_NUMor-cn, which specifies the interval of batches to create a temporary model checkpoint at during training.--VALID_NUMor-vn, which specifies the number of validation images to use. If None, uses full amount from train/valid split. The reason for including this is that, even with an e.g. 0.99--TRAIN_VALID_FRAC, a prohibitively large number of images could still be left for validation for very large datasets.--RESTART_DIRECTORYor-rd, training directory to load MinImagen instance from if resuming training. A new Training Directory will be created for the training, leaving the previous Training Directory from which the checkpoint is loaded unperturbed.--TESTINGor-test, which is used to run the script with a small MinImagen instance and small dataset for testing.
For example, to run a small training using the provided example parameters folder, run the following in the terminal:
python train.py --PARAMETERS ./parameters --BATCH_SIZE 2 --TIMESTEPS 25 --TESTINGAfter execution, you will see a new training_<TIMESTAMP> Training Directory that contains the files as listed above from the training.
To generate images using a model from a Training Directory, we can use inference.py. Simply run inference.py and specify relevant command line arguments. The possible arguments are:
--TRAINING_DIRECTORY"or-d, which specifies the training directory from which to load the MinImagen instance for inference.--CAPTIONSor-c, which specifies either (a) a single caption to generate an image for, or (b) a filepath to a.txtfile that contains a list of captions to generate images for, where each caption is on a new line.
For example, to generate images for the example captions provided in captions.txt using the model generated from the above training line, simply run
python inference.py -CAPTIONS captions.txt --TRAINING_DIRECTORY training_<TIMESTAMP> where TIMESTAMP is replaced with the appropriate value from your training.
A minimal training script using the minimagen package is shown below. See train.py for a more built-up version of the below code.
import os
from datetime import datetime
import torch.utils.data
from torch import optim
from minimagen.Imagen import Imagen
from minimagen.Unet import Unet, Base, Super, BaseTest, SuperTest
from minimagen.generate import load_minimagen, load_params
from minimagen.t5 import get_encoded_dim
from minimagen.training import get_minimagen_parser, ConceptualCaptions, get_minimagen_dl_opts, \
create_directory, get_model_size, save_training_info, get_default_args, MinimagenTrain, \
load_testing_parameters
# Get device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Command line argument parser
parser = get_minimagen_parser()
args = parser.parse_args()
# Create training directory
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
dir_path = f"./training_{timestamp}"
training_dir = create_directory(dir_path)
# Replace some cmd line args to lower computational load.
args = load_testing_parameters(args)
# Load subset of Conceptual Captions dataset.
train_dataset, valid_dataset = ConceptualCaptions(args, smalldata=True)
# Create dataloaders
dl_opts = {**get_minimagen_dl_opts(device), 'batch_size': args.BATCH_SIZE, 'num_workers': args.NUM_WORKERS}
train_dataloader = torch.utils.data.DataLoader(train_dataset, **dl_opts)
valid_dataloader = torch.utils.data.DataLoader(valid_dataset, **dl_opts)
# Use small U-Nets to lower computational load.
unets_params = [get_default_args(BaseTest), get_default_args(SuperTest)]
unets = [Unet(**unet_params).to(device) for unet_params in unets_params]
# Specify MinImagen parameters
imagen_params = dict(
image_sizes=(int(args.IMG_SIDE_LEN / 2), args.IMG_SIDE_LEN),
timesteps=args.TIMESTEPS,
cond_drop_prob=0.15,
text_encoder_name=args.T5_NAME
)
# Create MinImagen from UNets with specified imagen parameters
imagen = Imagen(unets=unets, **imagen_params).to(device)
# Fill in unspecified arguments with defaults to record complete config (parameters) file
unets_params = [{**get_default_args(Unet), **i} for i in unets_params]
imagen_params = {**get_default_args(Imagen), **imagen_params}
# Get the size of the Imagen model in megabytes
model_size_MB = get_model_size(imagen)
# Save all training info (config files, model size, etc.)
save_training_info(args, timestamp, unets_params, imagen_params, model_size_MB, training_dir)
# Create optimizer
optimizer = optim.Adam(imagen.parameters(), lr=args.OPTIM_LR)
# Train the MinImagen instance
MinimagenTrain(timestamp, args, unets, imagen, train_dataloader, valid_dataloader, training_dir, optimizer, timeout=30)A minimal inference script using the minimagen package is shown below. See inference.py for a more built-up version of the below code.
from argparse import ArgumentParser
from minimagen.generate import load_minimagen, sample_and_save
# Command line argument parser
parser = ArgumentParser()
parser.add_argument("-d", "--TRAINING_DIRECTORY", dest="TRAINING_DIRECTORY", help="Training directory to use for inference", type=str)
args = parser.parse_args()
# Specify the caption(s) to generate images for
captions = ['a happy dog']
# Use `sample_and_save` to generate and save the iamges
sample_and_save(captions, training_directory=args.TRAINING_DIRECTORY)
# Alternatively, rather than specifying a Training Directory, you can input just a MinImagen instance to use for image generation.
# In this case, information about the MinImagen instance used to generate the images will not be saved.
minimagen = load_minimagen(args.TRAINING_DIRECTORY)
sample_and_save(captions, minimagen=minimagen) To see more of what MinImagen has to offer, or to get additional details on the scripts above, check out the MinImagen Documentation
If you want to make modifications to the source code (rather than use the minimagen package), first clone this repository and navigate into it:
$ git clone https://github.com/AssemblyAI-Examples/MinImagen.git
$ cd MinImagenAfter that, create a virtual environment:
$ pip install virtualenv
$ virtualenv venvThen activate the virtual environment and install all dependencies:
$ .\venv\Scripts\activate.bat # Windows
$ source venv/bin/activate # MacOS/Linux
$ pip install -r requirements.txtNow you can modify the source code and the changes will be reflected when running any of the included scripts (as long as the virtual environment created above is active).
- For a step-by-step guide on how to build the version of Imagen in this repository, see Build Your Own Imagen Text-to-Image Model.
- For an deep-dive into how Imagen works, see How Imagen Actually Works.
- For a deep-dive into Diffusion Models, see our Introduction to Diffusion Models for Machine Learning guide.
- For additional learning resources on Machine Learning and Deep Learning, check out our Blog and YouTube channel.
- Read the original Imagen paper here.
- Follow us on Twitter for more Deep Learning content.
- Follow our newsletter to stay up to date on our recent content.