本项目记录一些学习爬虫逆向的案例,仅供学习参考,请勿用于非法用途。
目前已完成:TLS、震坤行、网易易盾、微信小程序反编译逆向(百达星系)、极验滑块验证码、同花顺、rpc实现解密、工业和信息化部政务服务平台(加速乐)、巨量算数、Boss直聘、企查查、中国五矿、qq音乐、产业政策大数据平台、企知道、雪球网(acw_sc__v2)、1688、七麦数据、whggzy、企名科技、全国建筑市场监管公告平台、艺恩数据、欧科云链(oklink)、度衍(uyan)、凤凰云智影院管理平台、DrissionPage过瑞数6
点击以上链接可跳转到对应文档位置,代码路径格式为**"月份/网站名称/"**。
npm install
pip install -r requirements.txt
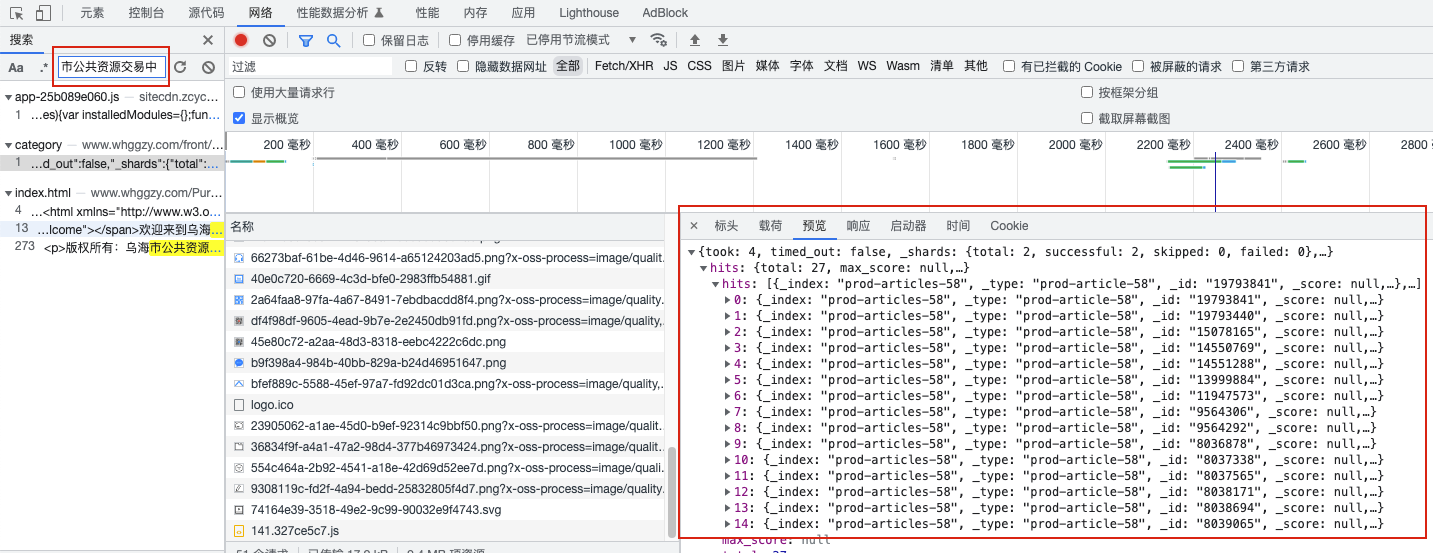
接口为 “http://www.whggzy.com/front/search/category”
将接口的headers和data传入,并进行测试
headers = {
# 这两个参数是必须的
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Referer": "http://www.whggzy.com/PurchaseAdvisory/index.html",
}
# 通过查看参数发现data传的是字符串,所以这个通过字符串的方式发送data,而不是字典
data = {
"categoryCode": "MostImportant",
"pageNo": 1,
"pageSize": 15
}访问后报错
在源代码->xhr/提取断点中加入断点,观察到headers的参数,且data参数为字符串
import requests
url = "http://www.whggzy.com/front/search/category"
headers = {
# 这两个参数是必须的
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Referer": "http://www.whggzy.com/PurchaseAdvisory/index.html",
# 通过xhr断点找到接口的headers包含一下几个
'Accept': "*/*",
'Content-Type': "application/json",
'X-Requested-With': "XMLHttpRequest",
}
# 通过查看参数发现data传的是字符串,所以这个通过字符串的方式发送data,而不是字典
data = '''{
"categoryCode": "MostImportant",
"pageNo": 1,
"pageSize": 15
}'''
print(requests.post(url, headers=headers, data=data).text)url: https://www.qimingpian.com/finosda/project/pinvestment
搜索不到数据,判断为通过ajax数据加密
找到接口:
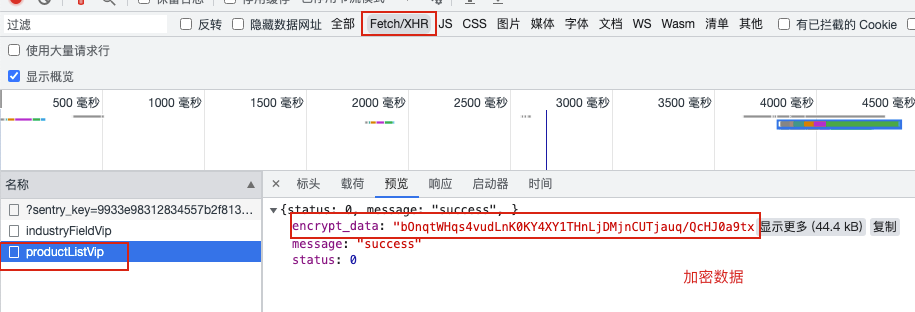
找到js文件
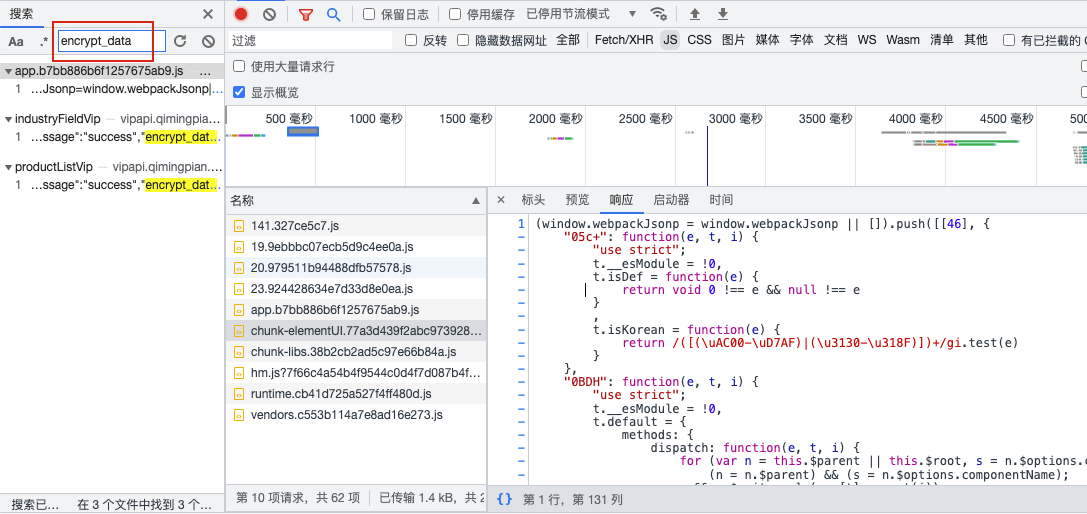
找到加密数据的方法:
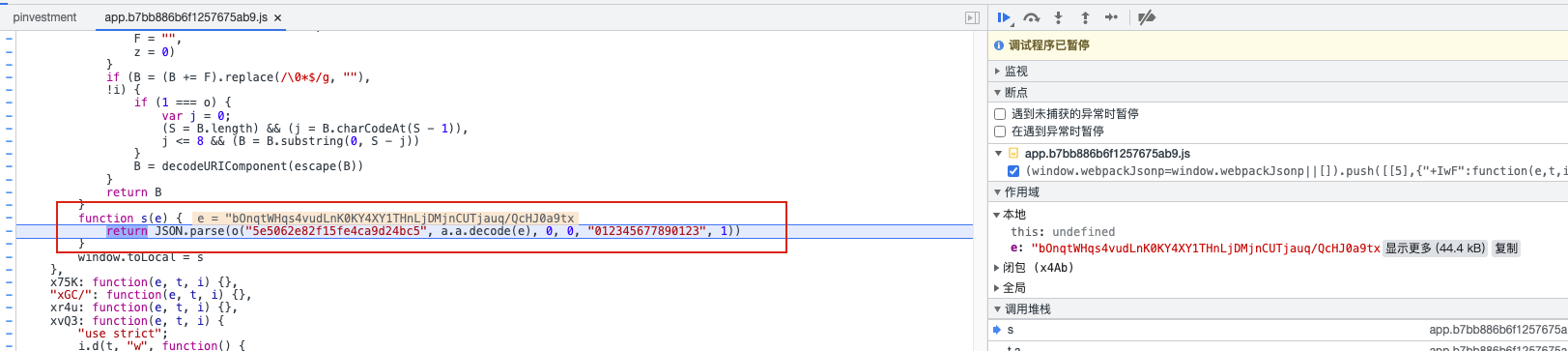
// 还需要找到o方法和decode方法,整合成js文件
function s(e) {
return JSON.parse(o("5e5062e82f15fe4ca9d24bc5", a.a.decode(e), 0, 0, "012345677890123", 1))
}import json
import execjs
import requests
url = 'https://vipapi.qimingpian.cn/DataList/productListVip'
headers = {}
data = {}
# 打开js文件
with open("./demo2_qiming.js", "r") as f:
jscode = f.read()
# 调用api接口拿到加密数据
resp = requests.get(url, headers=headers, data=data).json()
# 调用js文件
ctx = execjs.compile(jscode).call('s', resp["encrypt_data"])
print(ctx)
print(f"type:{type(ctx)}")url: aHR0cHM6Ly9qenNjLm1vaHVyZC5nb3YuY24vZGF0YS9jb21wYW55
接口:https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list?pg=0&pgsz=15&total=0
数据经过加密,data: 95780ba09437300...
通过接口名称找到js文件,在js文件里搜索JSON.parse,打断点进行调试
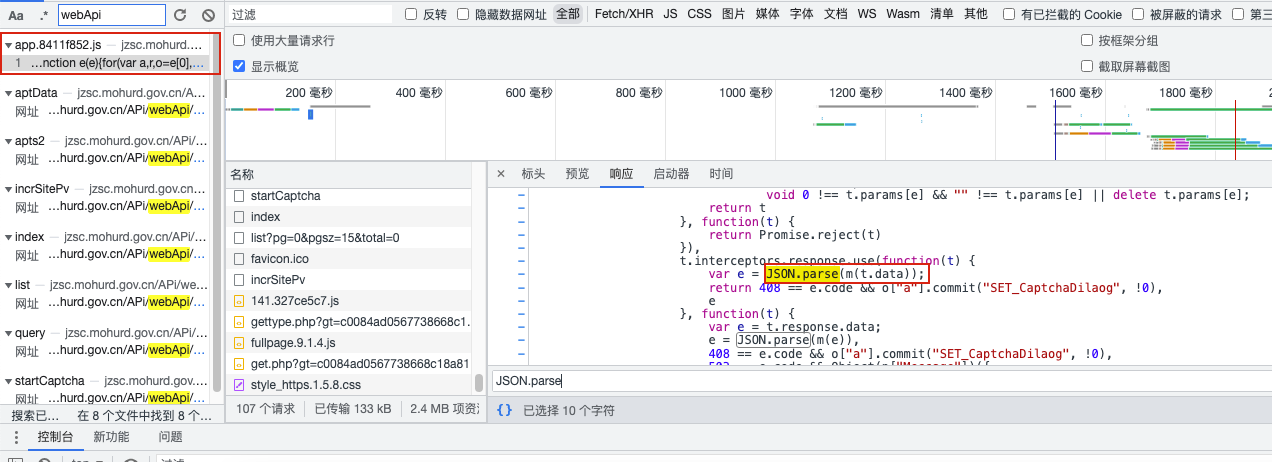
常见js算法:crypto-js、jsdom、hash、md5、逆向算法
判断使用的加密是CryptoJS,使用npm安装库后导入,替换原始js里使用的方法
const CryptoJS = require('crypto-js')
// 常见js算法:jsdom hash md5 逆向算法
function m(t) {
// d.a是CryptoJS
var f = CryptoJS.enc.Utf8.parse("jo8j9wGw%6HbxfFn")
var h = CryptoJS.enc.Utf8.parse("0123456789ABCDEF")
var e = CryptoJS.enc.Hex.parse(t),
n = CryptoJS.enc.Base64.stringify(e),
a = CryptoJS.AES.decrypt(n, f, {
iv: h,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
}),
r = a.toString(CryptoJS.enc.Utf8);
return r.toString()
}url: https://www.endata.com.cn/BoxOffice/BO/Year/index.html
url = "https://www.endata.com.cn/API/GetData.ashx"
headers = {} # 略
data = {} # 略
ori_data = requests.post(url, headers=headers, data=data).text
"""
out:
AFB3D177A5D1D916CFEFBE70FEFC0C59C0463AE137DE1A099C4B169B8AB9DBC33EE55B1...(加密数据)
"""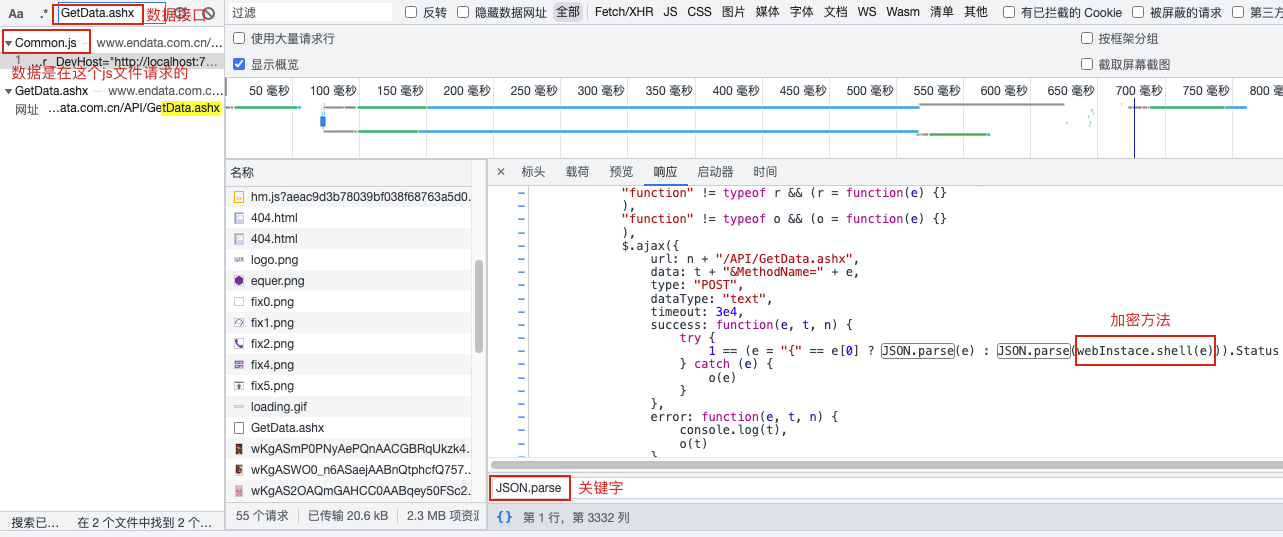
通过断点找到加密的方法,方法经过了js混淆,直接复制方法,执行这个方法,根据提示补齐所有缺失的属性。
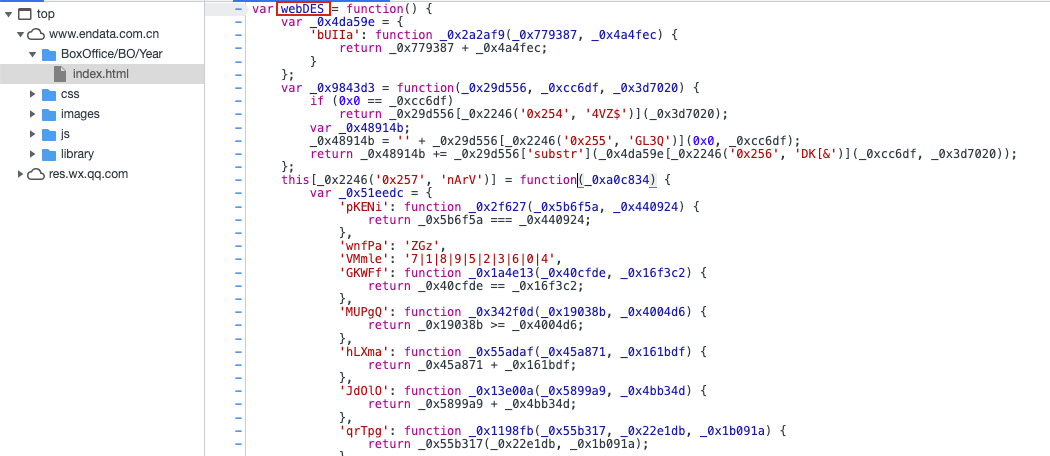
js代码中存在一个navigator属性,为环境属性,需要手动写入
global.navigator = {'userAgent': "node.js"}"""js混淆"""
import execjs
import requests
url = "https://www.endata.com.cn/API/GetData.ashx"
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
data = {
"year": 2023,
"MethodName": "BoxOffice_GetYearInfoData"
}
ori_data = requests.post(url, headers=headers, data=data).text
with open("./endata.js", 'r') as f:
js_code = f.read()
result = execjs.compile(js_code).call("webInstace.shell", ori_data)
print(result)
# (webInstace.shell(data));有加密参数,找这个参数的js文件
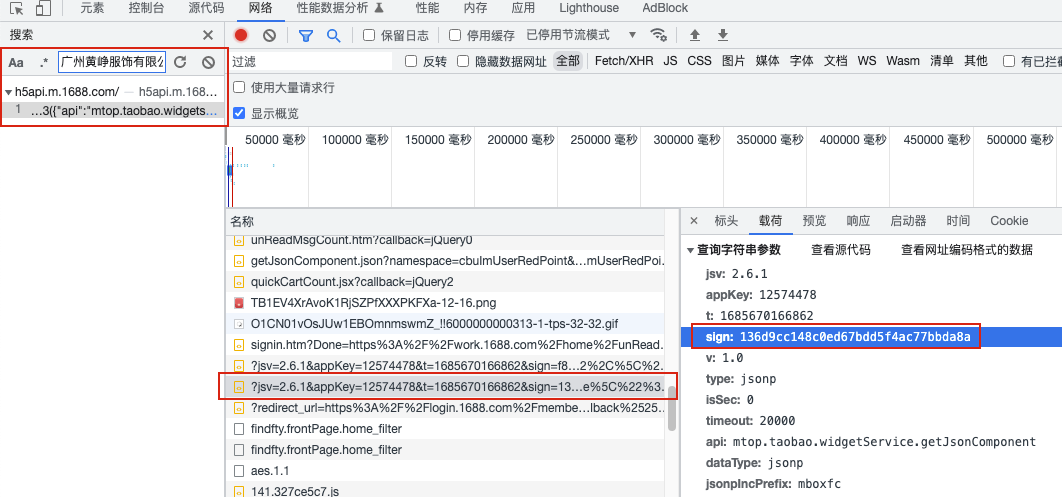
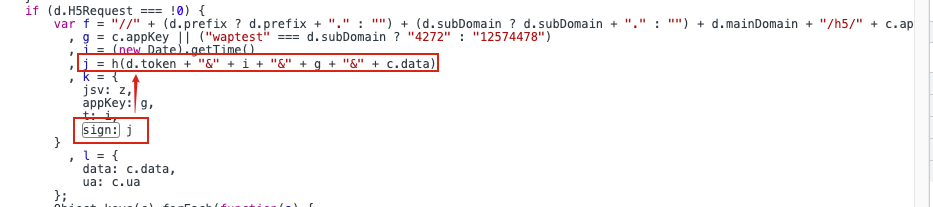
**sign参数的组成:**token & 时间戳 & g & 请求参数,数据均没有变化
再经过h函数
# 请求的参数
data = '{"cid":"FactoryRankServiceWidget:FactoryRankServiceWidget","methodName":"execute","params":"{\\"extParam\\":{\\"methodName\\":\\"readRelatedRankEntries\\",\\"cateId\\":\\"10166\\",\\"size\\":\\"15\\",\\"pageNo\\":\\"1\\",\\"pageSize\\":\\"20\\",}}"}'
# sign = token & 时间戳 & g & 请求参数
token = "2a3e896698e27affa623d6ecd90aca5e"
i = int(time.time() * 1000)
g = "12574478"
# 拼接出字符串
j = f"{token}&{i}&{g}&{str(data)}"
# 使用js文件生成sign
with open("./h.js", "r", encoding="utf-8") as f:
js_code = f.read()
sign = execjs.compile(js_code).call("h", j)# 设置header和params
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Referer": "https://sale.1688.com/",
# 这里需要传入cookie,不然会提示token为空
"Cookie":"...",
}
# 这里的data、时间戳要和sign里的data一样
params = {"jsv": "2.6.1", "appKey": "12574478", "t": str(i), "sign": sign, "v": "1.0", "type": "jsonp", "isSec": 0,
"timeout": 20000, "api": "mtop.taobao.widgetService.getJsonComponent", "dataType": "jsonp",
"jsonpIncPrefix": "mboxfc", "callback": "mtopjsonpmboxfc3", "data": data}
url = "https://h5api.m.1688.com/h5/mtop.taobao.widgetservice.getjsoncomponent/1.0/"
print(requests.get(url, headers=headers, params=params).text)url: https://webapi.cninfo.com.cn/#/marketDataDate
为base64加密
通过标头名或者路径搜索,找到js文件;该方法使用了js混淆。
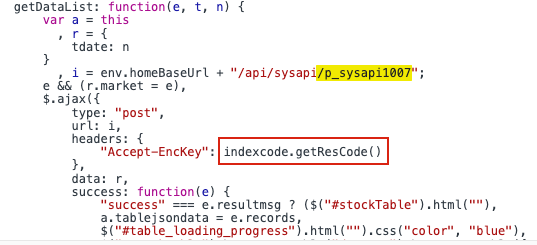
url: https://www.qimai.cn/rank
通过英文搜索到接口(中文有编码)
接口的参数名搜索js,参数名:analysis,找到对应的js文件
在js文件中添加接口url的路径:/rank/indexPlus/brand_id/1
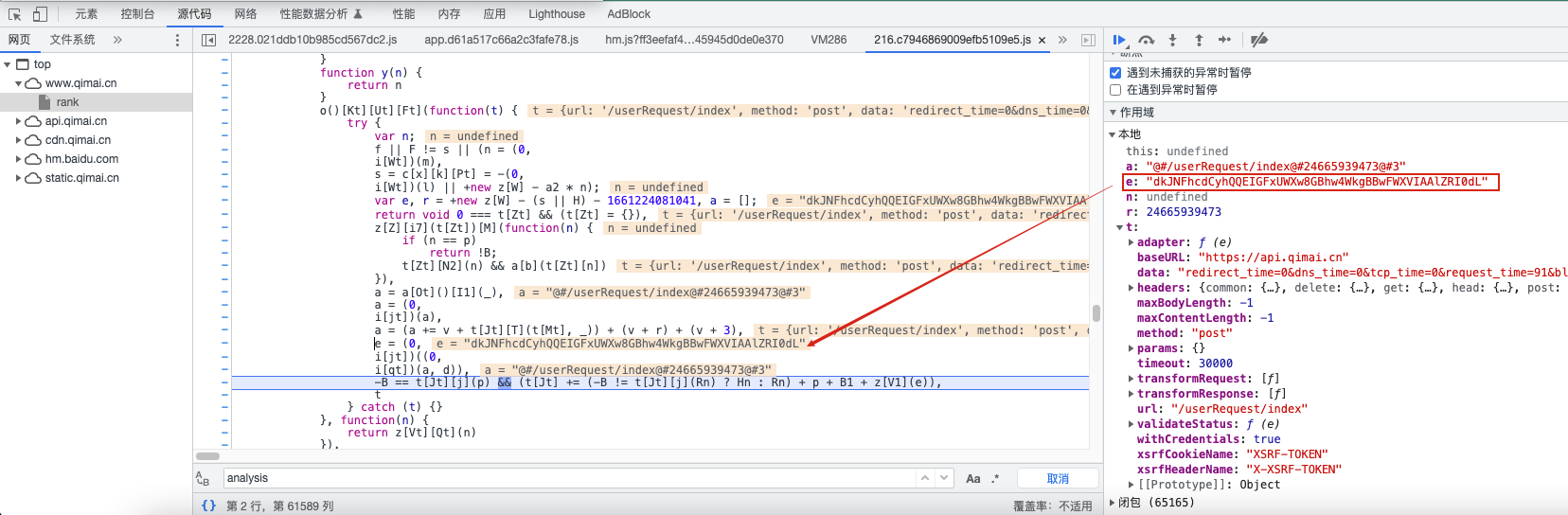
js使用了js混淆,需要根据调试根据判断使用了什么方法,具体请看注解
// 注释的代码为原始代码
function v(t) {
// 找到这里使用的方法
// t = z[V1](t)[T](/%([0-9A-F]{2})/g, function(n, t) {
t = encodeURIComponent(t).replace(/%([0-9A-F]{2})/g, function (n, t) {
// 这里的Y1是个固定字符
// return o(Y1 + t)
return o("0x" + t)
});
try {
// boat方法
// return z[Q1](t)
return btoa(t)
} catch (n) {
// 找到这个方法
// return z[W1][K1](t)[U1](Z1)
return Buffer.from(t).toString("base64")
}
}
function o(n) {
let f2 = '66';
let s2 = '72';
let d2 = '6f';
let m2 = '6d';
let l2 = '43';
let v2 = '68';
let p2 = '61';
let h2 = '64';
let y2 = '65';
t = "",
[f2, s2, d2, m2, l2, v2, p2, s2, l2, d2, h2, y2].forEach(function (n) {
t += unescape("%u00" + n)
});
var t, e = t;
// 调试时这里的e一直是undefined,通过打断点再调试确定为这个方法
// return z[b2][e](n)
return String.fromCharCode(n)
}
function h(n, t) {
t = t || u();
// 替换方法和值
// for (var e = (n = n[$1](_))[R], r = t[R], a = q1, i = H; i < e; i++)
for (var e = (n = n.split("")).length, r = t.length, a = "charCodeAt", i = 0; i < e; i++)
n[i] = o(n[i][a](0) ^ t[(i + 10) % r][a](0));
// return n[I1](_)
return n.join("")
}
function url(pass) {
var s = 1359
var H = 0
var e, r = +new Date() - (s || H) - 1661224081041, a = [];
var v1 = "@#"
// 固定值
var d = "xyz517cda96abcd"
// a = a[Ot]()[I1](_),
a = a.sort().join("")
// 这里调用了一个去掉域名的方法,但我们传的是后面的接口路径,所以直接使用
// a = (a += v + t[Jt][T](t[Mt], _)) + (v + r) + (v + 3),
a = (a += v1 + pass) + (v1 + r) + (v1 + 3)
// 在调试工具里找到这两个方法,复制到上面
// e = (0,
// i[jt])((0,
// i[qt])(a, d))
e = (0,
v)((0,
h)(a, d))
return e
}
const pass = "/rank/indexPlus/brand_id/1"
console.log(url(pass));
找到方法,再进行搜索
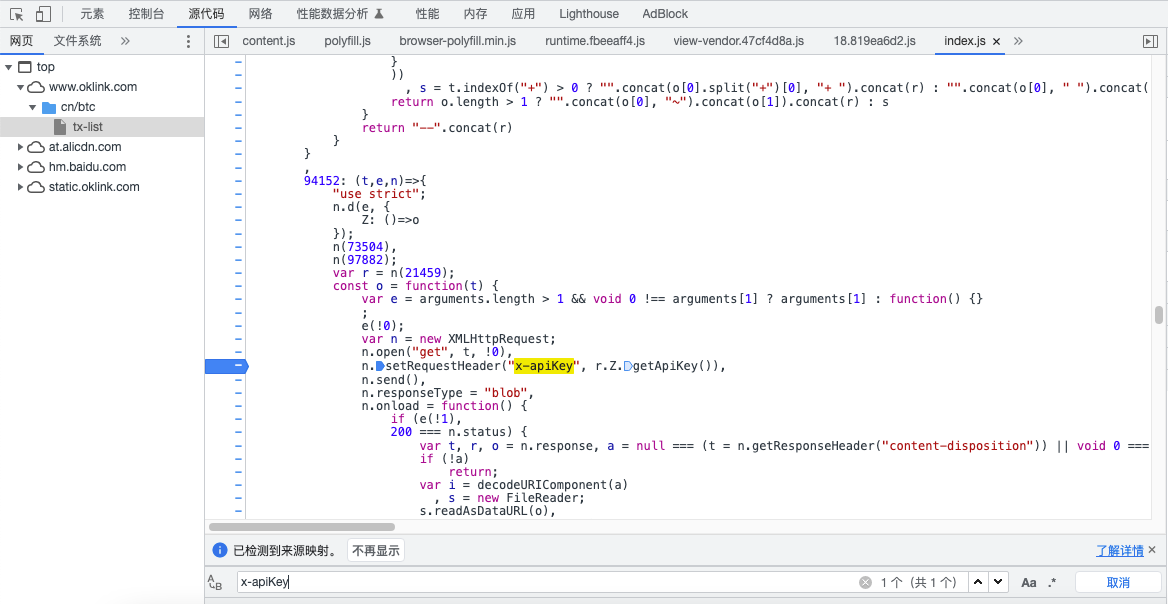
找到webpack打包的代码,改写后补齐所有方法
{
key: "encryptApiKey",
value: function() {
var t = this.API_KEY
, e = t.split("")
, n = e.splice(0, 8);
return t = e.concat(n).join("")
}
}, {
key: "encryptTime",
value: function(t) {
var e = (1 * t + a).toString().split("")
, n = parseInt(10 * Math.random(), 10)
, r = parseInt(10 * Math.random(), 10)
, o = parseInt(10 * Math.random(), 10);
return e.concat([n, r, o]).join("")
}
}, {
key: "comb",
value: function(t, e) {
var n = "".concat(t, "|").concat(e);
return window.btoa(n)
}
},
{
key: "getApiKey",
value: function() {
var t = (new Date).getTime()
, e = this.encryptApiKey();
return t = this.encryptTime(t),
this.comb(e, t)
}
}function encryptApiKey() {
let API_KEY = "a2c903cc-b31e-4547-9299-b6d07b7631ab"
var t = API_KEY
, e = t.split("")
, n = e.splice(0, 8);
return t = e.concat(n).join("")
}
function encryptTime(t) {
let a = 1111111111111
var e = (1 * t + a).toString().split("")
, n = parseInt(10 * Math.random(), 10)
, r = parseInt(10 * Math.random(), 10)
, o = parseInt(10 * Math.random(), 10);
return e.concat([n, r, o]).join("")
}
function comb(t, e) {
var n = "".concat(t, "|").concat(e);
return Buffer.from(n).toString("base64")
}
function getApiKey() {
var t = (new Date).getTime()
, e = encryptApiKey();
return t = encryptTime(t),
comb(e, t)
}
getApiKey()def get_api_key():
"""获取加密字符串"""
times = int(time.time() * 1000)
# 固定的加密值
api_key = "a2c903cc-b31e-4547-9299-b6d07b7631ab"
# encryptApiKey()
key1 = api_key[0:8]
key2 = api_key[8:]
# 交换位置
new_key = key2 + key1
# encryptTime()
a = 1111111111111
new_time = str(1 * times + a)
random1 = str(random.randint(0, 9))
random2 = str(random.randint(0, 9))
random3 = str(random.randint(0, 9))
# 拼接
cur_time = new_time + random1 + random2 + random3
# 合并前面生成的两个值,并用base64加密
this_key = new_key + "|" + cur_time
n_k = this_key.encode("utf-8")
x_apikey = base64.b64encode(n_k)
return x_apikeyurl:https://m.flight.qunar.com/h5/flight/
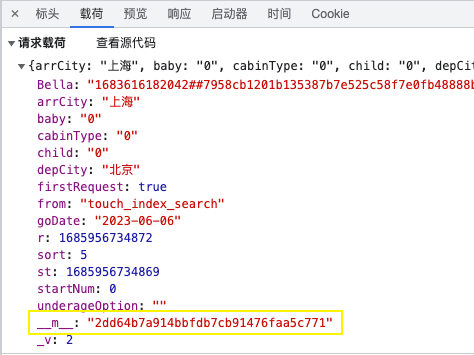
8.1.1、请求参数:__m__
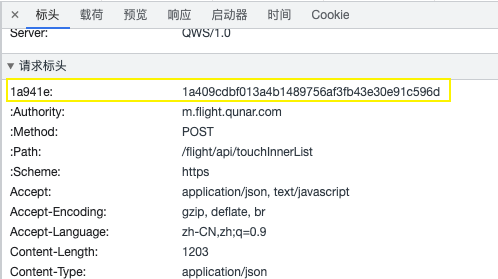
8.1.2、请求头参数:键值对加密
f()为md5加密
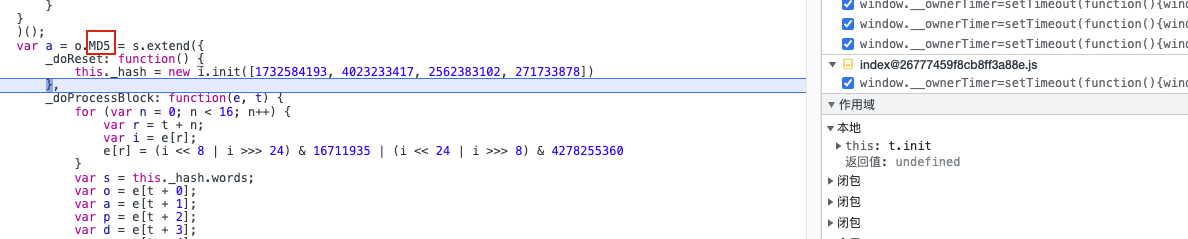
u()为SHA1加密

// 所有方法
// 加密算法
function encryptFunction() {
/**
* 调试进入这两个算法中,找到他们对应的算法,找关键字,例如算法名称
* f:md5
* n: SHA1
*/
return [function (e) {
// t % 2 == 0执行这个方法
// e = t时间戳 + n字符串
var t = (0,
u.default)(e).toString();
return (0,
f.default)(t).toString()
}
// t % 2 == 1执行这个方法
, function (e) {
var t = (0,
f.default)(e).toString();
return (0,
u.default)(t).toString()
}
]
}
function dencryptCode(t) {
return t.map(function (e) {
return String.fromCharCode(e - 2)
}).join("")
}
function getQtTime(t) {
/*
* 如果有t这里直接返回t
* 没t这里把时间戳分割后的char值-2转为字符串
*/
return t ? Number(t.split(",").map(function (e) {
return String.fromCharCode(e - 2)
}).join("")) : 0
}
// 获取字符串方法
function getTokenStr() {
var t = this.dencryptCode(this.tokenStr);
// 这里选择了页面中一个id为t的元素的值
var n = document.getElementById(t).innerHTML;
// 这里会返回元素的值或者方法的值
return n ? n : (0,
s.default)(this.dencryptCode(this.cookieToken))
}
// 获取参数的方法
function encrypt() {
// t是页面元素的值
var t = this.getTokenStr()
// 这里n是时间戳
, n = this.getQtTime((0,
s.default)(this.dencryptCode(this.qtTime)))
// r是对时间戳取模
, r = n % 2;
return encryptFunction()[r](t + n)
}
// 加密的方法
function encryptToken(t) {
return (0,
f.default)(t).toString()
}根据前面解析js代码,得到m参数的生成逻辑
import hashlib
import time
def md5_hash(text):
# 创建MD5哈希对象
md5_hasher = hashlib.md5()
# 更新哈希对象以包含待加密的文本
md5_hasher.update(text.encode('utf-8'))
# 返回MD5加密后的结果
return md5_hasher.hexdigest()
def sha1_hash(text):
# 创建SHA1哈希对象
sha1_hasher = hashlib.sha1()
# 更新哈希对象以包含待加密的文本
sha1_hasher.update(text.encode('utf-8'))
# 返回SHA1加密后的结果
return sha1_hasher.hexdigest()
def get_m():
# .data["__m__"] = u.default.encryptToken(u.default.encrypt());
# 获取需要被加密的参数,即u.default.encrypt()
# 页面存储的token"00008a002f1051a169b06202"
t = "00008a002f1051a169b06202"
# 时间戳
n = int(time.time() * 1000)
# n = 1686020493263
# 时间戳取余
r = n % 2
p1 = t + str(n)
# 根据r决定先用SHA1还是MD5
if r == 0:
# SHA1
p1 = sha1_hash(p1)
# MD5
p1 = md5_hash(p1)
else:
# MD5
p1 = md5_hash(p1)
# SHA1
p1 = sha1_hash(p1)
# 最后再用一次MD5加密
p1 = md5_hash(p1)
return p1
# fbc1646d57a2b22ceb5f5ef60018f67d
print(get_m())// 生成key的方法,传入的参数是时间戳
function getRandomKey(t) {
var n = "";
// 从时间戳的第四位开始截取
var r = ("" + t).substr(4);
// 时间戳每一位映射的acsii编码
r.split("").forEach(function (e) {
n += e.charCodeAt()
});
// md5加密
var i = (0,
f.default)(n).toString();
// -6:
return i.substr(-6)
}
// headers的主要生成方法
function getToken() {
// dict
var t = {};
// this.getQtTime((0,s.default)(this.dencryptCode(this.qtTime))) 依然是时间戳
// value是__m__参数一样的加密方法
t[this.getRandomKey(this.getQtTime((0,
s.default)(this.dencryptCode(this.qtTime))))] = this.encrypt();
return t
}def get_random_key(t):
""" 获取请求头参数的key """
# 截取4开始的字符串
t = str(t)[4:]
n = ""
# 转为ascii编码并拼接
for i in t:
n += str(ord(i))
# md5解密
key = md5_hash(n)
# 返回最后6位
return key[-6:]
def get_headers():
""" 获取请求头参数 键值对"""
t = int(time.time() * 1000)
# 获取key
key = get_random_key(t)
# 获取值
value = get_m(t)
return {key:value}url: https://gz.meituan.com/meishi/
_token为加密参数。
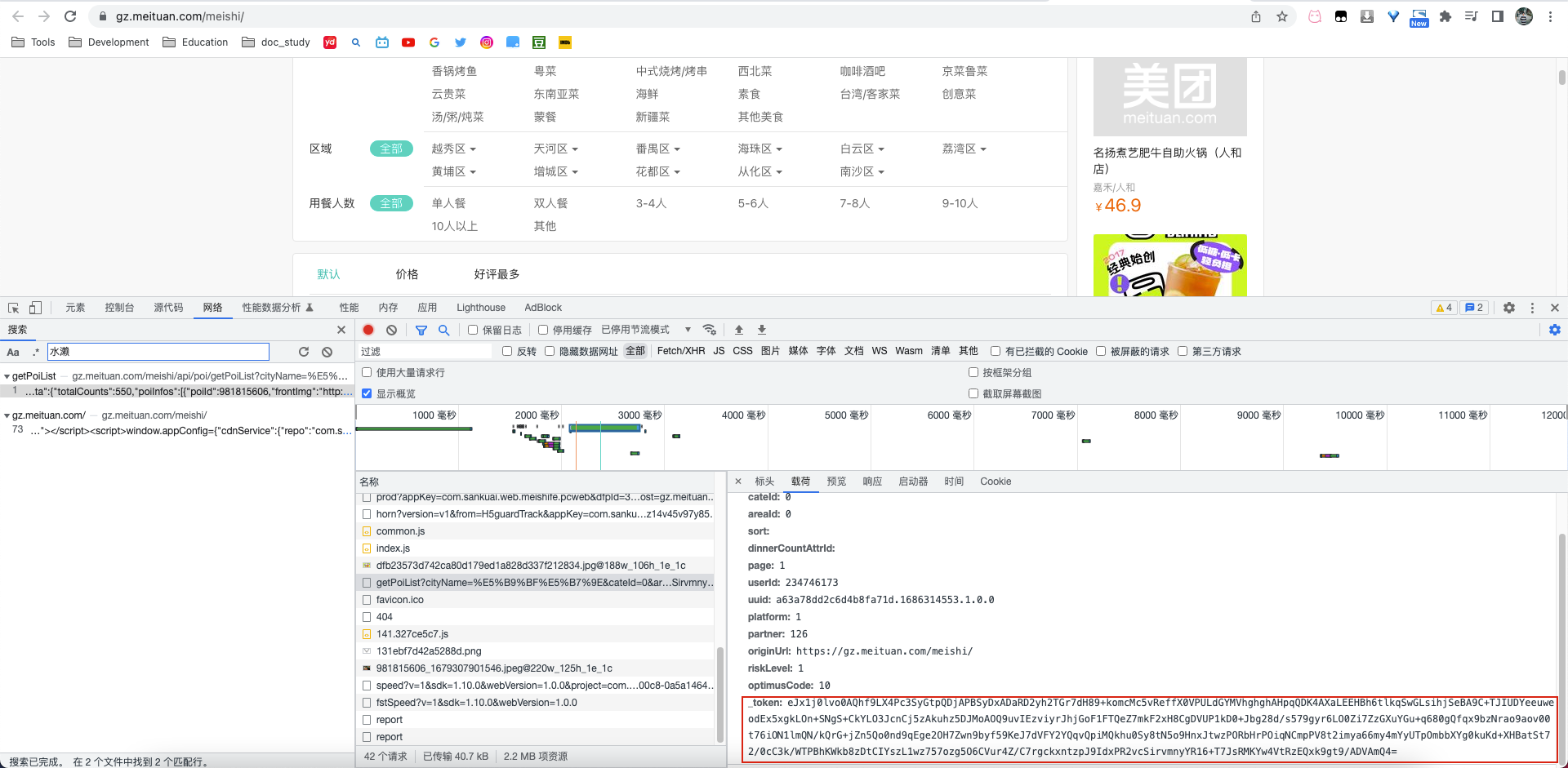
查找到token的生成位置,找到加密的方法
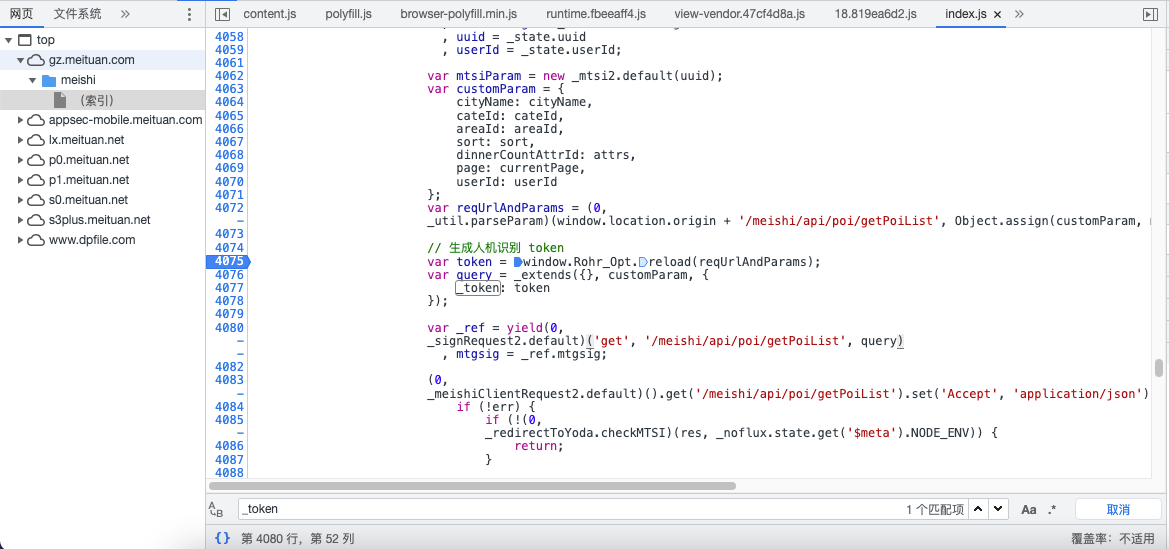
_token参数为iP类进行加密后得到的,但目前只能得出iP的sign参数,对iP进行加密后没办法得到最终的值,如果你知道怎么做欢迎提交issue给我。
iP.sign为参数排序后进行base64加密。
def decode_sign(token_str):
token_str = token_str.replace(" ", "")
# base编码
# token_str = f"\"{str(token_str)}\""
# token_str = str(token_str)
# token_str = f"'{token_str}'"
print(f"str:::{token_str}")
encode1 = str(token_str).encode()
# 参数 压缩成 特殊的编码
compress = zlib.compress(encode1)
b_encode = base64.b64encode(compress)
# 转变 str
e_sign = str(b_encode, encoding="utf-8")
return e_sign
# 查询参数
params = {
'cityName': '广州',
'cateId': 0,
'areaId': 0,
'sort': '',
'dinnerCountAttrId': '',
'page': 1,
'userId': '234746173',
'uuid': 'cab1469b7bd84ca09ea5.1686484028.1.0.0',
'platform': 1,
'partner': 126,
'originUrl': 'https://gz.meituan.com/meishi/',
'riskLevel': 1,
'optimusCode': 10
}
# 生成sign
params_str = "\""
# 对key进行排序
keys = [i for i in params.keys()]
keys.sort()
# 拼接
for key in keys:
params_str += f"{key}={params.get(key)}&"
params_str = params_str[:-1]
params_str += "\""
# 加密
sign = decode_sign(params_str)
# iP
iP = {
'rId': 100900,
'ver': "1.0.6",
# 'ts': 1686369166338,
# 'cts': 1686369167064,
"ts":1686485181487,
"cts":1686485200311,
'brVD': [
1920,
150
],
'brR': [
[
1920,
1080
],
[
1920,
981
],
30,
30
],
'bI': [
'https://gz.meituan.com/meishi/',
''
],
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign': sign
}
- 完成登陆请求中的json_key参数加密方法
- 解析返回的接口
url:https://patents.qizhidao.com/
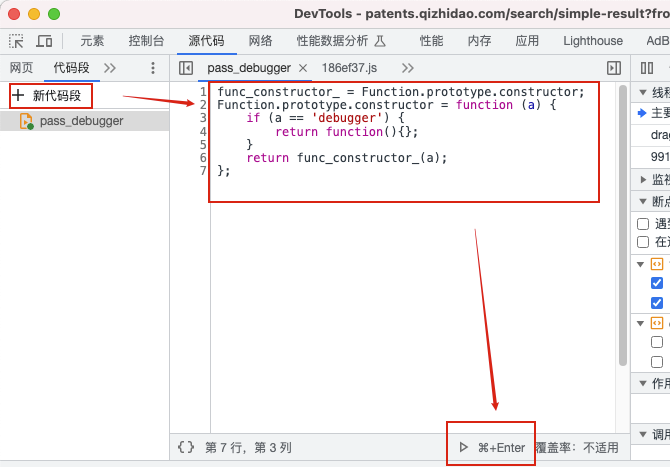
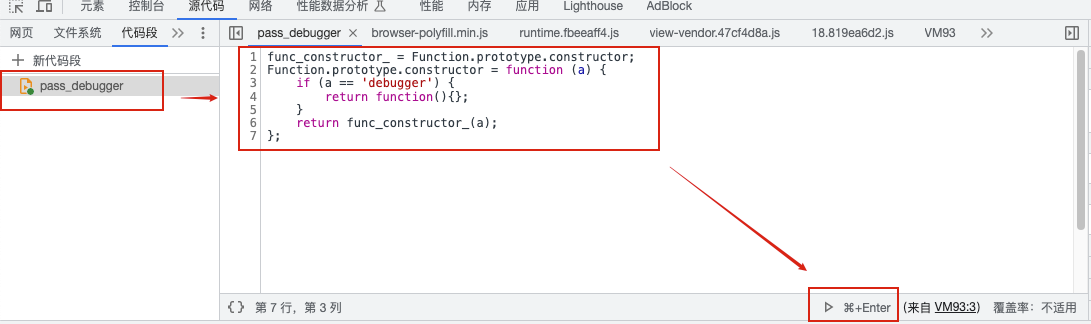
这个网站的反debug是带参数的,直接设置跳过会导致返回不了结果卡死。需要通过脚本返回空的值,注意:需要等页面加载后再执行。
func_constructor_ = Function.prototype.constructor;
Function.prototype.constructor = function (a) {
if (a == 'debugger') {
return function(){};
}
return func_constructor_(a);
};
复制接口的cURL到https://curlconverter.com/自动构造,代码有点长这里只放片段:
import requests
cookies = {
# ...
}
headers = {
'authority': 'app.qizhidao.com',
# ...
}
json_data = {
'text_ver': 'N',
# ...
'statement': '华为',
'filter': '',
'pageCount': 21073,
'checkResult': True,
}
response = requests.post(
'https://app.qizhidao.com/qzd-bff-patent/patent/simple-version/search',
cookies=cookies,
headers=headers,
json=json_data,
).json()
# 返回结果:
# {'code': 0, 'status': 0, 'success': True, 'msg': '成功', 'data1': 'ikEaI3qCl29i...', 'hasUse': 2}data1:这个是加密后的参数,需要解密。AES加密
hasUse:加密的key的位置。key是个字典,2代表第二个value
- 搜索”encrypt“
- 搜索接口

交集在186ef37.js
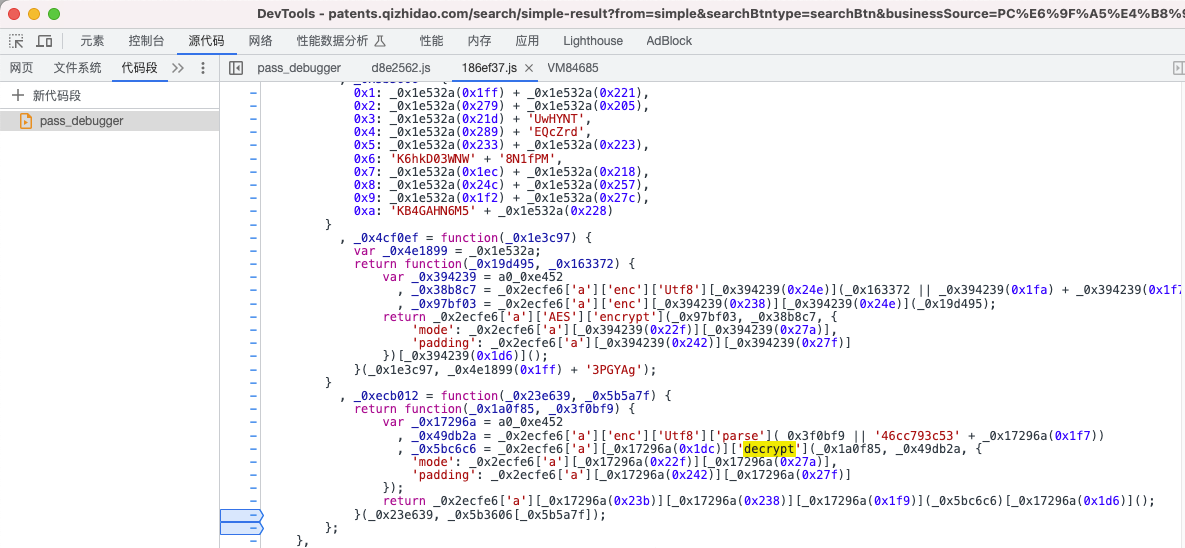
// 第一个参数是密文,第二个参数是加密的key
// AES加密
_0xecb012 = function(_0x23e639, _0x5b5a7f) {
return function(_0x1a0f85, _0x3f0bf9) {
var _0x17296a = a0_0xe452
, _0x49db2a = _0x2ecfe6['a']['enc']['Utf8']['parse'](_0x3f0bf9 || '46cc793c53' + _0x17296a(0x1f7))
, _0x5bc6c6 = _0x2ecfe6['a'][_0x17296a(0x1dc)]['decrypt'](_0x1a0f85, _0x49db2a, {
// 加密模式是ECB
'mode': _0x2ecfe6['a'][_0x17296a(0x22f)][_0x17296a(0x27a)],
'padding': _0x2ecfe6['a'][_0x17296a(0x242)][_0x17296a(0x27f)]
});
return _0x2ecfe6['a'][_0x17296a(0x23b)][_0x17296a(0x238)][_0x17296a(0x1f9)](_0x5bc6c6)[_0x17296a(0x1d6)]();
}(_0x23e639, _0x5b3606[_0x5b5a7f]);通过观察发现key不是固定的,存储在一个字典中。通过接口返回的值hasUse选择对应的key。
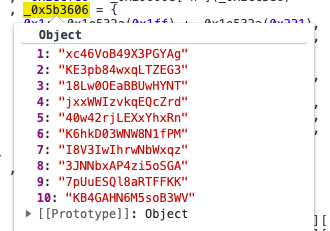
def AES_decrypt(data, hasUse:int):
key_list = [b"xc46VoB49X3PGYAg", b"KE3pb84wxqLTZEG3", b"18Lw0OEaBBUwHYNT", b"jxxWWIzvkqEQcZrd", b"40w42rjLEXxYhxRn",
b"K6hkD03WNW8N1fPM", b"I8V3IwIhrwNbWxqz", b"3JNNbxAP4zi5oSGA", b"7pUuESQl8aRTFFKK", b"KB4GAHN6M5soB3WV"]
# 解码
html = base64.b64decode(data)
# mode为ECB的AES加密
aes = AES.new(key_list[hasUse-1], AES.MODE_ECB)
# 解密
info = aes.decrypt(html)
# 填充
decrypt = unpad(info, AES.block_size).decode()
return decrypt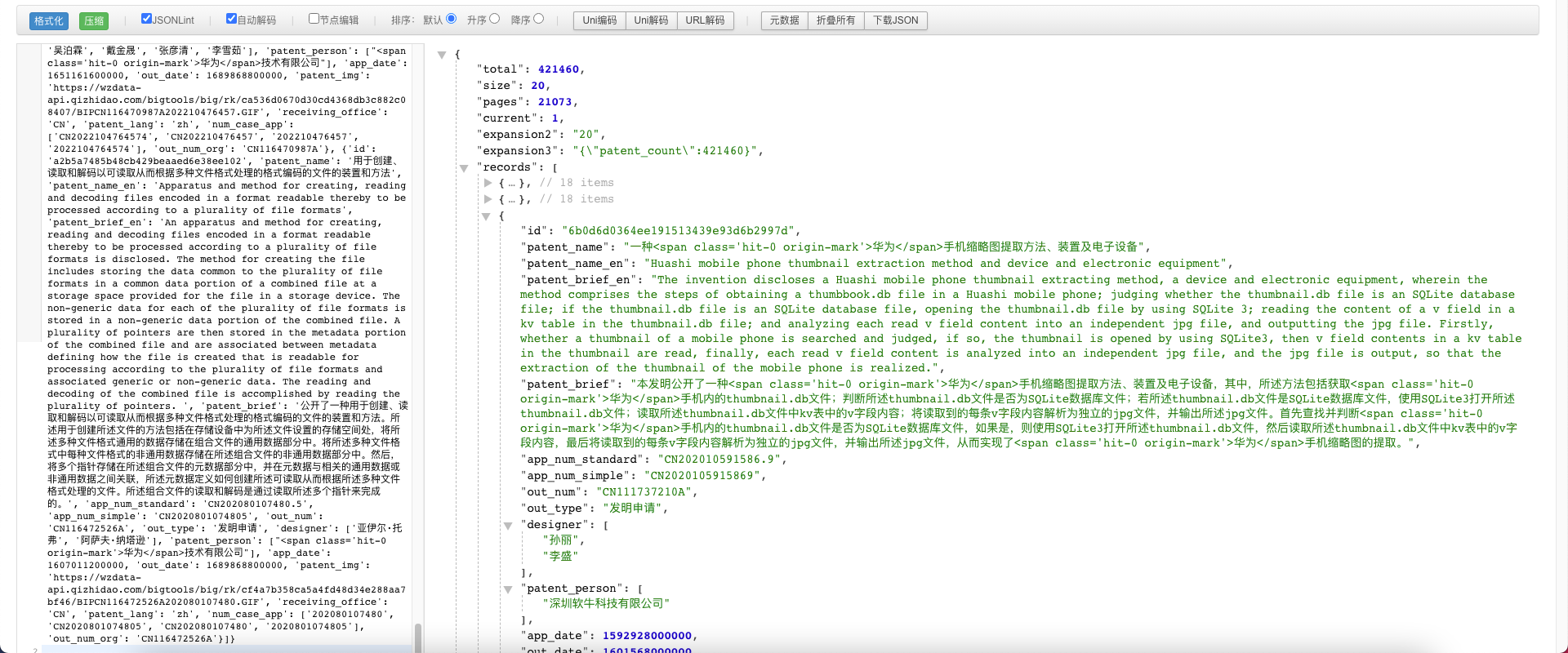
url:https://www.aqistudy.cn/historydata/monthdata.php?city=%E5%8C%97%E4%BA%AC
通过js生产请求参数
有两次请求,第一次获取js代码,第二次通过代码生成参数发送请求
尝试本地替换,发现没有进入方法。是在VM中执行的
进入debug,可以看到调用的位置,打断点调试,进入堆栈中的方法。
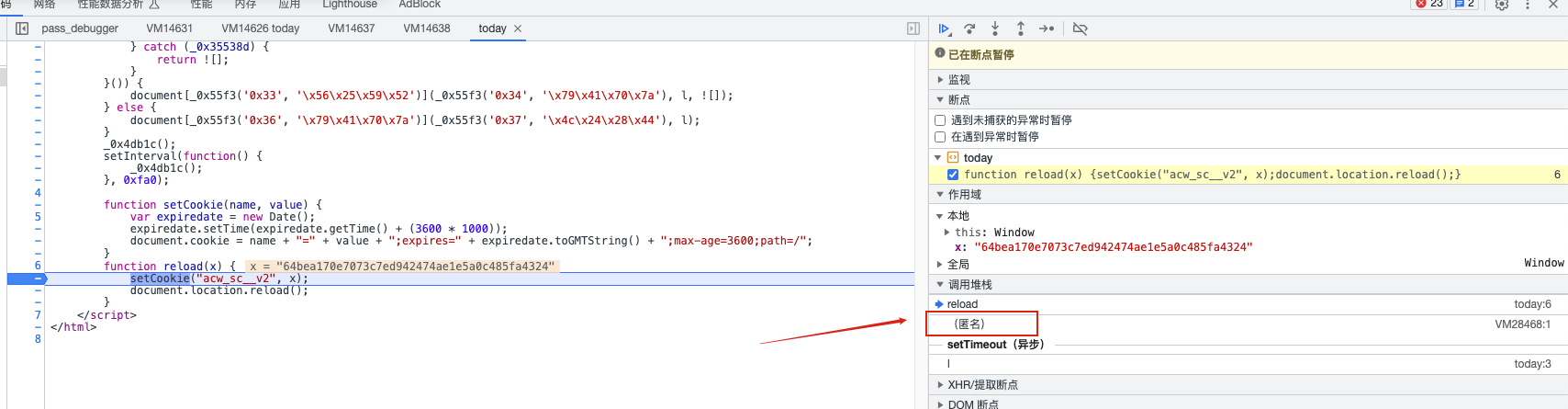
参数是arg2,查找这个参数。
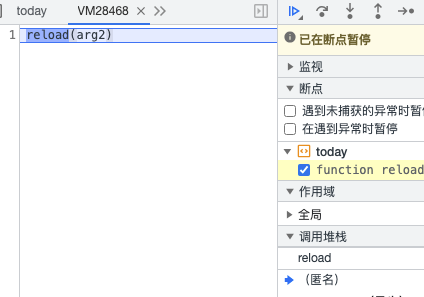
返回原代码,找到生成arg2的代码,把混淆的代码还原。通过对比,只有arg1值是不固定的,在第一次请求中就包含了这个值,通过正则提取,传入js代码里生成就可以得到cookie。
String['prototype']['hexXor'] = function (_0x4e08d8) {
var _0x5a5d3b = '';
for (var _0xe89588 = 0x0; _0xe89588 < this['length'] && _0xe89588 < _0x4e08d8['length']; _0xe89588 += 0x2) {
var _0x401af1 = parseInt(this['slice'](_0xe89588, _0xe89588 + 0x2), 0x10);
var _0x105f59 = parseInt(_0x4e08d8['slice'](_0xe89588, _0xe89588 + 0x2), 0x10);
var _0x189e2c = (_0x401af1 ^ _0x105f59)['toString'](0x10);
if (_0x189e2c['length'] == 0x1) {
_0x189e2c = '\x30' + _0x189e2c;
}
_0x5a5d3b += _0x189e2c;
}
return _0x5a5d3b;
}
String['prototype']['unsbox'] = function () {
var _0x4b082b = [0xf, 0x23, 0x1d, 0x18, 0x21, 0x10, 0x1, 0x26, 0xa, 0x9, 0x13, 0x1f, 0x28, 0x1b, 0x16, 0x17, 0x19, 0xd, 0x6, 0xb, 0x27, 0x12, 0x14, 0x8, 0xe, 0x15, 0x20, 0x1a, 0x2, 0x1e, 0x7, 0x4, 0x11, 0x5, 0x3, 0x1c, 0x22, 0x25, 0xc, 0x24];
var _0x4da0dc = [];
var _0x12605e = '';
for (var _0x20a7bf = 0x0; _0x20a7bf < this['length']; _0x20a7bf++) {
var _0x385ee3 = this[_0x20a7bf];
for (var _0x217721 = 0x0; _0x217721 < _0x4b082b['length']; _0x217721++) {
if (_0x4b082b[_0x217721] == _0x20a7bf + 0x1) {
_0x4da0dc[_0x217721] = _0x385ee3;
}
}
}
_0x12605e = _0x4da0dc['join']('');
return _0x12605e;
}
function get_cookie(arg1) {
// 这个值是变化的
// var arg1 = 'E7FC4E89FD5A4E550E19A8BE2061BD16BE4C0DB3';
var _0x23a392 = arg1['unsbox']();
var _0x5e8b26 = '3000176000856006061501533003690027800375'
// arg2 = _0x23a392[_0x55f3('0x1b', '\x7a\x35\x4f\x26')](_0x5e8b26);
arg2 = _0x23a392['hexXor'](_0x5e8b26);
return arg2
}
console.log(get_cookie('E7FC4E89FD5A4E550E19A8BE2061BD16BE4C0DB3'));import re
import execjs
import requests
headers = {
# ...
}
# 获取到第一次请求的值,返回生成cookie的代码,里面包含了需要的参数 arg1
response = requests.get('https://xueqiu.com/today', headers=headers).text
# with open("./ali.html", 'w', encoding='utf-8') as f:
# f.write(response)
# 正则提取arg1的值
# Regular expression pattern to match the argument assignment
pattern = r"var arg1='([A-F0-9]+)';"
# Search for the pattern in the JavaScript code
arg1 = re.search(pattern, response).group(1)
with open("./xueqiu.js") as f:
js_code = f.read()
cookie_acw_sc__v2 = execjs.compile(js_code).call("get_cookie", arg1)
print(cookie_acw_sc__v2)
cookies = {
'acw_sc__v2': cookie_acw_sc__v2,
# ...
}
headers = {
#...
}
response = requests.get('https://xueqiu.com/today', cookies=cookies, headers=headers).text
print(response)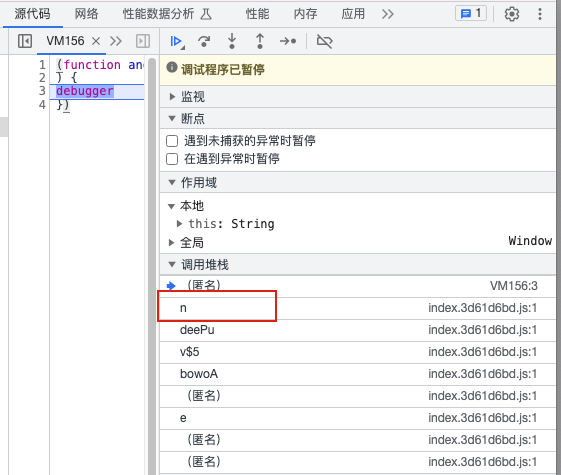
// 调用的方法
[f(-302, -39, -274, -178, "mK8a") + o(430, 0, "sXA$") + "r"](t[c(-294, "o#Hz", 0, -62)](t[h(1402, 1326, 1439, "wJdL")], t[h(1596, 1182, 1426, "2QAW")]))[c(-180, "mK8a", 0, -159)](t[h(1113, 950, 1143, "Es!I")])
// 逐步拆解
[f(-302, -39, -274, -178, "mK8a") + o(430, 0, "sXA$") + "r"]
// => ['constructor']
(t[c(-294, "o#Hz", 0, -62)](t[h(1402, 1326, 1439, "wJdL")], t[h(1596, 1182, 1426, "2QAW")]))
// => debugger
[c(-180, "mK8a", 0, -159)]
// => call
(t[h(1113, 950, 1143, "Es!I")])
// => actionfunc_constructor_ = Function.prototype.constructor;
Function.prototype.constructor = function (a) {
if (a == 'debugger') {
return function(){};
}
return func_constructor_(a);
};
xhr中添加接口的路径:/info_api/policyType/showPolicyType
找到interceptors.response.use的位置,返回的结果中存在了加密数据data。
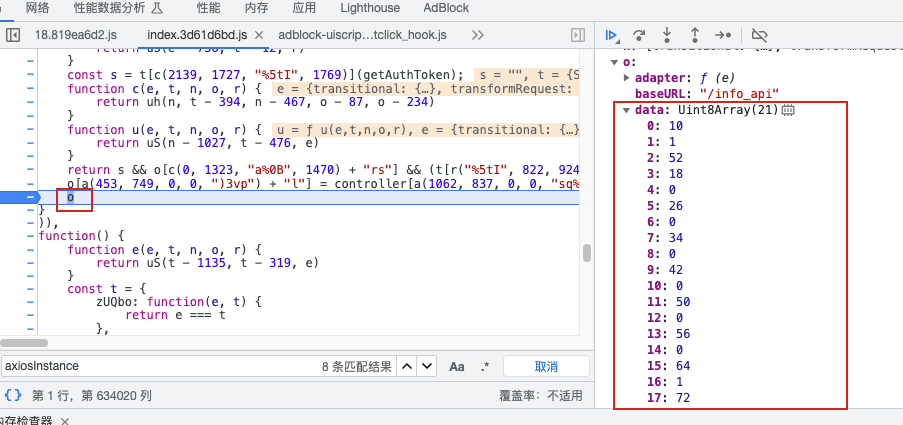
找到生成o的位置:
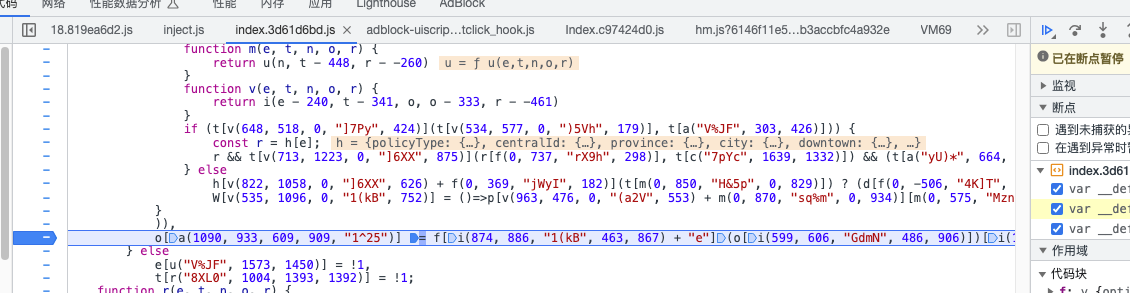
找到生成的方法:
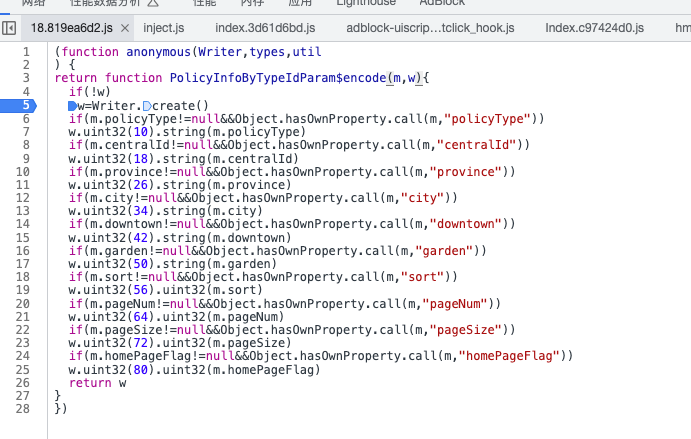
这里缺少了Writer,断点进入,这个代码是在vm中的生成的,找到函数的位置,扣下来完整的代码,用变量接收:
var writer_;
commonjsGlobal = global;
!function (g) {
var r, e, t, i;
r = {...},
e = {},
t = [16],
i = function t(n) {
var o = e[n];
return o || r[n][0].call(o = e[n] = {
exports: {}
}, t, o, o.exports),
o.exports
}(t[0]),
i.util.global.protobuf = i,
module && module.exports && (module.exports = i)
// 方法存放在i变量中
writer_ = i;
}()
function PolicyInfoByTypeIdParam_encode(m, w) {
if (!w)
w = writer_.Writer.create()
if (m.policyType != null && Object.hasOwnProperty.call(m, "policyType"))
w.uint32(10).string(m.policyType)
if (m.centralId != null && Object.hasOwnProperty.call(m, "centralId"))
w.uint32(18).string(m.centralId)
if (m.province != null && Object.hasOwnProperty.call(m, "province"))
w.uint32(26).string(m.province)
if (m.city != null && Object.hasOwnProperty.call(m, "city"))
w.uint32(34).string(m.city)
if (m.downtown != null && Object.hasOwnProperty.call(m, "downtown"))
w.uint32(42).string(m.downtown)
if (m.garden != null && Object.hasOwnProperty.call(m, "garden"))
w.uint32(50).string(m.garden)
if (m.sort != null && Object.hasOwnProperty.call(m, "sort"))
w.uint32(56).uint32(m.sort)
if (m.pageNum != null && Object.hasOwnProperty.call(m, "pageNum"))
w.uint32(64).uint32(m.pageNum)
if (m.pageSize != null && Object.hasOwnProperty.call(m, "pageSize"))
w.uint32(72).uint32(m.pageSize)
if (m.homePageFlag != null && Object.hasOwnProperty.call(m, "homePageFlag"))
w.uint32(80).uint32(m.homePageFlag)
return w
}
/**
* 接收类型和页号,返回请求所需的参数
* @param type 类型,str
* @param page 页号,int
* @returns {*} 加密后的数据,字典格式,数据在"data"
*/
function get_data(type, page) {
var data = {
"policyType": type,
"province": "",
"city": "",
"downtown": "",
"garden": "",
"centralId": "",
"sort": 0,
"homePageFlag": 1,
"pageNum": page,
"pageSize": 7
}
result = PolicyInfoByTypeIdParam_encode(data).finish().slice()
return result;
}
console.log(get_data("3", 1))import execjs
import requests
cookies = {
# 略
}
headers = {
'Accept': 'application/json, text/plain, */*',
# ... 略
}
with open("./spolicy.js") as f:
js_code = f.read()
# 获取type4的,第一页的请求加密参数
data = execjs.compile(js_code).call("get_data", "4", 1)
print(data)
response = requests.post(
'http://www.spolicy.com/info_api/policyType/showPolicyType',
cookies=cookies,
headers=headers,
# 转为bytes
data=bytes(data["data"]),
verify=False,
).json()
print(response)url:https://ec.minmetals.com.cn/open/home/purchase-info
每次请求都有两个接口,public获取公钥,用于后面加密参数;by-lx-page是数据接口,参数param是加密后的请求参数
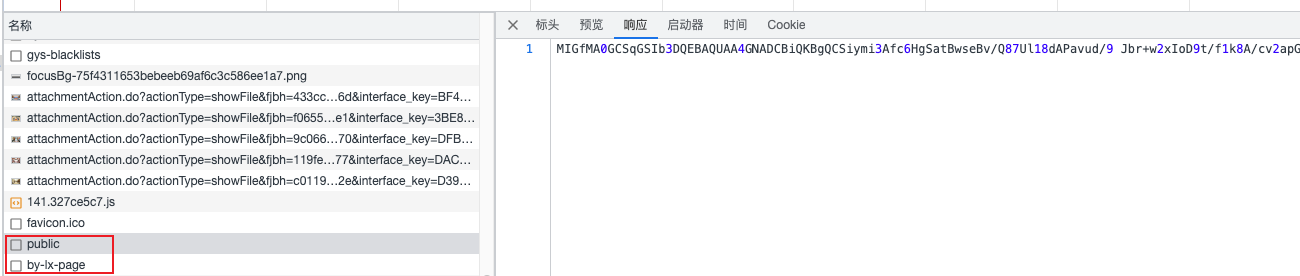
搜索**/open/homepage/public**(public公钥接口路径)找到js文件位置
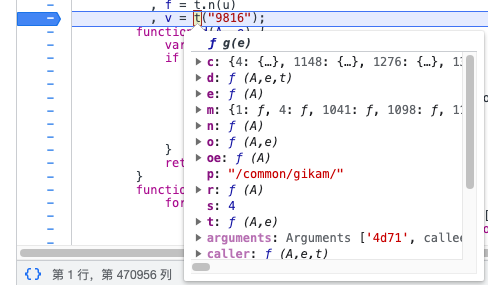
只要加载器部分,下面的函数可以只复制需要的
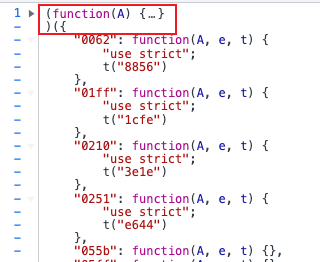
补充需要的模块,在这里搜索9816,复制到代码中
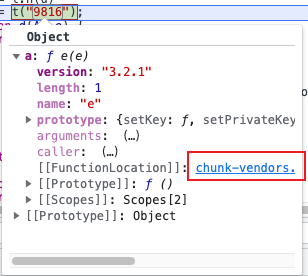
运行时报错,原因是缺少模块,打印出e,看看报错前的模块名,补充模块
/minmetals.js:52
return A[e].call(t.exports, t, t.exports, g),
^
TypeError: Cannot read property 'call' of undefined
之后补齐所有代码,有两个部分是变化的,public公钥和e请求参数部分,后续通过python传入
// ....其他代码省略
function get_param(public_key, param) {
// public_key
r = public_key
// e: params
e = param
t.setPublicKey(r),
a = m(m({}, e), {}, {
// 这里是md5加密,不用扣代码了,直接写一个
sign: md5Hash(JSON.stringify(e)),
timeStamp: +new Date
});
s = t.encryptLong(JSON.stringify(a))
return s
}
// 公钥
r = 'MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCSiymi3Afc6HgSatBwseBv/Q87Ul18dAPavud/9Jbr+w2xIoD9t/f1k8A/cv2apGmPwKnudecWa5IfXPVUvoqjG8GsTBR9kL4QKkBveZx46wx2KZEBSbjx9Ok92hgr6sCEHT4sO53VF6rhzYJ4WaqsugGdL3CrZEGV3x7MuvZ0tQIDAQAB'
// 请求参数
e = {
"inviteMethod": "",
"businessClassfication": "",
"mc": "",
"lx": "ZBGG",
"dwmc": "",
"pageIndex": 1
}
get_param(r, e)分为两个步骤,1是获取public公钥,2是将参数和公钥进行加密,发起请求
import execjs
import requests
# 获取public
import requests
cookies = {
# ...
}
headers = {
# ...
}
# 获取public_key
public_key = requests.post('https://ec.minmetals.com.cn/open/homepage/public', cookies=cookies, headers=headers).text
print(public_key)
# 获取parms加密参数
with open("./minmetals.js") as f:
js_code = f.read()
param = {
"inviteMethod": "",
"businessClassfication": "",
"mc": "",
"lx": "ZBGG",
"dwmc": "",
"pageIndex": 2
}
param = execjs.compile(js_code).call("get_param", public_key, param)
json_data = {
'param': param
}
response = requests.post(
'https://ec.minmetals.com.cn/open/homepage/zbs/by-lx-page',
cookies=cookies,
headers=headers,
json=json_data,
).json()
print(response)url:https://y.qq.com/n/ryqq/search
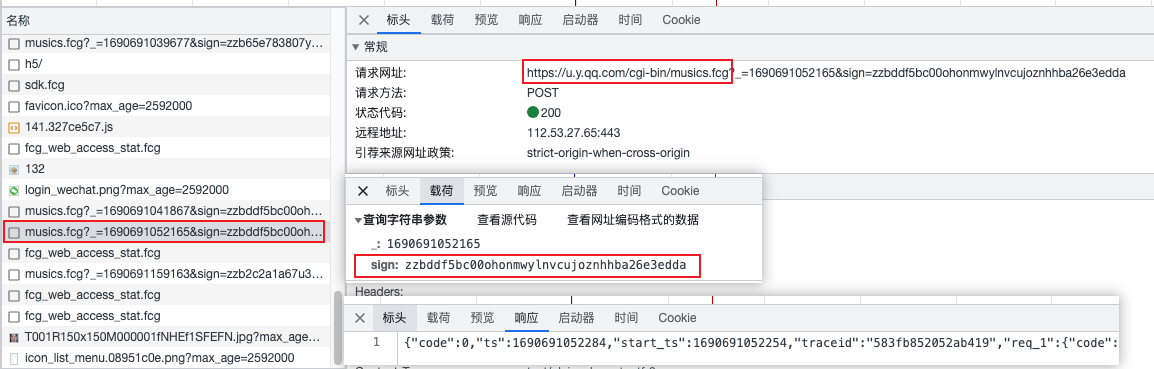
接口中sign参数为加密参数
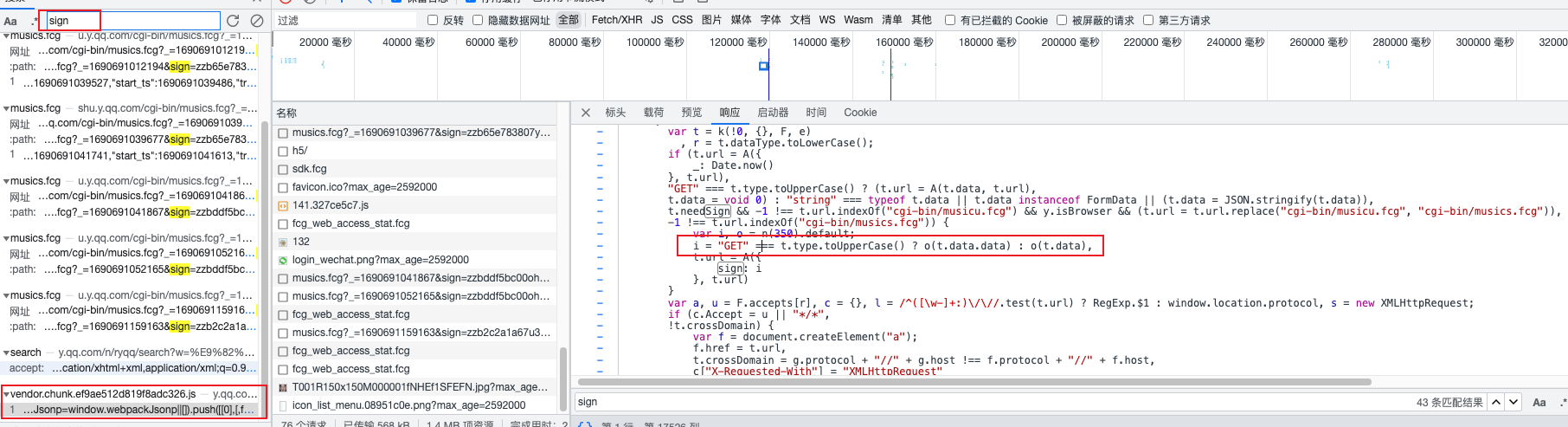
加密的方法是o(),找到o的生成位置
加载器
n为加载器,把n的代码复制(webpack)
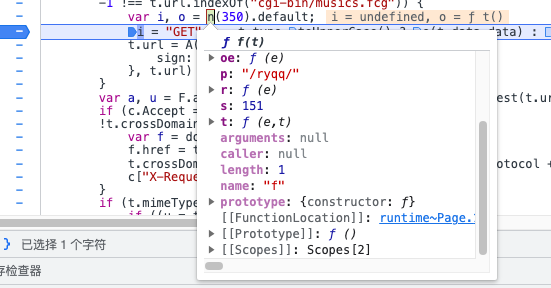
var loader_;
!function(e) {
// ...
// f是加载器,用全局变量接收
loader_ = f;
}([])加载器方法
这里是具体方法,把整个代码复制,在原来的代码中导入
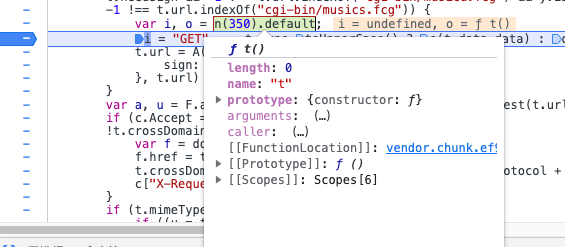
// 加载这个方法的所有代码
require("module")
var loader_;
!function(e) {
// ...
// f是加载器,用全局变量接收
loader_ = f;
}([])使用相同的参数,网页中返回的加密参数值为:"zzb5f83fe81ctmp7buyrgfgmht5hfggeb4159a0"
// ....
// 对比和网页的加密结果是否一致
origin_result = "zzb5f83fe81ctmp7buyrgfgmht5hfggeb4159a0"
result = loader_(350).default(t_data)
// 并不一致
// zzb5f83fe81ctmp7buyrgfgmht5hfggeb4159a0
// zzb2938d59cvfb4kyj1do3c4ldgj6o9qe0f41793加密方法是一样的,但是结果不一样,考虑是环境的问题,补充一些环境再测试
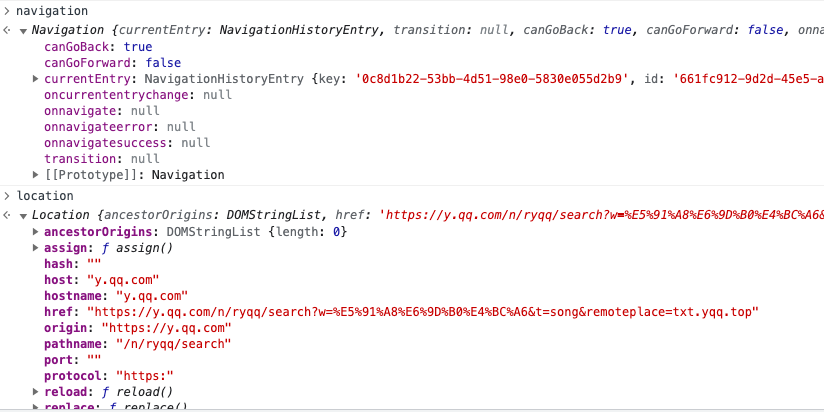
navigator = {
canGoBack: true,
canGoForward: false,
currentEntry: {
"id": "661fc912-9d2d-45e5-a144-fae79c979d88",
"index": 5,
"key": "0c8d1b22-53bb-4d51-98e0-5830e055d2b9",
"ondispose": null,
"sameDocument": true,
"url": "https://y.qq.com/n/ryqq/search?w=%E5%91%A8%E6%9D%B0%E4%BC%A6&t=song&remoteplace=txt.yqq.top"
},
"oncurrententrychange": null,
"onnavigate": null,
"onnavigateerror": null,
"onnavigatesuccess": null,
"transition": null
}
location = {
"ancestorOrigins": {},
"href": "https://y.qq.com/n/ryqq/search?w=%E5%91%A8%E6%9D%B0%E4%BC%A6&t=song&remoteplace=txt.yqq.top",
"origin": "https://y.qq.com",
"protocol": "https:",
"host": "y.qq.com",
"hostname": "y.qq.com",
"port": "",
"pathname": "/n/ryqq/search",
"search": "?w=%E5%91%A8%E6%9D%B0%E4%BC%A6&t=song&remoteplace=txt.yqq.top",
"hash": ""
}
// ....
console.log("zzb5f83fe81ctmp7buyrgfgmht5hfggeb4159a0");
console.log(loader_(350).default(t_data));
//zzb5f83fe81ctmp7buyrgfgmht5hfggeb4159a0
//zzb5f83fe81ctmp7buyrgfgmht5hfggeb4159a0import time
import execjs
import requests
# cookies和headers一定要正确才能请求到
cookies = {
# ...
}
headers = {
# ...
}
# 请求参数
singer = "周杰伦"
page_num = 1
data = '{"comm":{"cv":4747474,"ct":24,"format":"json","inCharset":"utf-8","outCharset":"utf-8","notice":0,"platform":"yqq.json","needNewCode":1,"uin":"1152921504860531892","g_tk_new_20200303":1531704962,"g_tk":1531704962},"req_1":{"method":"DoSearchForQQMusicDesktop","module":"music.search.SearchCgiService","param":{"remoteplace":"txt.yqq.top","searchid":"68939297501935721","search_type":0,"query":"'+singer+'","page_num":'+str(page_num)+',"num_per_page":10}}}'
# 获取sign加密参数
with open("./loader.js") as f:
js_code = f.read()
time_str = round(time.time() * 1000)
sign = execjs.compile(js_code).call("get_sign", data)
params = {
# 时间戳
'_': time_str,
# 加密参数
'sign': sign,
}
# 这里data要编码
response = requests.post('https://u.y.qq.com/cgi-bin/musics.fcg', params=params, cookies=cookies, headers=headers, data=data.encode()).json()
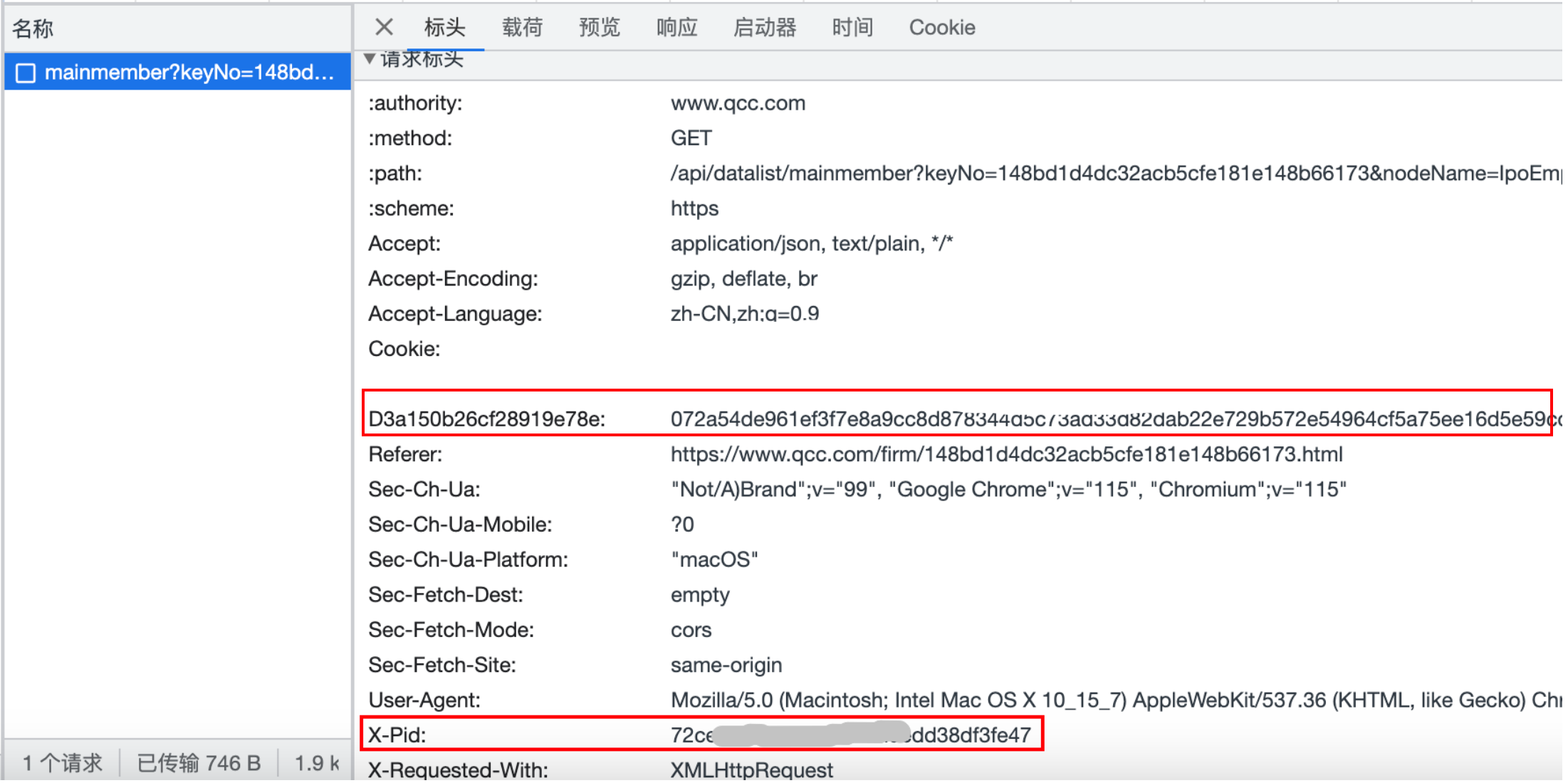
print(response)企查查的加密参数为接口的请求标头中的参数,key和value都不是固定的。
还有一个参数是X-Pid,可以在页面返回的数据中找到。
由于这个参数设置了headers的key和value,所以在代码里搜 "headers[" 或者 "headers." 找到加密的位置。
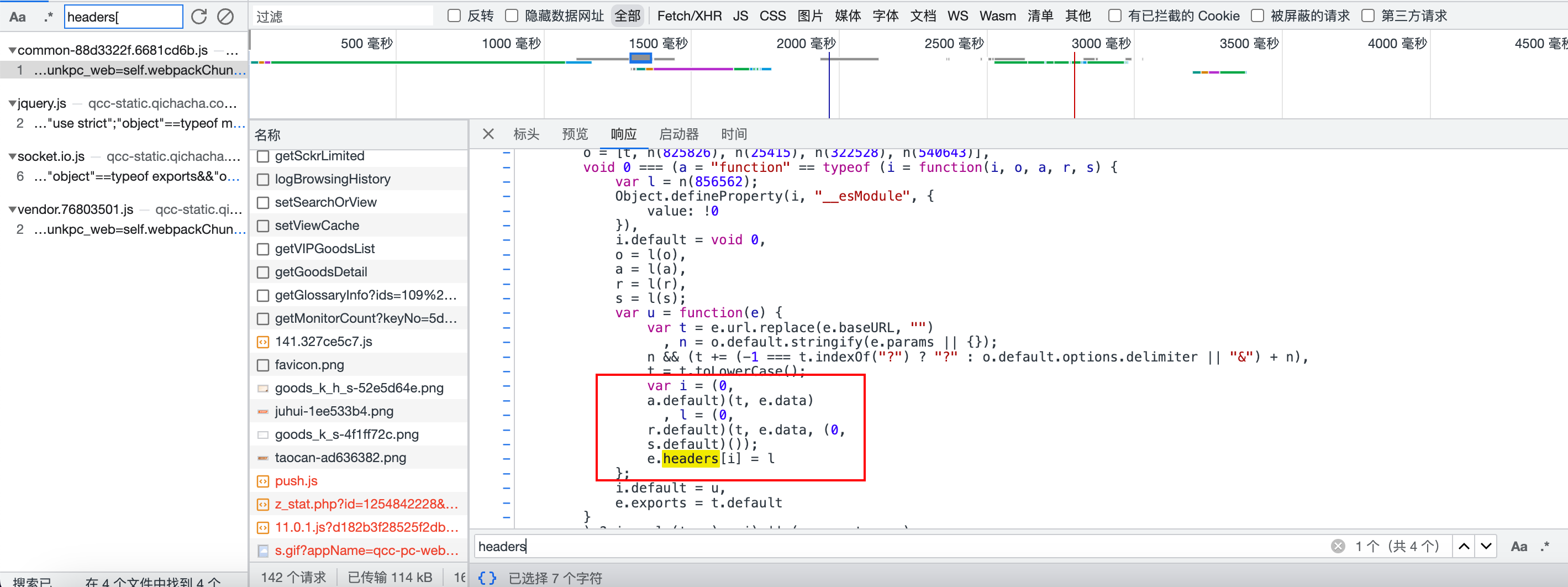
加密的位置就在这里,然后去扣所有的代码,最后会生成js文件,调用run方法即可生成接口参数。
可以看到最后生成的方法中需要两个参数,一个是path,一个是tid,最后的json_data是post请求的参数。
function run(path, tid, json_data){}path:即请求的路径,例如请求接口:https://www.qcc.com/api/datalist/mainmember?keyNo=....,path参数即为/api/datalist/mainmember?keyNo=....
tid:tid在请求的页面中,可以使用正则表达式提取出来。
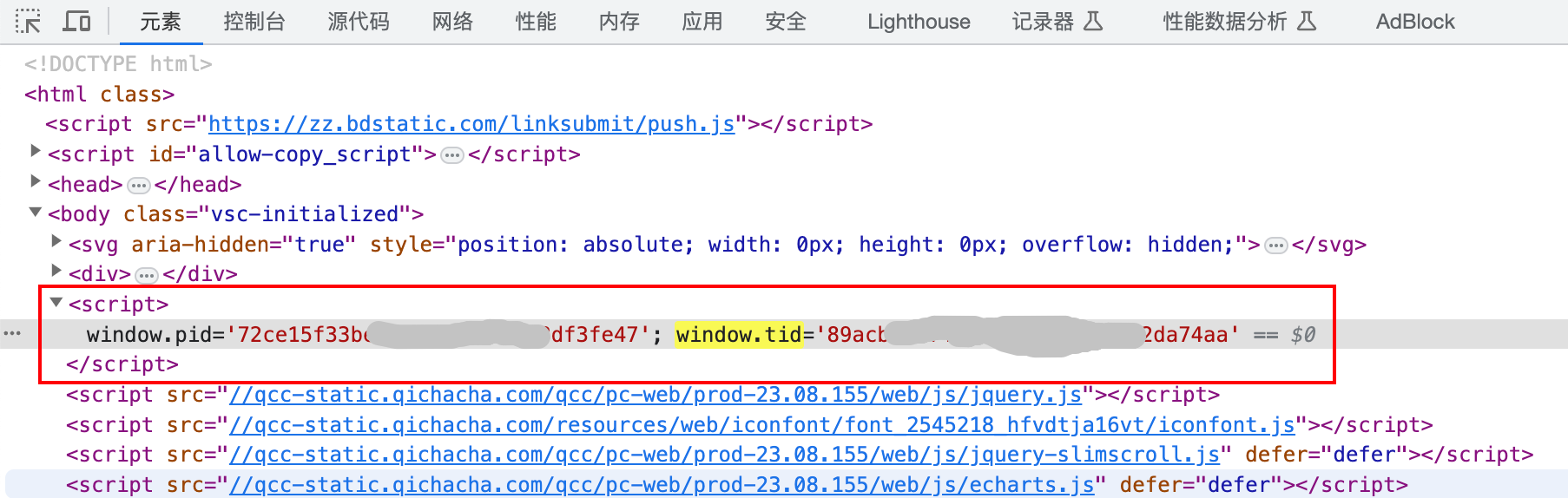
pid:就在tid旁边,这个参数放在headers里,key是x-pid
至此就可以对企查查的接口进行爬取。
import re
import execjs
import requests
# TODO 这里补充一下cookies
cookies = {
}
def build_api_headers(url, key_no, pid, tid, json_data=None):
"""
构造请求头
Args:
url: 链接,包含参数
key_no: 企业编号
pid: 页面的加密参数pid
tid: 页面的加密参数tid
json_data: post请求的json数据
Returns:
response对象
"""
headers = {'authority': 'www.qcc.com', 'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9', 'cache-control': 'no-cache', 'content-type': 'application/json',
'origin': 'https://www.qcc.com', 'pragma': 'no-cache',
'sec-ch-ua': '"Not/A)Brand";v="99", "Google Chrome";v="115", "Chromium";v="115"',
'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest', "referer": f'https://www.qcc.com/firm/{key_no}.html', 'x-pid': pid}
# 正则取出'/api'及其后面的所有内容
path = re.findall(r'(/api.*)', url)[0]
print(f"path: {path}")
# 执行qichacha.js中的run方法
with open('./qichacha_.js', 'r', encoding='utf-8') as f:
js = f.read()
if json_data:
ctx = execjs.compile(js).call('run', path, tid, json_data)
else:
ctx = execjs.compile(js).call('run', path, tid)
# ctx是个字典,便利出所有的key和value,添加到headers中,不要覆盖原来的headers
for k, v in ctx.items():
headers[k] = v
return headers
def post_api(url, key_no, pid, tid, json_data=None):
"""
请求企查查api接口,post请求
Args:
url: 链接,包含参数
key_no: 企业编号
pid: 页面的加密参数pid
tid: 页面的加密参数tid
json_data: post请求的json数据
Returns:
response对象
"""
headers = build_api_headers(url, key_no, pid, tid, json_data)
response = requests.post(url, cookies=cookies, headers=headers, json=json_data)
return response
def get_api(url, key_no, pid, tid, json_data=None):
"""
get请求企查查api接口
Args:
url: 链接,包含参数
key_no: 企业编号
pid: 页面的加密参数pid
tid: 页面的加密参数tid
Returns:
response对象
"""
headers = build_api_headers(url, key_no, pid, tid, json_data)
response = requests.get(url, cookies=cookies, headers=headers)
return response
if __name__ == '__main__':
# 以某企业为例
key_no = '5dffb644394922f9073544a08f38be9f'
pid = 'e19fd3c7ed52c1725cfff3226ba8af8c'
tid = 'd471a1659954b0cf6eb558c770dfdb3b'
# 请求可能需要会员,如果没有会员可以访问其他不需要会员的接口
# get请求
page_index = 1
get_url = f'https://www.qcc.com/api/datalist/mainmember?keyNo={key_no}&nodeName=IpoEmployees&pageIndex={page_index}'
main_member = get_api(get_url, key_no, pid, tid).json()
print(main_member)
# post请求
post_url = 'https://www.qcc.com/api/datalist/financiallist'
json_data = {
'keyNo': '5dffb644394922f9073544a08f38be9f',
'type': 'cm',
'reportType': 1,
'reportPeriodTypes': [
0,
4,
],
'currency': '',
'rate': 1,
}
financial = post_api(post_url, key_no, pid, tid, json_data=json_data).json()
print(financial)url:https://www.uyanip.com/register
1、接收图片,识别出验证码,拿到Cookies
2、发送短信,拿到token
3、发送注册请求
def get_img():
"""
获取验证码
:return: 返回cookies和验证码
"""
headers = {} # 省略
response = requests.get('https://api.duyandb.com/auth/register/captcha', headers=headers)
print(response.cookies)
# 检查响应状态码是否为 200
if response.status_code == 200:
# 将响应的内容解析为图片
image = Image.open(BytesIO(response.content))
captcha_code = ocr.classification(image)
else:
print("请求失败,状态码:", response.status_code)
return None
# 这里的coockies用于下一次请求
return {
"cookies":response.cookies, "captcha_code":captcha_code
}def send_code(phone_number:str, captcha_code, cookies):
"""
发送短信验证码
:param phone_number: 手机号
:param captcha_code: 图片验证码
:param cookies: 图片验证码拿到的Cookies
:return: {'data':'', 'errCode': 0}
"""
"""
发送验证码
:param phone_number: 手机号
:return: {'data':'', 'errCode': 0}
"""
headers={} # 省略
# 这里传入手机号和图片验证码
json_data = {
'value': phone_number,
'captchaCode': captcha_code,
}
response = requests.post('https://api.duyandb.com/auth/register/smscode', cookies=cookies, headers=headers,
json=json_data)
# 返回data和状态码,状态码为0则请求成功
return response.json()手机验证码发送成功后,就可以请求注册接口了
def register(phone_number:str):
"""
注册
:param phone_number: 手机号
:return: 成功或None
"""
headers = {} # 省略
# 获取图片验证码和Cookies
img_obj = get_img()
if img_obj:
# 发送短信,返回token。验证码错误会失败
code_obj = send_code(phone_number, img_obj['captcha_code'], img_obj["cookies"])
if code_obj["errCode"] != 0:
print(code_obj['data'])
return None
print(f"code_obj:{code_obj}")
# 手机验证码
phone_code = ''
phone_code = input("请输入手机验证码:")
json_data = {
# 这里需要传入短信验证码接口返回的token
'vtoken': code_obj['data'],
# 手机号
'phone': phone_number,
# 手机短信验证码
'smscode': phone_code,
'password': 'mima123456',
'confirmPassword': 'mima123456',
# 随机用户名
'nickname': generate_username(),
'pinvitationCode': '',
'type': 0,
}
# 发送注册请求
response = requests.put('https://api.duyandb.com/auth/register/submit', headers=headers, json=json_data)
# 成功会返回{'errCode':0, 'data': ''}
return response.json()如果你有短信验证码的接口这里可以进行批量注册。另外代码中没有添加代理,如果需要批量注册可能需要增加代理。
if __name__ == '__main__':
result = register('17118060285')
if result and result.get('errCode') == 0:
print("注册成功")
else:
print('注册失败,请重试')password是加密的
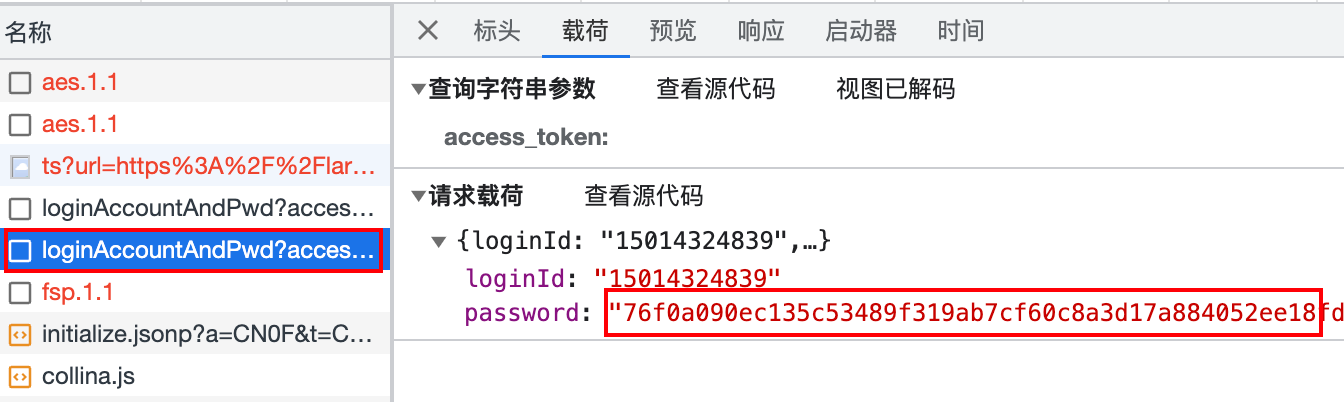
使用xhr断点或者堆栈找到加密的位置
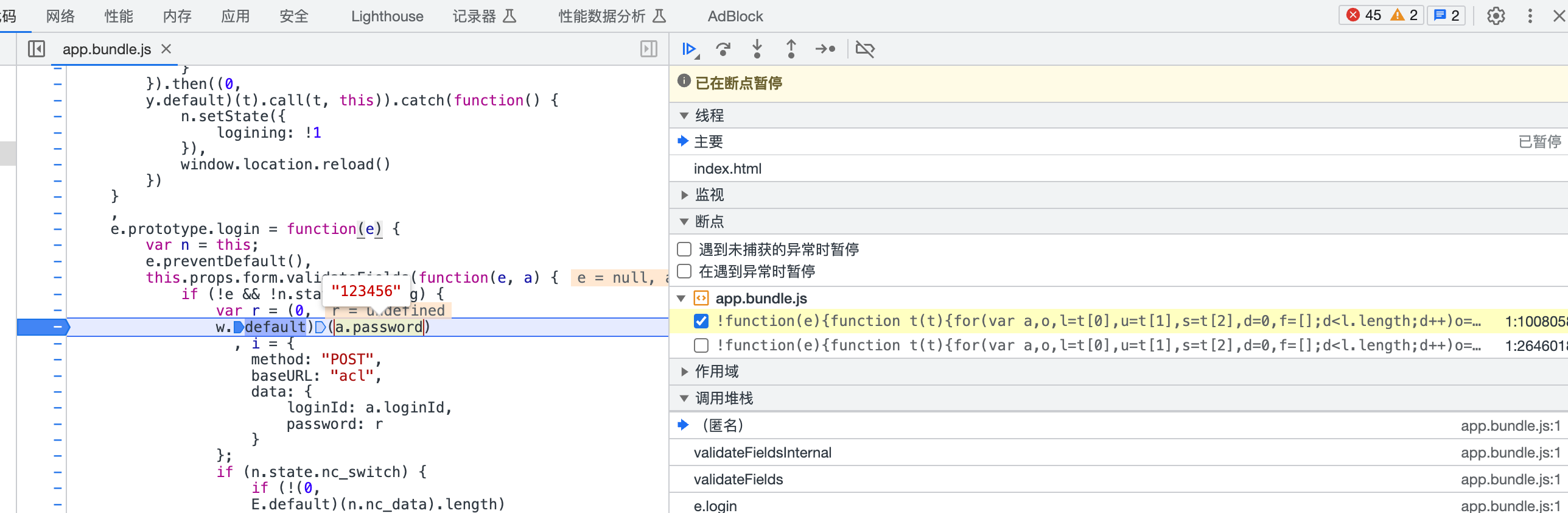
// 加密的js代码
var i = r(n(2132));
i.default.setMaxDigits(130);
var c = new i.default.RSAKeyPair("10001","", s['prod']);
i.default.encryptedString(c, encodeURIComponent(e))下面我们来补全这些代码

这里的n是加载器,下标2132这个方法就是i。
首先先把加载器的代码拿下来,然后再去找2132对应的方法,把方法放进数组里。
点击n的位置跳转到代码,前面部分是加载器,后面是所有的方法。这里只拿加载器,就是最开头的部份,后面跟着的数组是方法。
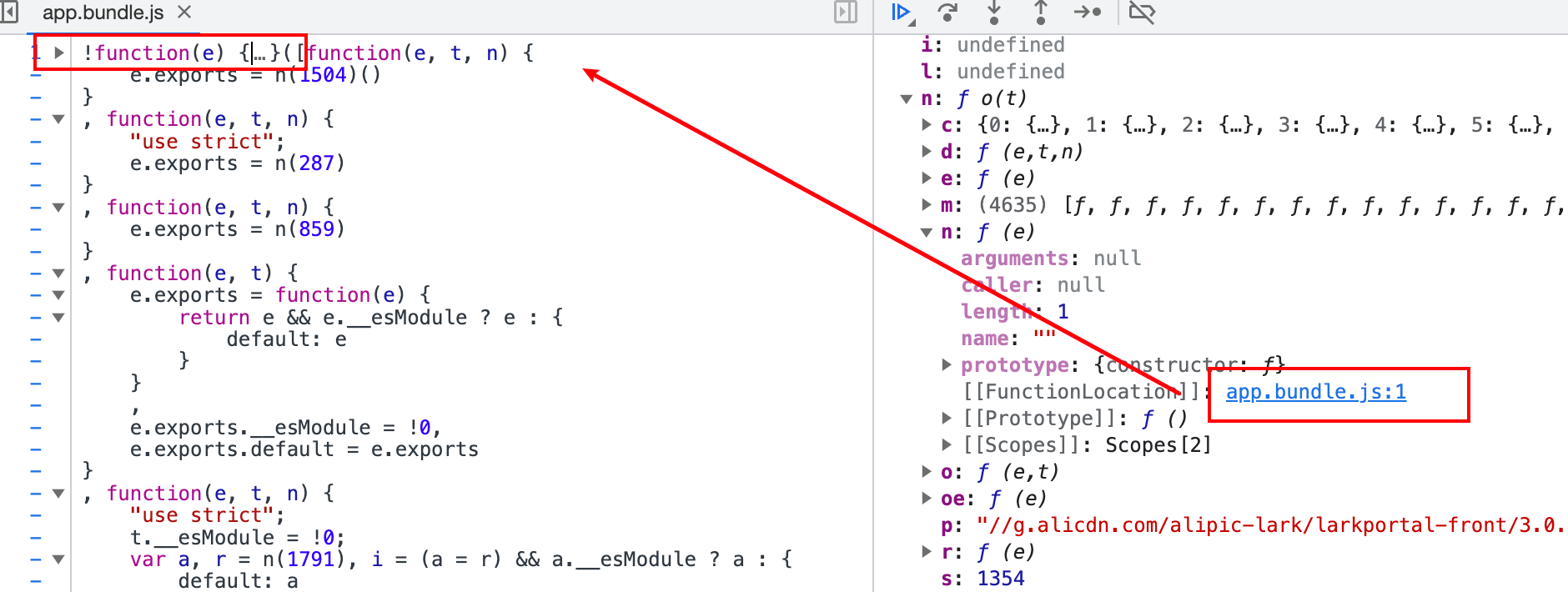
下一部是把这个方法里的代码复制到加载器的数组里,
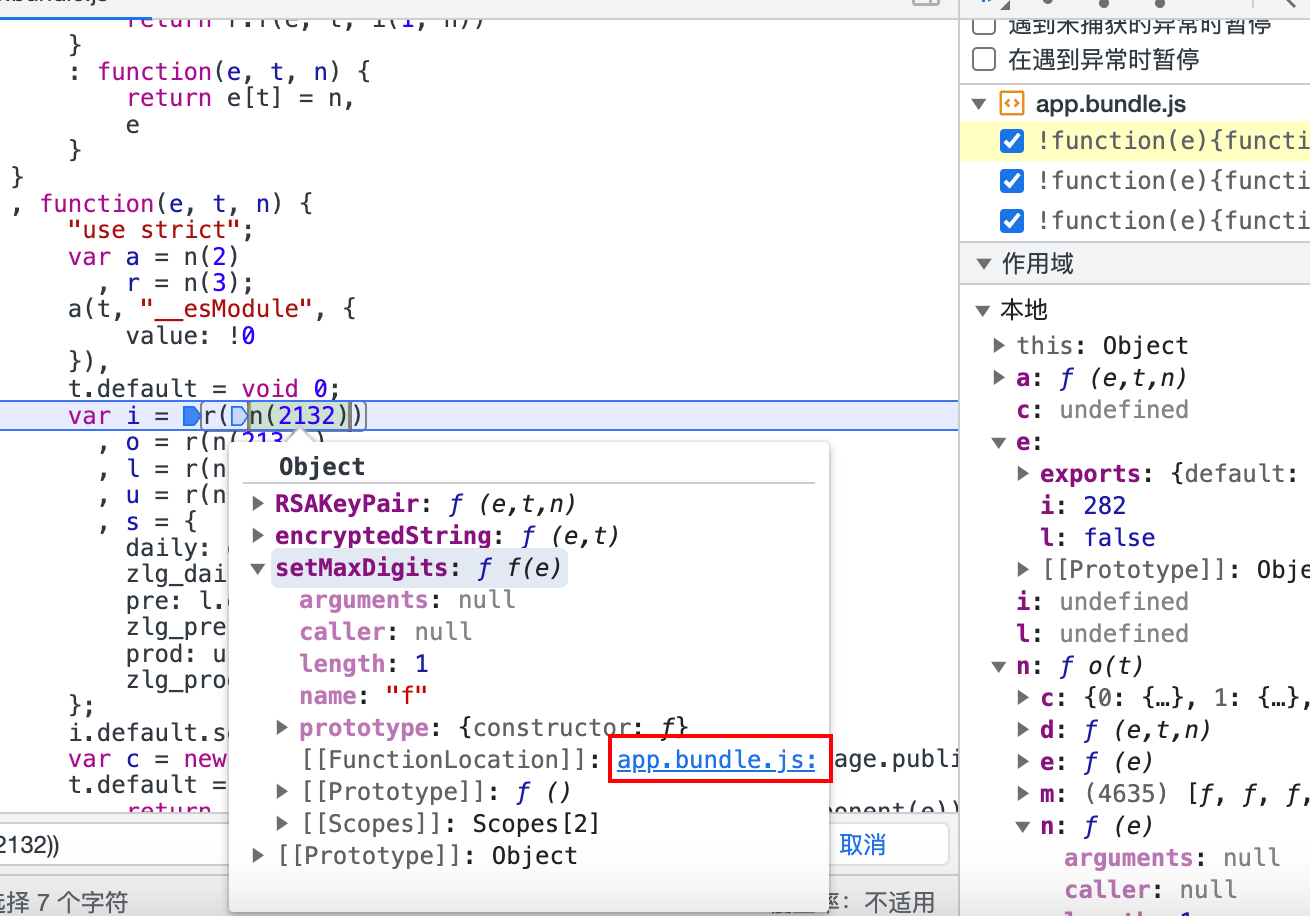
// 全局变量
var loader;
// 加载器
!function(e){
// ...
// 里面的方法都赋值给了o,所以这里用全局变量接收o
loader = o;
}([
// 这里面放方法,这个代码在第二步里找
function(e, t) {}
])
loader(0) // 这里就拿到了n(2132)对应的方法最终的js代码是这样的。yuekeyun.js
// 全局变量
var loader;
// 加载器
!function(e){
// ...
// 里面的方法都赋值给了o,所以这里用全局变量接收o
loader = o;
}([
// 这里面放方法,这个代码在第二步里找
function(e, t) {}
])
// 公钥
s = {
"prod": "837ec9791ee734418f44220b56cd22252c53309f59c560ff231d71e2579d38ea7a4408b017b1af85c6683111da151af25dddc53904a01e219bd56495a1add8cb70e54428bb87d95cd40478f6f800414be8a334ac779f4b819ae94fec240dc2ace1f99df64de88eef7bcbde4aabbdeac0e70a55e61331a9ea3d0546fe647977f9",
}
// loader(0)是RSA加密的函数
var i = loader(0);
function get_password(e) {
i.setMaxDigits(130);
var c = new i.RSAKeyPair("10001", "", s['prod']);
// e参数是密码
return i.encryptedString(c, encodeURIComponent(e));
}# 接口路径
url = 'https://www.zhipin.com/wapi/zpgeek/search/joblist.json'
cookies = {
# 略
# __zp_stoken__这个cookies就是加密的参数
'__zp_stoken__': 'ad34eWCUTC1I3FyZ7fGIuWAAsARcpQh5BZiZBcEhYbzhQO28Xb3l%2FZkN0Om9sLyV5LXtlQGx3HWUkfTs3LEIocAZwThoHVhsNFVsdeAxUJTtfHCFwXzpxYkR0YGsoCAMyb0JXPz99EG9pPD4%3D',
}
headers = {
# 略
}
params = {
# 略
# 关键词
'query': 'python',
'city': '101280600',
'multiSubway': '',
# 分页
'page': '2',
'pageSize': '30',
}
response = requests.get(url, params=params, cookies=cookies, headers=headers)通过关键字搜索 _zp_stoken_,找到生成参数的js。
// cookies的值
r = (new e).z(t, parseInt(n) + 60 * (480 + (new Date).getTimezoneOffset()) * 1e3)通过搜索cookies加密的参数可以找到js文件,断点到加密的位置,把js文件复制下来。
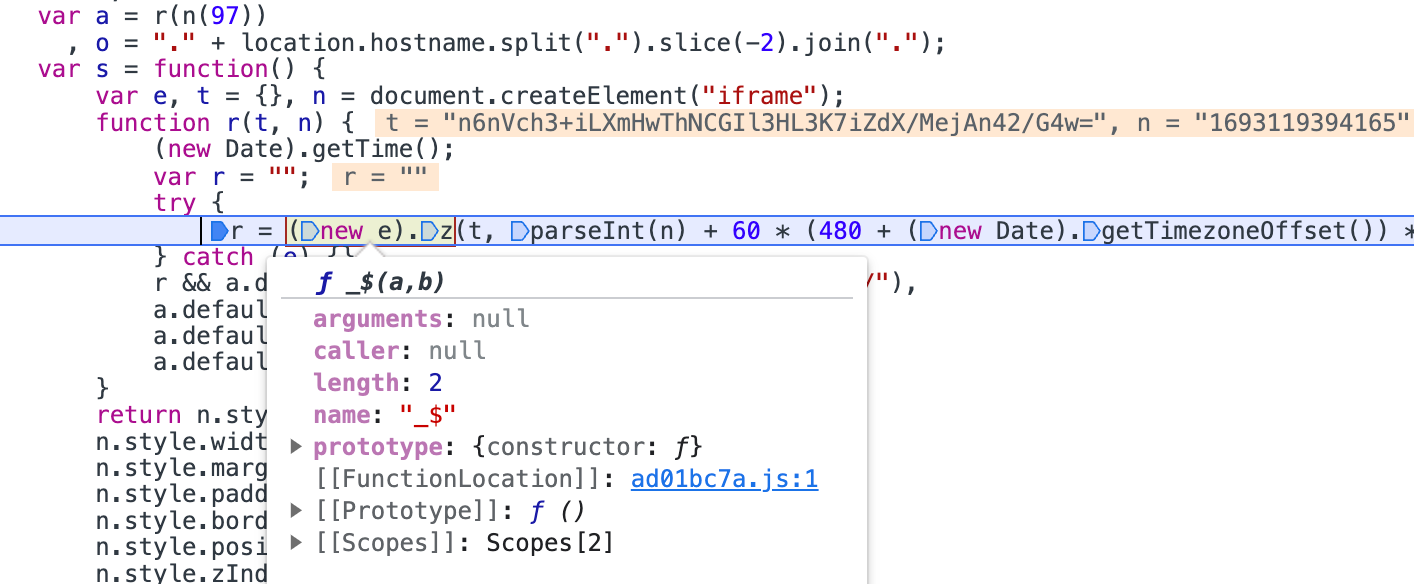
调试后发现是在**window['ABD']['prototype']**里,最后我们要调用的方法是:
// seek和ts也在cookies中
window["ABC"]["prototype"].z(seek, ts)
执行js的时候发现很多属性没有,这是很多环境不存在导致的,需要把环境补上。具体可查看代码
const{JSDOM}=require("jsdom");
const dom = new JSDOM(`<!DOCTYPE html><p>Hello world</p>`, {
url: 'https://www.zhipin.com/'
});
window=dom.window;
document=window.document;
navigator=window.navigator;
location=window.location;
history=window.history;
screen=window.screen; /**
* 生成zp_token cookies参数
* @param sseed cookies中的__zp_sseed__参数
* @param sts cookies中的__zp_sts__参数
* @returns __zp_token__ __zp_token__参数
*/
function get_zp_token(sseed, sts) {
return window["ABC"]["prototype"].z(sseed, parseInt(sts) + 60 * (480 + (new Date).getTimezoneOffset()) * 1e3)
}
- msToken: 用于加密的参数,可以在area接口中获取
- X-Bogus: 加密生成的参数
- _signature: 加密生成的参数
可以添加X-Bogus或者__signature,这里以最后一个参数为例:

这里需要注意是添加到后面的方法上,不要直接添加在断点的位置(添加到上图中红框黄色箭头的位置)。
添加条件断点是因为这里会执行比较多的参数,我们只需要x-bogus和signature,根据返回的长度来决定是否debugger。x-bogus会返回长度28的str,signature是147.
// _signature
_0x2c5e7b['apply'](_0x275c89, _0x301f8b).length === 147
// X-Bogus
_0x2c5e7b['apply'](_0x275c89, _0x301f8b).length === 28断点后我们直接进入方法,在两个断点中可以分别查看看方法和参数,将所有代码扣下来,将两个加密的方法用变量接收,并且补齐环境,包括document.cookie。
function get_param(msToken, url, body) {
/**
* 生成请求的参数
* @type {string} msToken,X-Bogus,_signature
*/
// body转为str
body_str = JSON.stringify(body)
xb = xb_func('msToken=' + msToken, body_str)
return {
'msToken': msToken,
'X-Bogus': xb,
'_signature': sign_func({
'body': body,
'url': url + 'msToken=' + msToken + '&X-Bogus=' + xb
}, undefined, 'forreal')
}
}这里分为两步:
- 首先是获取msToken,在area这个接口中,携带cookie请求后即可获取;
- 其次是接口数据获取,需要将msToken传入js文件中生成x-bogus参数和signature参数,然后发起请求。
**tips:**cookie具有时效性,如果请求失效或者signature的值错误,可能是cookie的问题。
import re
import execjs
import requests
cookies = {
# ...
}
def get_ms_token() -> str:
"""
获取msToken参数,需要cookies
:return: msToken
"""
headers = {
# ...
}
params = {
'dates': 'daily-20230831_weekly-20230827_monthly-202307',
'area': '["11"]',
'category_id': '1',
}
# 请求area接口,获取msToken
response = requests.get('https://trendinsight.oceanengine.com/area', params=params, cookies=cookies,
headers=headers).text
if 'msToken' in response:
ms_token = re.search(r'msToken=(.*?);', response).group(1)
return ms_token
else:
return ''
def get_poi_list() -> dict:
"""
获取数据
:return: json格式的数据
"""
# 获取msToken
ms_token = get_ms_token()
if not ms_token:
print("not msToken")
return {}
headers = {
# ...
}
# 请求参数,根据需要调整
json_data = {
# ...
}
url = 'https://trendinsight.oceanengine.com/api/open/area/get_poi_list'
# 读取./juliang.js调用get_params方法,获取两个加密参数
with open('./juliang.js', 'r') as f:
js_code = f.read()
ctx = execjs.compile(js_code)
params_dict = ctx.call('get_param', ms_token, url, json_data)
x_bogus = params_dict['X-Bogus']
_signature = params_dict['_signature']
# 发起请求
response = requests.post(
f'{url}?msToken={ms_token}&X-Bogus={x_bogus}&_signature={_signature}',
cookies=cookies,
headers=headers,
json=json_data,
)
return response.json()
if __name__ == '__main__':
print(get_poi_list())url:https://www.geetest.com/demo/slide-float.html
极验3滑块验证码,版本:7.9.1。
https://www.geetest.com/demo/gt/register-slide?t=1694237711524
// 响应
{
"success": 1,
"challenge": "18318454a32f0cfd280c5ba9d5f68fcd",
"gt": "019924a82c70bb123aae90d483087f94",
"new_captcha": true
}https://apiv6.geetest.com/get.php...
{
"status": "success",
"data": {
"c": [
12,
58,
98,
36,
43,
95,
62,
15,
12
],
"s": "61752c3a",
// ...
}
}https://api.geetest.com/get.php
{
"gt": "019924a82c70bb123aae90d483087f94",
"challenge": "18318454a32f0cfd280c5ba9d5f68fcd8z",
"id": "a18318454a32f0cfd280c5ba9d5f68fcd",
"bg": "pictures/gt/cd0bbb6fe/bg/51e3c23b0.jpg",
"fullbg": "pictures/gt/cd0bbb6fe/cd0bbb6fe.jpg",
"height": 160,
"slice": "pictures/gt/cd0bbb6fe/slice/51e3c23b0.png",
"api_server": "https://api.geetest.com",
"static_servers": [
"static.geetest.com/",
"dn-staticdown.qbox.me/"
],
"c": [
12,
58,
98,
36,
43,
95,
62,
15,
12
],
"s": "51363072",
"gct_path": "/static/js/gct.b71a9027509bc6bcfef9fc6a196424f5.js"
// ...
}通过轨迹和其他参数最终会生成w值。
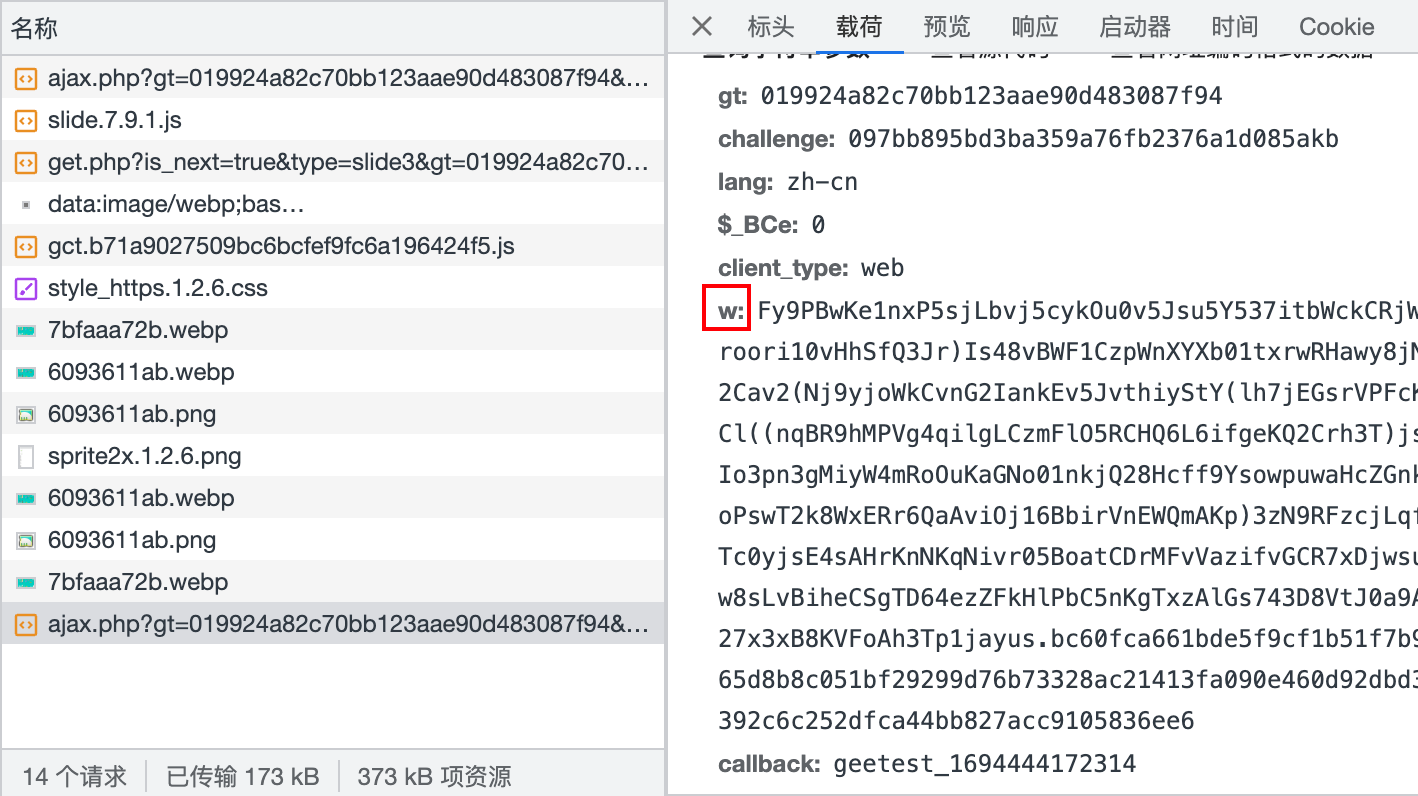
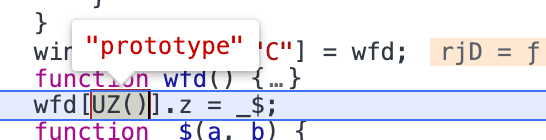
点击验证码会请求js文件,然后搜索w的unicode编码**"/u0077"**,可以找到代码。
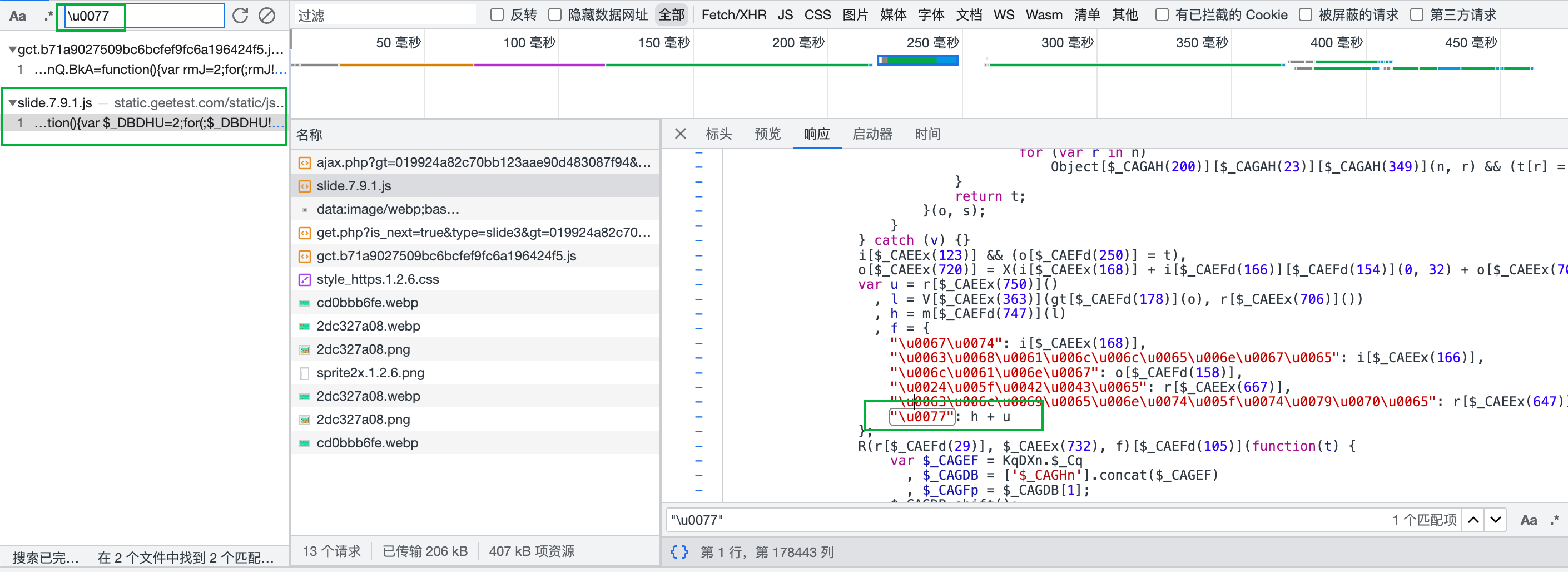
在这个js里会用到前面接口生成的c、s、gt、challenge,还需要轨迹、滑动时间、滑动距离。代码比较多比较杂,这里直接展示最终的参数生成代码,只需传入对应的参数。
function generate_w(params){
/**
* 生成w, params需要传入distance, passtime, track, c, s, gt, challenge
*/
var u = new U()["encrypt"](rt_) // 这里的rt是一个随机值,但是需要和下面保持一致
o = {
"lang": "zh-cn",
"userresponse": H(params['distance'], params['challenge']), // 把滑动距离和challenge传入H函数,得到userresponse
"passtime": params['passtime'], // 滑动时间,要和轨迹里的滑动时间一致
"imgload": 155, // 加载时间,可以是随机值
"aa": sign_aaa(params['track'], params['c'], params['s']), // 传入轨迹、c、s,生成aa
"ep": sign_ep(), // 一些版本号(7.9.1),时间等信息
"h9s9": "1816378497", // 固定值
"rp": md5Hash(params['gt'] + params['challenge'].slice(0, 32) + params['passtime']) // 传入gt、challenge、passtime,md5生成rp
}
var l = V['encrypt'](gt['stringify'](o), rt_)
var h = m["$_FCp"](l)
return h + u
}滑块可以使用ddddorc库进行识别,识别出来的距离需要-10,因为距离不是从最左侧开始计算的。
接口请求都需要访问一次,不然可能会报错,尤其是get.php、ajax.php等接口。
challenge、gt、c、s等参数都在接口中,需要注意参数可能变化,需要使用最新的值。
url:aHR0cHM6Ly9iZWlhbi5taWl0Lmdvdi5jbi9pbmRleCMvSW50ZWdyYXRlZC9pbmRleA
index页面一共会访问三次
返回一段js代码,会生成**__jsl_clearance_s**的cookie参数。
请求中会返回**__jsluid_s**的cookie,可以使用session或者将这个值保存。
携带前面生成的两个cookie参数,返回一段加密js代码。
代码使用了ob混淆,可以使用在线工具还原。https://ob.nightteam.cn/
一共有三份代码,分别是sha1、sha256、md5加密,将加密部分抽离即可。
js代码最后有一个json格式的参数,加密时需要用到,可以使用正则提取。
ha参数就是加密的方式。
携带第二次js代码加密生成的cookie就可以获取到数据。
使用chrome本地替换的方式对代码进行调试,还原过程比较简单。因为有三份加密代码,所以要将代码封装起来用参数判断,最后代码如下:
_0x8b2003 = new Date();
function hash_md5(_0x4838bf){}
function hash_sha256(_0x14757c){}
function hash_sha1(_0xa1962c){}
function get_cookie(data) {
_0x190080 = data
// 判断加密参数
if (data['ha']=='md5') {
hash = hash_md5
}else if (data['ha']=='sha1') {
hash = hash_sha1
}else if (data['ha']=='sha256') {
hash = hash_sha256
}else{
throw new Error('hash not found')
}
function _0x247acb(_0x315328, _0x4b6f80) {
// ... 略
if (hash(_0x4e03cb) == _0x315328) {
return [_0x4e03cb, new Date() - _0x8b2003];
}
}
var cookie_value = _0x247acb(_0x190080['ct'], _0x190080["bts"]);
return cookie_value
}rpc实现js解密的思路即在浏览器和本地之间实现websocket通信,本地远程调用浏览器的方法,返回函数的结果(加密函数等),即可获取页面的加密参数。
使用此方法可以快速解决部分反爬的问题,省去了扣js、补环境等操作。
**示例网站(Base64):**aHR0cDovL3d3dy5mYW5nZGkuY29tLmNuL3NlcnZpY2UvYnVsbGV0aW5fbGlzdC5odG1sP3R5cGVhPTNiODgwMzdiYjhiM2Y5MDgmbmFtZT0lRTglQTElOEMlRTQlQjglOUElRTUlOEElQTglRTYlODAlODE=
在浏览器终端,通过断点调试的方式找到方法,然后将加密方法定义到windows中,方便调用。
windows.my_crypto = _$vQ; // _$vQ为加密的方法,需要一个参数
在终端中执行或者使用代码段等方式嵌入代码。
!(function () {
// 监听端口
var ws = new WebSocket("ws://127.0.0.1:5678"); // 自定义端口
ws.onmessage = function (evt) {
console.log("receive msg: " + evt.data);
// 退出
if (evt.data === "quit") {
ws.close();
} else {
// 调用方法,此处的my_crypto改为定义的函数名
ws.send(my_crypto(evt.data))
}
};
})()import sys
import asyncio
import websockets
async def receive_massage(websocket):
while True:
# 输入参数
send_text = input("Enter param please: ")
if send_text == "quit":
await websocket.send(send_text)
await websocket.close()
print('quit')
sys.exit()
else:
# 发送参数
await websocket.send(send_text)
# 返回结果
response_text = await websocket.recv()
print("\n result:", response_text)
start_server = websockets.serve(receive_massage, '127.0.0.1', 5678) # 自定义端口
asyncio.get_event_loop().run_until_complete(start_server)
asyncio.get_event_loop().run_forever()输入参数,浏览器调用方法执行函数,返回结果
Enter param please: hello
result: http://www.xxxxxxx.com.cn/xxxxxx/hello?MmEwMD=4PCeybQd55uKYvUSSmDMRog5lWDWPHMOxmxIXWJlR55hSD_g1sJthJJJiTjbRm686KiRBYNY41.hVzO_6f1JmHlRl9d3h9HIgACnzKG5pcDI3NVYvoLoFjC2V.EolPuiI5rUi03HA1C32CKC2JMoteoVc.0IFoO_YL9_nSTo7I4jeEIObQr4XNjytzCPwl2C8ydfVBETAIdAiT5_2gAHrTUReojI7O.lr50sXQfusIkswqG1.4byu903XQju.VACsrgydmKPmXAQCQXQ7hfZjDwMS_UrVCB_pZptj.BJyDIK2w5HpCjxvBYYlcV5cfsI5JYThkZ2C8ANvIhOhtD1Dw6esCSVnc_F1YeHilQcqen9Gn9SSa.wB92txGz_rucFEE2a.oLL3XaRl7WFExc0suFrQwy.bqaxIhwKpbb9pLcPJX9UFu6PES_oM6_MPCwQrrvz
url:aHR0cDovL3EuMTBqcWthLmNvbS5jbi8=
hook cookie的方式有很多,油猴、代码注入等,这一次使用的工具是v_jstools,后面补环境的时候也是用它。
当然你也可以使用其他的方式,hook的js代码:
(function() {
// 严谨模式 检查所有错误
'use strict';
// document 为要hook的对象 这里是hook的cookie
var cookieTemp = "";
Object.defineProperty(document, 'cookie', {
// hook set方法也就是赋值的方法
set: function(val) {
// 这样就可以快速给下面这个代码行下断点
// 从而快速定位设置cookie的代码
console.log('Hook捕获到cookie设置->', val);
debugger;
cookieTemp = val;
return val;
},
// hook get 方法也就是取值的方法
get: function()
{
return cookieTemp;
}
});
})();看到这个值是v的时候就是我们的目标cookie了,往上跟栈找到它的代码,就在如下的位置。

最终会看到这个方法,它就是生成cookie的:
var TOKEN_SERVER_TIME = 1695968000.498;
!function(n, t) {
// .... 省略
function O() {
S[R]++,
S[p] = Jn.serverTimeNow(),
S[d] = Jn.timeNow(),
S[B] = Vn,
S[I] = nt.getMouseMove(),
S[y] = nt.getMouseClick(),
S[_] = nt.getMouseWhell(),
S[C] = nt.getKeyDown(),
S[E] = nt.getClickPos().x,
S[A] = nt.getClickPos().y;
var n = S.toBuffer();
return zn.encode(n)
}
// ....
}(/* ... */)把上述文件的js代码全部复制,把加密方法用全局变量接收:
var Heixin;
/*
在上述代码中把加密方法赋值给全局变量
Heixin = O
*/
function get_v(){
return Hexin()
}这里如果运行,会发现有很多环境没有。下一步开始补环境。
补环境我们用v_jstools工具来补。安装在开头的超链接中,clone后拖到扩展中心即可(开发者模式)。

点击工具,点击打开配置页面,然后勾选如下配置:
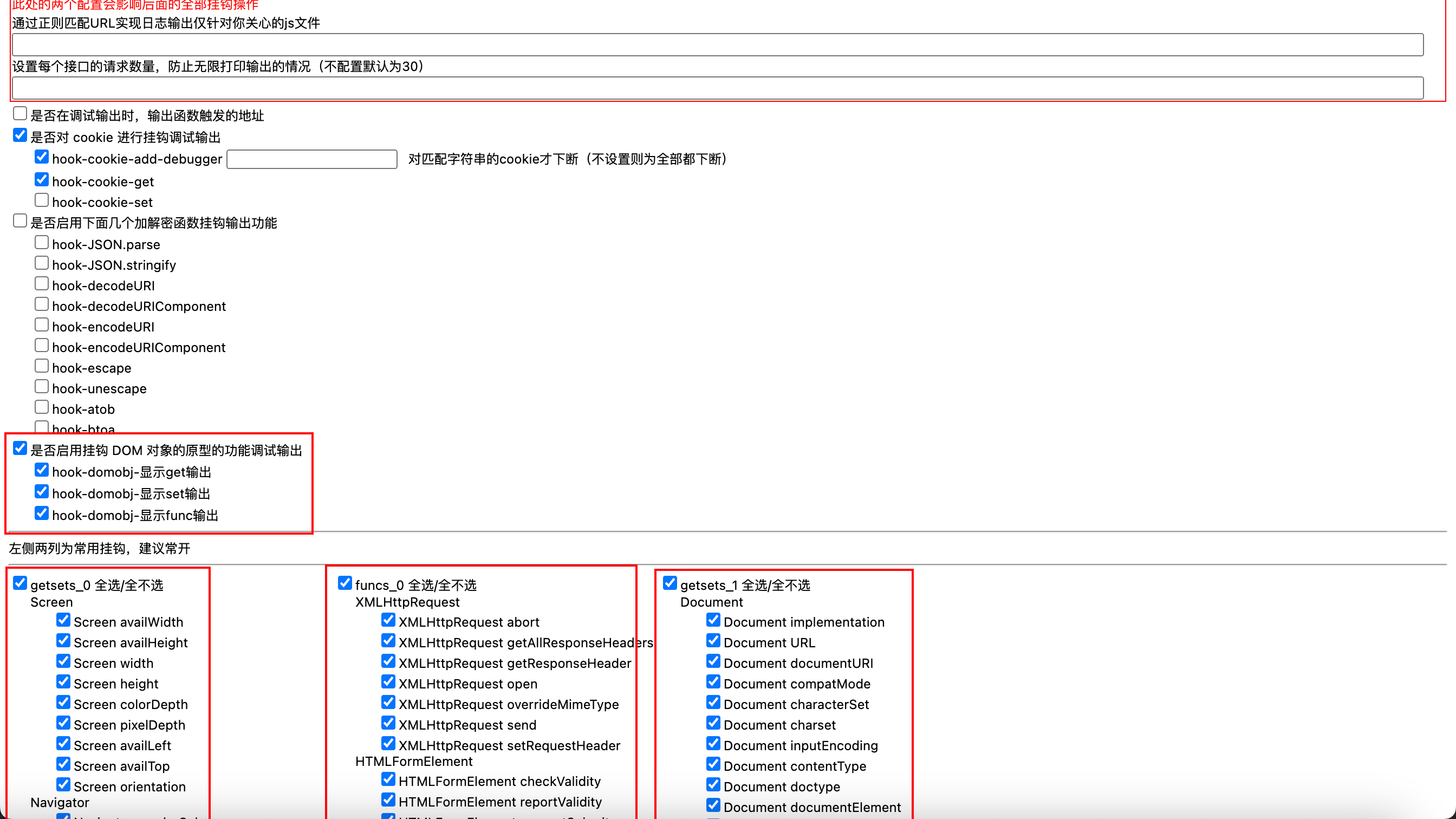
先清空cookie,然后打开开发者工具,刷新页面。控制台应该会有很多输出,打开扩展工具菜单,点击生成临时环境,即可复制环境代码,粘贴到最开始的代码上方即可。
加密的cookie在cookies中,也在名为hexin-x的headers参数中,请求时带上即可。
请求的代码就不便展示啦....
微信:3.8.1版本
cd ~/Library/Containers/com.tencent.xinWeChat/Data/.wxapplet/packages/文件夹名为:wx***(每个小程序对应一个文件夹,可以根据修改日期判断),打开后里面有几个**.wxapkg**后缀的文件,这是小程序的包,稍后需要反编译。
(Windows路径请百度)
参考:https://sspai.com/post/55066#
工具:unveilr.exe https://www.aliyundrive.com/s/Ckkm4xeJwSB 提取码: 48fs
反编译工具有wxappUnpacker等,但是项目比较老,运行会报错。所以用到了unveilr.exe这个工具,只找到了windows上运行的版本,可以使用虚拟机或者windows系统进行反编译。
将packages/***.wxapkg文件都放到一个文件夹中,执行:
unveilr.exe /testpkg # /testpkg替换为你存放文件的路径完成后会生成一个文件夹**__APP__**
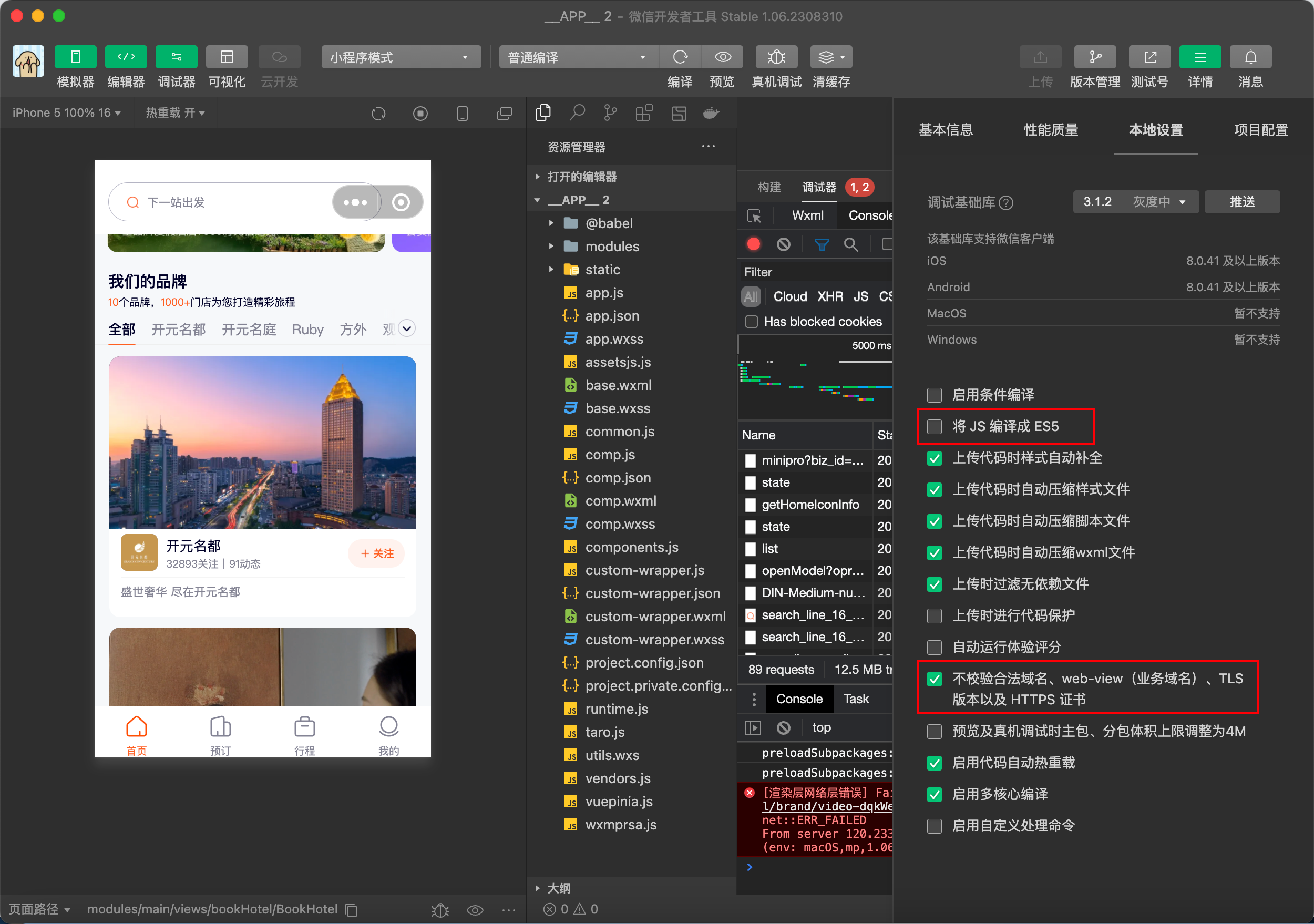
打开微信开发者工具,选择导入项目,将APP文件夹导入。
取消勾选**"将JS编译成ES5",勾选"不校验合法域名..."**,点击编译
以list接口为例。
加密参数在headers中:
MessageId
Signature
全局搜索MessageId和Signature参数,加密方法都在common.js文件中,逆向过程没有什么难点,只提几个注意事项:
- **c()**方法为MD5加密,可以导入库进行加密,不用扣代码;
- Signature需要MessageId作为参数,所以先扣MessageId,当然先随便写个参数也无所谓。
- t.url为请求接口的url,可以封装成方法直接传入。
// 导入md5
const CryptoJS = require('crypto-js')
// url = "https://api.betterwood.com/hotel/brand/museum/list"
/**
* 传入接口的完整url,返回headers中的参数
* @param url 接口的完整url
* @returns {{Signature: *, MessageId}}
*/
function get_headers(url) {
// MessageId
H = function (t) {
for (var n = [8, 13, 18, 23], e = 0; e < n.length; e++)
t = t.slice(0, n[e]) + "-" + t.slice(n[e]);
return t
}
x = function () {
for (var t = arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "", n = [], e = "0123456789abcdef", r = 0; r < 36; r++) {
var o = Math.floor(16 * Math.random());
n[r] = e.substring(o, o + 1)
}
n[14] = "4";
var i = 3 & Number(n[19]) | 8;
n[19] = e.substring(i, i + 1),
n[8] = n[13] = n[18] = n[23] = "-";
var u = n.join("")
, a = H(CryptoJS.MD5(u + (new Date).getTime() + t).toString());
return a
}
MessageId = x()
// Signature
L = function (t, n, e, r, o, i, u, a, s) {
var d = "";
return d = a ? "AppVersion=".concat(o, "Authorization=").concat(a, "Channel=").concat(i, "ClientType=").concat(r, "DeviceManufacture=").concat(n, "DeviceModel=").concat(e, "MessageId=").concat(u, "OsVersion=").concat(t, "AppKey=C49E2654AAA94F5085A9C12FE2CAB09CUrl=").concat(s) : "AppVersion=".concat(o, "Channel=").concat(i, "ClientType=").concat(r, "DeviceManufacture=").concat(n, "DeviceModel=").concat(e, "MessageId=").concat(u, "OsVersion=").concat(t, "AppKey=C49E2654AAA94F5085A9C12FE2CAB09CUrl=").concat(s),
d = CryptoJS.MD5(d.replace(/\s*/g, "")).toString().substring(4, 28).toLocaleUpperCase()
}
var o = {
"content-type": "application/json",
"Channel": "bdw",
"AppVersion": "2.3.6",
"BusinessType": 1,
"MessageId": MessageId,
"ClientType": "5",
"OsVersion": "iOS 10.0.1",
"DeviceManufacture": "devtools",
"DeviceModel": "iPhone 5"
}
, i = o.OsVersion
, u = o.DeviceManufacture
, c = o.DeviceModel
, a = o.ClientType
, d = o.AppVersion
, l = o.Channel
, p = o.MessageId
, h = o.Authorization
, g = encodeURIComponent(url.split("betterwood.com")[1].split("?")[0])
, Signature = L(i, u, c, a, d, l, p, h, g);
return {
'Signature': Signature,
'MessageId': MessageId,
}
}import execjs
import requests
# 需要两个参数
# MessageId = ''
# Signature = ''
url = 'https://api.betterwood.com/hotel/brand/museum/list'
# 执行js
with open('./betterwood.js', 'r') as f:
read = f.read()
v = execjs.compile(read).call('get_headers', url)
MessageId = v['MessageId']
Signature = v['Signature']网站:aHR0cDovL2FwcC5taWl0LWVpZGMub3JnLmNuL21paXR4eGdrL2dvbmdnYW8veHhnay9xdWVyeUNwUGFyYW1QYWdlP2RhdGFUYWc9WiZnaWQ9VzAxNDczMDgmcGM9MzIw
使用reres插件进行替换,因为链接是变化的,浏览器不支持正则匹配。
[
{
"req": "http:\\/\\/cstaticdun\\.126\\.net\\/([\\d.]+)\\/core\\.v([\\d.]+)\\.min\\.js\\?v=\\d+",
"res": "file:///.../core.js",
"checked": true
}
]res替换为你实际的代码。
js为ob混淆,需要解码,不然后面调试很麻烦。
pip install ddddocr接口比较多,加密的参数也比较多。d、b接口是用于验证通过后请求页面的cookie的参数(以我自己测试的网站为例)。只请求以下接口即可获取验证结果。
接口: /api/v2/getconf
这个接口获取的是dt参数和acToken,可以直接访问。
{
"data": {
"dt": "QZCRDl9Lpl1BBgQRQAKByyc31aO1bp/J",
"ac": {
// ...
"token": "9ca17ae2e6fecda16ae2e6eeb5cb528ab69db8ea65bcaeaf9ad05b9c94a3a3c434898987d2b25ef4b2a983bb2af0feacc3b92ae2f4ee95a132e29aa3b1cd72abae8cd1d44eb0b7bb82f55bb08fa3afd437fffeb3"
}
}接口 /api/v3/get
接口后缀为get。在开始逆向之前,需要先将core*.js文件保存到本地,然后进行替换,由于链接参数会变,而且文件也会变,请使用正则替换(见1.1)。
在启动器找到core*.js文件,可以看到是webpack打包的,需要将加载器拿出来,再将生成参数所需的方法放到加载器中,之后的参数也是同理。
cb参数在core*.js文件中搜索即可。
// webpack加载器
var loader;
!(function (_0x3b7444) {
function _0x1cb9e6(_0x3fc657) {
if (_0x3669a8[_0x3fc657]) return _0x3669a8[_0x3fc657]["exports"];
var _0xe69548 = _0x3669a8[_0x3fc657] = {
"exports": {},
"id": _0x3fc657,
"loaded": !1
};
return _0x3b7444[_0x3fc657]["call"](_0xe69548["exports"], _0xe69548, _0xe69548["exports"], _0x1cb9e6), _0xe69548["loaded"] = !0, _0xe69548["exports"];
}
var _0x3669a8 = {};
loader = _0x1cb9e6;
}([
// 方法放在这里
])fp参数也可以进行搜索找到,里面是xxx['fingerprint'],再往上是windows['gdxidpyhxde'],hook一下这个变量:
(function() {
// 严谨模式 检查所有错误
'use strict';
// document 为要hook的对象 这里是hook的cookie
var cookieTemp = "";
Object.defineProperty(window, 'gdxidpyhxde', {
// hook set方法也就是赋值的方法
set: function(val) {
// 这样就可以快速给下面这个代码行下断点
// 从而快速定位设置cookie的代码
console.log('Hook捕获到cookie设置->', val);
debugger;
cookieTemp = val;
return val;
},
// hook get 方法也就是取值的方法
get: function()
{
return cookieTemp;
}
});
})();id是固定的值,每个网站都有一个固定的id
dt、acToken来自第一个接口,后面如果有同样的名称均来自这个接口,不再赘述。
{
"bg": [
// 图片,取下来计算距离
"http://necaptcha.nosdn.127.net/[email protected]",
"http://necaptcha1.nosdn.127.net/[email protected]"
],
"front": [
"http://necaptcha.nosdn.127.net/[email protected]",
"http://necaptcha1.nosdn.127.net/[email protected]"
],
// 这个token会用到校验的接口中
"token": "fa1a9c71663e4f1a8acf9ae5b60a085b",
"type": 2,
"zoneId": "CN31"
}数据校验接口,成功会返回validate值。
这个接口主要的参数是data,里面包含了轨迹。
跟栈check接口就可以找到生成位置,直接扣下来即可。
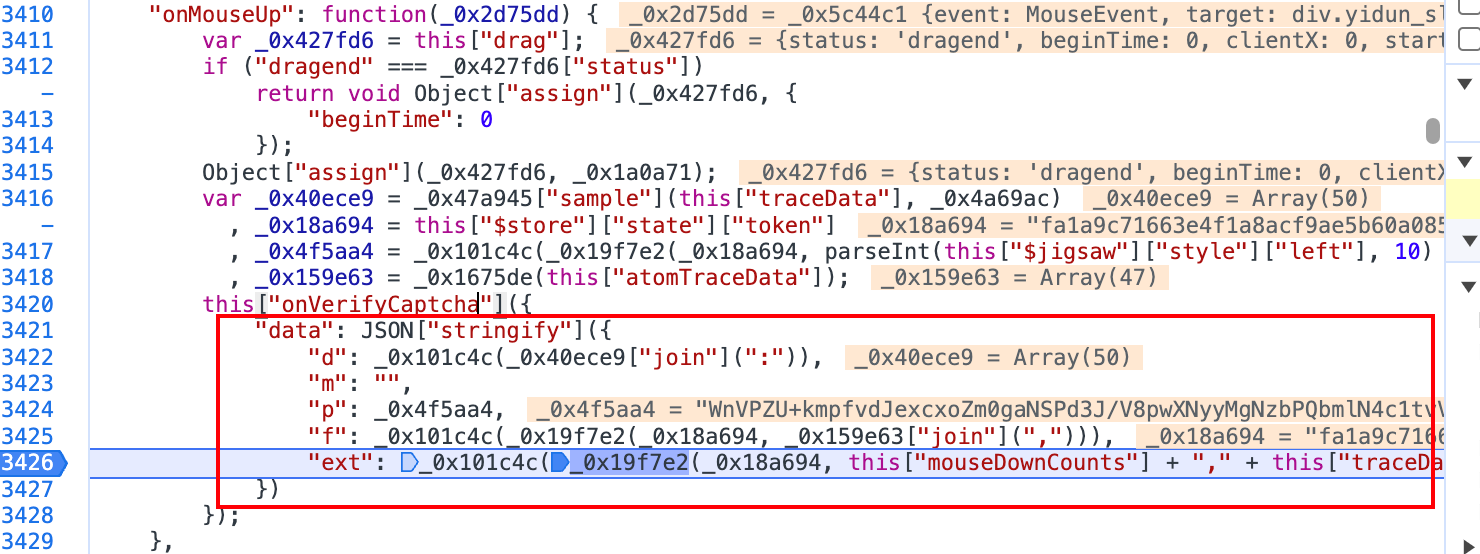
其中,atomTraceData是原始轨迹,tranceData是加密后的轨迹。这些参数最好都打断点看一下,确实生成的是否和网站一致。
来自图片接口返回的token。
如果返回的接口一直是false,大概率是轨迹的问题。
易盾的验证个人感觉还是比较繁琐的,接口、加密参数都比较多,建议看看b站视频和论坛的文档参考。
https://blog.csdn.net/weixin_56199707/article/details/129083704?spm=1001.2014.3001.5502
逆向参数生成,获取price接口数据。
需求是获取商品和价格。
直接搜索,可以看到商品的数据,但是没有价格。
价格应该是另外的接口请求得到的,在接口列表可以看到一个叫price的接口,但是返回的数据是加密的,所有也不确定是不是这个接口(解密后确实是这个接口)。
这个接口的加密参数还是比较多。
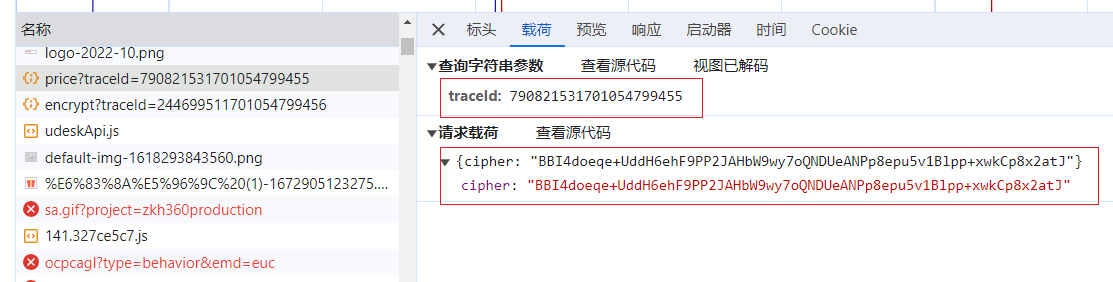
这个是一段随机的字符串,每次请求都会带。同一个接口中需要使用同一个。即如果这个接口里用到了TraceId来加密,请使用同一段字符串。
这个是请求的参数,请求价格的商品id。例如:
["FU8443", "FU8448"]将这段参数加密后就是cipher。
这两个参数的加密位置在一起,就是对类似TraceId或者一些随机字符串加密。需要注意的是加密的方法要和代码里一样,建议使用相同的js包进行加密。
这两个参数通过请求接口获取,用于上述参数的加密,是公钥。
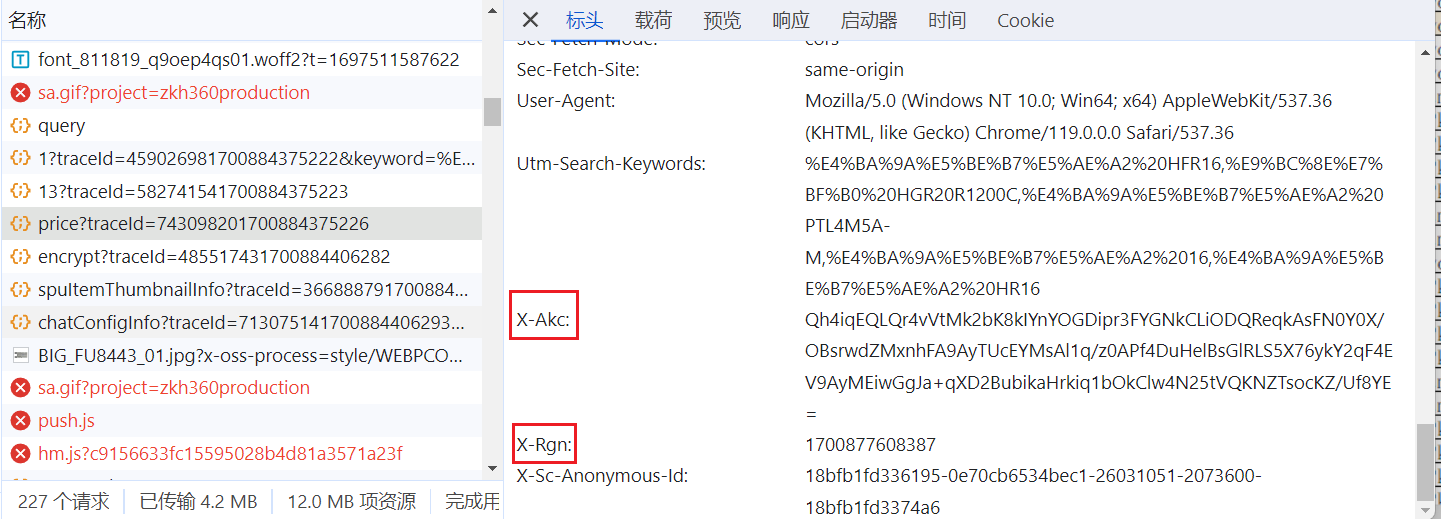
因为是headers里的加密参数,可以**搜索headers["x-akc"]**来查找,如果代码是混淆的,则可以通过hook。这里直接搜索找到了加密的位置。
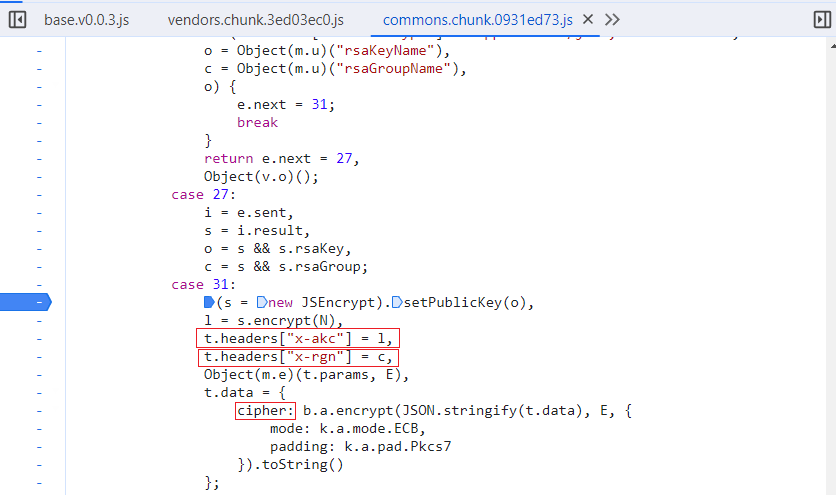
这里可以看到三个加密参数。
这个参数是随机字符串,用以下方法生成即可。
getTraceId = function (e = 8, t = !0) {
var n = ""
, n = Math.ceil(1e14 * Math.random()).toString().substr(0, e || 4);
return t && (n += Date.now()),
n
}x-rgn和x-akc需要先访问rsaKey接口,它会返回rsaKey和rsaGroup。
params = {
'traceId': self.js.call('getTraceId'),
}
response = self.session.get('https://www.zkh.com/zkhweb/zkhAuth/rsaKey', params=params, cookies=cookies,
headers=headers)
return response.json()返回参数:
{
"code": "0000",
"result": {
"rsaKey": "MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQC5Ud0C1rtI80azjpEHF44YJucGSBTGjRGCxqIq2b1IUaZuJU3+psQyL1hgOTxPwHn9d4uRuguLZdf0iGvnWChZSVBqwCKvyBjkUbTKXYYjyHpCHe1iO+F0ITrXZhUbKTmBZz845mjsw1vx5tWqr9zgId6Gdo5hL9vG18V9dQsG0QIDAQAB",
"rsaGroup": 1700884827505
}
}x-rgn参数就是rsaGroup。即上述例子中的“1700884827505”
先看js,需要公钥publicKey,就是2.2.2中请求返回的rsaKey,传入即可。这里它用到了JSEncrypt这个库,在nodejs中下载相同的库使用相同的方法即可。
const jsencrypt = require('jsencrypt')
o = rsaKey
c = rsaGroup
let s = new jsencrypt();
s.setPublicKey(o)
const encryptedData = s.encrypt(N)
const headers = {
'x-akc': encryptedData,
'x-rgn': c.toString()
};这个是难点,因为它用到的b.a.encrypt来自webpack打包的代码,所以需要还原。
这里的k.a可以使用crypto-js包。
// 这里的data是列表,具体请查看1.1.1
cipher: b.a.encrypt(JSON.stringify(t.data), E, {
// mode: k.a.mode.ECB,
// padding: k.a.pad.Pkcs7
mode: crypto_js.mode.ECB,
padding: crypto_js.pad.Pkcs7
}).toString()下一步开始找b.a。代码往上看,可以找到b的定义。
t = n(398), b = n.n(t)就是说b为webpack中索引398的代码。
开始构造,先找到加载器。然后把398位置的代码放进去。加载器在runtime~catalogNew.*.js里。
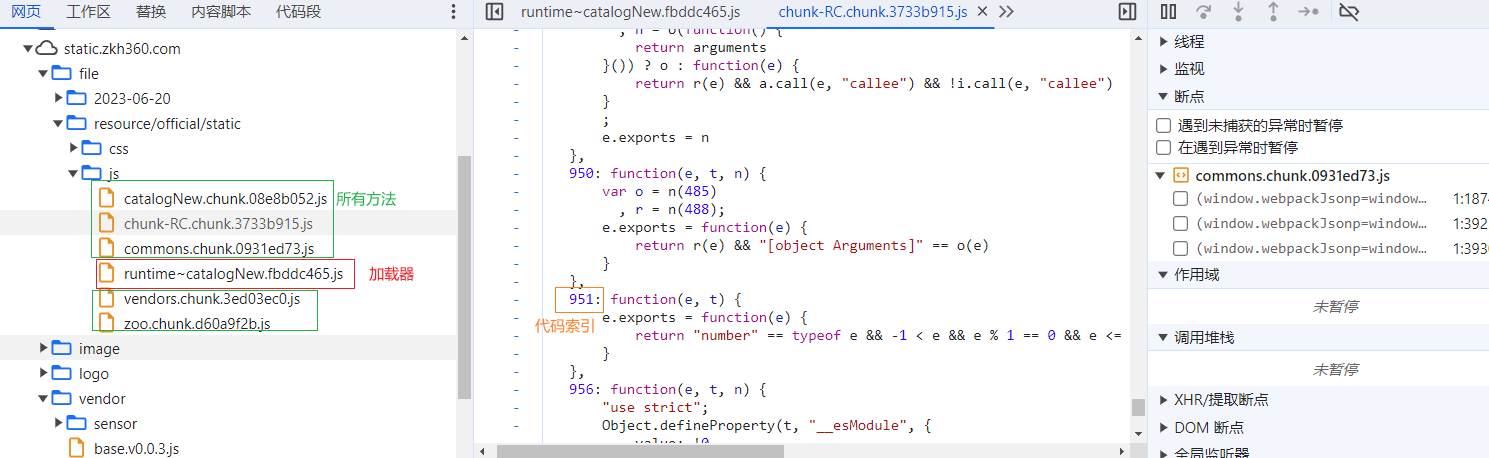
var loader;
!function(l) {
// ...
function i(e) {
var r;
return (t[e] || (r = t[e] = {
i: e,
l: !1,
exports: {}
},
l[e].call(r.exports, r, r.exports, i),
r.l = !0,
r)).exports
}
// ...
//var r = (n = window.webpackJsonp = window.webpackJsonp || []).push.bind(n);
//n.push = e;
//for (var n = n.slice(), o = 0; o < n.length; o++)
// e(n[o]);
//var s = r;
//a()
// 把i定义为全局变量,可以在外部调用
loader = i;
}([
// 这里放代码
398: function(){}
]);398代码中还引用了其他的代码,需要依次导入。另外,部分代码是没有写索引的,需要根据列表中下标的位置判断。例如以下代码,下标是1,因为在数组中1的位置。
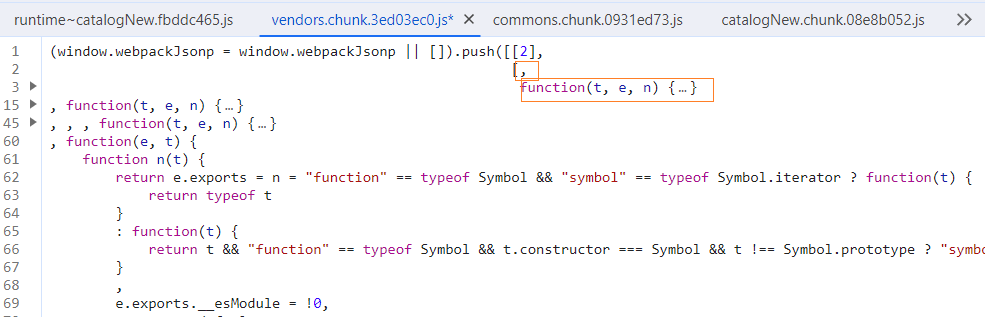
最后使用loader变量加载代码,即可完成这部分加密。
a = loader(398)
let cipher = a.encrypt(JSON.stringify(data), E, {
mode: crypto_js.mode.ECB,
padding: crypto_js.pad.Pkcs7
}).toString()
headers["cipher"] = cipher至此就全部完成了。
TLS指纹是一种用于标识和验证传输层安全性(TLS)连接的方法。TLS是一种用于在网络上加密通信的协议,它的前身是SSL(Secure Sockets Layer)。TLS指纹通常是通过对连接的一些特征信息进行哈希计算而生成的唯一标识。
TLS指纹的主要组成部分包括:
- TLS版本号: 描述使用的TLS协议版本,例如TLS 1.2或TLS 1.3。
- 加密算法: 描述在通信中使用的加密算法,包括对称加密、非对称加密等。
- 密钥长度: 描述使用的加密密钥的长度。
- 哈希算法: 描述用于生成消息摘要的哈希算法。
- 证书信息: 描述服务器的证书,包括颁发机构、有效期等。
TLS指纹的生成过程通常是将上述信息进行哈希计算,以产生一个固定长度的字符串,作为该连接的唯一标识。
目标网站:https://match.yuanrenxue.cn/api/match/19?page=1
{
"status": "1",
"state": "success",
"data": [
{
"value": 7396
},
{
"value": 5018
},
{
"value": 9546
},
{
"value": 4476
},
{
"value": 5297
},
{
"value": 880
},
{
"value": 4644
},
{
"value": 5918
},
{
"value": 3853
},
{
"value": 1572
}
]
}正常返回,使用wireshark查看:
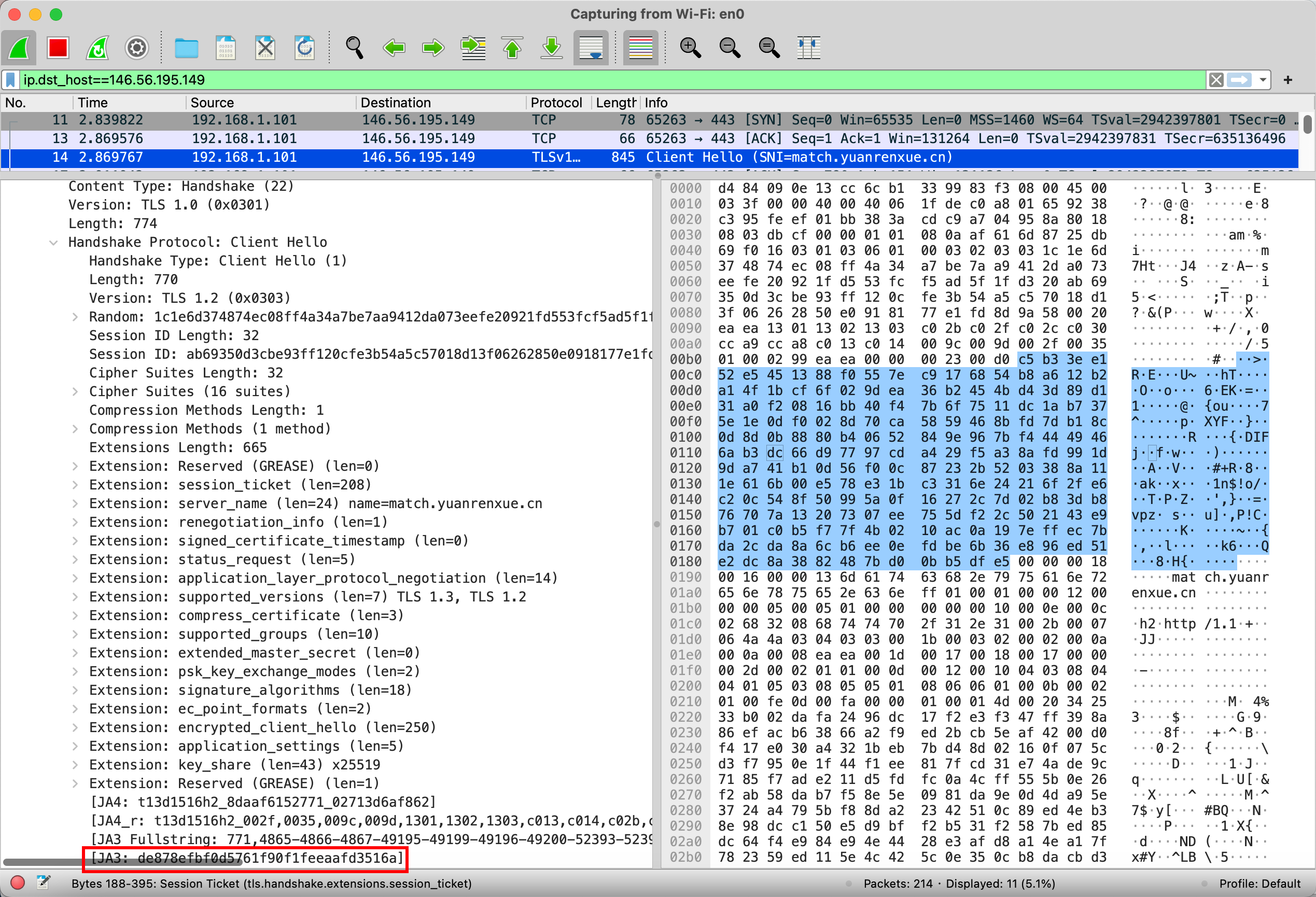
{"status": "0", "error": "page no found"}requests发送的指纹是固定的,请求容易被拦截
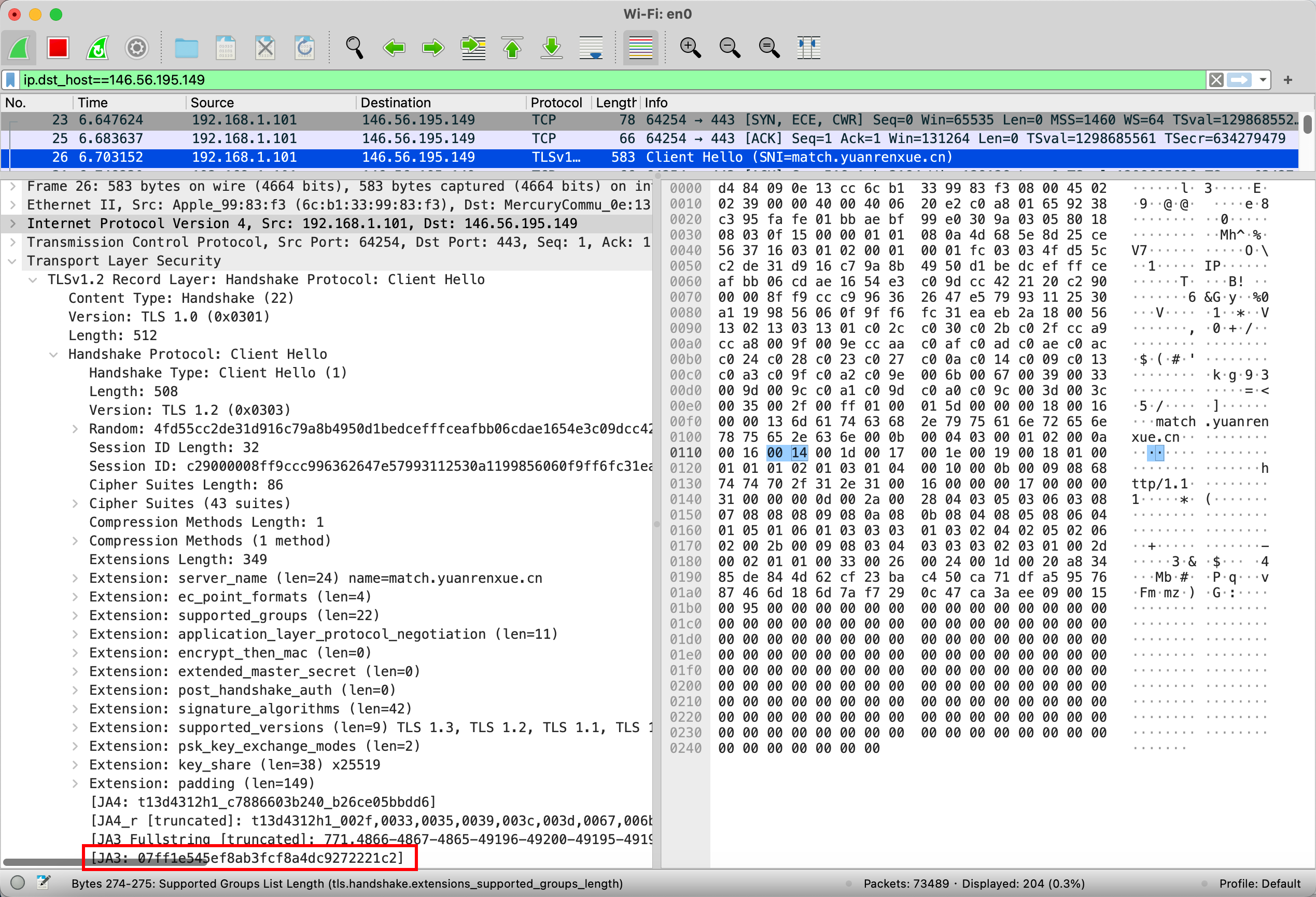
TLS版本号、加密算法、密钥长度、哈希算法、证书信息
JA3 Fullstring:
771,
4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,
35-0-65281-18-5-16-43-27-10-23-45-13-11-65037-17513-51,
29-23-24,
0
根据以上数据md5加密生成
JA3:
de878efbf0d5761f90f1feeaafd3516a
requests底层用urllib3发送请求,urllib3的TLS指纹生成有固定的支持算法,可以通过修改这部份变量,伪造不同的TLS指纹。
import requests
# 0、普通请求
res = requests.get('https://match.yuanrenxue.cn/api/match/19?page=1')
print(res.text) # TLS指纹校验不通过
# 1、修改urllib3源码
import urllib3
urllib3.util.ssl_.DEFAULT_CIPHERS = ":".join(
[
"ECDHE+AESGCM",
"ECDHE+CHACHA20",
"DHE+AESGCM",
"DHE+CHACHA20",
"ECDH+AESGCM",
"DH+AESGCM",
# 修改掉部分内容
# "ECDH+AES",
# "DH+AES",
# "RSA+AESGCM",
# "RSA+AES",
"!aNULL",
"!eNULL",
"!MD5",
"!DSS",
]
)
res = requests.get('https://match.yuanrenxue.cn/api/match/19?page=1')
print(res.text) # 通过底层使用curl工具实现
# 2、用curl_cffi通过验证
from curl_cffi import requests
res = requests.get('https://match.yuanrenxue.cn/api/match/19?page=1', impersonate="chrome110") # 指定生成浏览器指纹
print(res.text) # 通过使用这个库可以指定ja3
package main
import (
"github.com/Danny-Dasilva/CycleTLS/cycletls"
"log"
)
func main() {
cycle := cycletls.Init()
response, err := cycle.Do("https://tls.browserleaks.com/json", cycletls.Options{
Body: "",
// 指定ja3 fullstring
Ja3: "771,4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,17513-65281-11-51-13-5-10-45-27-16-65037-18-0-23-35-43,29-23-24,0",
}, "GET")
if err != nil {
log.Print(err)
}
log.Print(response)
}pip install DrissionPage用自动化的方式绕过反爬,代码非常简单:
from DrissionPage import ChromiumOptions, WebPage
import base64
url = base64.b64decode(b'aHR0cHM6Ly93d3cudXJidGl4LmhrLw==').decode('utf-8')
# 启动并访问网站
co = ChromiumOptions()
page = WebPage(chromium_options=co)
page.get(url)
# 开始监听包含'list?AfbF5fe='的接口
page.listen.start('list?AfbF5fe=')
i = 0
for packet in page.listen.steps():
print(packet.response.body) # body为json格式数据,raw_body可以得到原始数据
# 手动退出
i += 1
if i >= 7:
break
page.close()DrissionPage同样可以使用在其他反爬中,比起selenium,优点在于不需要复杂的配置,安装即用,并且直接获取数据接口,可操作性很高。