
- Background
- Introduction
- Features
- Technical Architecture
- Installation
- Usage Guide
- Documentation System
- Recommendation Algorithm
- Development Plan
- Contributing
- License
OpenChain is an innovative project focused on open source community relationship visualization, developed as an entry for the "OpenRank Cup" Open Source Digital Ecosystem Analysis and Innovation Competition. In today's thriving open source ecosystem, the relationship network between developers and projects is becoming increasingly complex. This project provides deep insights into open source communities through data visualization and intelligent analysis.
OpenChain builds a comprehensive open source community relationship analysis platform based on the OpenDigger toolkit and GitHub API, combined with the Spark Large Language Model. The system mainly focuses on:
- Analysis of inter-project relationships
- Developer interest preference profiling
- Discovery of potential collaboration opportunities
- Technology ecosystem development trend prediction
-
Multi-dimensional Relationship Analysis
- User Relationships: Identify developers with similar tech stacks
- Project Relationships: Explore project dependencies and technical connections
- User-Project Relationships: Precise contribution opportunity recommendations
-
Intelligent Recommendation System
- Project recommendations based on user tech stack
- Contributor recommendations based on project characteristics
- Multi-dimensional similarity calculation and matching
-
Large Model Analysis
- Deep analysis using Spark Large Language Model
- Relationship network interpretation
- Personalized collaboration suggestion generation
-
Interactive Visualization
- Force-directed graph for relationship network display
- Node influence visualization
- Dynamic association strength display
- High-level interaction support
- Next.js 14 - React framework
- TypeScript - Type safety
- D3.js - Data visualization engine
- Tailwind CSS - Styling framework
- Radix UI - Component library
- FastAPI - Python Web framework
- OpenDigger API - Open source data analysis
- GitHub API - Data source
- Spark Large Language Model API - Intelligent analysis
- Python-dotenv - Environment configuration management
- Node.js 18+
- Python 3.8+
- npm or yarn
- Git
- Visit GitHub settings page: https://github.com/settings/tokens
- Generate new access token (classic)
- Configure necessary permissions:
- repo
- read:user
- user:email
- Save the generated token
git clone https://github.com/Frank-whw/OpenChain.git
cd OpenChain# Install dependencies
npm install
# Start development server
npm run dev# Enter backend directory
cd backend
# Install Python dependencies
pip install -r requirements.txt
# Configure environment variables
# Create .env file and add:
GITHUB_TOKEN=your_GitHub_Token
# Start backend service
uvicorn main:app --reloadVisit http://localhost:3000 in your browser
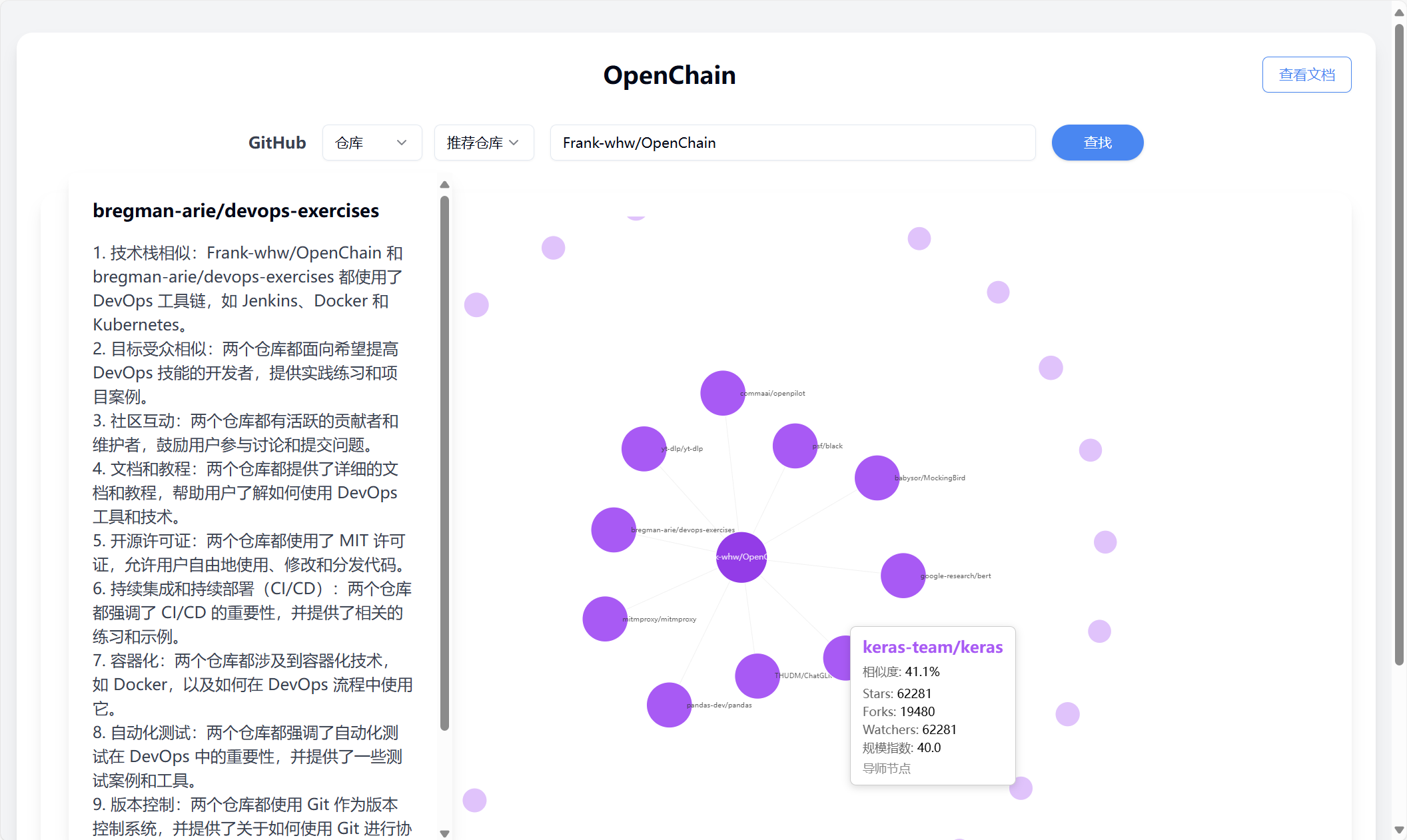
- Analysis type selection (user/repository)
- Search target input
- Visualization result viewing
- Node detail analysis
Type: User
Search: Repository
Input: Frank-whw
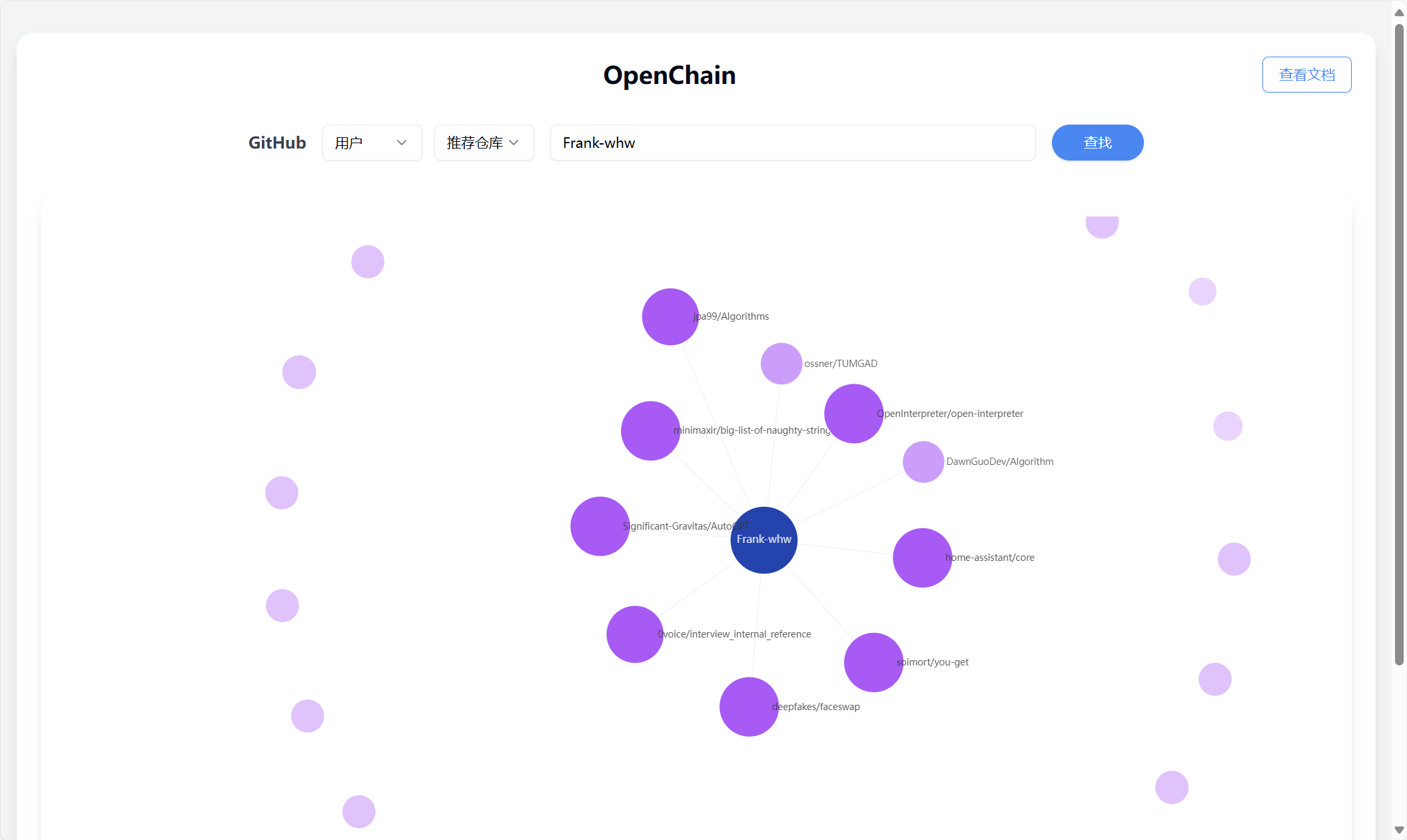
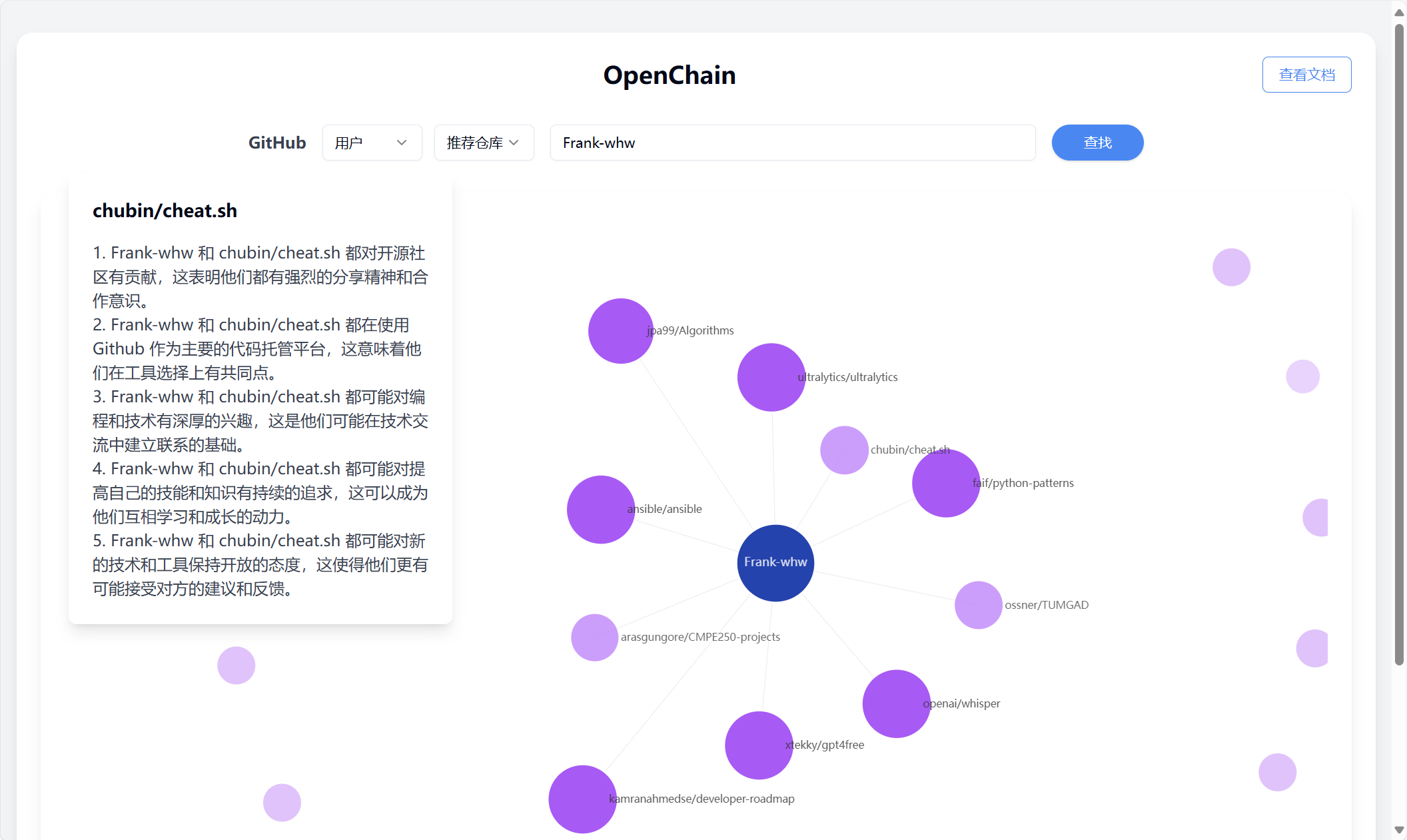
Click on any node except the center node to generate large model analysis results
Type: User
Search: User
Input: Frank-whw
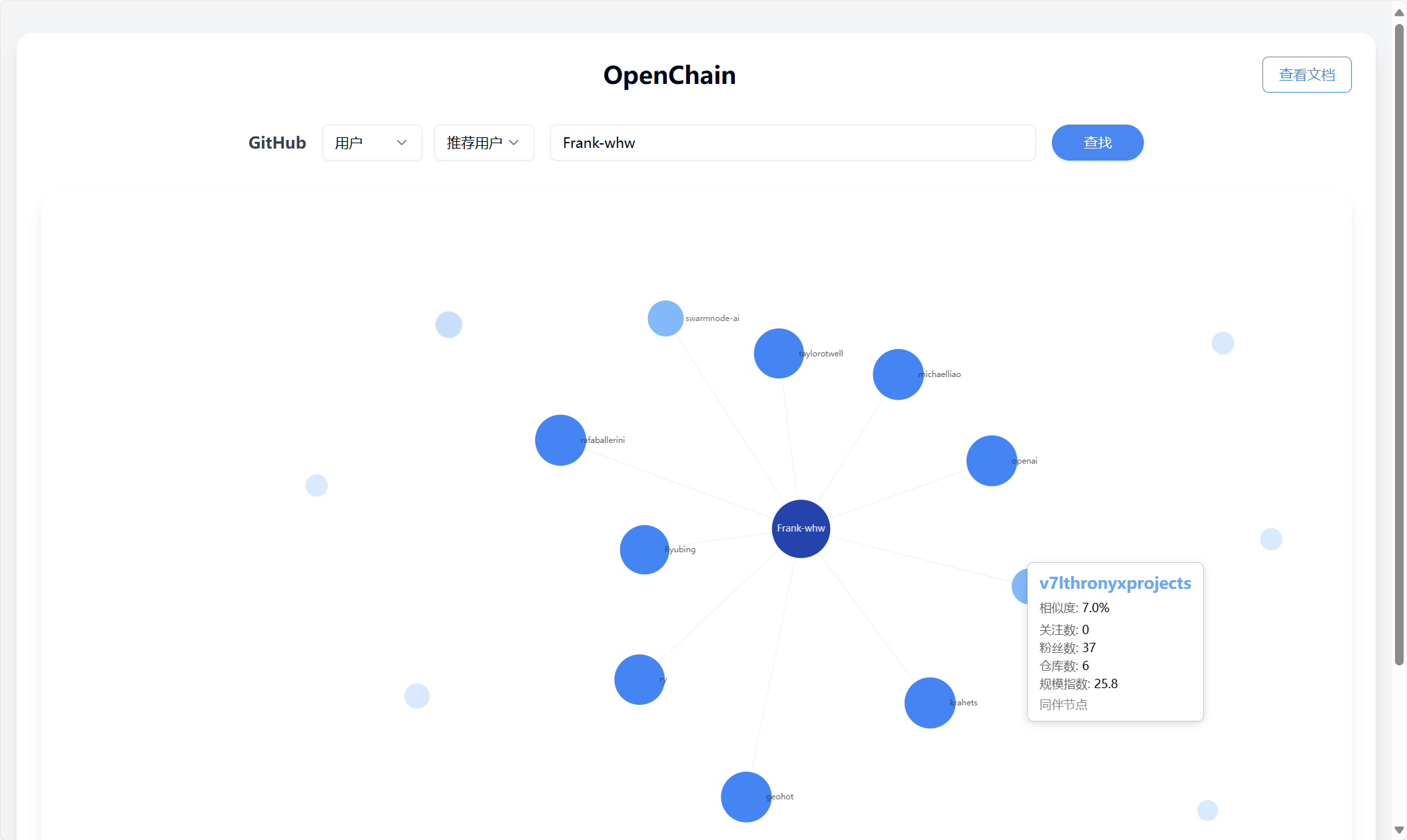
Type: Repository
Search: User
Input: Frank-whw/OpenChain
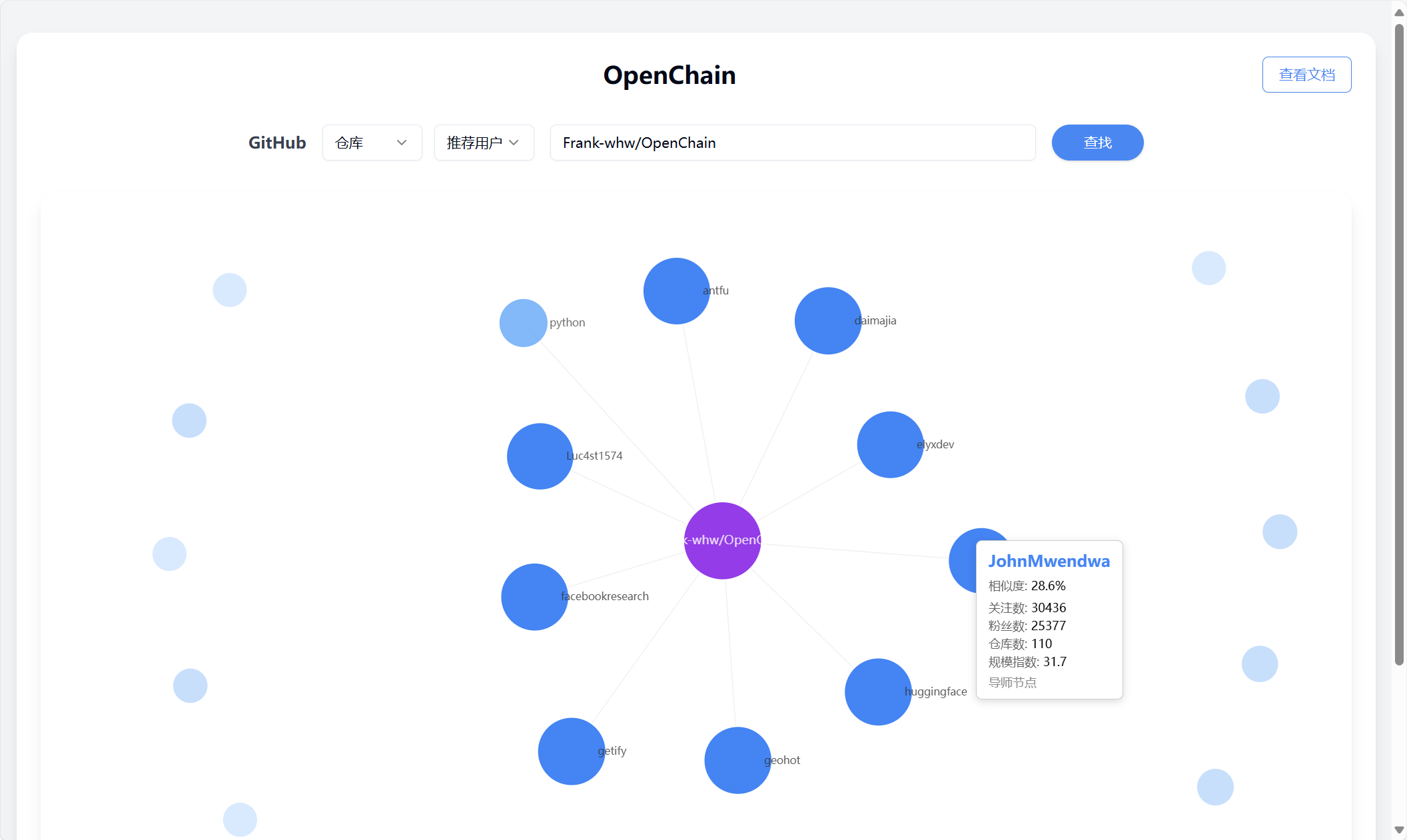
Type: Repository
Search: Repository
Input: Frank-whw/OpenChain
The system provides comprehensive documentation including:
- User similarity calculation methods
- Repository similarity calculation methods
- Recommendation process details
- Node type classification rules
- Node hover effects with detailed information
- Click interaction for AI analysis
- Zoom and pan capabilities
- Dynamic force-directed layout
- Color coding for different node types
- Size variation based on importance
- Connection strength visualization
- Interactive tooltips
The system uses multi-dimensional similarity calculation methods:
- Language preference matching
- Tech stack overlap
- Project scale similarity
- Activity level comparison
- Programming language analysis
- Topic tag matching
- Project scale evaluation
- Functional description similarity
-
Data Collection
- GitHub API data retrieval
- OpenDigger metrics analysis
- User behavior data mining
-
Feature Extraction
- Language preference analysis
- Topic tag extraction
- Activity level calculation
- Scale evaluation
-
Similarity Calculation
- Feature vector construction
- Weighted similarity calculation
- Normalization processing
-
Result Optimization
- Similarity ranking
- Activity level weighting
- TOP-N filtering
- Basic framework setup
- API system implementation
- Visualization engine development
- Large model integration
- Recommendation algorithm optimization
- Visualization enhancement
- User feedback system
Welcome to submit Issues and Pull Requests to participate in project improvement. Before submitting, please ensure:
- Issue description is clear and complete
- Pull Request includes detailed explanation
- Code complies with project standards
- Necessary test cases are provided
This project is licensed under the MIT License