
En este proyecto, nos sumergimos en la evolución constante del rol del Data Scientist al aplicar técnicas avanzadas de gestión de datos, análisis exploratorio y la creación de sistemas de recomendación impulsados por machine learning. Utilizaremos una base de datos proveniente de una plataforma multinacional de videojuegos como punto de partida. Nuestra misión es desentrañar y comprender los patrones y tendencias que gobiernan el comportamiento de los usuarios, lo que nos capacitará para generar recomendaciones altamente personalizadas. Este proyecto abarca todo el ciclo de desarrollo, desde la extracción inicial de los datos hasta la implementación completa del sistema de recomendación. En cada etapa, documentaremos cuidadosamente nuestros pasos y explicaremos de manera transparente las decisiones que respaldan la implementación de nuestro modelo de machine learning. Como culminación, desplegaremos el proyecto como una API virtual en la plataforma en la nube de Render, lo que asegura un acceso sin restricciones a los resultados desde cualquier lugar y dispositivo.
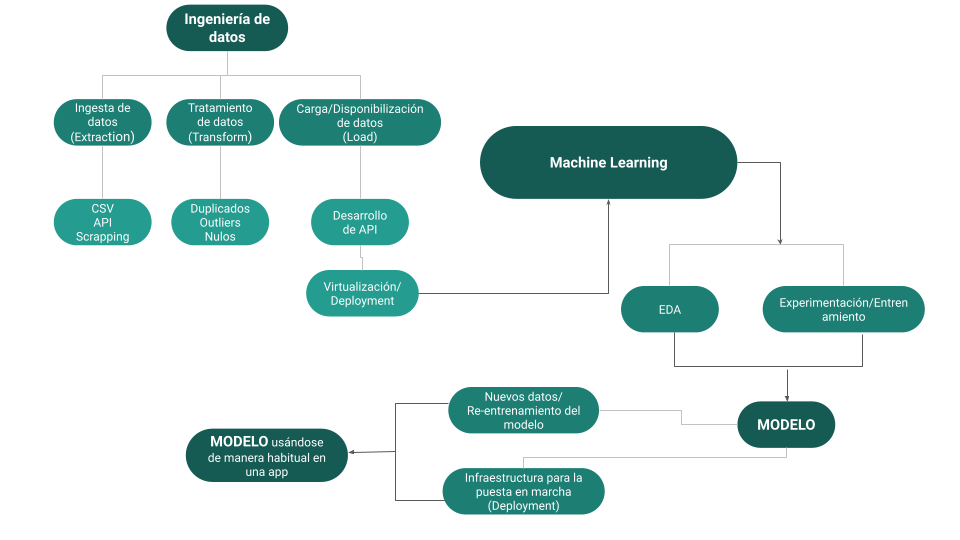
En la fase de Extracción de Datos, procedemos a almacenar objetos JSON de forma individual, abriendo y cargando cada objeto del archivo JSON de manera independiente. Posteriormente, estos objetos JSON se transforman en un DataFrame para su posterior procesamiento.
En esta fase, se ejecutan múltiples acciones para el manejo de los datos, que incluyen la eliminación de valores faltantes, aplanamiento de datos, agrupación de datos, renombrado de columnas y verificación del tamaño del DataFrame. Posteriormente, en la etapa de Imputación de Datos, se recurre a mensajes descriptivos, se imputan valores en columnas de tipo fecha y se verifica la coherencia de los tipos de datos.
Finalmente, se crea una variedad de conjuntos de datos destinados a diversos puntos finales de la API, y estos se almacenan en archivos CSV para su uso posterior.
En las bases de datos generadas se cuenta con las siguientes columnas:
genres: Géneros de videojuegos.sum_playtime_forever: Horas jugadas.anio_released: Año del lanzamiento del videojuego.anio_posted: Año en que se jugó.User_id: Identificador de usuario.app_name: Nombre del contenido.recommend: Tipo de recomendación.sentiment_analysis: Análisis de sentimientos (Negativo=0; Neutral=1; Positivo=2).title: Título del contenido.tags: Etiquetas de contenido.
PlayTimeGenre: Selecciona un género disponible en la plataforma de videojuegos y proporciona el año en el que se registraron más horas de juego en ese género en particular.UserForGenre: Ingresa un género disponible en la plataforma de videojuegos y muestra el usuario que ha acumulado más horas de juego en ese género específico, junto con una lista de la cantidad de horas jugadas por año.UsersRecommend: Ingresa el año de lanzamiento del contenido y proporciona el top 3 de juegos más recomendados por usuarios para ese año en particular.UsersNotRecommend: Ingresa el año en el que se jugó y muestra el top 3 de juegos menos recomendados por los usuarios para ese año específico.sentiment_analysis: Según el año de lanzamiento, genera una lista que muestra la cantidad de registros de reseñas de usuarios categorizados en tres análisis de sentimiento: 0 (Negativo), 1 (Neutral) y 2 (Positivo).recomendacion_juego: Al ingresar el título de un contenido, recibes una lista que contiene 5 juegos recomendados que son similares al que ingresaste.recomendacion_usuario: Al ingresar el ID de un usuario, recibes una lista de 5 juegos recomendados especialmente seleccionados para ese usuario.
Es importante destacar que, en la creación del modelo, se procedió a eliminar los títulos duplicados de los videos juegos con el objetivo de optimizar los recursos computacionales."
Nota: Para acceder a los notebook utilizados para las funciones y el modelo puede ingresar al siguiente enlace de Google Drive: Enlace a los notebook
README.md: Archivo principal con información detallada del proyecto.modelo.ipynb: Contiene todo el desarrollo del modelo de machine learning basado en un sistema de recomendación de videojuegos.ETL_EDA.ipynb: Este conjunto de código engloba las etapas de extracción, transformación y carga de datos, seguidas de un análisis exploratorio exhaustivo. Además, a partir de este análisis se generan varios archivos CSV necesarios para crear los endpoints requeridos en el desarrollo de la API.funciones.ipynb: Este conjunto de funciones ha sido desarrollado para llevar a cabo consultas de búsqueda en el conjunto de datos, asegurando su correcto funcionamiento. Estas funciones serán esenciales para la posterior implementación de los diversos endpoints requeridos en el proyecto.main.py: Este código abarca todos los aspectos necesarios para la creación y el funcionamiento efectivo de la API.requirements.txt: Este archivo incluye las dependencias y bibliotecas necesarias para ejecutar el proyecto de manera adecuada.
Nota: Para acceder a todos los datasets utilizados se puede ingresar al siguiente enlace de Google Drive: Enlace a los Datasets
Para acceder a la API, utiliza los siete endpoints diferentes disponibles para obtener información y realizar consultas sobre videojuegos. Las descripciones en cada una de estas funciones te orientarán en cómo ingresar los datos correspondientes.


Asegúrate de tener instalado lo siguiente:
- Python
- Scikit-Learn
- Pandas
- FastAPI
- Uvicorn
- Pydantic
- Render (Enlace a Render)
En resumen, este proyecto nos ha permitido explorar a fondo el rol en evolución del Data Scientist, y hemos adquirido una comprensión profunda de las técnicas de gestión de datos, análisis exploratorio y la creación de sistemas de recomendación basados en machine learning. Hemos utilizado una base de datos de una plataforma multinacional de videojuegos para desvelar valiosos patrones de comportamiento de los usuarios. A lo largo del ciclo de desarrollo, hemos documentado meticulosamente nuestras acciones y explicado nuestras decisiones en la implementación del modelo. Finalmente, al desplegar el proyecto como una API en la nube, hemos garantizado la accesibilidad y utilidad de nuestros resultados. En conjunto, esta experiencia nos ha proporcionado conocimientos sólidos en el manejo y análisis de datos en el contexto de las plataformas de entretenimiento digital, así como en la implementación exitosa de soluciones en la nube.
Elaborado por: Marianela Garcia
Correo Electrónico: [email protected]