






👋 join us on 𝕏 (Twitter), Discord and WeChat
Install from source:
git clone https://github.com/InternLM/lagent.git
cd lagent
pip install -e .Lagent is inspired by the design philosophy of PyTorch. We expect that the analogy of neural network layers will make the workflow clearer and more intuitive, so users only need to focus on creating layers and defining message passing between them in a Pythonic way. This is a simple tutorial to get you quickly started with building multi-agent applications.
Agents use AgentMessage for communication.
from typing import Dict, List
from lagent.agents import Agent
from lagent.schema import AgentMessage
from lagent.llms import VllmModel, INTERNLM2_META
llm = VllmModel(
path='Qwen/Qwen2-7B-Instruct',
meta_template=INTERNLM2_META,
tp=1,
top_k=1,
temperature=1.0,
stop_words=['<|im_end|>'],
max_new_tokens=1024,
)
system_prompt = '你的回答只能从“典”、“孝”、“急”三个字中选一个。'
agent = Agent(llm, system_prompt)
user_msg = AgentMessage(sender='user', content='今天天气情况')
bot_msg = agent(user_msg)
print(bot_msg)content='急' sender='Agent' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
Both input and output messages will be added to the memory of Agent in each forward pass. This is performed in __call__ rather than forward. See the following pseudo code
def __call__(self, *message):
message = pre_hooks(message)
add_memory(message)
message = self.forward(*message)
add_memory(message)
message = post_hooks(message)
return messageInspect the memory in two ways
memory: List[AgentMessage] = agent.memory.get_memory()
print(memory)
print('-' * 120)
dumped_memory: Dict[str, List[dict]] = agent.state_dict()
print(dumped_memory['memory'])[AgentMessage(content='今天天气情况', sender='user', formatted=None, extra_info=None, type=None, receiver=None, stream_state=<AgentStatusCode.END: 0>), AgentMessage(content='急', sender='Agent', formatted=None, extra_info=None, type=None, receiver=None, stream_state=<AgentStatusCode.END: 0>)]
------------------------------------------------------------------------------------------------------------------------
[{'content': '今天天气情况', 'sender': 'user', 'formatted': None, 'extra_info': None, 'type': None, 'receiver': None, 'stream_state': <AgentStatusCode.END: 0>}, {'content': '急', 'sender': 'Agent', 'formatted': None, 'extra_info': None, 'type': None, 'receiver': None, 'stream_state': <AgentStatusCode.END: 0>}]
Clear the memory of this session(session_id=0 by default):
agent.reset()DefaultAggregator is called under the hood to assemble and convert AgentMessage to OpenAI message format.
def forward(self, *message: AgentMessage, session_id=0, **kwargs) -> Union[AgentMessage, str]:
formatted_messages = self.aggregator.aggregate(
self.memory.get(session_id),
self.name,
self.output_format,
self.template,
)
llm_response = self.llm.chat(formatted_messages, **kwargs)
...Implement a simple aggregator that can receive few-shots
from typing import List, Union
from lagent.memory import Memory
from lagent.prompts import StrParser
from lagent.agents.aggregator import DefaultAggregator
class FewshotAggregator(DefaultAggregator):
def __init__(self, few_shot: List[dict] = None):
self.few_shot = few_shot or []
def aggregate(self,
messages: Memory,
name: str,
parser: StrParser = None,
system_instruction: Union[str, dict, List[dict]] = None) -> List[dict]:
_message = []
if system_instruction:
_message.extend(
self.aggregate_system_intruction(system_instruction))
_message.extend(self.few_shot)
messages = messages.get_memory()
for message in messages:
if message.sender == name:
_message.append(
dict(role='assistant', content=str(message.content)))
else:
user_message = message.content
if len(_message) > 0 and _message[-1]['role'] == 'user':
_message[-1]['content'] += user_message
else:
_message.append(dict(role='user', content=user_message))
return _message
agent = Agent(
llm,
aggregator=FewshotAggregator(
[
{"role": "user", "content": "今天天气"},
{"role": "assistant", "content": "【晴】"},
]
)
)
user_msg = AgentMessage(sender='user', content='昨天天气')
bot_msg = agent(user_msg)
print(bot_msg)content='【多云转晴,夜间有轻微降温】' sender='Agent' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
In AgentMessage, formatted is reserved to store information parsed by output_format from the model output.
def forward(self, *message: AgentMessage, session_id=0, **kwargs) -> Union[AgentMessage, str]:
...
llm_response = self.llm.chat(formatted_messages, **kwargs)
if self.output_format:
formatted_messages = self.output_format.parse_response(llm_response)
return AgentMessage(
sender=self.name,
content=llm_response,
formatted=formatted_messages,
)
...Use a tool parser as follows
from lagent.prompts.parsers import ToolParser
system_prompt = "逐步分析并编写Python代码解决以下问题。"
parser = ToolParser(tool_type='code interpreter', begin='```python\n', end='\n```\n')
llm.gen_params['stop_words'].append('\n```\n')
agent = Agent(llm, system_prompt, output_format=parser)
user_msg = AgentMessage(
sender='user',
content='Marie is thinking of a multiple of 63, while Jay is thinking of a '
'factor of 63. They happen to be thinking of the same number. There are '
'two possibilities for the number that each of them is thinking of, one '
'positive and one negative. Find the product of these two numbers.')
bot_msg = agent(user_msg)
print(bot_msg.model_dump_json(indent=4)){
"content": "首先,我们需要找出63的所有正因数和负因数。63的正因数可以通过分解63的质因数来找出,即\\(63 = 3^2 \\times 7\\)。因此,63的正因数包括1, 3, 7, 9, 21, 和 63。对于负因数,我们只需将上述正因数乘以-1。\n\n接下来,我们需要找出与63的正因数相乘的结果为63的数,以及与63的负因数相乘的结果为63的数。这可以通过将63除以每个正因数和负因数来实现。\n\n最后,我们将找到的两个数相乘得到最终答案。\n\n下面是Python代码实现:\n\n```python\ndef find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)",
"sender": "Agent",
"formatted": {
"tool_type": "code interpreter",
"thought": "首先,我们需要找出63的所有正因数和负因数。63的正因数可以通过分解63的质因数来找出,即\\(63 = 3^2 \\times 7\\)。因此,63的正因数包括1, 3, 7, 9, 21, 和 63。对于负因数,我们只需将上述正因数乘以-1。\n\n接下来,我们需要找出与63的正因数相乘的结果为63的数,以及与63的负因数相乘的结果为63的数。这可以通过将63除以每个正因数和负因数来实现。\n\n最后,我们将找到的两个数相乘得到最终答案。\n\n下面是Python代码实现:\n\n",
"action": "def find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)",
"status": 1
},
"extra_info": null,
"type": null,
"receiver": null,
"stream_state": 0
}
ActionExecutor uses the same communication data structure as Agent, but requires the content of input AgentMessage to be a dict containing:
name: tool name, e.g.'IPythonInterpreter','WebBrowser.search'.parameters: keyword arguments of the tool API, e.g.{'command': 'import math;math.sqrt(2)'},{'query': ['recent progress in AI']}.
You can register custom hooks for message conversion.
from lagent.hooks import Hook
from lagent.schema import ActionReturn, ActionStatusCode, AgentMessage
from lagent.actions import ActionExecutor, IPythonInteractive
class CodeProcessor(Hook):
def before_action(self, executor, message, session_id):
message = message.copy(deep=True)
message.content = dict(
name='IPythonInteractive', parameters={'command': message.formatted['action']}
)
return message
def after_action(self, executor, message, session_id):
action_return = message.content
if isinstance(action_return, ActionReturn):
if action_return.state == ActionStatusCode.SUCCESS:
response = action_return.format_result()
else:
response = action_return.errmsg
else:
response = action_return
message.content = response
return message
executor = ActionExecutor(actions=[IPythonInteractive()], hooks=[CodeProcessor()])
bot_msg = AgentMessage(
sender='Agent',
content='首先,我们需要...',
formatted={
'tool_type': 'code interpreter',
'thought': '首先,我们需要...',
'action': 'def find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)',
'status': 1
})
executor_msg = executor(bot_msg)
print(executor_msg)content='3969.0' sender='ActionExecutor' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
For convenience, Lagent provides InternLMActionProcessor which is adapted to messages formatted by ToolParser as mentioned above.
Lagent adopts dual interface design, where almost every component(LLMs, actions, action executors...) has the corresponding asynchronous variant by prefixing its identifier with 'Async'. It is recommended to use synchronous agents for debugging and asynchronous ones for large-scale inference to make the most of idle CPU and GPU resources.
However, make sure the internal consistency of agents, i.e. asynchronous agents should be equipped with asynchronous LLMs and asynchronous action executors that drive asynchronous tools.
from lagent.llms import VllmModel, AsyncVllmModel, LMDeployPipeline, AsyncLMDeployPipeline
from lagent.actions import ActionExecutor, AsyncActionExecutor, WebBrowser, AsyncWebBrowser
from lagent.agents import Agent, AsyncAgent, AgentForInternLM, AsyncAgentForInternLM- Try to implement
forwardinstead of__call__of subclasses unless necessary. - Always include the
session_idargument explicitly, which is designed for isolation of memory, LLM requests and tool invocation(e.g. maintain multiple independent IPython environments) in concurrency.
Math agents that solve problems by programming
from lagent.agents.aggregator import InternLMToolAggregator
class Coder(Agent):
def __init__(self, model_path, system_prompt, max_turn=3):
super().__init__()
llm = VllmModel(
path=model_path,
meta_template=INTERNLM2_META,
tp=1,
top_k=1,
temperature=1.0,
stop_words=['\n```\n', '<|im_end|>'],
max_new_tokens=1024,
)
self.agent = Agent(
llm,
system_prompt,
output_format=ToolParser(
tool_type='code interpreter', begin='```python\n', end='\n```\n'
),
# `InternLMToolAggregator` is adapted to `ToolParser` for aggregating
# messages with tool invocations and execution results
aggregator=InternLMToolAggregator(),
)
self.executor = ActionExecutor([IPythonInteractive()], hooks=[CodeProcessor()])
self.max_turn = max_turn
def forward(self, message: AgentMessage, session_id=0) -> AgentMessage:
for _ in range(self.max_turn):
message = self.agent(message, session_id=session_id)
if message.formatted['tool_type'] is None:
return message
message = self.executor(message, session_id=session_id)
return message
coder = Coder('Qwen/Qwen2-7B-Instruct', 'Solve the problem step by step with assistance of Python code')
query = AgentMessage(
sender='user',
content='Find the projection of $\\mathbf{a}$ onto $\\mathbf{b} = '
'\\begin{pmatrix} 1 \\\\ -3 \\end{pmatrix}$ if $\\mathbf{a} \\cdot \\mathbf{b} = 2.$'
)
answer = coder(query)
print(answer.content)
print('-' * 120)
for msg in coder.state_dict()['agent.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')Asynchronous blogging agents that improve writing quality by self-refinement (original AutoGen example)
import asyncio
import os
from lagent.llms import AsyncGPTAPI
from lagent.agents import AsyncAgent
os.environ['OPENAI_API_KEY'] = 'YOUR_API_KEY'
class PrefixedMessageHook(Hook):
def __init__(self, prefix: str, senders: list = None):
self.prefix = prefix
self.senders = senders or []
def before_agent(self, agent, messages, session_id):
for message in messages:
if message.sender in self.senders:
message.content = self.prefix + message.content
class AsyncBlogger(AsyncAgent):
def __init__(self, model_path, writer_prompt, critic_prompt, critic_prefix='', max_turn=3):
super().__init__()
llm = AsyncGPTAPI(model_type=model_path, retry=5, max_new_tokens=2048)
self.writer = AsyncAgent(llm, writer_prompt, name='writer')
self.critic = AsyncAgent(
llm, critic_prompt, name='critic', hooks=[PrefixedMessageHook(critic_prefix, ['writer'])]
)
self.max_turn = max_turn
async def forward(self, message: AgentMessage, session_id=0) -> AgentMessage:
for _ in range(self.max_turn):
message = await self.writer(message, session_id=session_id)
message = await self.critic(message, session_id=session_id)
return await self.writer(message, session_id=session_id)
blogger = AsyncBlogger(
'gpt-4o-2024-05-13',
writer_prompt="You are an writing assistant tasked to write engaging blogpost. You try to generate the best blogpost possible for the user's request. "
"If the user provides critique, then respond with a revised version of your previous attempts",
critic_prompt="Generate critique and recommendations on the writing. Provide detailed recommendations, including requests for length, depth, style, etc..",
critic_prefix='Reflect and provide critique on the following writing. \n\n',
)
user_prompt = (
"Write an engaging blogpost on the recent updates in {topic}. "
"The blogpost should be engaging and understandable for general audience. "
"Should have more than 3 paragraphes but no longer than 1000 words.")
bot_msgs = asyncio.get_event_loop().run_until_complete(
asyncio.gather(
*[
blogger(AgentMessage(sender='user', content=user_prompt.format(topic=topic)), session_id=i)
for i, topic in enumerate(['AI', 'Biotechnology', 'New Energy', 'Video Games', 'Pop Music'])
]
)
)
print(bot_msgs[0].content)
print('-' * 120)
for msg in blogger.state_dict(session_id=0)['writer.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')
print('-' * 120)
for msg in blogger.state_dict(session_id=0)['critic.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')A multi-agent workflow that performs information retrieval, data collection and chart plotting (original LangGraph example)
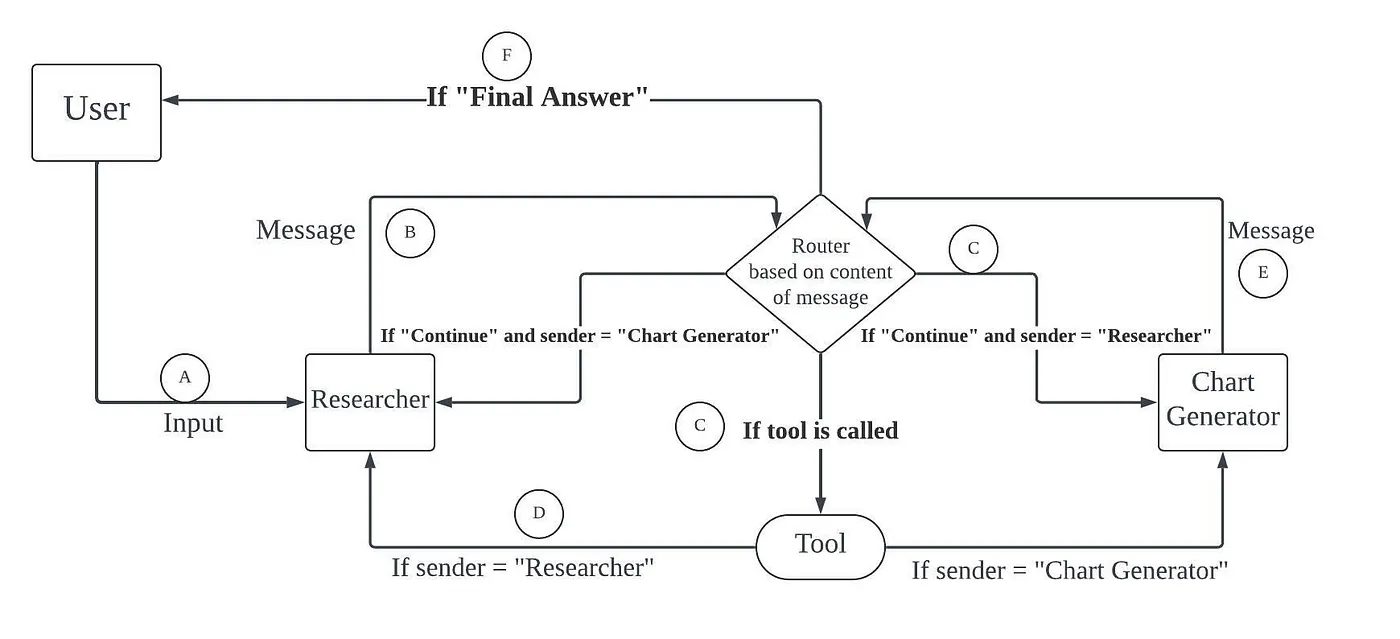
import json
from lagent.actions import IPythonInterpreter, WebBrowser, ActionExecutor
from lagent.agents.stream import get_plugin_prompt
from lagent.llms import GPTAPI
from lagent.hooks import InternLMActionProcessor
TOOL_TEMPLATE = (
"You are a helpful AI assistant, collaborating with other assistants. Use the provided tools to progress"
" towards answering the question. If you are unable to fully answer, that's OK, another assistant with"
" different tools will help where you left off. Execute what you can to make progress. If you or any of"
" the other assistants have the final answer or deliverable, prefix your response with {finish_pattern}"
" so the team knows to stop. You have access to the following tools:\n{tool_description}\nPlease provide"
" your thought process when you need to use a tool, followed by the call statement in this format:"
"\n{invocation_format}\\\\n**{system_prompt}**"
)
class DataVisualizer(Agent):
def __init__(self, model_path, research_prompt, chart_prompt, finish_pattern="Final Answer", max_turn=10):
super().__init__()
llm = GPTAPI(model_path, key='YOUR_OPENAI_API_KEY', retry=5, max_new_tokens=1024, stop_words=["```\n"])
interpreter, browser = IPythonInterpreter(), WebBrowser("BingSearch", api_key="YOUR_BING_API_KEY")
self.researcher = Agent(
llm,
TOOL_TEMPLATE.format(
finish_pattern=finish_pattern,
tool_description=get_plugin_prompt(browser),
invocation_format='```json\n{"name": {{tool name}}, "parameters": {{keyword arguments}}}\n```\n',
system_prompt=research_prompt,
),
output_format=ToolParser(
"browser",
begin="```json\n",
end="\n```\n",
validate=lambda x: json.loads(x.rstrip('`')),
),
aggregator=InternLMToolAggregator(),
name="researcher",
)
self.charter = Agent(
llm,
TOOL_TEMPLATE.format(
finish_pattern=finish_pattern,
tool_description=interpreter.name,
invocation_format='```python\n{{code}}\n```\n',
system_prompt=chart_prompt,
),
output_format=ToolParser(
"interpreter",
begin="```python\n",
end="\n```\n",
validate=lambda x: x.rstrip('`'),
),
aggregator=InternLMToolAggregator(),
name="charter",
)
self.executor = ActionExecutor([interpreter, browser], hooks=[InternLMActionProcessor()])
self.finish_pattern = finish_pattern
self.max_turn = max_turn
def forward(self, message, session_id=0):
for _ in range(self.max_turn):
message = self.researcher(message, session_id=session_id, stop_words=["```\n", "```python"]) # override llm stop words
while message.formatted["tool_type"]:
message = self.executor(message, session_id=session_id)
message = self.researcher(message, session_id=session_id, stop_words=["```\n", "```python"])
if self.finish_pattern in message.content:
return message
message = self.charter(message)
while message.formatted["tool_type"]:
message = self.executor(message, session_id=session_id)
message = self.charter(message, session_id=session_id)
if self.finish_pattern in message.content:
return message
return message
visualizer = DataVisualizer(
"gpt-4o-2024-05-13",
research_prompt="You should provide accurate data for the chart generator to use.",
chart_prompt="Any charts you display will be visible by the user.",
)
user_msg = AgentMessage(
sender='user',
content="Fetch the China's GDP over the past 5 years, then draw a line graph of it. Once you code it up, finish.")
bot_msg = visualizer(user_msg)
print(bot_msg.content)
json.dump(visualizer.state_dict(), open('visualizer.json', 'w'), ensure_ascii=False, indent=4)If you find this project useful in your research, please consider cite:
@misc{lagent2023,
title={{Lagent: InternLM} a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents},
author={Lagent Developer Team},
howpublished = {\url{https://github.com/InternLM/lagent}},
year={2023}
}This project is released under the Apache 2.0 license.