We put forward several techniques and guidelines for the application of (amortized) neural simulation-based inference to scientific problems. In this work we examine the relation between dark matter subhalo impacts and the observed stellar density variations in the GD-1 stellar stream to differentiate between Warm Dark Matter and Cold Dark Matter.
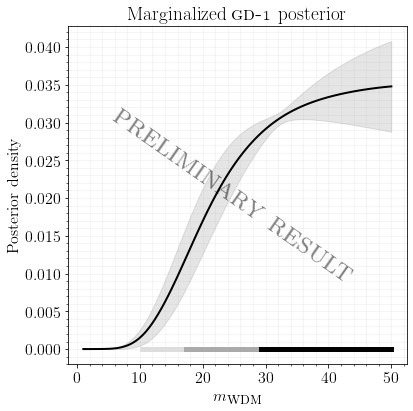
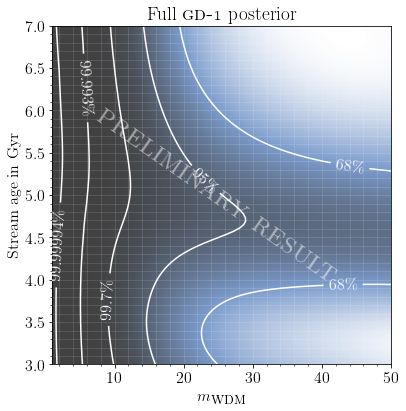
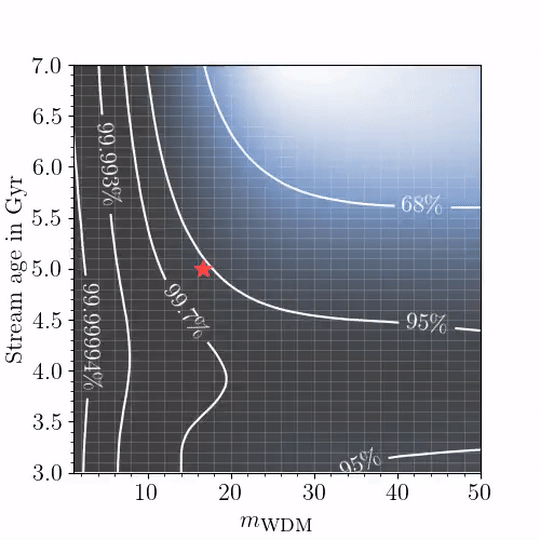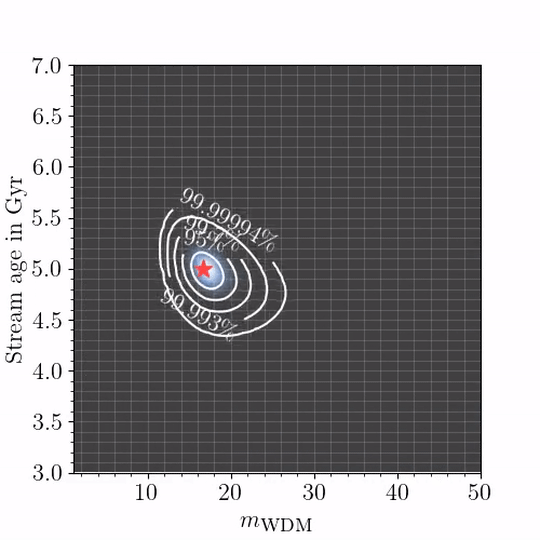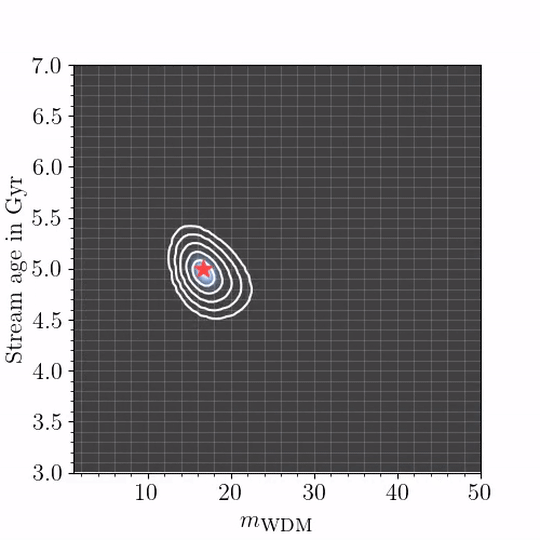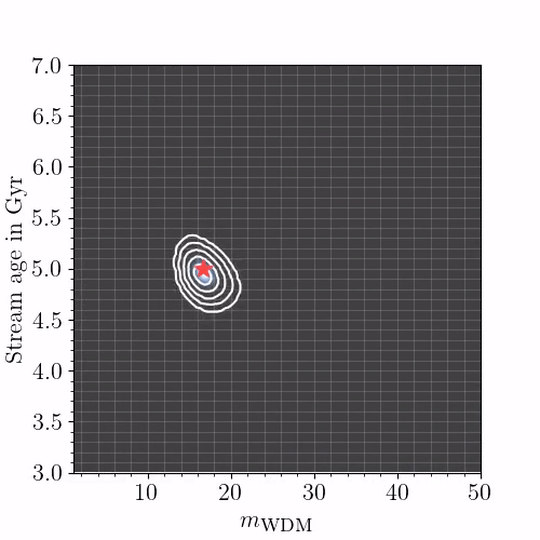
Disclaimer: Baryonic effects are not accounted for, see paper for details.
This repository contains the code to reproduce this work on a Slurm enabled HPC cluster or on your local machine.
The Slurm arguments you typically use in your batch submission scripts will flawlessly run on your development machine without actually requiring or installing Slurm binaries. Futhermore, our scripts will automatically manage the Anaconda environment related to this work.
- Demonstration notebooks
- Requirements
- Datasets and models
- Usage
- Pipelines
- Notebooks
- Manuscripts
- Citing
Note. If you are viewing this notebook right after release, it might be possible that the Binder links do no work yet. We are actively solving this!
In addition to the code related to the contents of this paper, we provide several demonstration notebooks to familiarize yourself with simulation-based inference.
| Short description | Render | Binder |
|---|---|---|
| Overview notebook with presimulated data and pretrained models | [view] | |
| Toy problem to demonstrate the technique | [view] | |
| Out-of-distribution or model misspecification detection | [view] | |
| Changing the implicit prior of the ratio estimator through MCMC | [view] |
Required. The project assumes you have a working Anaconda installation.
In order to execute this project, you need at least 40 GB of available storage space. We do not recommend to run the simulations on a single machine, as this would take about 60 years to complete. On a HPC cluster, the simulations will take about 2-3 weeks. Training all ratio estimators will take 1-2 days depending on the availability of GPU's. Diagnostics another day.
you@localhost:~ $ wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
you@localhost:~ $ sh Miniconda3-latest-Linux-x86_64.shThe corresponding environment can be installed by executing
you@localhost:~ $ sh scripts/install.shin the root directory of the project. This will install several dependencies in a certain order due to some quirks in Anaconda.
The required computational resources mentioned above might not be available to everyone. As such, the presimulated datasets and pretrained models can be made available on request by e-mailing [email protected], or by opening an issue in this GitHub repository.
Simply execute ./run.sh -h to display all available options or./run.sh to install the Anaconda environment and dependencies related to this project.
A specific set of experiments can be executed by supplying a comma-seperated list.
you@localhost:~ $ bash run.sh -e simulations,inferenceIf you update the environment.yml file by adding or removing dependencies, please run bash run.sh -i first. The script will automatically synchronize the changes with the Anaconda environment associated to this project.
This section gives a quick overview of our results.
A link to a detailed description of every experiment is listed. As described in the usage section, the identifier plays an important roll if the developer or end-user wishes to execute a subset of pipelines (experiments).
| Identifier | Short description | Link |
|---|---|---|
| inference | Analyses and plots. | [details] |
| simulations | A pipeline for simulating the datasets and GD-1 mocks. | [details] |
Overview of a non-exclusive list of interesting notebooks in this repository, not included in the main paper.
| Short description | Render |
|---|---|
| In this notebook we explore in a ad-hoc fashion how the neural network uses the high-level features in a stellar stream to differentiate between CDM and WDM. | [view] |
The preprint is available at manuscript/preprint/main.pdf.
Our NeurIPS submission can be found at manuscript/neurips/main.pdf.
If you use our code or methodology, please cite our paper
TODO
and the original method paper published at ICML2020
@ARTICLE{hermansSBI,
author = {{Hermans}, Joeri and {Begy}, Volodimir and {Louppe}, Gilles},
title = "{Likelihood-free MCMC with Amortized Approximate Ratio Estimators}",
journal = {arXiv e-prints},
keywords = {Statistics - Machine Learning, Computer Science - Machine Learning},
year = "2019",
month = "Mar",
eid = {arXiv:1903.04057},
pages = {arXiv:1903.04057},
archivePrefix = {arXiv},
eprint = {1903.04057},
primaryClass = {stat.ML},
adsurl = {https://ui.adsabs.harvard.edu/abs/2019arXiv190304057H},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}