Streamlit visualizations, improved T5, models for Farsi, Hebrew, Korean, Turkish and UMLS, LOINC, HPO, Resolvers in NLU 3.0.2
This release contains examples and tutorials on how to visualize the 1000+ state-of-the-art NLP models provided by NLU in just 1 line of code in streamlit.
It includes simple 1-liners you can sprinkle into your Streamlit app to for features like Dependency Trees, Named Entities (NER), text classification results, semantic simmilarity,
embedding visualizations via ELMO, BERT, ALBERT, XLNET and much more . Additionally, improvements for T5, various resolvers have been added and models Farsi, Hebrew, Korean, and Turkish
This is the ultimate NLP research tool. You can visualize and compare the results of hundreds of context aware deep learning embeddings and compare them with classical vanilla embeddings like Glove
and can see with your own eyes how context is encoded by transformer models like BERT or XLNETand many more !
Besides that, you can also compare the results of the 200+ NER models John Snow Labs provides and see how peformances changes with varrying ebeddings, like Contextual, Static and Domain Specific Embeddings.
Install
For detailed instructions refer to the NLU install documentation here
You need Open JDK 8 installed and the following python packages
pip install nlu streamlit pyspark==3.0.1 sklearn plotly Problems? Connect with us on Slack!
Impatient and want some action?
Just run this Streamlit app, you can use it to generate python code for each NLU-Streamlit building block
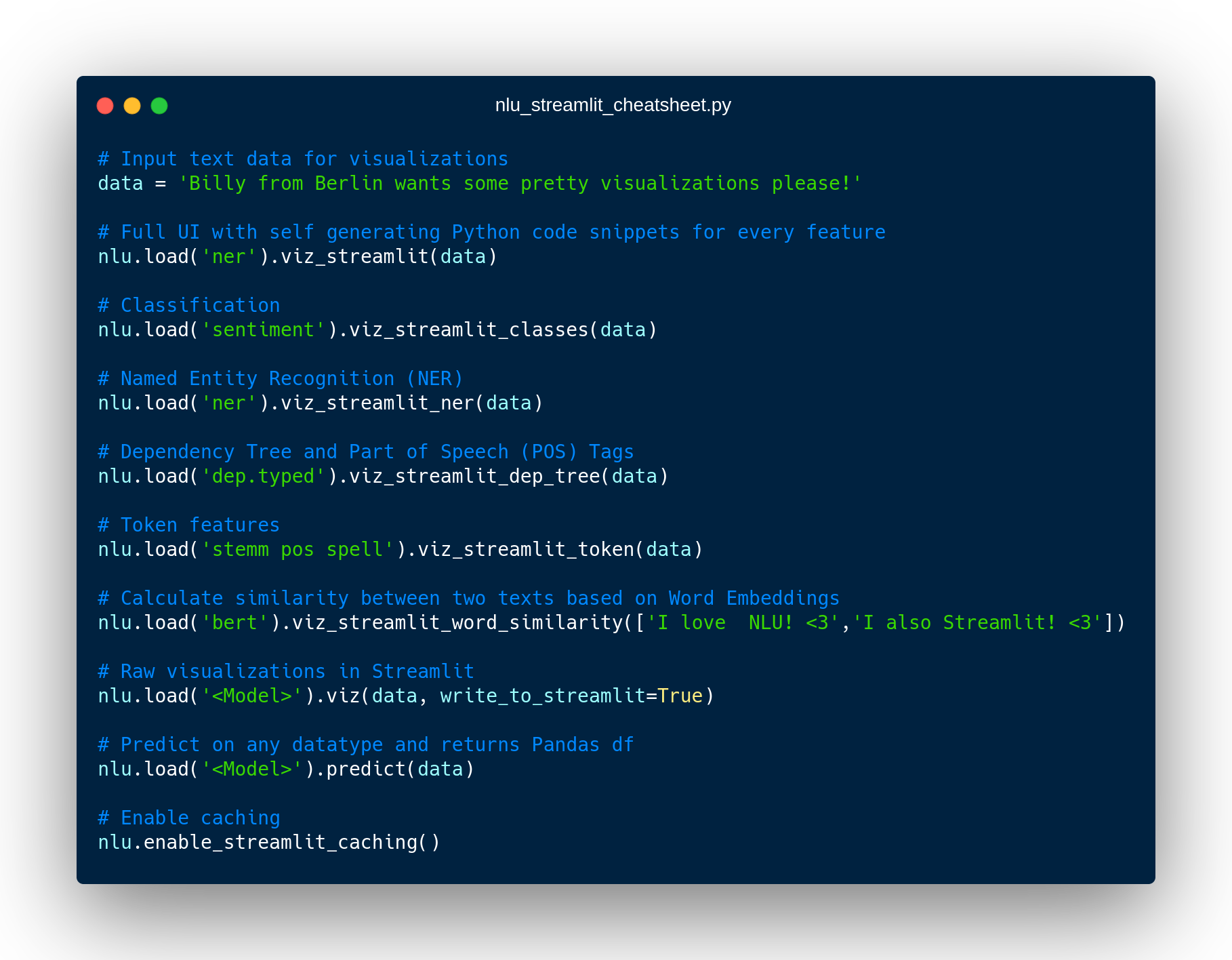
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/01_dashboard.pyQuick Starter cheat sheet - All you need to know in 1 picture for NLU + Streamlit
For NLU models to load, see the NLU Namespace or the John Snow Labs Modelshub or go straight to the source.
Examples
Just try out any of these.
You can use the first example to generate python-code snippets which you can
recycle as building blocks in your streamlit apps!
Example: 01_dashboard
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/01_dashboard.pyExample: 02_NER
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/02_NER.pyExample: 03_text_similarity_matrix
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/03_text_similarity_matrix.pyExample: 04_dependency_tree
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/04_dependency_tree.pyExample: 05_classifiers
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/05_classifiers.pyExample: 06_token_features
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/06_token_features.pyHow to use NLU?
All you need to know about NLU is that there is the nlu.load() method which returns a NLUPipeline object
which has a .predict() that works on most common data types in the pydata stack like Pandas dataframes .
Ontop of that, there are various visualization methods a NLUPipeline provides easily integrate in Streamlit as re-usable components. viz() method
Overview of NLU + Streamlit buildingblocks
| Method | Description |
|---|---|
nlu.load('<Model>').predict(data) |
Load any of the 1000+ models by providing the model name any predict on most Pythontic data strucutres like Pandas, strings, arrays of strings and more |
nlu.load('<Model>').viz_streamlit(data) |
Display full NLU exploration dashboard, that showcases every feature avaiable with dropdown selectors for 1000+ models |
nlu.load('<Model>').viz_streamlit_similarity([string1, string2]) |
Display similarity matrix and scalar similarity for every word embedding loaded and 2 strings. |
nlu.load('<Model>').viz_streamlit_ner(data) |
Visualize predicted NER tags from Named Entity Recognizer model |
nlu.load('<Model>').viz_streamlit_dep_tree(data) |
Visualize Dependency Tree together with Part of Speech labels |
nlu.load('<Model>').viz_streamlit_classes(data) |
Display all extracted class features and confidences for every classifier loaded in pipeline |
nlu.load('<Model>').viz_streamlit_token(data) |
Display all detected token features and informations in Streamlit |
nlu.load('<Model>').viz(data, write_to_streamlit=True) |
Display the raw visualization without any UI elements. See viz docs for more info. By default all aplicable nlu model references will be shown. |
nlu.enable_streamlit_caching() |
Enable caching the nlu.load() call. Once enabled, the nlu.load() method will automatically cached. This is recommended to run first and for large peformance gans |
Detailed visualizer information and API docs
function pipe.viz_streamlit
Display a highly configurable UI that showcases almost every feature available for Streamlit visualization with model selection dropdowns in your applications.
Ths includes :
Similarity Matrix&Scalars&Embedding Informationfor any of the 100+ Word Embedding ModelsNER visualizationsfor any of the 200+ Named entity recognizersLabled&Unlabled Dependency Trees visualizationswithPart of Speech Tagsfor any of the 100+ Part of Speech ModelsToken informationspredicted by any of the 1000+ modelsClassification resultspredicted by any of the 100+ models classification modelsPipeline Configuration&Model Information&Link to John Snow Labs Modelshubfor all loaded pipelinesAuto generate Python codethat can be copy pasted to re-create the individual Streamlit visualization blocks.
NlLU takes the first model specified asnlu.load()for the first visualization run.
Once the Streamlit app is running, additional models can easily be added via the UI.
It is recommended to run this first, since you can generate Python code snippetsto recreate individual Streamlit visualization blocks
nlu.load('ner').viz_streamlit(['I love NLU and Streamlit!','I hate buggy software'])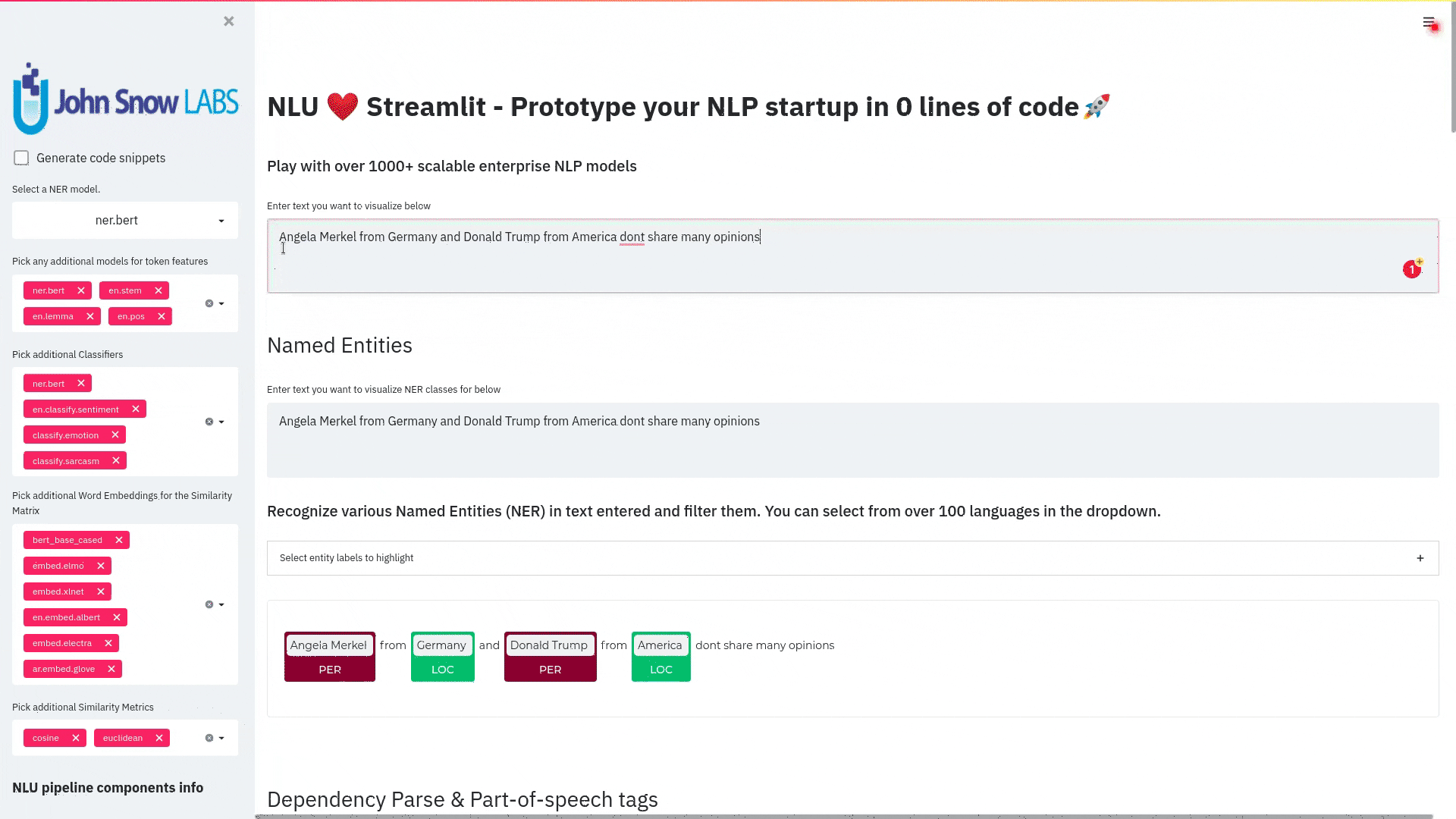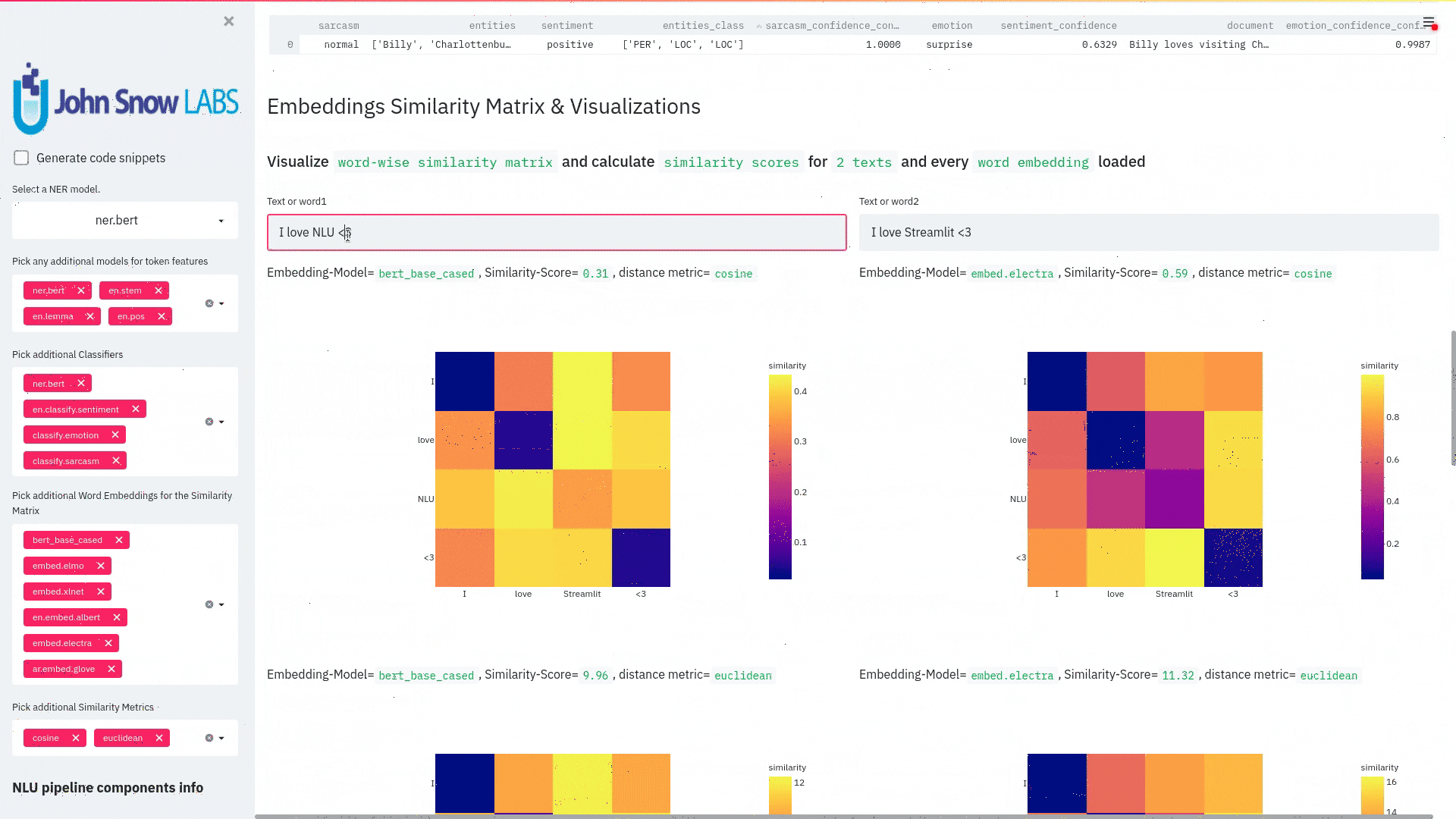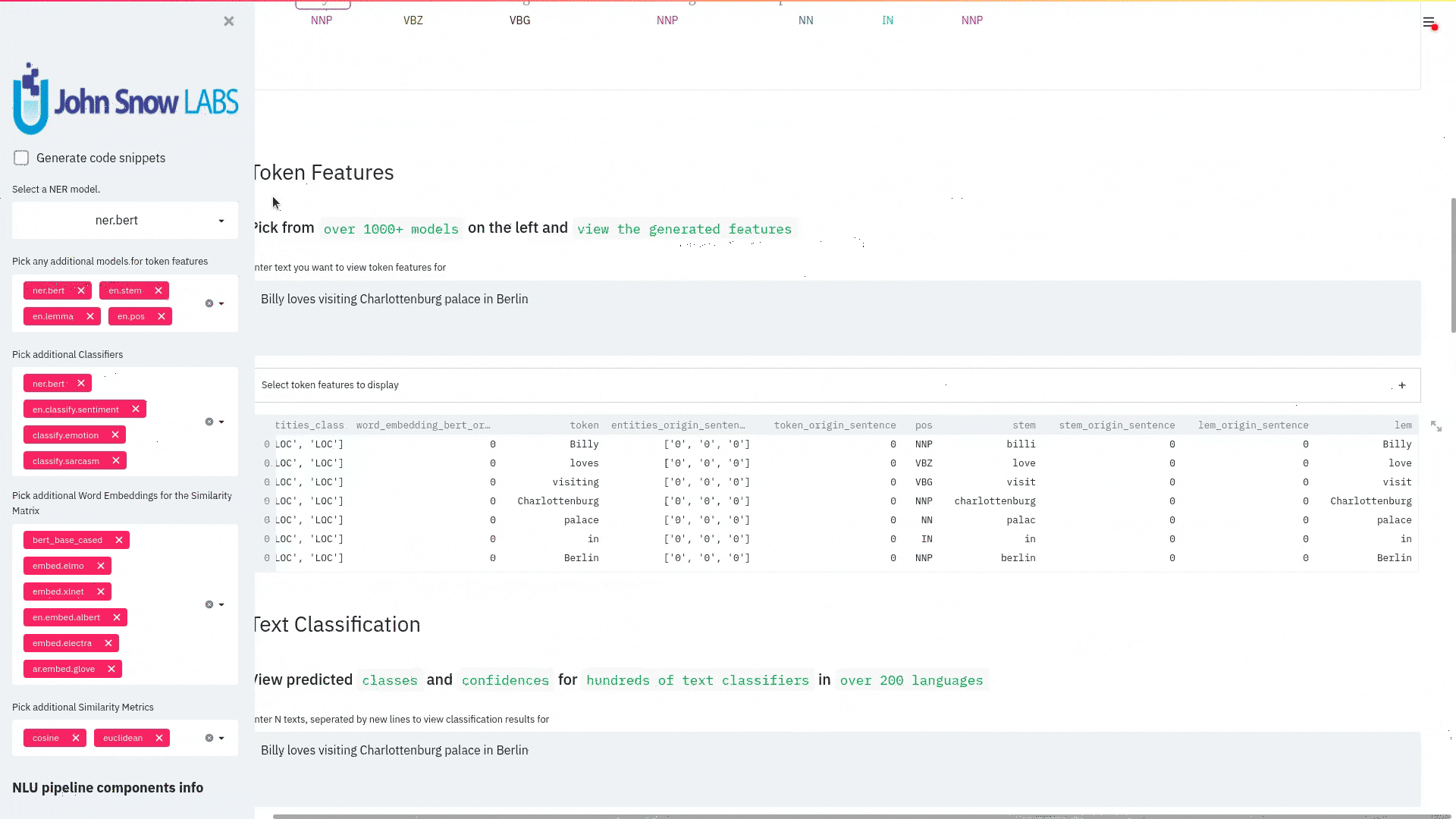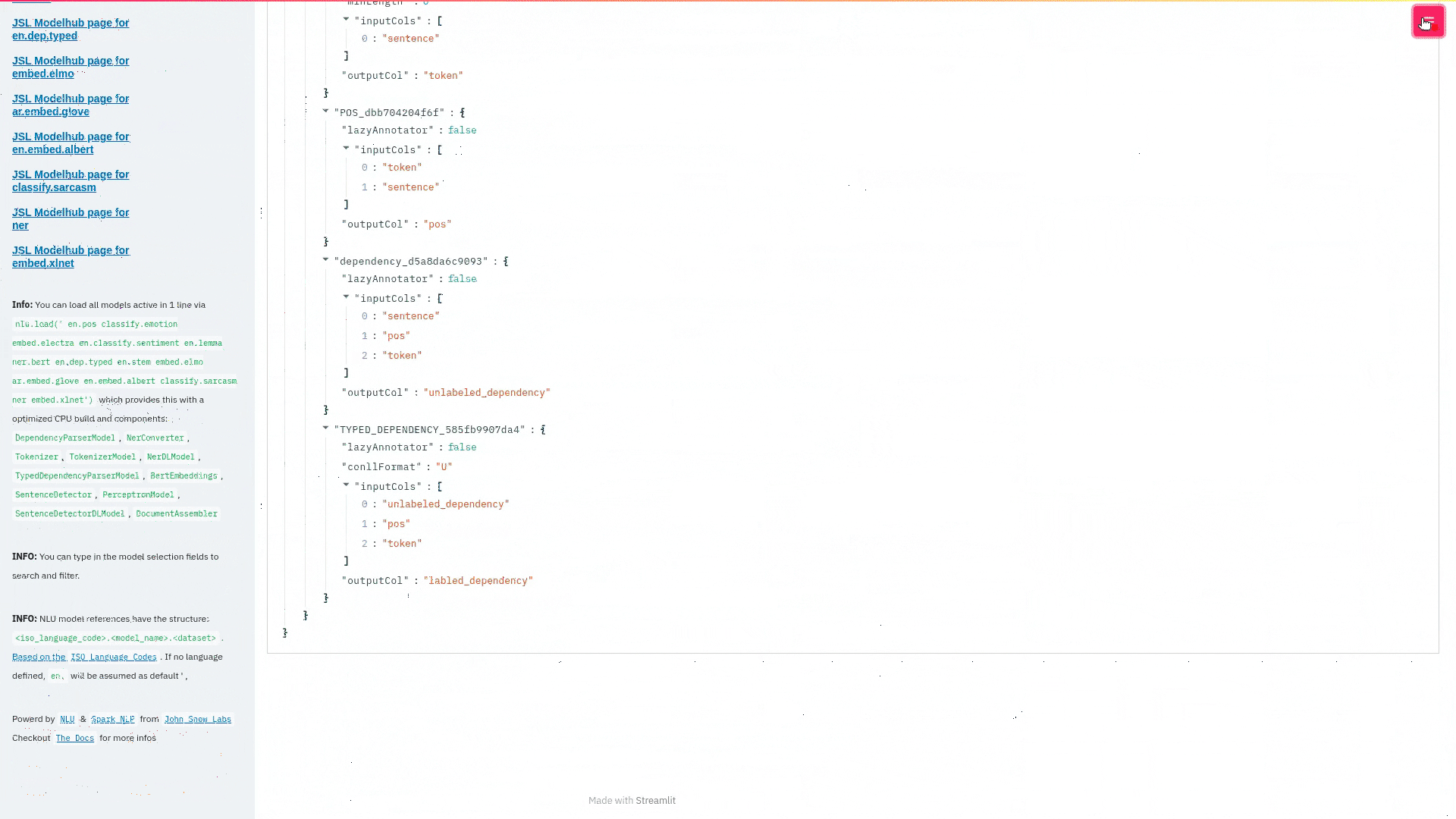
function parameters pipe.viz_streamlit
| Argument | Type | Default | Description |
|---|---|---|---|
text |
Union [str, List[str], pd.DataFrame, pd.Series] |
'NLU and Streamlit go together like peanutbutter and jelly' |
Default text for the Classification, Named Entitiy Recognizer, Token Information and Dependency Tree visualizations |
similarity_texts |
Union[List[str],Tuple[str,str]] |
('Donald Trump Likes to part', 'Angela Merkel likes to party') |
Default texts for the Text similarity visualization. Should contain exactly 2 strings which will be compared token embedding wise. For each embedding active, a token wise similarity matrix and a similarity scalar |
model_selection |
List[str] |
[] |
List of nlu references to display in the model selector, see the NLU Namespace or the John Snow Labs Modelshub or go straight to the source for more info |
title |
str |
'NLU ❤️ Streamlit - Prototype your NLP startup in 0 lines of code🚀' |
Title of the Streamlit app |
sub_title |
str |
'Play with over 1000+ scalable enterprise NLP models' |
Sub title of the Streamlit app |
visualizers |
List[str] |
( "dependency_tree", "ner", "similarity", "token_information", 'classification') |
Define which visualizations should be displayed. By default all visualizations are displayed. |
show_models_info |
bool |
True |
Show information for every model loaded in the bottom of the Streamlit app. |
show_model_select |
bool |
True |
Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click |
show_viz_selection |
bool |
False |
Show a selector in the sidebar which lets you configure which visualizations are displayed. |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
model_select_position |
str |
'side' |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
show_code_snippets |
bool |
False |
Display Python code snippets above visualizations that can be used to re-create the visualization |
num_similarity_cols |
int |
2 |
How many columns should for the layout in Streamlit when rendering the similarity matrixes. |
function pipe.viz_streamlit_classes
Visualize the predicted classes and their confidences and additional metadata to streamlit.
Aplicable with any of the 100+ classifiers
nlu.load('sentiment').viz_streamlit_classes(['I love NLU and Streamlit!','I love buggy software', 'Sign up now get a chance to win 1000$ !', 'I am afraid of Snakes','Unicorns have been sighted on Mars!','Where is the next bus stop?'])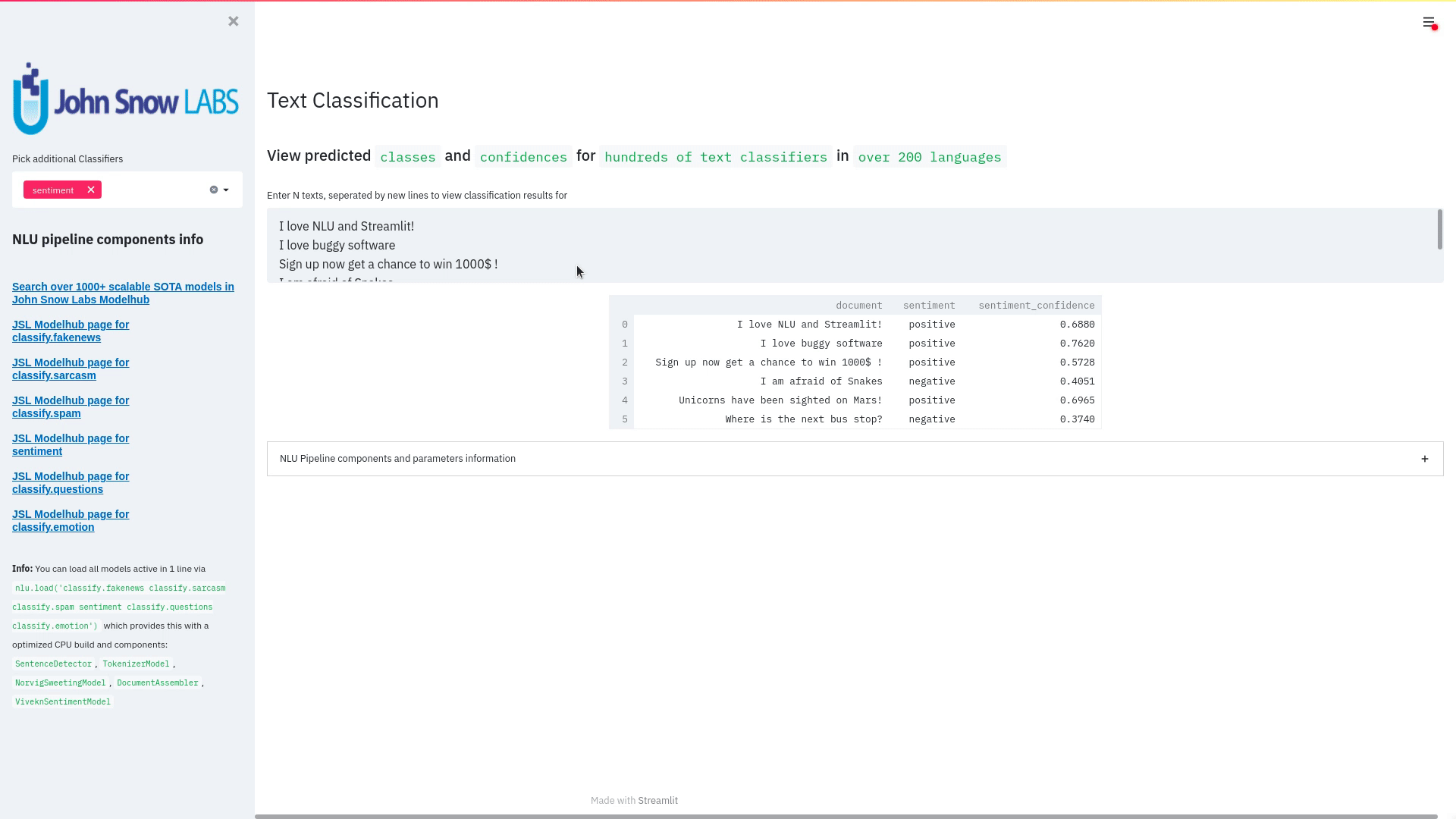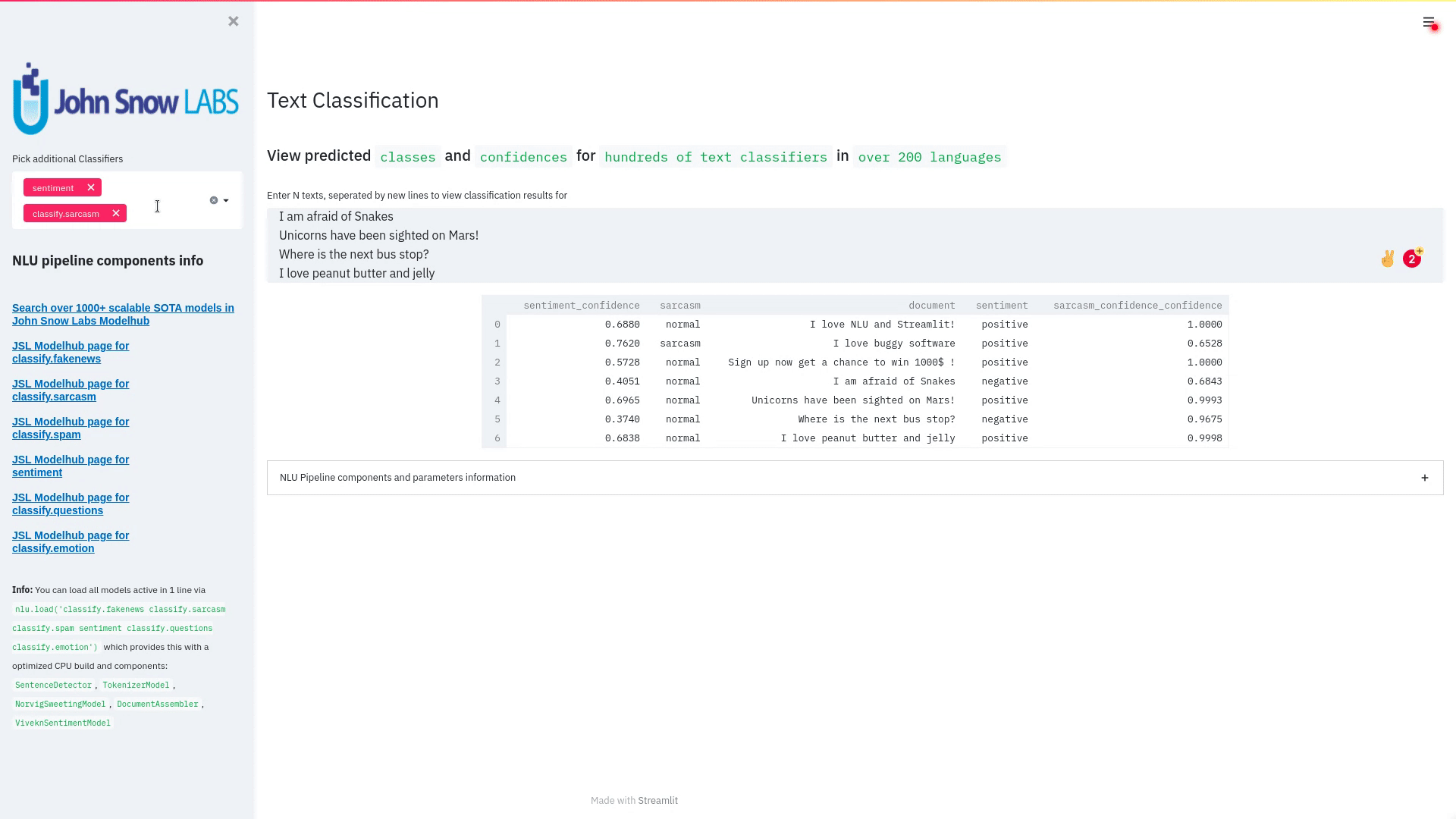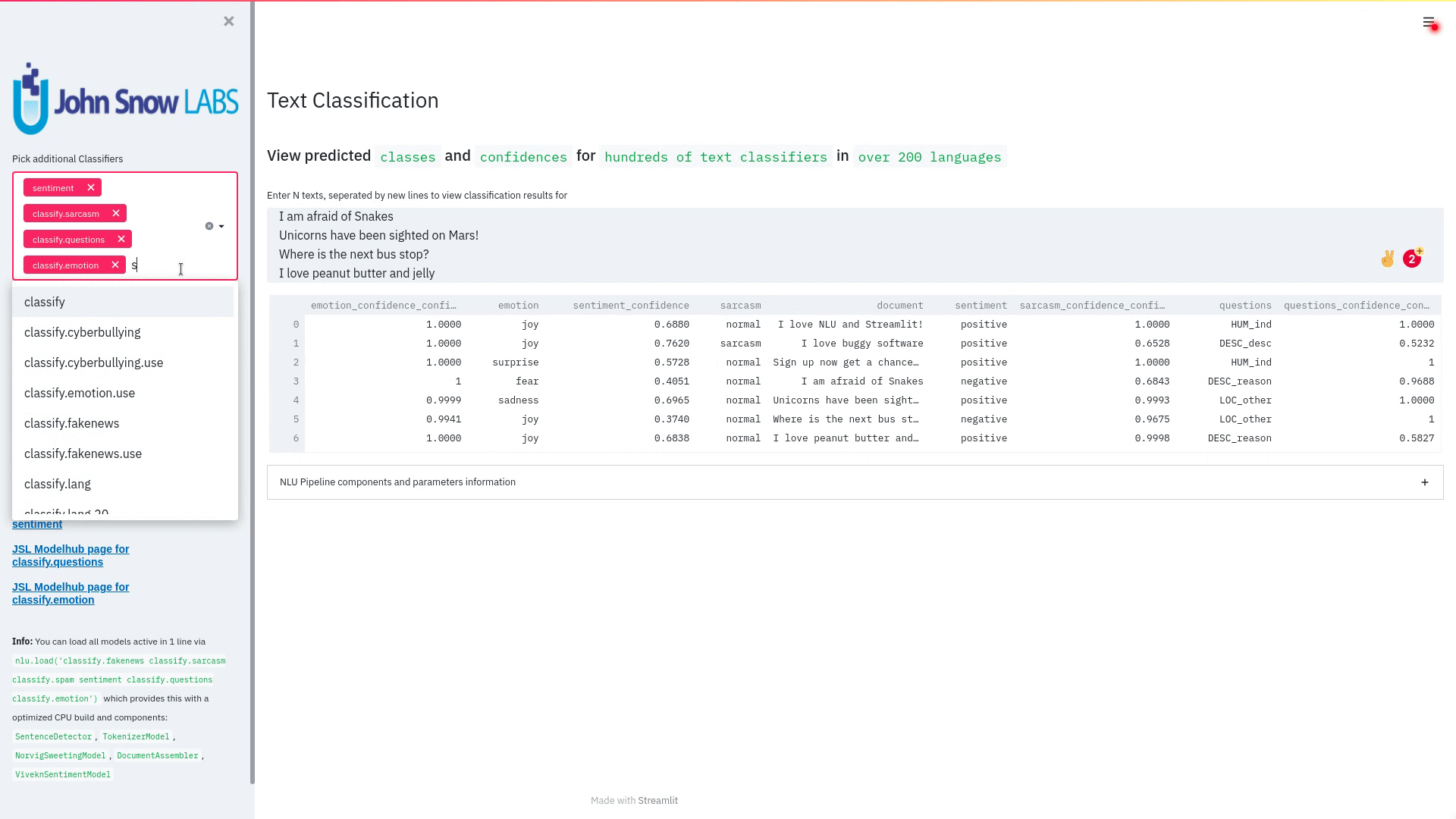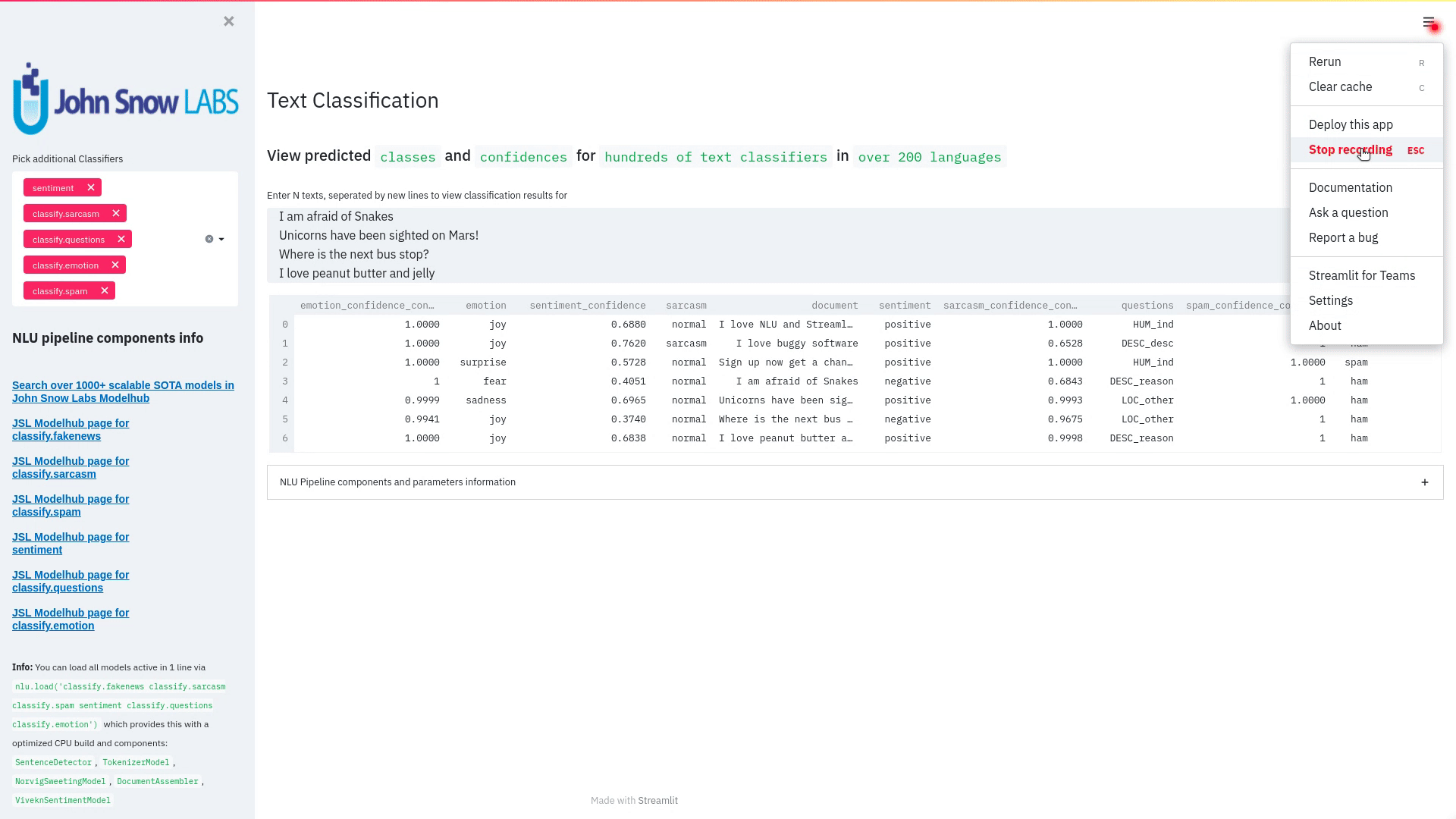
function parameters pipe.viz_streamlit_classes
| Argument | Type | Default | Description |
|---|---|---|---|
text |
Union[str,list,pd.DataFrame, pd.Series, pyspark.sql.DataFrame ] |
'I love NLU and Streamlit and sunny days!' |
Text to predict classes for. Will predict on each input of the iteratable or dataframe if type is not str. |
output_level |
Optional[str] |
document |
Outputlevel of NLU pipeline, see pipe.predict() docsmore info |
include_text_col |
bool |
True |
Whether to include a e text column in the output table or just the prediction data |
title |
Optional[str] |
Text Classification |
Title of the Streamlit building block that will be visualized to screen |
metadata |
bool |
False |
whether to output addition metadata or not, see pipe.predict(meta=true) docs for more info |
positions |
bool |
False |
whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
model_select_position |
str |
'side' |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
generate_code_sample |
bool |
False |
Display Python code snippets above visualizations that can be used to re-create the visualization |
show_model_select |
bool |
True |
Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
function pipe.viz_streamlit_ner
Visualize the predicted classes and their confidences and additional metadata to Streamlit.
Aplicable with any of the 250+ NER models.
You can filter which NER tags to highlight via the dropdown in the main window.
Basic usage
nlu.load('ner').viz_streamlit_ner('Donald Trump from America and Angela Merkel from Germany dont share many views')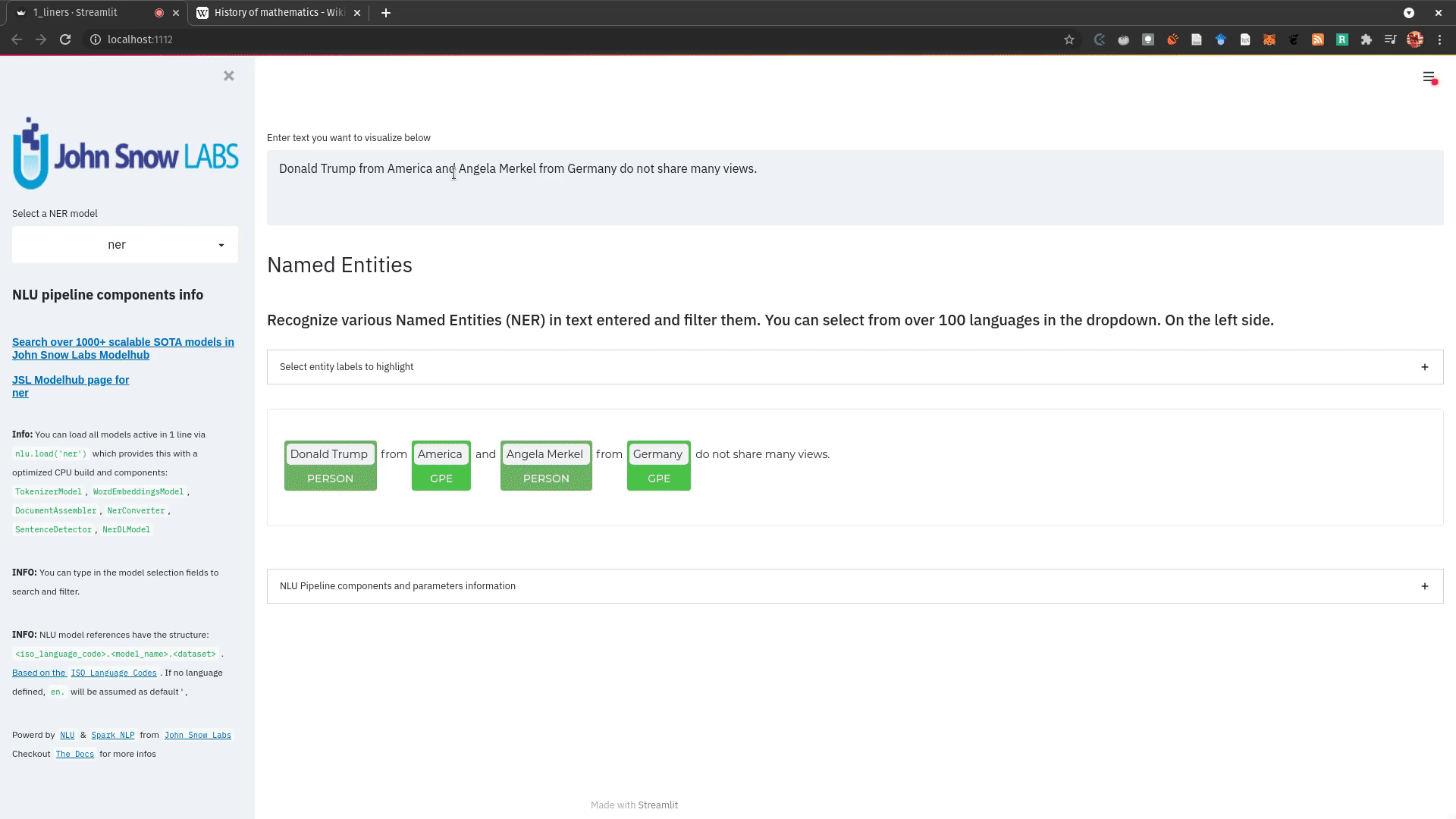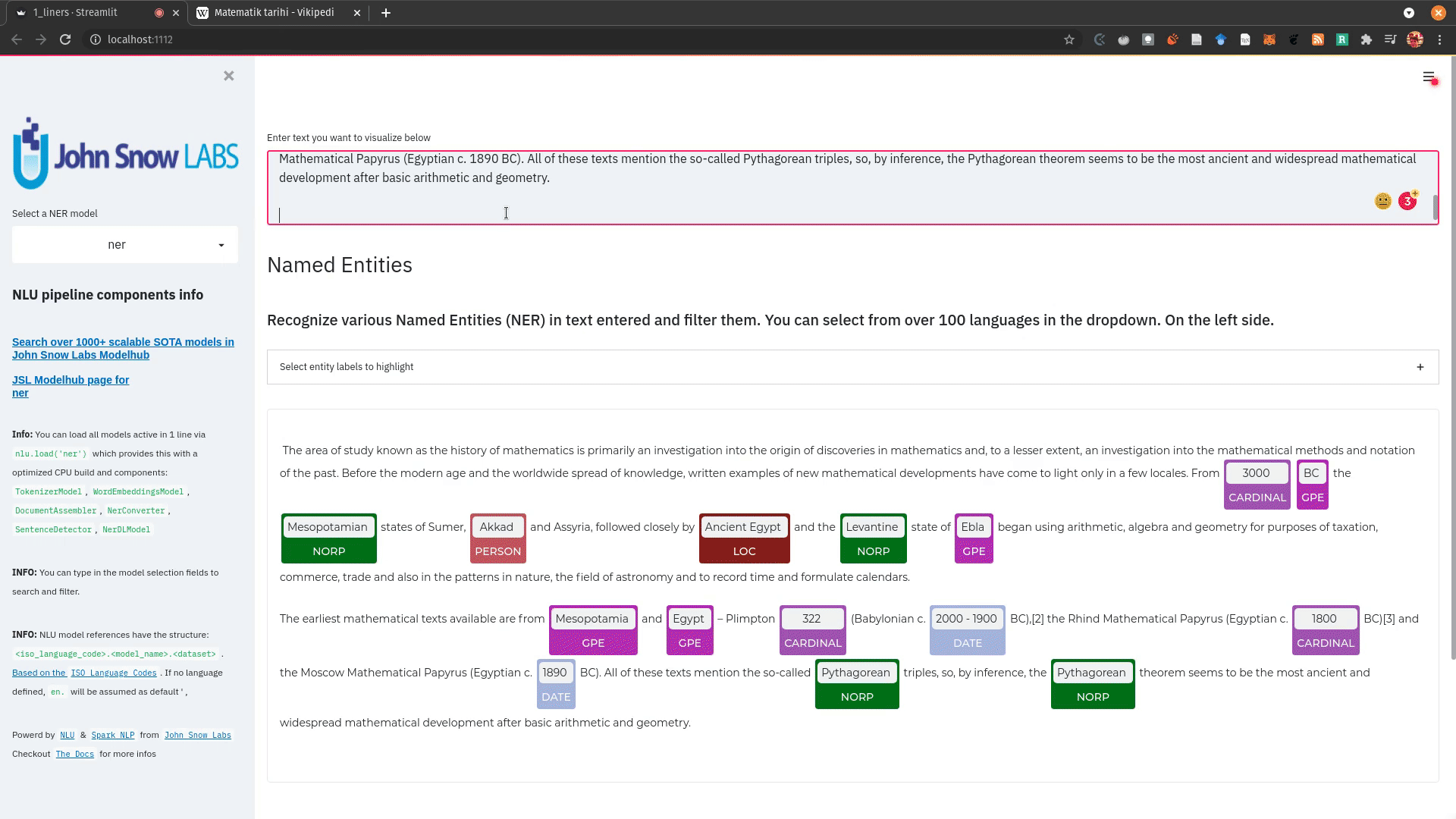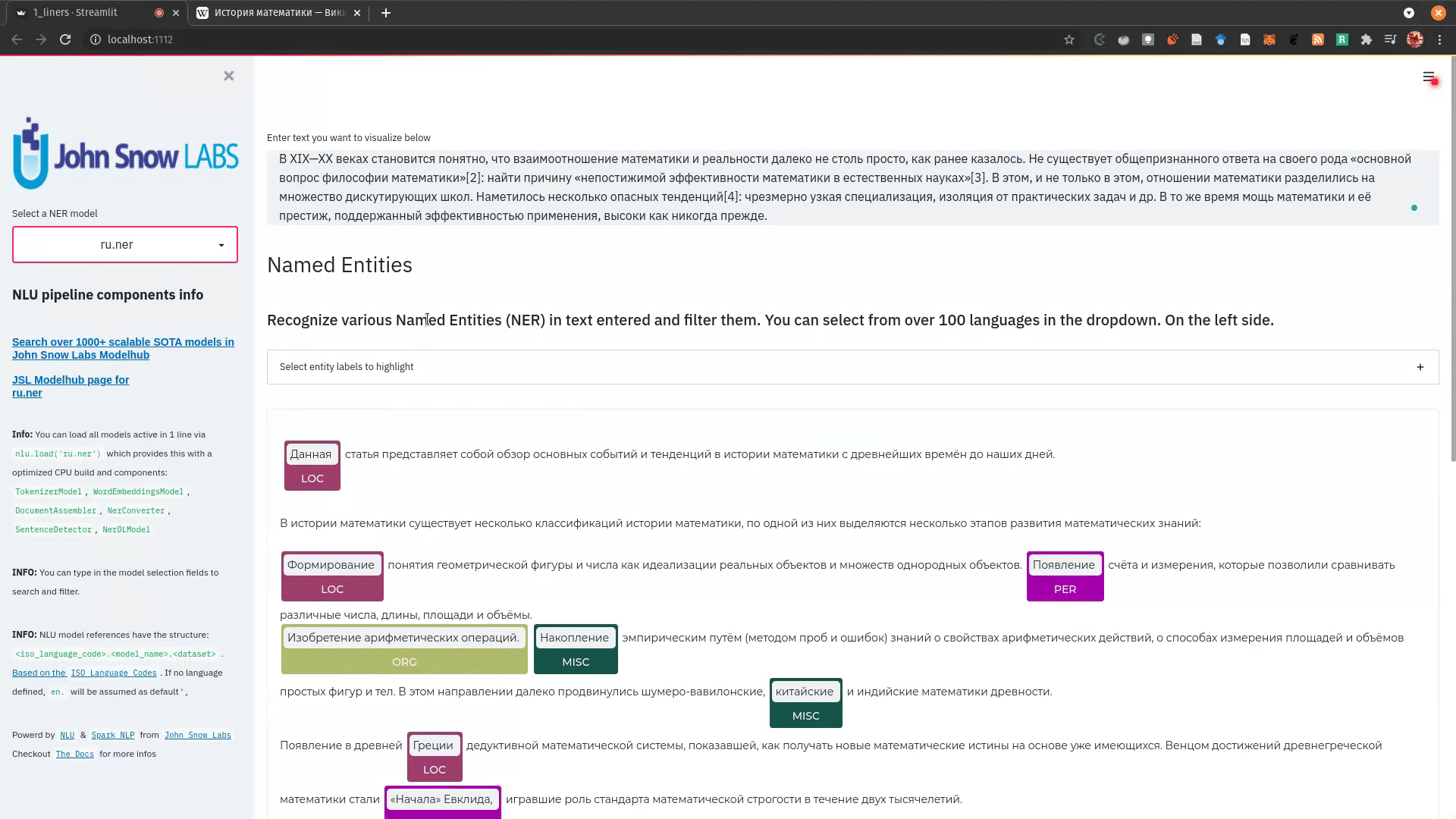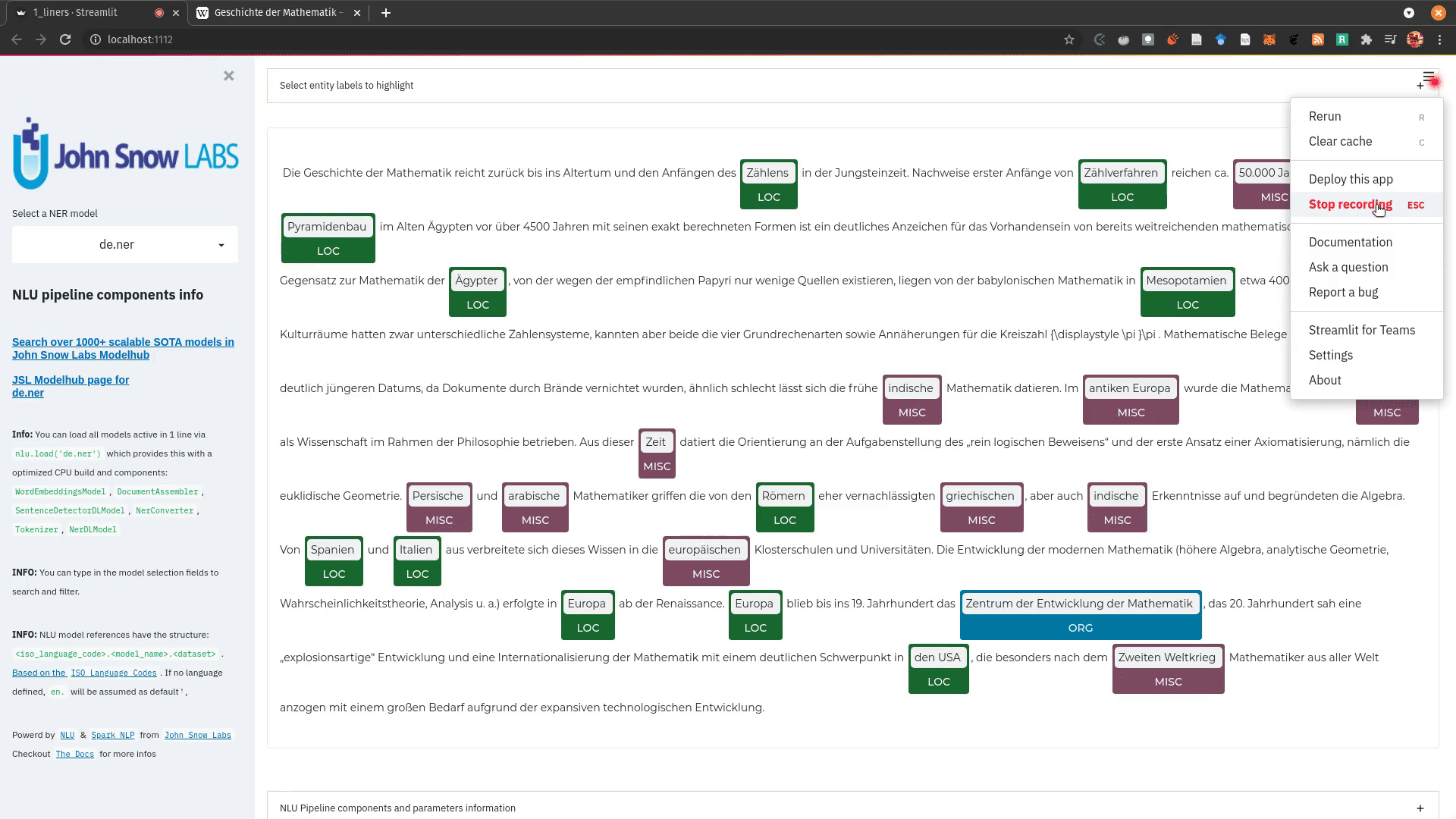
Example for coloring
# Color all entities of class GPE black
nlu.load('ner').viz_streamlit_ner('Donald Trump from America and Angela Merkel from Germany dont share many views',colors={'PERSON':'#6e992e', 'GPE':'#000000'})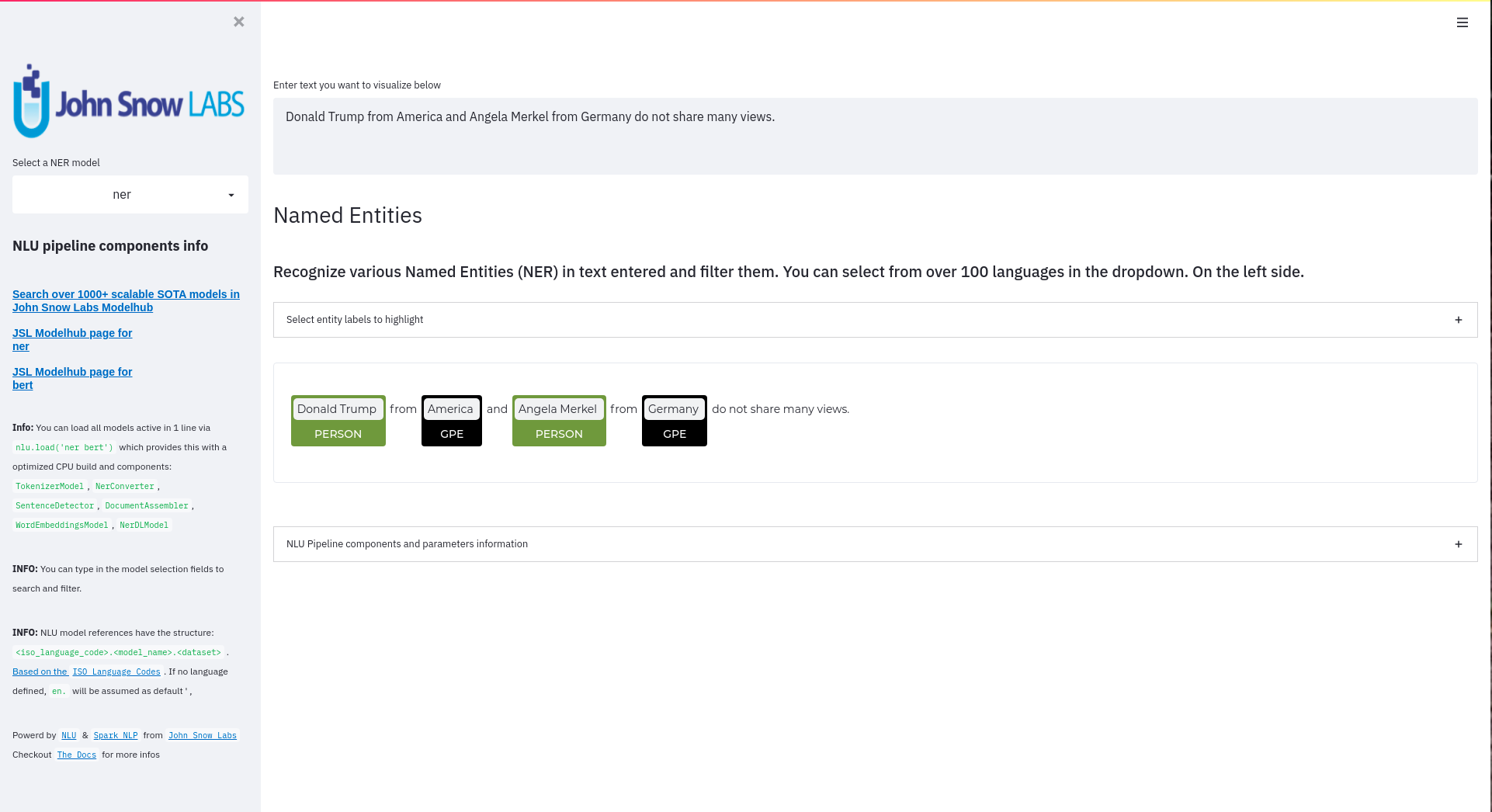
function parameters pipe.viz_streamlit_ner
| Argument | Type | Default | Description |
|---|---|---|---|
text |
str |
'Donald Trump from America and Anegela Merkel from Germany do not share many views' |
Text to predict classes for. |
ner_tags |
Optional[List[str]] |
None |
Tags to display. By default all tags will be displayed |
show_label_select |
bool |
True |
Whether to include the label selector |
show_table |
bool |
True |
Whether show to predicted pandas table or not |
title |
Optional[str] |
'Named Entities' |
Title of the Streamlit building block that will be visualized to screen |
sub_title |
Optional[str] |
'"Recognize various Named Entities (NER) in text entered and filter them. You can select from over 100 languages in the dropdown. On the left side.",' |
Sub-title of the Streamlit building block that will be visualized to screen |
colors |
Dict[str,str] |
{} |
Dict with KEY=ENTITY_LABEL and VALUE=COLOR_AS_HEX_CODE,which will change color of highlighted entities.See custom color labels docs for more info. |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
generate_code_sample |
bool |
False |
Display Python code snippets above visualizations that can be used to re-create the visualization |
show_model_select |
bool |
True |
Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click |
model_select_position |
str |
'side' |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
show_text_input |
bool |
True |
Show text input field to input text in |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
function pipe.viz_streamlit_dep_tree
Visualize a typed dependency tree, the relations between tokens and part of speech tags predicted.
Aplicable with any of the 100+ Part of Speech(POS) models and dep tree model
nlu.load('dep.typed').viz_streamlit_dep_tree('POS tags define a grammatical label for each token and the Dependency Tree classifies Relations between the tokens')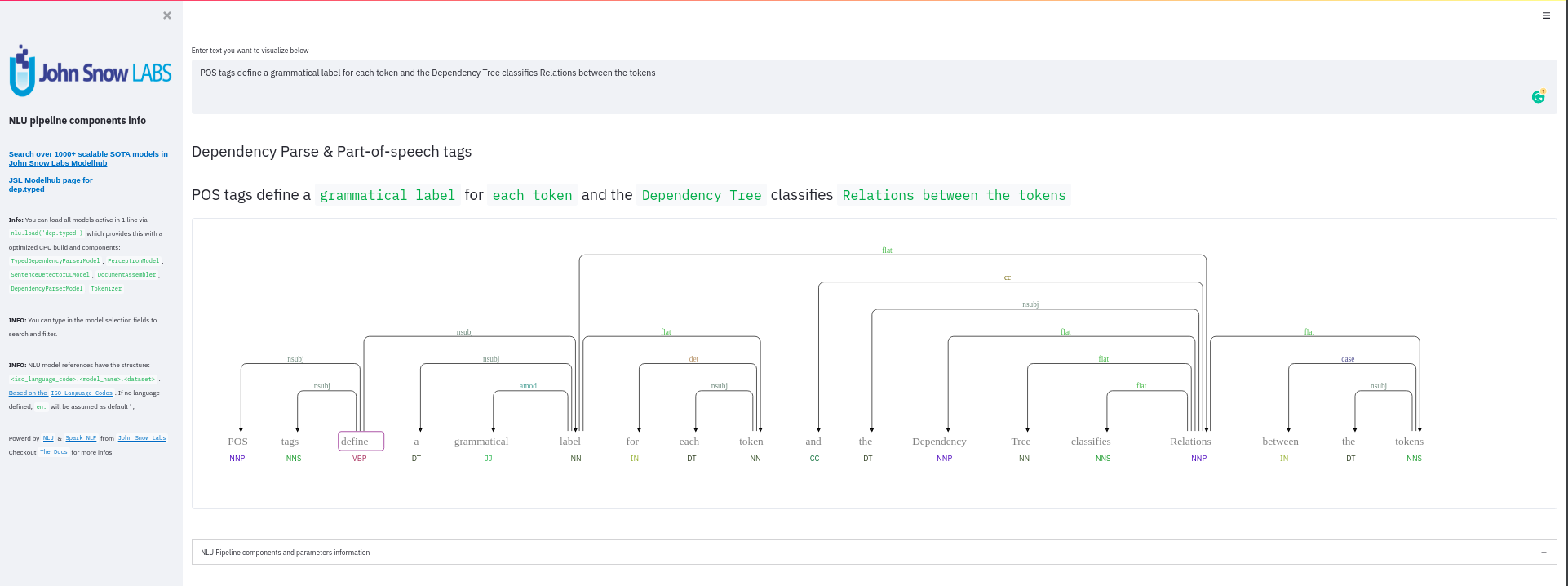
function parameters pipe.viz_streamlit_dep_tree
| Argument | Type | Default | Description |
|---|---|---|---|
text |
str |
'Billy likes to swim' |
Text to predict classes for. |
title |
Optional[str] |
'Dependency Parse Tree & Part-of-speech tags' |
Title of the Streamlit building block that will be visualized to screen |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
generate_code_sample |
bool |
False |
Display Python code snippets above visualizations that can be used to re-create the visualization |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
generate_code_sample |
bool |
False |
Display Python code snippets above visualizations that can be used to re-create the visualization |
show_model_select |
bool |
True |
Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click |
model_select_position |
str |
'side' |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
function pipe.viz_streamlit_token
Visualize predicted token and text features for every model loaded.
You can use this with any of the 1000+ models and select them from the left dropdown.
nlu.load('stemm pos spell').viz_streamlit_token('I liek pentut buttr and jelly !')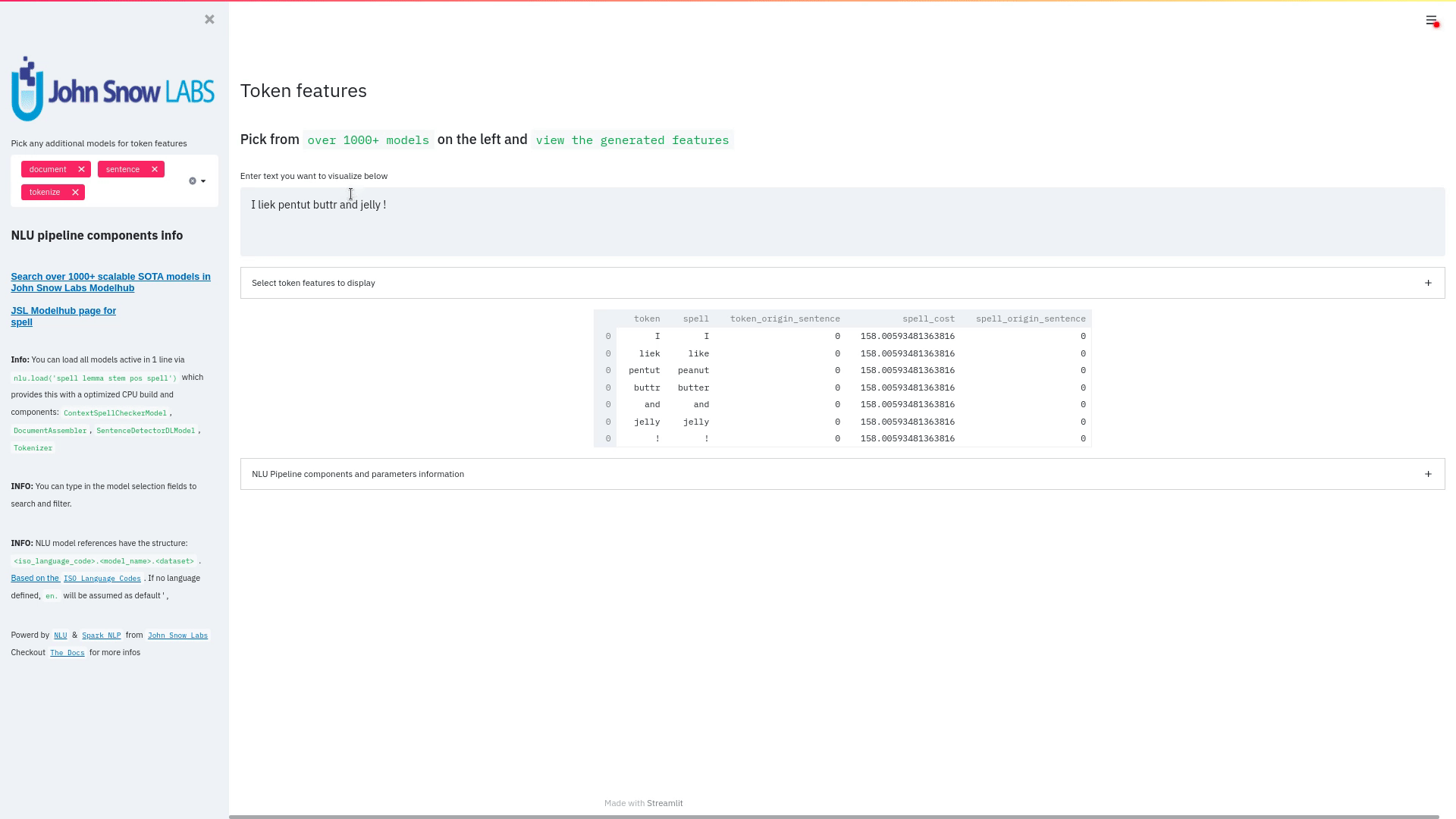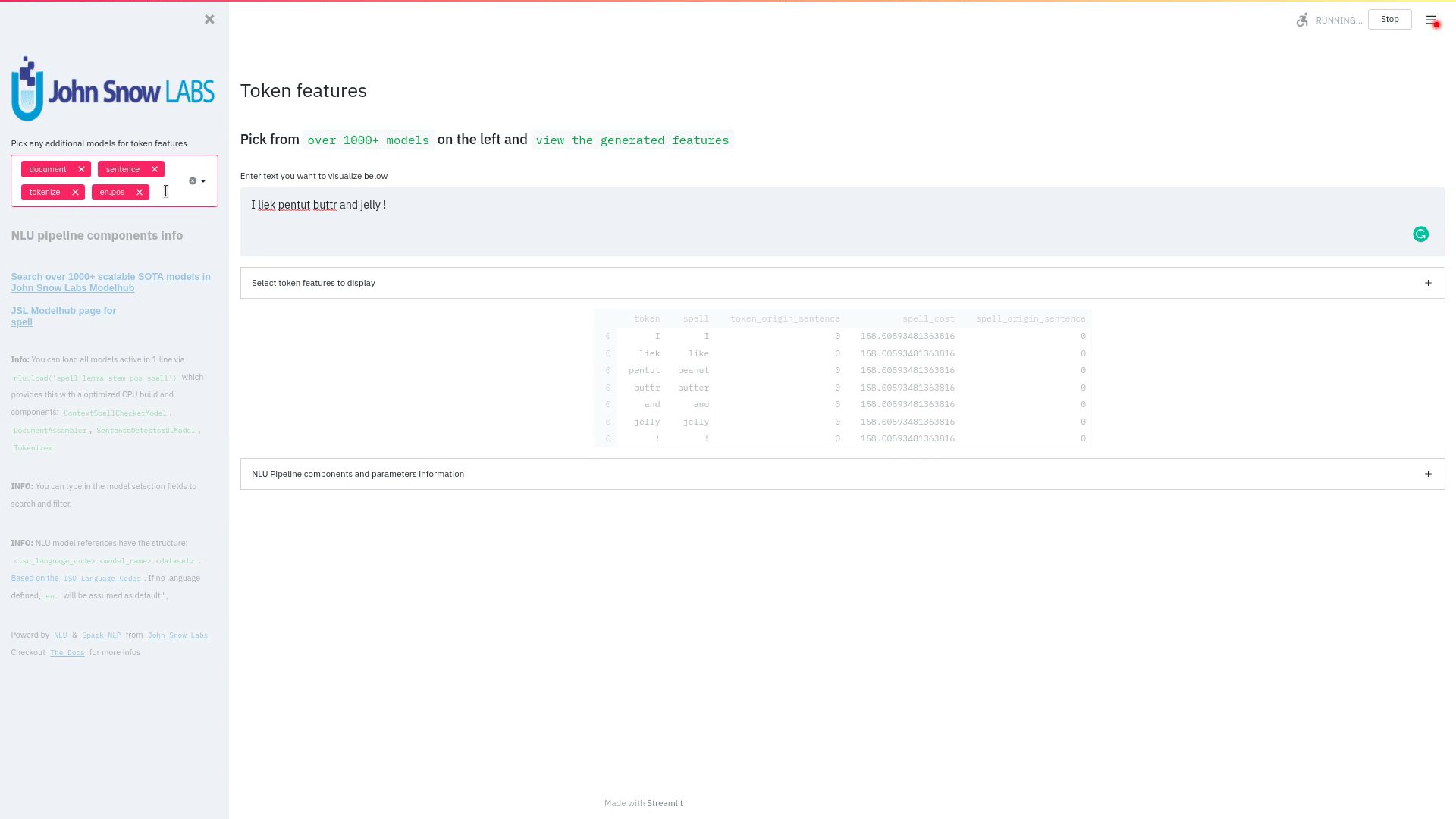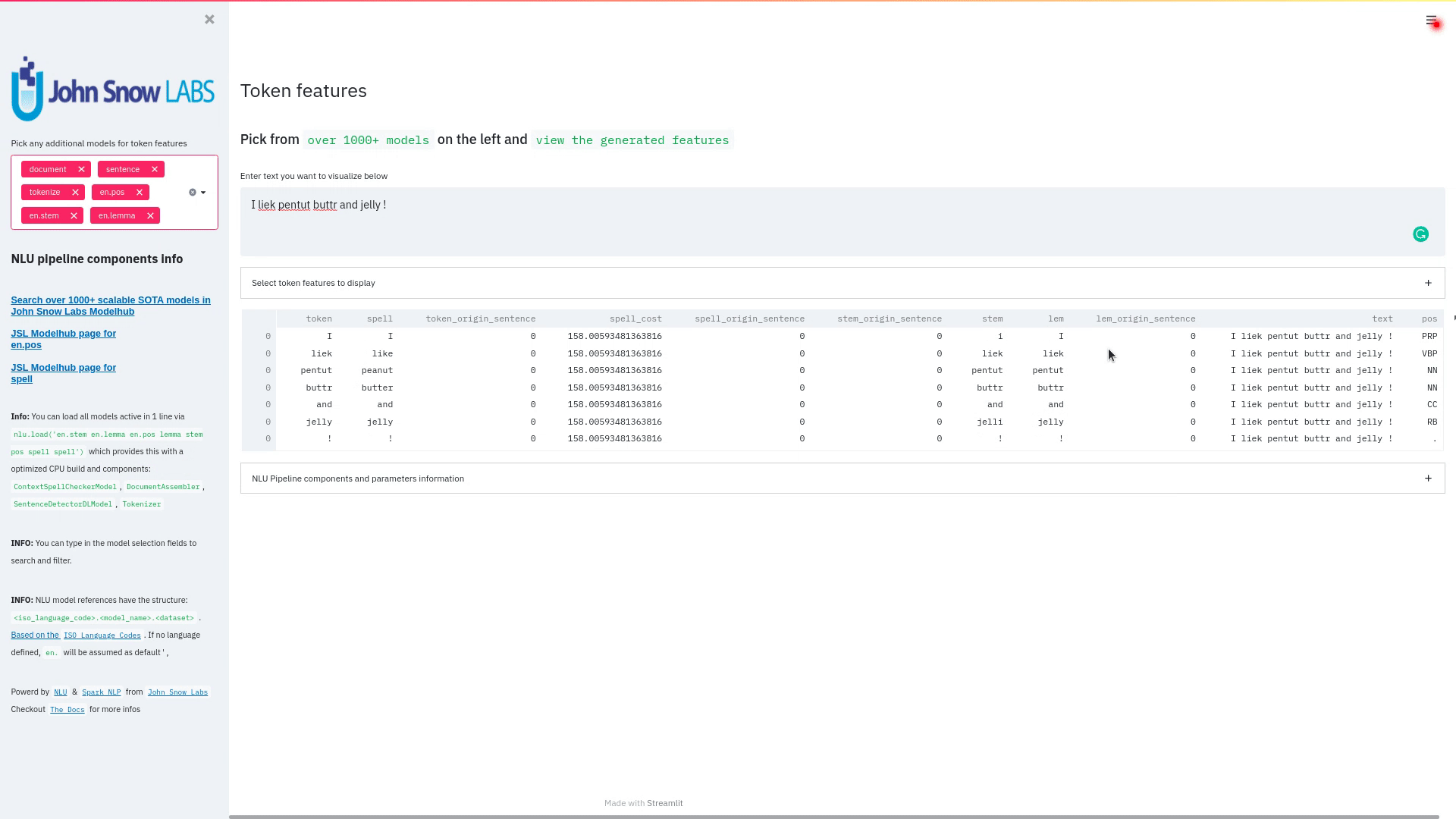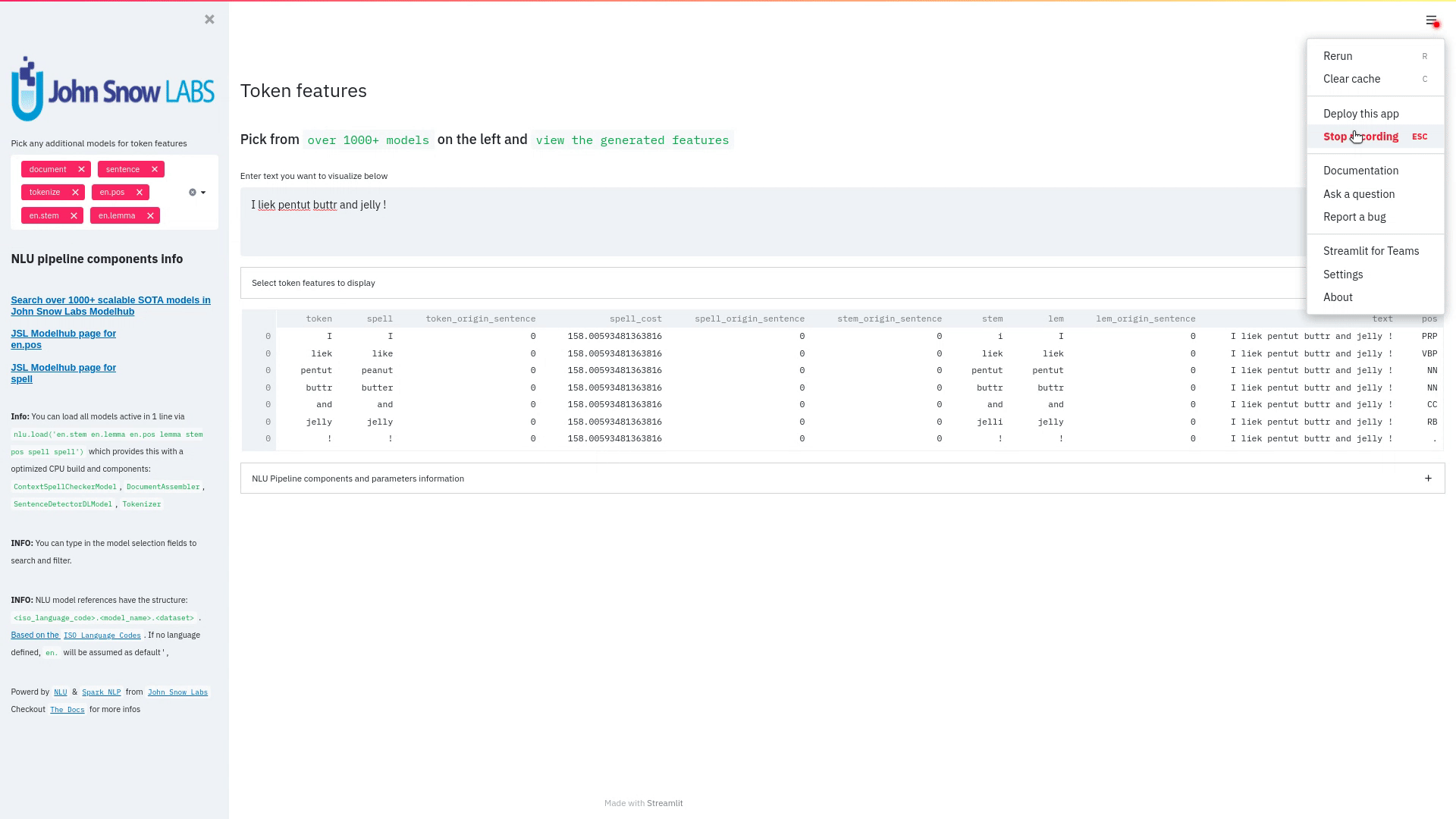
function parameters pipe.viz_streamlit_token
| Argument | Type | Default | Description |
|---|---|---|---|
text |
str |
'NLU and Streamlit are great!' |
Text to predict token information for. |
title |
Optional[str] |
'Named Entities' |
Title of the Streamlit building block that will be visualized to screen |
show_feature_select |
bool |
True |
Whether to include the token feature selector |
features |
Optional[List[str]] |
None |
Features to to display. By default all Features will be displayed |
metadata |
bool |
False |
Whether to output addition metadata or not, see pipe.predict(meta=true) docs for more info |
output_level |
Optional[str] |
'token' |
Outputlevel of NLU pipeline, see pipe.predict() docsmore info |
positions |
bool |
False |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
generate_code_sample |
bool |
False |
Display Python code snippets above visualizations that can be used to re-create the visualization |
show_model_select |
bool |
True |
Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click |
model_select_position |
str |
'side' |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
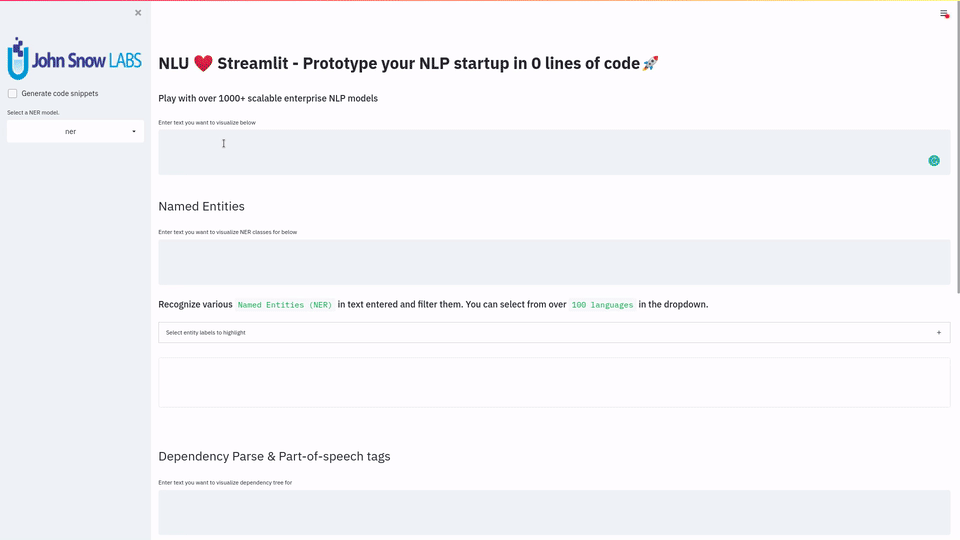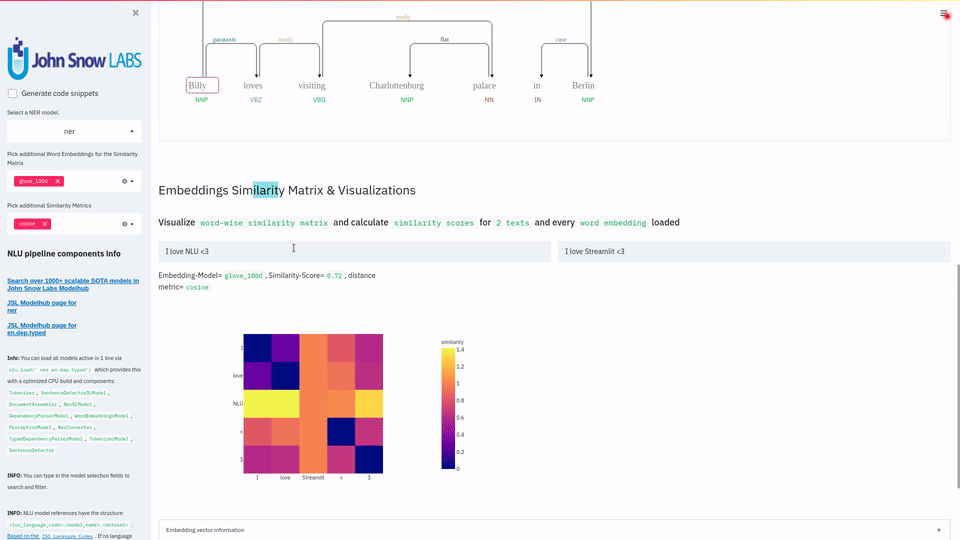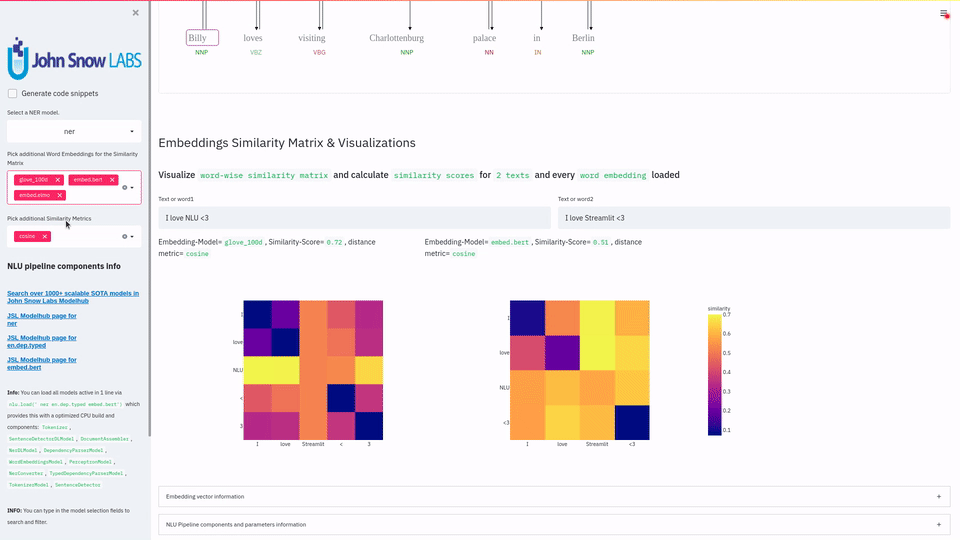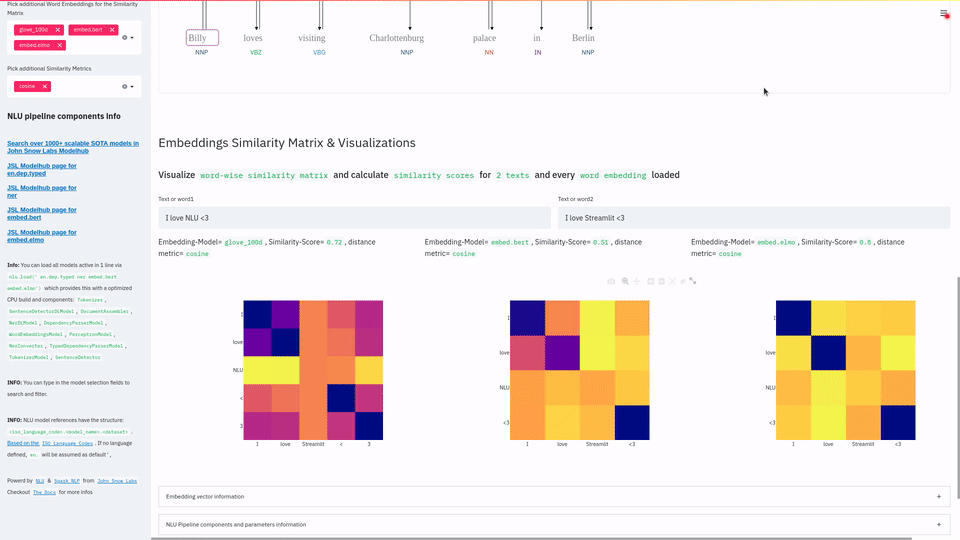
function pipe.viz_streamlit_similarity
- Displays a
similarity matrix, wherex-axisis every token in the first text andy-axisis every token in the second text. - Index
i,jin the matrix describes the similarity oftoken-itotoken-jbased on the loaded embeddings and distance metrics, based on Sklearns Pariwise Metrics.. See this article for more elaboration on similarities - Displays a dropdown selectors from which various similarity metrics and over 100 embeddings can be selected.
-There will be one similarity matrix permetricandembeddingpair selected.num_plots = num_metric*num_embeddings
Also displays embedding vector information.
Applicable with any of the 100+ Word Embedding models
nlu.load('bert').viz_streamlit_word_similarity(['I love love loooove NLU! <3','I also love love looove Streamlit! <3'])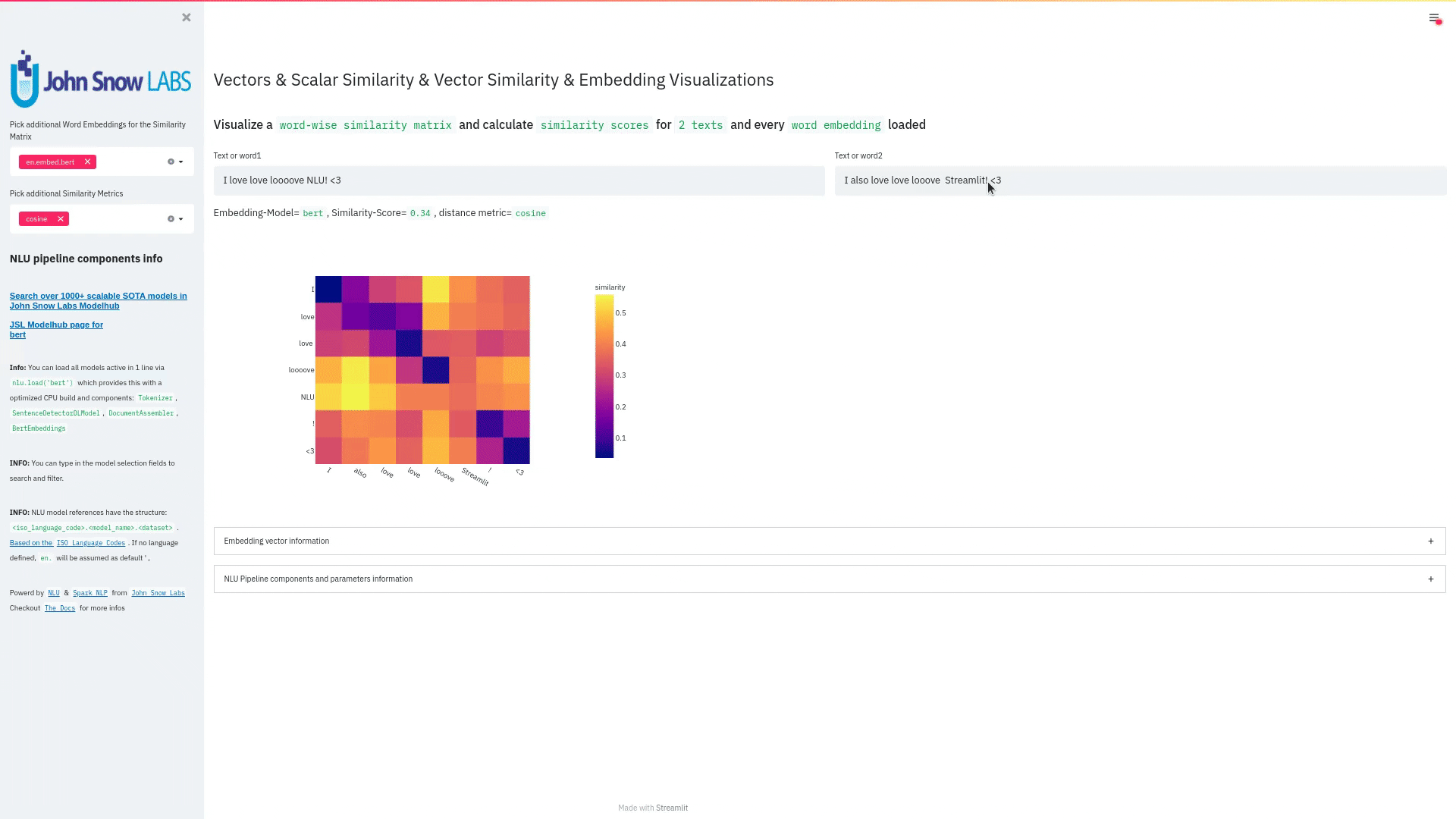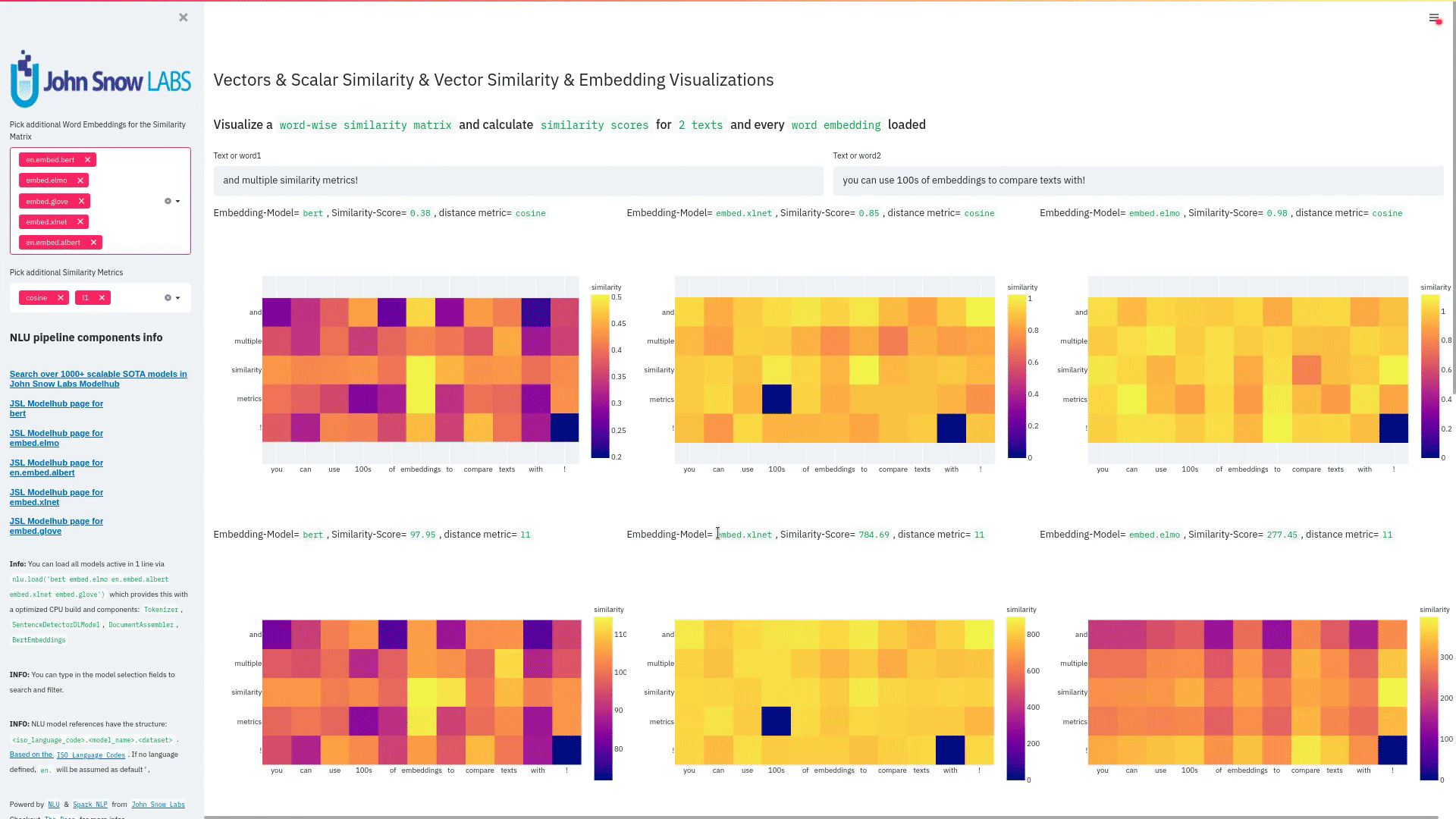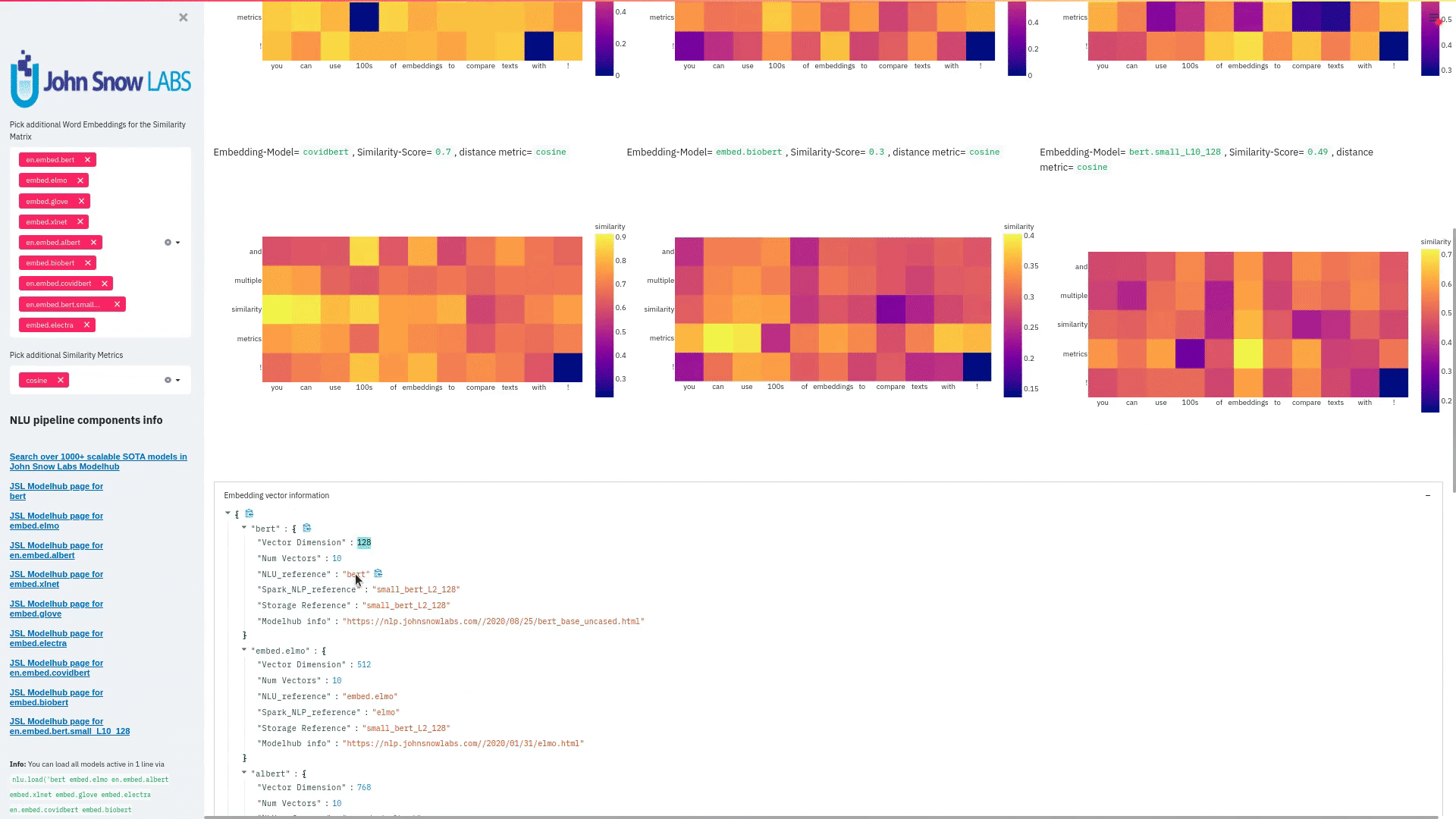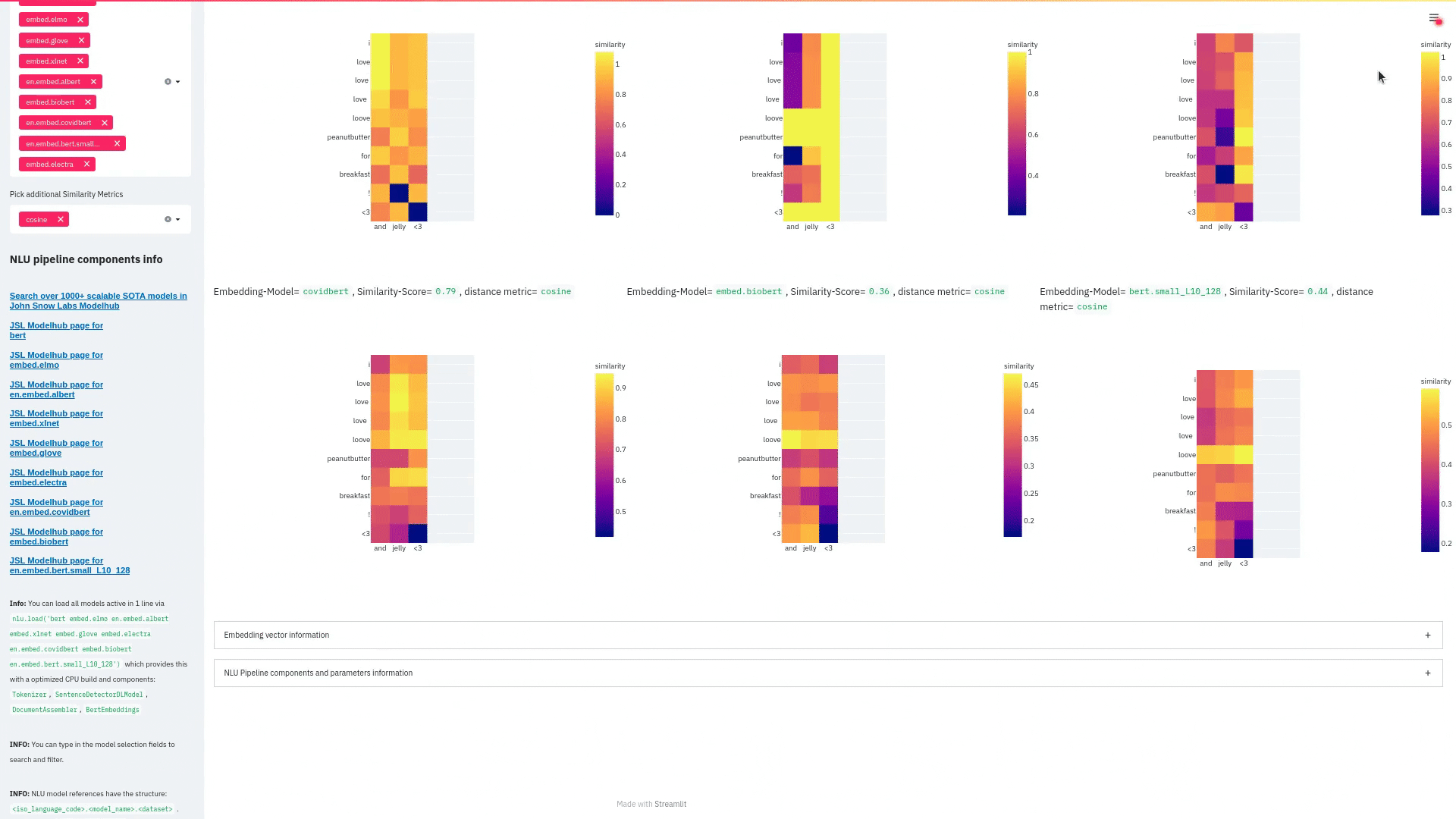
function parameters pipe.viz_streamlit_similarity
| Argument | Type | Default | Description |
|---|---|---|---|
texts |
str |
'Donald Trump from America and Anegela Merkel from Germany do not share many views.' |
Text to predict token information for. |
title |
Optional[str] |
'Named Entities' |
Title of the Streamlit building block that will be visualized to screen |
similarity_matrix |
bool |
None |
Whether to display similarity matrix or not |
show_algo_select |
bool |
True |
Whether to show dist algo select or not |
show_table |
bool |
True |
Whether show to predicted pandas table or not |
threshold |
float |
0.5 |
Threshold for displaying result red on screen |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
generate_code_sample |
bool |
False |
Display Python code snippets above visualizations that can be used to re-create the visualization |
show_model_select |
bool |
True |
Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click |
model_select_position |
str |
'side' |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
write_raw_pandas |
bool |
False |
Write the raw pandas similarity df to streamlit |
display_embed_information |
bool |
True |
Show additional embedding information like dimension, nlu_reference, spark_nlp_reference, sotrage_reference, modelhub link and more. |
dist_metrics |
List[str] |
['cosine'] |
Which distance metrics to apply. If multiple are selected, there will be multiple plots for each embedding and metric. num_plots = num_metric*num_embeddings. Can use multiple at the same time, any of of cityblock,cosine,euclidean,l2,l1,manhattan,nan_euclidean. Provided via Sklearn metrics.pairwise package |
num_cols |
int |
2 |
How many columns should for the layout in streamlit when rendering the similarity matrixes. |
display_scalar_similarities |
bool |
False |
Display scalar simmilarities in an additional field. |
display_similarity_summary |
bool |
False |
Display summary of all similarities for all embeddings and metrics. |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
In addition have added some new features to our T5 Transformer annotator to help with longer and more accurate text generation, trained some new multi-lingual models and pipelines in Farsi, Hebrew, Korean, and Turkish.
T5 Model Improvements
- Add 6 new features to T5Transformer for longer and better text generation
- doSample: Whether or not to use sampling; use greedy decoding otherwise
- temperature: The value used to module the next token probabilities
- topK: The number of highest probability vocabulary tokens to keep for top-k-filtering
- topP: If set to float < 1, only the most probable tokens with probabilities that add up to
top_por higher are kept for generation - repetitionPenalty: The parameter for repetition penalty. 1.0 means no penalty. See CTRL: A Conditional Transformer Language Model for Controllable Generation paper for more details
- noRepeatNgramSize: If set to int > 0, all ngrams of that size can only occur once
New Open Source Model in NLU 3.0.2
New multilingual models and pipelines for Farsi, Hebrew, Korean, and Turkish
| Model | NLU Reference | Spark NLP Reference | Lang |
|---|---|---|---|
| ClassifierDLModel | tr.classify.news |
classifierdl_bert_news | tr |
| UniversalSentenceEncoder | xx.use.multi |
tfhub_use_multi | xx |
| UniversalSentenceEncoder | xx.use.multi_lg |
tfhub_use_multi_lg | xx |
| Pipeline | NLU Reference | Spark NLP Reference | Lang |
|---|---|---|---|
| PretrainedPipeline | fa.ner.dl |
recognize_entities_dl | fa |
| PretrainedPipeline | he.explain_document |
explain_document_lg | he |
| PretrainedPipeline | ko.explain_document |
explain_document_lg | ko |
New Healthcare Models in NLU 3.0.2
Five new resolver models:
en.resolve.umls: This model returns CUI (concept unique identifier) codes for Clinical Findings, Medical Devices, Anatomical Structures and Injuries & Poisoning terms.en.resolve.umls.findings: This model returns CUI (concept unique identifier) codes for 200K concepts from clinical findings.en.resolve.loinc: Map clinical NER entities to LOINC codes using sbiobert.en.resolve.loinc.bluebert: Map clinical NER entities to LOINC codes using sbluebert.en.resolve.HPO: This model returns Human Phenotype Ontology (HPO) codes for phenotypic abnormalities encountered in human diseases. It also returns associated codes from the following vocabularies for each HPO code:
| Model | NLU Reference | Spark NLP Reference |
|---|---|---|
| Resolver | en.resolve.umls |
sbiobertresolve_umls_major_concepts |
| Resolver | en.resolve.umls.findings |
sbiobertresolve_umls_findings |
| Resolver | en.resolve.loinc |
sbiobertresolve_loinc |
| Resolver | en.resolve.loinc.biobert |
sbiobertresolve_loinc |
| Resolver | en.resolve.loinc.bluebert |
sbluebertresolve_loinc |
| Resolver | en.resolve.HPO |
sbiobertresolve_HPO |
nlu.load('med_ner.jsl.wip.clinical en.resolve.HPO').viz("""These disorders include cancer, bipolar disorder, schizophrenia, autism, Cri-du-chat syndrome,
myopia, cortical cataract-linked Alzheimer's disease, and infectious diseases""")
nlu.load('med_ner.jsl.wip.clinical en.resolve.loinc.bluebert').viz("""A 28-year-old female with a history of gestational diabetes mellitus diagnosed eight years prior to presentation and
subsequent type two diabetes mellitus (TSS2DM), one prior episode of HTG-induced pancreatitis three years prior to presentation, associated with an acute
hepatitis, and obesity with a body mass index (BMI) of 33.5 kg/m2, presented with a one-week history of polyuria, polydipsia, poor appetite, and vomiting.""")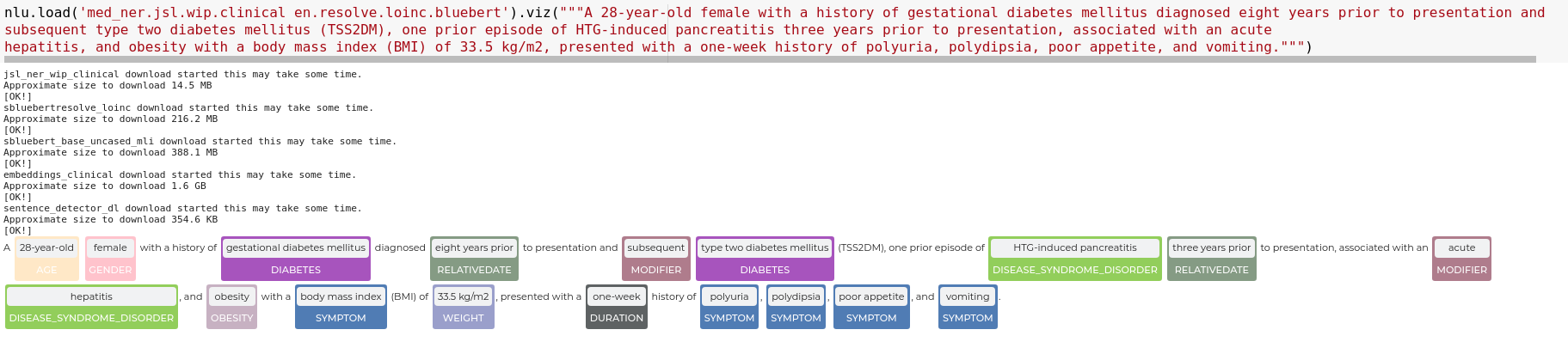
nlu.load('med_ner.jsl.wip.clinical en.resolve.umls.findings').viz("""A 28-year-old female with a history of gestational diabetes mellitus diagnosed eight years prior to presentation and
subsequent type two diabetes mellitus (TSS2DM), one prior episode of HTG-induced pancreatitis three years prior to presentation, associated with an acute
hepatitis, and obesity with a body mass index (BMI) of 33.5 kg/m2, presented with a one-week history of polyuria, polydipsia, poor appetite, and vomiting."""
)
nlu.load('med_ner.jsl.wip.clinical en.resolve.umls').viz("""A 28-year-old female with a history of gestational diabetes mellitus diagnosed eight years prior to presentation and
subsequent type two diabetes mellitus (TSS2DM), one prior episode of HTG-induced pancreatitis three years prior to presentation, associated with an acute
hepatitis, and obesity with a body mass index (BMI) of 33.5 kg/m2, presented with a one-week history of polyuria, polydipsia, poor appetite, and vomiting.""")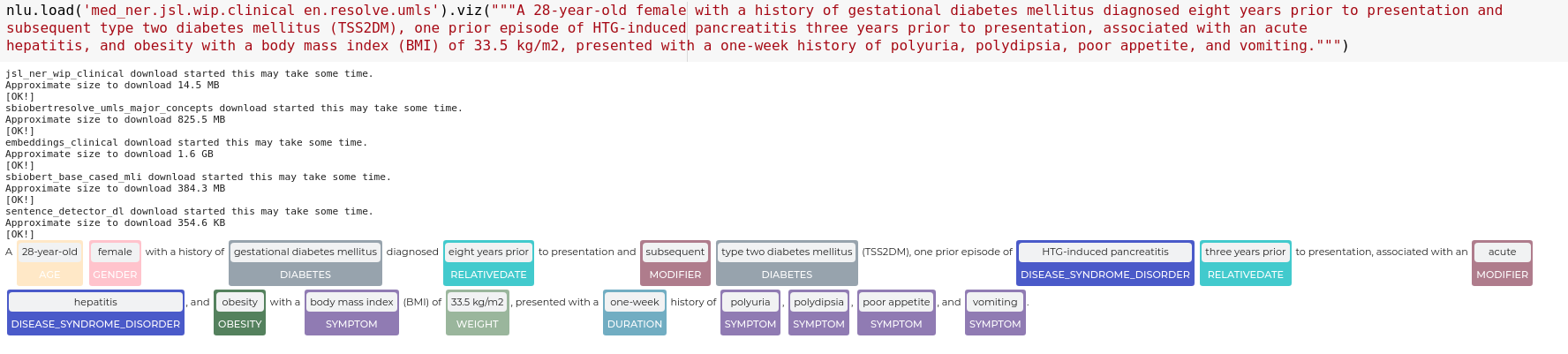
nlu.load('med_ner.jsl.wip.clinical en.resolve.loinc').predict("""A 28-year-old female with a history of gestational diabetes mellitus diagnosed eight years prior to presentation and
subsequent type two diabetes mellitus (TSS2DM), one prior episode of HTG-induced pancreatitis three years prior to presentation, associated with an acute
hepatitis, and obesity with a body mass index (BMI) of 33.5 kg/m2, presented with a one-week history of polyuria, polydipsia, poor appetite, and vomiting.""")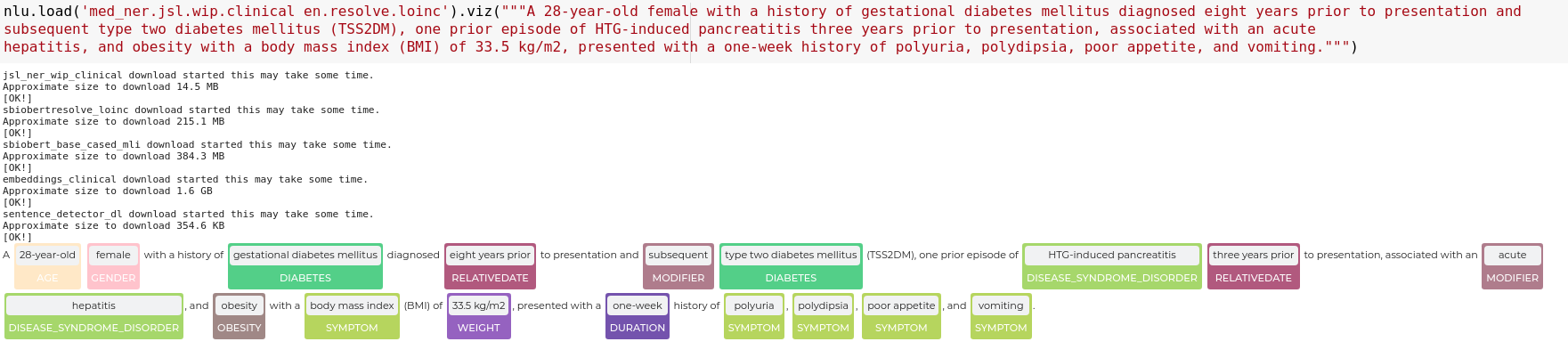
nlu.load('med_ner.jsl.wip.clinical en.resolve.loinc.biobert').predict("""A 28-year-old female with a history of gestational diabetes mellitus diagnosed eight years prior to presentation and
subsequent type two diabetes mellitus (TSS2DM), one prior episode of HTG-induced pancreatitis three years prior to presentation, associated with an acute
hepatitis, and obesity with a body mass index (BMI) of 33.5 kg/m2, presented with a one-week history of polyuria, polydipsia, poor appetite, and vomiting.""")
- 140+ tutorials
- New Streamlit visualizations docs
- The complete list of all 1100+ models & pipelines in 192+ languages is available on Models Hub.
- Spark NLP publications
- NLU in Action
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
1 line Install NLU on Google Colab
!wget https://setup.johnsnowlabs.com/nlu/colab.sh -O - | bash
1 line Install NLU on Kaggle
!wget https://setup.johnsnowlabs.com/nlu/kaggle.sh -O - | bash
Install via PIP
! pip install nlu pyspark==3.0.1