2000%+ Speedup on small data, 63 new models for 100+ Languages with 6 new supported Transformer classes including BERT, XLM-RoBERTa, alBERT, Longformer, XLnet based models, 48 NER profiling helathcare pipelines and much more in John Snow Labs NLU 3.3.0
We are incredibly excited to announce NLU 3.3.0 has been released!
It comes with a up to 2000%+ speedup on small datasets, 6 new Types of Deep Learning transformer models, including
RoBertaForTokenClassification,XlmRoBertaForTokenClassification,AlbertForTokenClassification,LongformerForTokenClassification,XlnetForTokenClassification,XlmRoBertaSentenceEmbeddings.
In total there are 63 NLP Models 6 New Languages Supported which are Igbo, Ganda, Dholuo, Naija, Wolof,Kinyarwanda with their corresponding ISO codes ig, lg, lou, pcm, wo,rw
with New SOTA XLM-RoBERTa models in Luganda, Kinyarwanda, Igbo, Hausa, and Amharic languages and 2 new Multilingual Embeddings with 100+ supported languages via XLM-Roberta are available.
On the healthcare NLP side we are glad to announce 18 new NLP for Healthcare models including
NER Profiling pretrained pipelines to run 48 different Clinical NER and 21 Different Biobert Models At Once Over the Input Text
New BERT-Based Deidentification NER Model, Sentence Entity Resolver Models For German Language
New Spell Checker Model For Drugs , 3 New Sentence Entity Resolver Models (3-char ICD10CM, RxNorm_NDC, HCPCS)
5 New Clinical NER Models (Trained By BertForTokenClassification Approach)
,Radiology NER Model Trained On cheXpert Datasetand New UMLS Sentence Entity Resolver Models
Additionally 2 new tutorials are avaiable, NLU & Streamlit Crashcourse and NLU for Healthcare Crashcourse of every of the 50 + healthcare Domains and 200+ healthcare models
New Features and Improvements
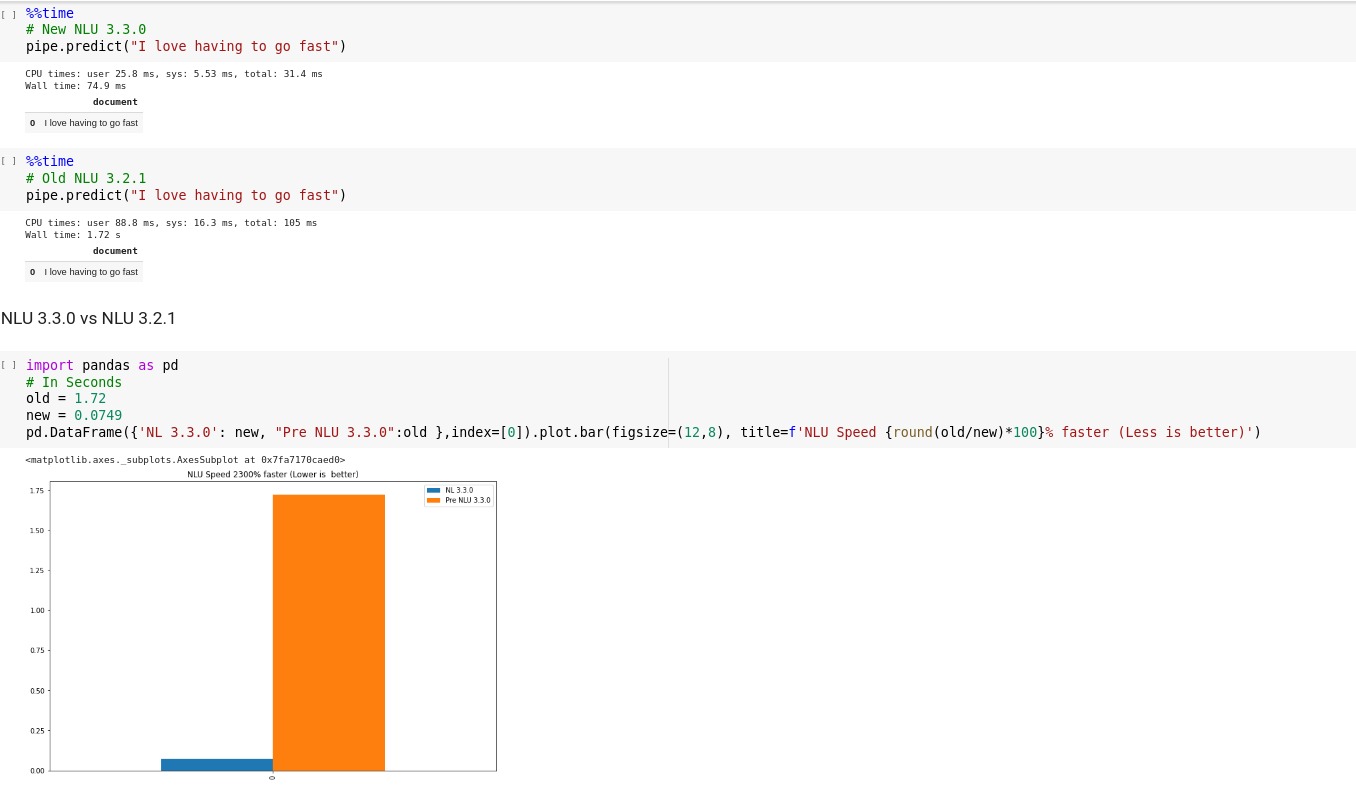
2000%+ Speedup prediction for small datasets
NLU pipelines now predict up to 2000% faster by optimizing integration with Spark NLP's light pipelines.
NLU will configure usage of this automatically, but it can be turned off as well via multithread=False
50x faster saving of NLU Pipelines
Up to 50x faster saving Spark NLP/ NLU models and pipelines! We have improved the way we package TensorFlow SavedModel while saving Spark NLP models & pipelines. For instance, it used to take up to 10 minutes to save the xlm_roberta_base model before Spark NLP 3.3.0, and now it only takes up to 15 seconds!
New Annotator Classes Integrated
The following new transformer classes are available with various pretrained weights in 1 line of code :
- RoBertaForTokenClassification
- XlmRoBertaForTokenClassification
- AlbertForTokenClassification
- LongformerForTokenClassification
- XlnetForTokenClassification
- XlmRoBertaSentenceEmbeddings
New Transformer Models
The following models are available from the amazing Spark NLP
3.3.0 and
3.3.1 releases
which includes NLP models for
Yiddish, Ukrainian, Telugu, Tamil, Somali, Sindhi, Russian, Punjabi, Nepali, Marathi, Malayalam, Kannada, Indonesian, Gujrati, Bosnian, Igbo, Ganda, Dholuo, Naija, Wolof,Kinyarwanda
New Healthcare models
The following models are available from the amazing Spark NLP for Healthcare releases
3.3.0,
3.2.3,
3.3.1,
which includes 48 Multi-NER tuning pipelines, BERT-based DEidentification, German NER resolvers, Spell Checkers for Drugs,
5 ner NER models trained via BErtForTokenClassification, NER models for Radiology CID10CM, RxNORM NDC and HCPCSS models and UMLS sentence resolver models
Updated Model Names
The nlu model references have been updated to better reflect their use-cases.
- en.classify.token_bert.conll03
- en.classify.token_bert.large_conll03
- en.classify.token_bert.ontonote
- en.classify.token_bert.large_ontonote
- en.classify.token_bert.few_nerd
- en.classify.token_bert.classifier_ner_btc
- es.classify.token_bert.spanish_ner
- ja.classify.token_bert.classifier_ner_ud_gsd
- fa.classify.token_bert.parsbert_armanner
- fa.classify.token_bert.parsbert_ner
- fa.classify.token_bert.parsbert_peymaner
- sv.classify.token_bert.swedish_ner
- tr.classify.token_bert.turkish_ner
- en.classify.token_bert.ner_clinical
- en.classify.token_bert.ner_jsl
New Tutorial Videos
- NLU & Streamlit Crashcourse
- NLU for Healthcare Crashcourse of every of the 50 + healthcare Domains and 200+ healthcare models
Optional get_embeddings parameter for pipelines
NLU pipelines can now be forced to not return embeddings via get_embeddings parameter.
Updated Compatibility Docs
Added documentation section regarding compatibility of NLU, Spark NLP and Spark NLP for healthcare
Bugfixes
- Fixed a bug with Pyspark versions 3.0 and below that caused failure of predicting with pipeline
- Fixed a bug that caused the results of TokenClassifier Models to not be properly extracted
Additional NLU ressources
- 140+ NLU Tutorials
- Streamlit visualizations docs
- The complete list of all 4000+ models & pipelines in 200+ languages is available on Models Hub.
- Spark NLP publications
- NLU in Action
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
1 line Install NLU on Google Colab
!wget https://setup.johnsnowlabs.com/nlu/colab.sh -O - | bash
1 line Install NLU on Kaggle
!wget https://setup.johnsnowlabs.com/nlu/kaggle.sh -O - | bash
Install via PIP
! pip install nlu pyspark streamlit==0.80.0