1.2 代码式开发(air)
本文以前文中的需求为例, 如果你还不了解需求, 可以点击这个地址跳转查看, 链接地址为: 1.1-需求分析
了解需求后, 我们可以按照下面的步骤进行爬虫开发, 他们分别是:
- 定义模型
- 定义种子
- 定义请求
- 定义解析
- 定义存储
- 事件拓展
首先, 你需要导入 bricks 爬虫基类, 然后定义一个类继承这个基类, 本文以代码式开发为例, 因此我们需要导入的基类的地址为: bricks.spider.air.Spider
from bricks.spider import air
class MySpider(air.Spider):
pass按照上面的代码定义完毕后, 你应该可以看到你的 IDE 的提示信息, 表示你有几个接口没有实现, 下面我们就来一一实现这些接口
该接口用于定义爬取目标, 在 bricks 内称作种子, 种子的类型是一个字典, 种子的内容是你的请求需要的一些变量. 具体种子的数量由你要爬取的目标来决定. 例如我要爬取所有的分类, 那么种子的格式应该为: {"category_id": "真实的 catgory id"} 这种格式, 因为当前案例是要爬取固定品类下的主播, 因此我们的变量就是 page, 所以种子的格式就是 {"page": 1}
from bricks.spider import air
class MySpider(air.Spider):
def make_seeds(self, context: air.Context, **kwargs):
return {"page": 1}该接口是为了将种子转化为请求对象, 也就是 bricks.spider.air.Request 对象, 这个对象是用来进行请求的, 你可以在这里定义请求的方法, 如请求连接, 请求方法, 请求头, 请求参数等等, 这里我们只需要定义请求的参数即可,
因为请求的方法是 GET, 请求的头部是默认的, 也就是 {"Content-Type": "application/json"}
from bricks import Request
from bricks.spider import air
class MySpider(air.Spider):
def make_seeds(self, context: air.Context, **kwargs):
return {"page": 1}
def make_request(self, context: air.Context) -> Request:
# 之前定义的种子会被投放至任务队列, 之后会被取出来, 迁入至 context 对象内
seeds = context.seeds
return Request(
url="https://fx1.service.kugou.com/mfanxing-home/h5/cdn/room/index/list_v2",
params={
"page": seeds["page"],
"cid": 6000
},
headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 10; Redmi K30 Pro) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Mobile Safari/537.36",
"Content-Type": "application/json;charset=UTF-8",
},
)上文中, 我们已经定义了种子和请求, 接下来就是要解决解析问题, 在需求分析中, 我们得知:
响应为 json 格式, bricks 内置了很多解析器,
其中就有 json, 可以使用 jsonpath 和 jmespath, 本文演示 jmespath 引擎, 需要实现的接口是 parse
from bricks import Request
from bricks.spider import air
class MySpider(air.Spider):
def make_seeds(self, context: air.Context, **kwargs):
return {"page": 1}
def make_request(self, context: air.Context) -> Request:
# 之前定义的种子会被投放至任务队列, 之后会被取出来, 迁入至 context 对象内
seeds = context.seeds
return Request(
url="https://fx1.service.kugou.com/mfanxing-home/h5/cdn/room/index/list_v2",
params={
"page": seeds["page"],
"cid": 6000
},
headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 10; Redmi K30 Pro) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Mobile Safari/537.36",
"Content-Type": "application/json;charset=UTF-8",
},
)
def parse(self, context: air.Context):
response = context.response
return response.extract(
engine="json",
rules={
"data.list": {
"userId": "userId",
"roomId": "roomId",
"score": "score",
"startTime": "startTime",
"kugouId": "kugouId",
"status": "status",
}
}
)
if __name__ == '__main__':
spider = MySpider()
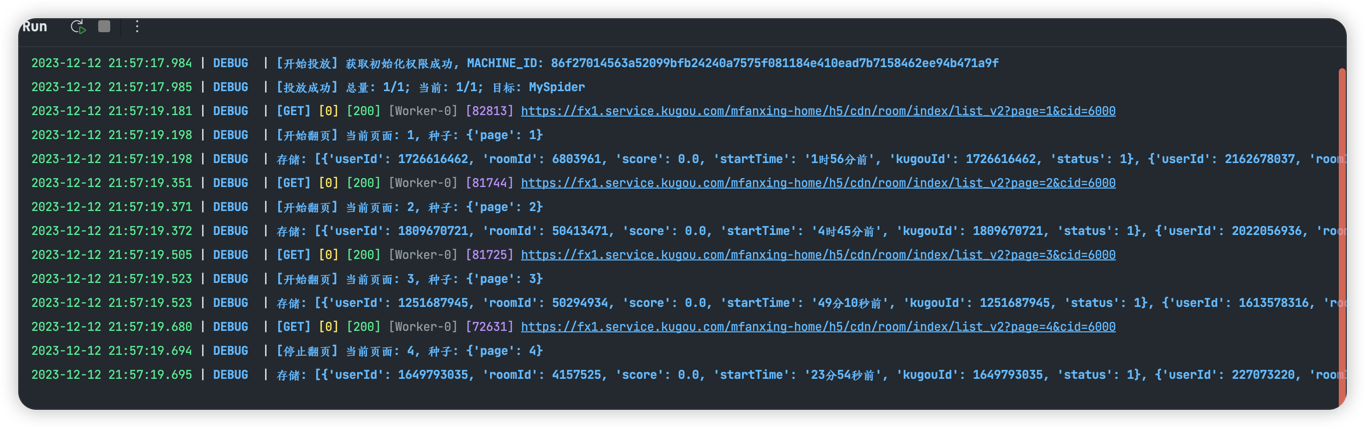
spider.run()做完这一步, 我们的爬虫就可以运行了, 在不定义存储管道的情况下, 会默认将解析得到的数据打印出来, 输出到控制台, 如下图所示:
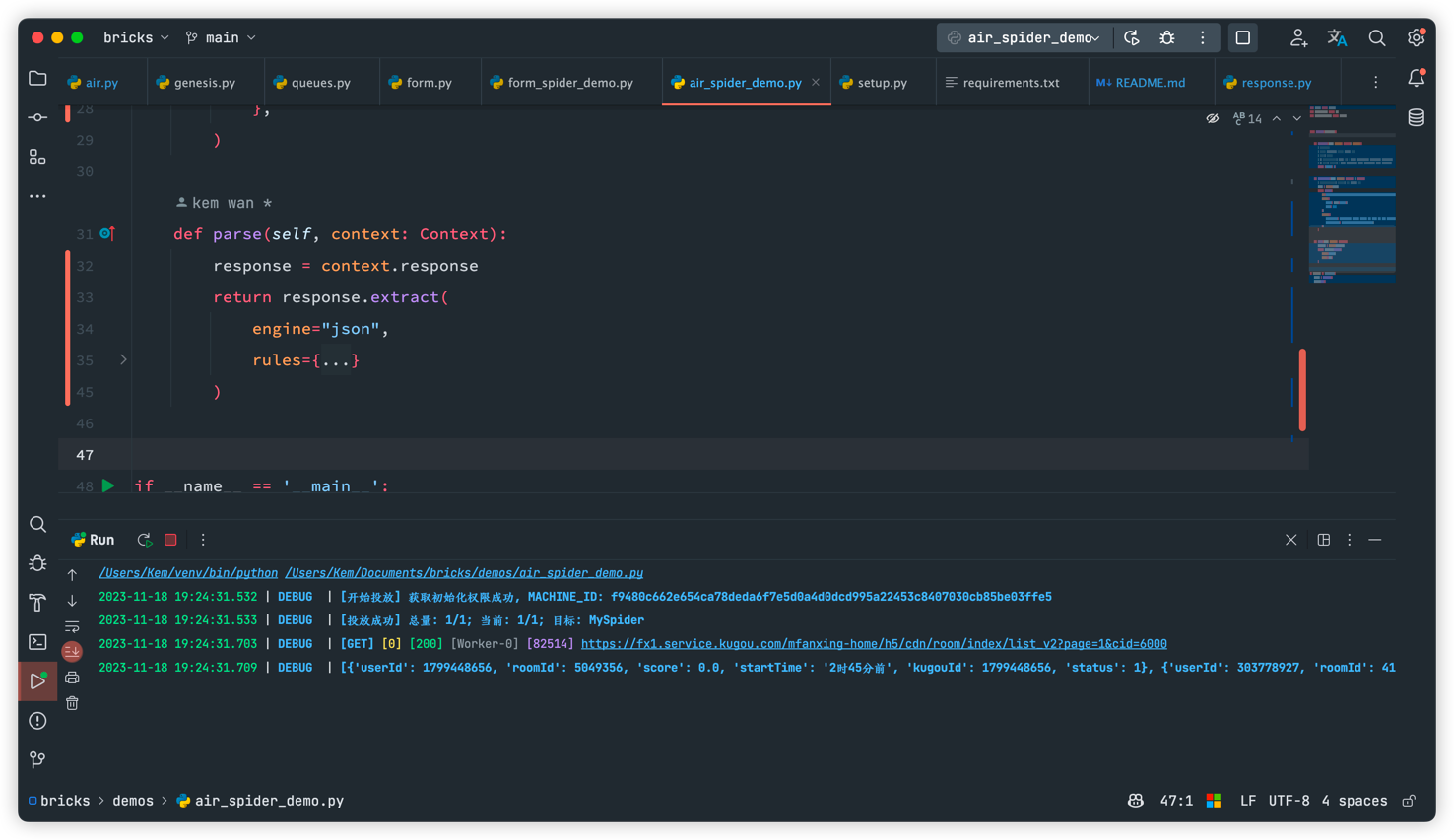
我们一般是不只是需要打印解析的, 还需要将解析的数据存储起来, 目前 bricks 也内置了几个存储引擎, 当然我们也可以自己实现存储, 本文不存储, 只做输出
from loguru import logger
from bricks import Request
from bricks.spider import air
class MySpider(air.Spider):
def make_seeds(self, context: air.Context, **kwargs):
return {"page": 1}
def make_request(self, context: air.Context) -> Request:
# 之前定义的种子会被投放至任务队列, 之后会被取出来, 迁入至 context 对象内
seeds = context.seeds
return Request(
url="https://fx1.service.kugou.com/mfanxing-home/h5/cdn/room/index/list_v2",
params={
"page": seeds["page"],
"cid": 6000
},
headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 10; Redmi K30 Pro) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Mobile Safari/537.36",
"Content-Type": "application/json;charset=UTF-8",
},
)
def parse(self, context: air.Context):
response = context.response
return response.extract(
engine="json",
rules={
"data.list": {
"userId": "userId",
"roomId": "roomId",
"score": "score",
"startTime": "startTime",
"kugouId": "kugouId",
"status": "status",
}
}
)
def item_pipeline(self, context: air.Context):
items = context.items
# 写自己的存储逻辑
logger.debug(f'存储: {items}')
# 确认种子爬取完毕后删除, 不删除的话后面又会爬取
context.success()
if __name__ == '__main__':
spider = MySpider()
spider.run()存储完之后记得调用 context.success() 方法确认种子爬取完毕, 该操作执行后会将任务队列中的种子进行删除, 以此种方式来防止种子因为异常中断丢失 (但是仅限于可持久化的队列, 例如 RedisQueue )
完成了上面的步骤, 我们已经可以消耗一个种子了, 接下来我们定义两个事件来实现请求成功判断和翻页操作.
再次之前, bricks 内置了一些事件, 如下图所示:
!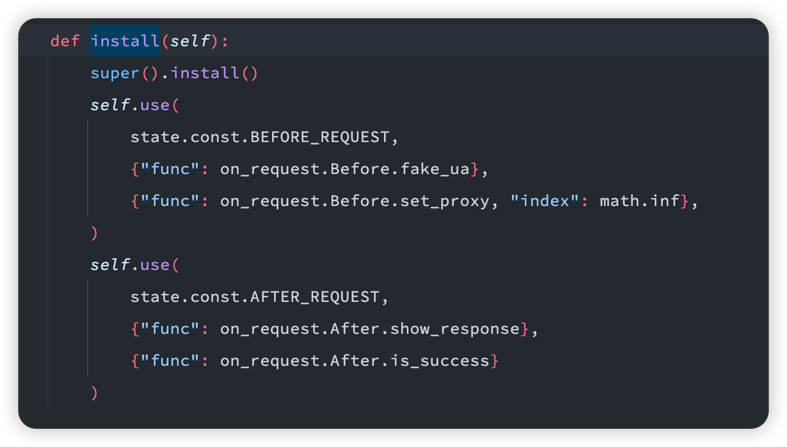
他们的功能如下:
- 请求前: 随机
ua - 请求前: 设置代理
- 请求后: 展示响应日志
- 请求后: 通用成功判断
因此你的自定义时间不需要判断状态码, 默认只有 2xx-3xx 的响应才能通过, 如果你想自定义该值, 你需要修改 request.status_codes 属性
本文的事件都比较简单, 直接使用内置的 scripts 脚本实现, 具体时候后面会详细介绍!
具体事件注册我们一般用的内置的 install 接口, 该接口会在爬虫实例化的时候自动调用一次, 你可以在这里注册你的事件, 注册采用的 spider 的 use 接口进行挂载, 代码如下:
from bricks import Request, const
from bricks.core import events
from bricks.plugins import scripts
from bricks.spider import air
from loguru import logger
class MySpider(air.Spider):
def make_seeds(self, context: air.Context, **kwargs):
return {"page": 1}
def make_request(self, context: air.Context) -> Request:
# 之前定义的种子会被投放至任务队列, 之后会被取出来, 迁入至 context 对象内
seeds = context.seeds
return Request(
url="https://fx1.service.kugou.com/mfanxing-home/h5/cdn/room/index/list_v2",
params={
"page": seeds["page"],
"cid": 6000
},
headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 10; Redmi K30 Pro) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Mobile Safari/537.36",
"Content-Type": "application/json;charset=UTF-8",
},
)
def parse(self, context: air.Context):
response = context.response
return response.extract(
engine="json",
rules={
"data.list": {
"userId": "userId",
"roomId": "roomId",
"score": "score",
"startTime": "startTime",
"kugouId": "kugouId",
"status": "status",
}
}
)
def item_pipeline(self, context: air.Context):
items = context.items
# 写自己的存储逻辑
logger.debug(f'存储: {items}')
# 确认种子爬取完毕后删除, 不删除的话后面又会爬取
context.success()
def install(self):
super().install()
self.use(
const.AFTER_REQUEST,
events.Task(
func=scripts.is_success,
kwargs={
"match": [
"context.response.get('code') == 0"
]
}
)
)
self.use(
const.BEFORE_PIPELINE,
events.Task(
func=scripts.turn_page,
kwargs={
"match": [
"context.response.get('data.hasNextPage') == 1"
]
}
)
)
if __name__ == '__main__':
spider = MySpider()
spider.run()