Scraper para baixar seus extratos do Itaú com um comando.
As APIs vieram para ficar, mas a maioria dos bancos ainda não oferecem forma fácil para seus clientes extraírem seus próprios dados. Algo tão simples quanto obter o seu extrato bancário é um sofrimento para sistematizar.
Pesquisei se existia algo pronto para o Itaú e encontrei o bankscraper do Kamus que disponibiliza vários scripts interessantes. Infelizmente o do Itaú não estava mais funcionando, mas estudando seu código encontrei uma boa dica:
O site do Itaú para computador é todo complicado para navegar com muita mágica em javascript. Mas e o site para disponsitivos móveis?
Ativei o "mobile mode" do Chrome com o Postman e o Postman Interceptor para rastrear todas as requisições e bingo. De fato é bem mais simples.
Decidi escrever este artigo para explicar o procedimento, evidenciar as bizarrices e quem sabe facilitar a manutenção futura quando algo mudar.
Este script funciona apenas para contas Pessoa Física, pois o Itaú força empresas a usarem seu aplicativo no celular não dando acesso ao site móvel pelo navegador.
O código é simples e usa Python 3 com a biblioteca requests para a navegação e lxml para a extração de dados com xpath.
Mais do que explicar o código em si, o importante é entender o fluxo de navegação que ele precisa reproduzir.
O protocolo HTTP é assíncrono exigindo que cada requisição envie novamente todas as informações necessárias. No entanto, o site do banco cria uma dinâmica cliente-servidor estabelecendo dependência entre as requisições mudando inclusive as urls de navegação. Por isso todo o processo acontece sequencialmente, cheio de etapas intermediárias que não seriam necessárias em condições normais.
Usando o requests.Session conseguimos reproduzir o efeito de navegação contínua
entre várias páginas propagando cookies e outros cabeçalhos.
A classe MobileSession implementa os cabeçalhos para nos fazermos
passar por um browser de celular.
A classe ItauScraper usa a session para realizar o login e
consultar o extrato.
Para fazer o login no site do banco é preciso acessar uma url inicial para
descobrirmos a url de login real, que muda de tempos em tempos pelo que eu entendi.
Com a url de login correta, agora é preciso fazer um novo GET para obter
informações que o ASP.NET injeta no formulário de login e então realizar o POST
efetuando a autenticação.
Depois do login feito, somos redirecionados para uma página com um menu de
navegação. Esta página não é usada no fluxo, mas quando quisermos implementar novas
funcionalidades no ItauScraper é nela que deveremos começar.
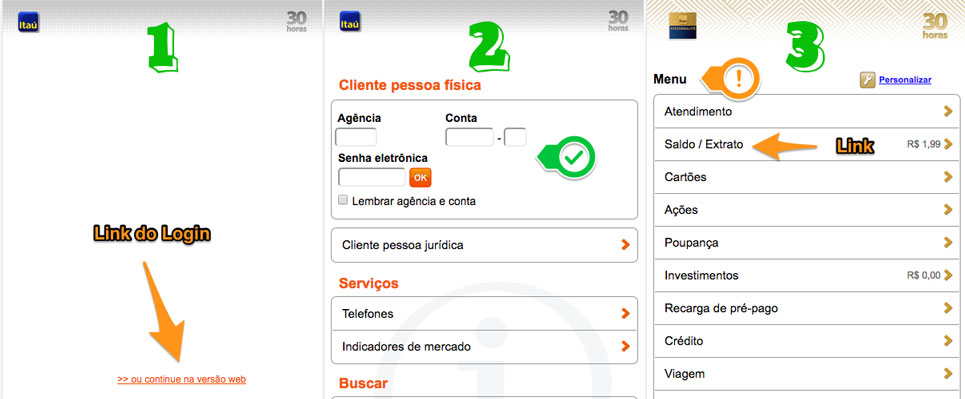
Quando acessamos a url do extrato, por padrão é exibido o extrato dos últimos 3 dias.
No fim da página do extrato tem 4 links para listar os extratos dos períodos
7, 15, 30 e 90 dias. Estas urls parecem mudar de tempos em tempos, como a do login,
então é preciso extrair o link para 90 dias e obter o extrato com outro GET.
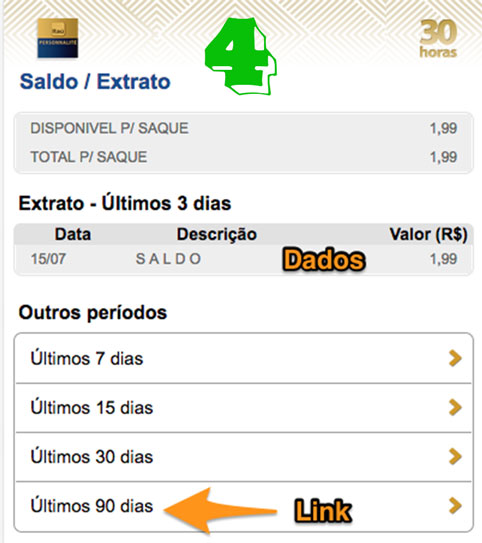
Com o extrato do maior período:
- Extraímos a informação do html;
- Reconstruímos a tabela com as colunas: data, descrição e valor;
- Filtramos as linhas de saldo que não correspondem a um lançamento;
- Convertemos cada data para o tipo
datetime.date; - Convertemos cada valor para o tipo
Decimal;
No final, temos uma tupla de tuplas na forma:
((datetime.date(2017, 1, 1), 'RSHOP-LOJA1', Decimal('-1.99')),
(datetime.date(2017, 1, 2), 'RSHOP-LOJA2', Decimal('-5.00')),
(datetime.date(2017, 1, 3), 'TBI 1234567', Decimal('10.00')))Quando acessamos a url do cartão, são exibidas 3 opções para listar:
- a fatura anterior;
- a fatura atual;
- os lançamentos parciais da próxima fatura.
Estas urls parecem mudar de tempos em tempos, então é preciso extrair o link para a fatura atual
e realizar um novo GET para obter o extrato de lançamentos.
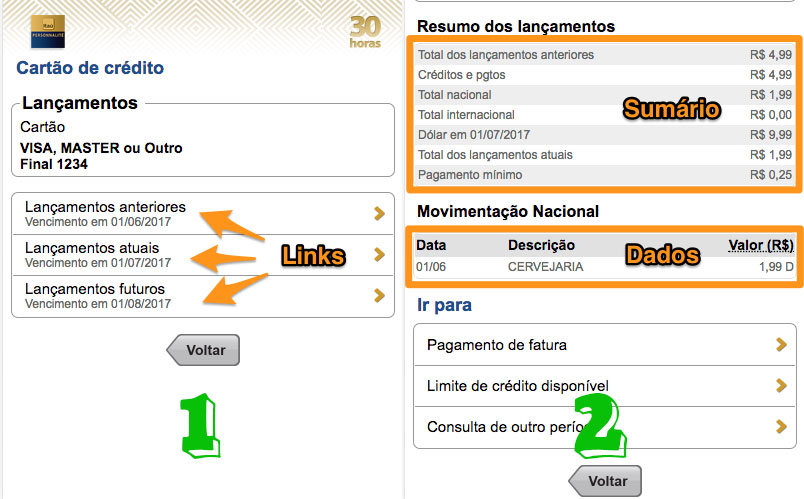
Além dos lançamentos, há na página um resumo com totais.
Com o extrato do cartão:
- Extraímos a informação do html;
- Reconstruímos o resumo como um dicionário.
- Reconstruímos a tabela com as colunas: data, descrição e valor;
- Convertemos cada data para o tipo
datetime.date; - Convertemos cada valor para o tipo
Decimal;
No final, temos um dicionário com o sumário da fatura e uma tupla de tuplas na forma:
# sumário
{'Total dos lançamentos anteriores': Decimal('4.99'),
'Créditos e pgtos': Decimal('4.99'),
'Total nacional': Decimal('1.99'),
'Total internacional': Decimal('0.00'),
'Dólar em 06/07/2017': Decimal('9.99'),
'Total dos lançamentos atuais': Decimal('1.99'),
'Pagamento mínimo': Decimal('0.25')}
# lançamentos
((datetime.date(2017, 1, 1), 'RSHOP-LOJA1', Decimal('-1.99')),
(datetime.date(2017, 1, 2), 'RSHOP-LOJA2', Decimal('-5.00')),
(datetime.date(2017, 1, 3), 'TBI 1234567', Decimal('10.00')))Use pela linha de comando:
$ itauscraper --extrato --cartao --agencia 1234 --conta 12345 --digito 6
Digite sua senha do Internet Banking:Ou:
$ itauscraper --extrato --cartao --agencia 1234 --conta 12345 --digito 6 --senha SECRETOu importe direto no seu código:
from itauscraper import ItauScraper
itau = ItauScraper(agencia='1234', conta='12345', digito='6', senha='SECRET')
itau.login():
print(itau.extrato())
print(itau.cartao())
# TODO: Divirta-se!Para conhecer todas as opções execute:
$ itauscraper -hgit clone https://github.com/henriquebastos/itauscraper.git
cd itauscraper
python -m venv -p python3.6 .venv
source .venv/bin/activate
pip install -r requirements.txtCopyright (C) 2017 Henrique Bastos.
Este código é distribuído nos termos da "GNU LGPLv3". Veja o arquivo LICENSE para detalhes.