This project seeks to classify speech toxicity through the use of machine learning models. Our toxicity ratings are derived from the Perspective API and our models were built in Python with the aid of libraries such as scikit-learn and Keras. We gathered AskReddit comments from 2005 to 2018 from pushshift.io and stored them in SQLite3 databases.
- Mikaela Guerrero
- Minh Hua
- Angel Chavez
The internet has no shortage of toxicity, including threats, derogatory comments, and other such hate speech. For example, in less than 24 hours, Twitter users unwittingly managed to force Microsoft to shut down its chatbot Tay, by teaching it to repeat extremely hate-filled discourse. As such, large social media sites (such as Reddit!) are very hard to moderate.
Before:

After:

Important in every data analysis task is the retrieval, wrangling, and cleaning of data - in this respect, our group had no shortage of challenges. The number one concern when dealing with Reddit comment data is its sheer volume - one month's worth of comments from one subreddit can take more than 5 GB to store. This roadblock generated two practical concerns: the time it takes to scrape the data, and the memory limitations Python imposes. As a result, clever data scraping and handling technique had to be implemented in order to surmount the obstacle.
In the beginning, we used the Praw API to directly scrape Reddit for comments, but this endeavour was hampered by shoddy internet connections and Python's memory limitations. As a result, we examined Pushshift.io, an online database/archive of all Reddit comments from the site's conception. The site had an API that allowed for intelligent queries of comments from specific subreddits, timeframes, alongside other criterion.
At our project's conception, we weren't clear and concise on our thesis question, which lead to a scraping pattern that was highly inefficient; we basically scraped comments from ten of the most popular subreddits, which soon proved to be impossible due to volume. As a result, once we improved upon our research question to only scrape one subreddit, we were able to much more efficiently retrieve the data.
In conclusion, in order to solve our memory problem, we utilized a SQL database and SQL batch injection. In order to solve our time problem, we used asyncio and aiohttp to send 2000 requests (scraping, labelling) at the same time, cutting down our scraping time a hundredfold; cloud computing also took out a chunk of the scraping work.
Our analysis on the toxicity of Reddit comments deals with a relatively standard machine learning problem: multi-class classification. We deal with supervised learning, which in this instance, involves training a classifier on data already labeled for toxicity in order to predict the toxicity level of other comments.
Using Perspective API's toxicity and severe toxicity models, we labeled our data with percentages that score toxicity for any given comment. We then created our own ground truth by placing comments into one of three categories (not toxic, moderately toxic, and very toxic) based on Perspective's ratings.
Our labels were created with the following thresholds:
- Not toxic
- Toxicity score is less than 40%
- Severe toxicity score is less than 75%
- Moderately toxic
- Toxicity score is greater than or equal to 40% and less than 90%
- Severe toxicity score is greater than or equal to 10%
- Very toxic
- Toxicity score is greater than or equal to 90%
- Severe toxicity score is greater than or equal to 75%

Machine learning models typically take numerical features as input. Since our Reddit data is text-based, we needed some way to transform the comments into numerical input readable by the machine learning models. Thus, we generated word embeddings from the tokenized Reddit comments using a Word2Vec skip-gram model. Word embeddings are vectorized representations of words mapped to the same vector space and positioned according to similarity. Skip-gram architecture involves taking a single word and attempting to predict words that might occur alongside the target word. We used Word2Vec's skip-gram rather than CBOW (Continuous Bag of Words) since skip-gram deals better with infrequent words.
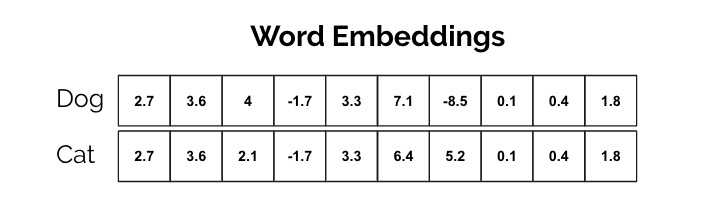
We then mapped each of the words in our dataset to their respective embeddings, with the intent of using said embeddings as feature vectors for supervised learning. We developed the following classification models:
- Logistic Regression
- Naive Bayes
- Random Forest
- Bidirectional LSTM
Each of these models took word embeddings as the input and predicted toxicity labels as the output.
Multinomial Logistic Regression is a standard model to use for text classification:
- Simple to implement with sklearn.
- Performs with good enough accuracy for a baseline model.
We chose to implement the Naive Bayes algorithm because:
- Just as with the other models, Naive Bayes performs well for multi-class text classification.
- It is simple, takes less training time, and is not prone to over fitting.
Our motivation for choosing Random Forest as one of the models were:
- It provides higher accuracy.
- This one is a no brainer. Higher accuracy = better results for days
- Random forest classifier will handle the missing values and maintain the accuracy of a large proportion of data.
- Comments are messy, ranging from single urls to sprawling paragraphs of text. As a result, there are often times Nan values that get pass our data cleaner.
- It has the power to handle a large data set with higher dimensionality
- Our dataset boasted more than 20 million comments, so a high functioning model was a necessity.
Lastly, we implemented an LSTM for the following reasons:
- We have a huge amount of data, which is required for neural networks.
- In regards to text classification, Recurrent Neural Networks typically outperform other models.
- LSTMs perform better than standard RNNs because they can access a larger frame of context.
- BiLSTMs understand context better than LSTMs.
We get an unexpected set of results using our dev sets. The Logistic Regression and Random Forest do surprisingly well, whereas the Naive Bayes and LSTM perform relatively poorly.
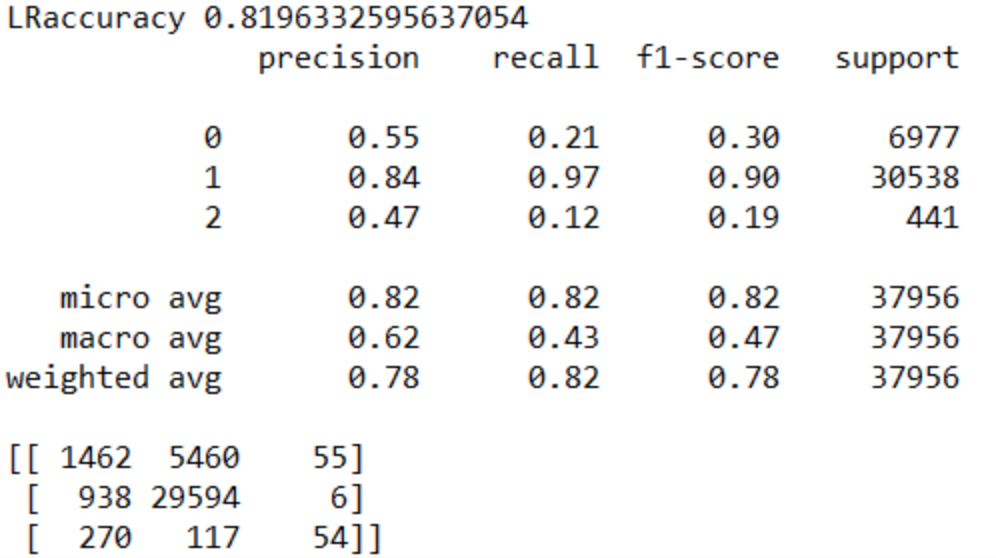
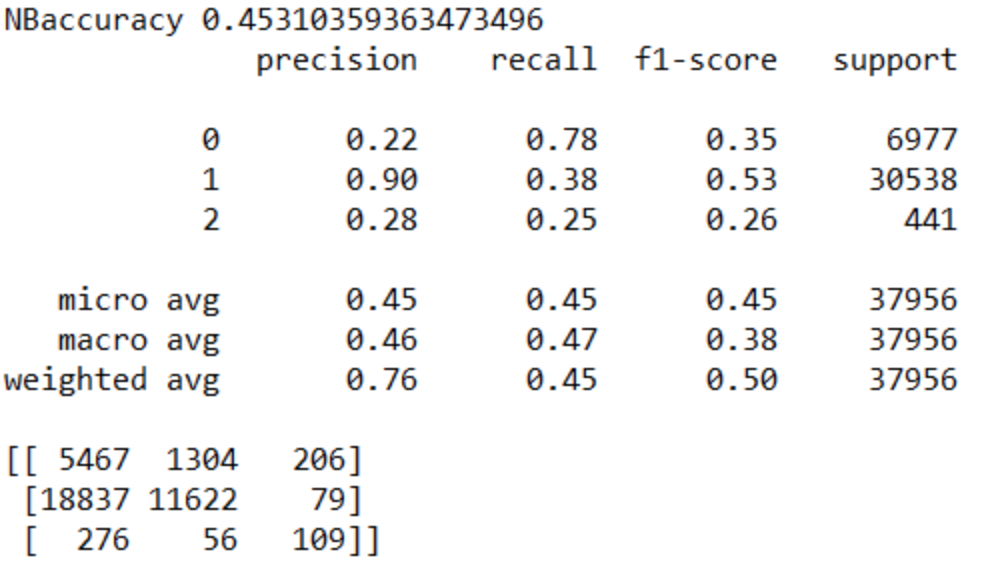
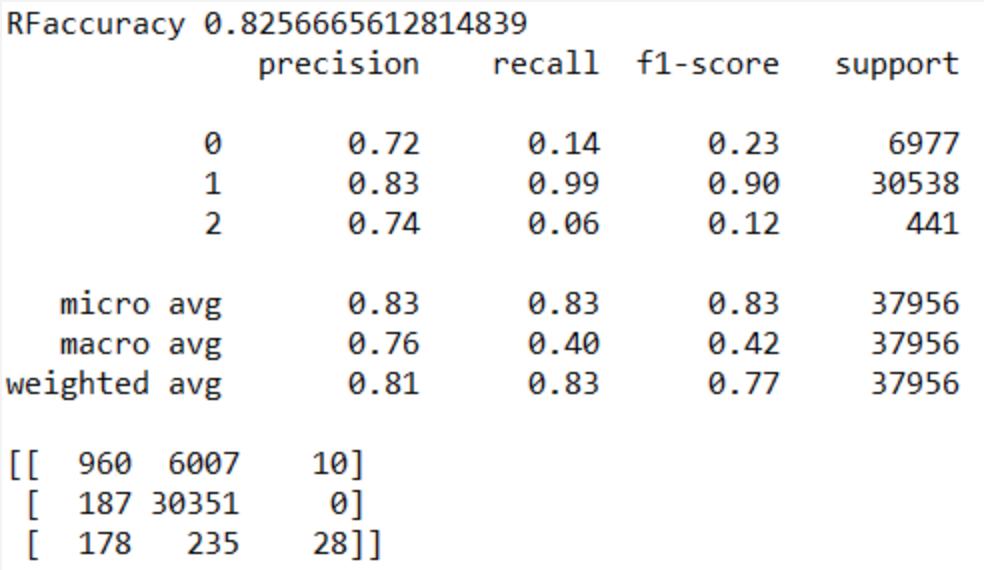

Due to the singular nature of the subject of our project, an obvious expansion is to include more subreddits. We picked AskReddit to be our object of analysis because it was one of the most popular subreddits, which meant it had plenty of comments for analyses. However, that isn't to say that there are other subreddits that are just as active, and might even feature behavior that is distinct from that of AskReddit.
Consequently, it would be interesting to see whether models trained on a specific subreddit generalize well to other subreddits. Working hypotheses include: do different subreddits generate a language or vernacular of their own? what are some of the similar or different features between subreddits? how can we aggregate separate analyses on different subreddits to potentially a "catch-all" monitor that generalizes to the whole of Reddit?
In terms of data visualization, a main goal of the group was to create an interactive web app that would chart the change in toxicitiy of AskReddit over time. We would also highlight key historical events, to see how they did or did not affect the toxicity of AskReddit. The data visualization itself is relatively simple, so there would be an emphasis on the user interface and accessibility.
