DocsSynopticCmdLineTutorial
Table of Contents:
This tutorial assumes zero knowledge of Synoptic and will walk you through all you need to know to use it.
- You should install Synoptic before going through this tutorial.
- For a brief Synoptic primer, consult the usage page.
By the end of this tutorial you will know how to:
- Compose regular expressions for Synoptic to parse typical log files
- Use the basic Synoptic command line options
- Interpret graphs generated by Synoptic
This tutorial does not make a case for why you should use Synoptic, nor does it tell you when you should use it.
In brief, Synoptic is a tool that summarizes log files. More exactly, Synoptic takes a set of log files, and some rules that tell it how to interpret lines in those log files, and outputs a summary that concisely and accurately captures the important properties of lines in the log files. Synoptic summaries are directed graphs. Sometimes we refer to Synoptic generated summaries as models, because they describe the process that produced the logs. The two terms are equivalent.
Synoptic has been developed as a command line tool, which means that to use it you will need to use a shell. However, we are currently working on graphical user interface (GUI) front-ends to Synoptic. For information regarding the Synoptic GUI options, see this page. This tutorial assumes that you're running Synoptic from the command line.
Synoptic's command line options can be grouped into the following categories:
- Required: essential options that specify required inputs -- without these Synoptic will not run
- Optional: change the behavior of how Synoptic runs, some provide convenient features, while others radically alter Synoptic's behavior
- Debugging: advanced options that you will rarely use
This tutorial covers the required and some of the optional options. So, lets jump in!
The basic command line to invoke Synoptic looks like this:
./synoptic.sh
Options are added to the end of this command line. For example, to show the basic help screen, run:
./synoptic.sh -h
To show the help screen with all possible options, run:
./synoptic.sh -H
Inevitably, your command line will get long. When this happens consider using the -c option and migrate some arguments to a file.
For example, if the file myargs contains the following text:
# (comment) This will show the help screen:
-h
Then you can reproduce the basic help screen by running:
./synoptic.sh -c myargs
The command line arguments file is parsed as follows:
- Lines starting with # are treated as comments and are ignored
- New lines are ignored
- All other lines are concatenated in the order that they appear and are treated as if they were entered on the command line
Synoptic requires the following inputs:
- Log files to analyze
- Output path prefix to use when outputting graphs and graphviz dot files
- Location of the
dotcommand executable (for generating image files of models) - A set of regular expressions that match every line in the log files (though there is a way to ignore lines, too)
If you fail to provide one of these inputs then Synoptic will fail to work. We now cover each of these inputs in more detail.
Synoptic takes a list of log files as its final command line argument. For example, the following command line passes the files file1.log and file2.log to Synoptic:
./synoptic.sh file1.log file2.log
If your shell interprets wildcards, like the bash shell, then you can pass a list of files to Synoptic with a shell regular expressions, like this:
./synoptic.sh file*.log
Synoptic needs to know where to output graphviz dot files and the associated graphics files. The -o option takes a path prefix, which means that every file Synoptic generates will begin with this string. Here is an example:
./synoptic.sh -o output/apache-trace
The above option value specifies a relative path prefix. That is, for it to work an output directory must exist in the directory where the command is run. You may also specify an absolute path prefix, such as:
./synoptic.sh -o /home/fred/output/apache-trace
Synoptic uses the Graphviz dot command to generate graphical representations of graphs. Without knowing where dot is, Synoptic can't create the pictures most users want to see. Use the -d option to tell Synoptic where to find the dot command. For example:
./synoptic.sh -d /usr/local/bin/dot
Synoptic relies on user-supplied regular expressions (Java 7 regular expressions) to parse log lines (or event instance). To parse the log lines Synoptic needs a set of regular expressions to tell it three things about each event instance:
- Event type and time value (-r)
- Trace sample partition (-s or -m)
The user can also tell Synoptic to ignore all lines that are not matched by the specified expressions using the -i option.
An event type provides abstraction. For example, consider the following log:
hello Bob
hello Alice
The above two event instances can be considered to be of type hello. The values Bob and Alice can be thought of as parameters to this type, creating unique event instances. A regular expression that parses these two lines and tells Synoptic that they have the same hello type is: ^hello .+(?<TYPE=>hello)$.
The list of regular expressions can be passed to Synoptic as a series of command line arguments, like this:
./synoptic.sh -r regex1 -r regex2 -r regex3 ...
So, the above regular expression can be passed to Synoptic with this:
./synoptic.sh -r '^hello .+(?<TYPE=>hello)$'
And if you wanted for Synoptic to analyze file1.log using this regular expression then you would run:
./synoptic.sh -r '^hello .+(?<TYPE=>hello)$' -o <outputPrefix> -d <dotCommand> file1.log
Where you filled in <outputPrefix> and <dotCommand> with the appropriate values (see above).
The reason you might want multiple regular expressions is because your log file might contain many different kinds of lines. Synoptic must be able to parse all lines in the supplied log files, so you often have to supply Synoptic with multiple regular expressions. The ordering of regular expressions is significant -- matching is attempted in the order in which the expressions are given.
Event definitions are highly flexible, and a different set of event types can create a completely different view on the log. For instance, event types can be defined dynamically based on the values in the event instance. Lets say, we expand the above log example to captures messages between nodes with the format src dst msg. A sample might look like:
node1 node2 hello Bob
node1 node3 goodbye Alice
node3 node1 re:hello
node2 node1 re:goodbye
...
If what you are interested in is learning about the sequence in which messages are exchanged from one node to another, regardless of the message contents, then you can define an event type solely in terms of src and dst. So, an event type might be node1->node2. A regular expression that would work here is: ^(?<src>\w+) (?<dst>\w+) .+(?<TYPE=>\\k<src>->\\k<dst>)$. The (?<src>\w+) and ?<dst>\w+) capture the values of src and dst, while <?TYPE=.. composes these to create a unique type of the form nodeX->nodeY. The \k<> syntax is the named-backreference syntax adopted by .NET and Java 7. These evaluate to the values captured elsewhere in the regular expression.
Typing all of the regex to handle whitespace and non-whitespace involved in typical log formats is a bit troublesome, so the named capture groups in our particular dialect of regular expressions default to a commonly desired value. (?<name>) becomes (?:\s*(?<name>\S+)\s*), which captures possible whitespace, followed by some non-whitespace, followed by some possible whitespace. The above example could therefore become ^(?<src>)(?<dst>).+(?<TYPE=>\\k<src>->\\k<dst>)$.
A time value relates event instances in an ordering relation. Synoptic supports three kinds of totally ordered time values (if no ordering is specified then Synoptic uses the implicit counting order -- all the above example have an implicit counting ordering). Here are the types of totally ordered time formats supported, and the corresponding regular expressions to parse the time explicitly.
| Integer time (32 bit) | 2 hello Bob |
^(?<TIME>) (?<TYPE>).+$ |
|---|---|---|
| Float time (32 bit) | 123.456 hello Bob |
^(?<DTIME>) (?<TYPE>).+$ |
| Double time (64 bit) | 123.456 hello Bob |
^(?<FTIME>) (?<TYPE>).+$ |
To compare two integer/double/float timestamps Synoptic uses numeric comparison operators.
In addition to total orderings, Synoptic also supports partial ordering. A partial ordering is one in which two elements, say e1 and e2, might not be comparable -- e1 != e2, e1 < e2 is false, and e1 > e2 is false. Partial ordering might be useful to reason about the ordering of events in a distributed system or a multi-threaded application. In these settings lack of order is useful because it can be interpreted as concurrency.
Currently, Synoptic supports just one kind of partial ordering format -- a vector timestamps format:
| Vector time | 1,2,3 hello Bob |
^(?<VTIME>) (?<TYPE>).+$ |
|---|
To compare two vector timestamps v1 and v2 Synoptic uses the following rule:
v1 < v2 iff ( ( v1[i] <= v2[i] for all i) and ( exists j such that v1[j] < v2[j] ) )
Synoptic assumes that the log containing the partial ordering is complete. That is, it is possible to implicitly map each log line to a process based on the vector timestamps. This is not possible if the log contains a subset of events that occurred in the system. In this case, Synoptic allows the user to specify the process identifier to explicitly map each log line with a vector timestamp to a process that executed the event. For this, users can use the (?<PID>) named group. For example, consider the following (incomplete) partially ordered log:
1,2,3 node0 read
1,4,3 node1 write
2,2,3 node0 write
...
This log can be parsed with the following regular expression: ^(?<VTIME>) (?<PID>)(?<TYPE>)$.
Synoptic mines properties, or invariants, from the log to help it construct a graph that is as accurate as possible. At the moment Synoptic mines three types of temporal invariants that relate event types. You can read more about these invariants and Synoptic's mining algorithm on this page.
Often, invariants hold true on just a portion of the log. For example, a user interested in invariants present in the log of a transaction processing system might be more interested in invariants that hold true per transaction than those that hold true for the entire log. To support such use cases Synoptic allows users to group event instances into sets, over which Synoptic then mines invariants. It support two ways of doing so: partitions, and separators.
By passing in a partition map expression, via -m, you may provide a string with references to fields in the event. After substituting these values, the resulting string is used to identify which set the particular event belongs. In other words, if your log looked like this:
0 ABC
1 QWE
0 DEF
1 RTY
then -r "(?<id>) (?<type>)" -m "\k<id>" would partition it into {ABC, DEF} and {QWE, RTY}.
This is also a good place to mention another type of special field type: FILE. This stores the absolute path to the file from which a trace was loaded. This allows you to partition traces based on which file they came from. -m "\k<FILE>" is the default value.
If your log contains a series of partitions, sequentially one after another, then instead of the -m option described above you should use the -s separator option. With the -s option you specify a delimiter, which, when match indicates the boundary between distinct partitions. That is, log lines below and above the line that matches the -s expression are placed into different partitions. Here is an example log where this might be applied:
User1:
a
b
User2:
a
d
User3:
b
d
The UserX lines act as separators. Therefore you can use -s "User*" to partition this trace into three partitions: {a, b}, {a, d}, and {b, d}.
<a href='Hidden comment: IB: this belongs in an advanced tutorial.
Separators are actually sugar implemented in terms of the other parsing features. They are work by augmenting the separator expression with an incrementor, (?<SEPCOUNT++>) , and adding \k to the partitioner. Incrementors work by maintaining context fields, which start at 0, and are added as a field to every traceline. Each time a line with an increment statement is successfully parsed, the appropriate variables are incremented. If instead, preincrement is used: (?<++X>) , the field is incremented before setting the value for the currently parsed line. '>
In some cases it is desirable to exclude certain lines in the file from the analysis (comments, whitespace, etc). To handle this the special HIDE field can be set to true, eg (?<HIDE=>true) as part of a regex that matches those lines that should be excluded.
As always, the order of the provided -r regular expressions is significant. If HIDE is used in the first parsing expression, it is effectively filtering which type of expressions to not consider. For example, If you don't want the parser to raise errors on lines which don't match your expressions, use .*(?<HIDE=>true) for the last one (you can also achieve the same behavior by using the --ignoreNonMatchingLines=true option, which can be abbreviated as -i).
Consider the traces/TwoPhaceCommit/2pc_3nodes_100tx.log file that is distributed with the Synoptic repository. The log has lines that looks like:
TM, 0, tx_prepare, 0
TM, 1, tx_prepare, 0
TM, 2, tx_prepare, 0
0, TM, abort, 0
1, TM, commit, 0
...
TM, 0, tx_prepare, 1
You can run Synoptic on traces/TwoPhaceCommit/2pc_3nodes_100tx.log with the commands: ./synoptic.sh -r '^(?<sender>),(?<receiver>),(?<TYPE>),(?<txId>)' -m '\\k<txId>' -o output/twopc ./traces/TwoPhaseCommit/2pc_3nodes_100tx.log
The regex will match the lines listed as the following:
| Line number | <sender> |
<receiver> |
<TYPE> |
<txID> |
|---|---|---|---|---|
| 1 | TM | 0 | tx_prepare | 0 |
| 2 | TM | 1 | tx_prepare | 0 |
| 3 | TM | 2 | tx_prepare | 0 |
| 4 | 0 | TM | abort | 0 |
| 5 | 1 | TM | commit | 0 |
| 6 | TM | 0 | tx_prepare | 1 |
The argument -m \\<txID> would make Synoptic partition the trace by txID, so line 6 would be in a different set from line 1-5. This allows you to analyze the sequence of message types that follow one another.
Synoptic determined the following invariants after parsing the entire log file as specified:
- INITIAL AlwaysFollowedBy(t) tx_prepare
- abort AlwaysFollowedBy(t) tx_abort
- abort AlwaysPrecedes(t) tx_abort
- abort NeverFollowedBy(t) tx_commit
- abort NeverFollowedBy(t) tx_prepare
- commit AlwaysPrecedes(t) tx_commit
- commit NeverFollowedBy(t) tx_prepare
- tx_abort NeverFollowedBy(t) abort
- tx_abort NeverFollowedBy(t) commit
- tx_abort NeverFollowedBy(t) tx_commit
- tx_abort NeverFollowedBy(t) tx_prepare
- tx_commit NeverFollowedBy(t) abort
- tx_commit NeverFollowedBy(t) commit
- tx_commit NeverFollowedBy(t) tx_abort
- tx_commit NeverFollowedBy(t) tx_prepare
- tx_prepare AlwaysPrecedes(t) abort
- tx_prepare AlwaysPrecedes(t) commit
- tx_prepare AlwaysPrecedes(t) tx_abort
- tx_prepare AlwaysPrecedes(t) tx_commit
After refinement, Synoptic will output the following model for {{{traces/TwoPhaceCommit/2pc_3nodes_100tx.log}}
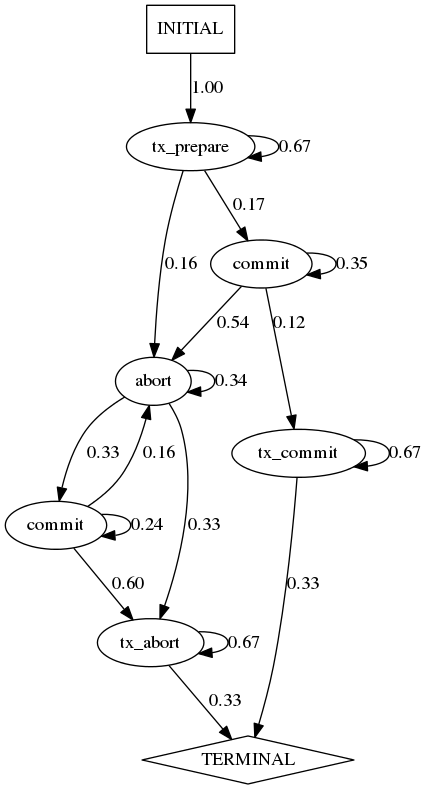
Each node in the model represents an event type, with the edges and their labels representing event transitions and their probability of occurring. The above model shows that the initial state is always tx_prepare, transitioning with 67% chance to another tx_prepare, 16% to an abort, and 17% chance to a commit event. Then through a series of aborts, commit, tx_commit, or tx_abort, each with their probability of occurring as labeled, the system will reach one of tx_abort or tx_commit before termination.
The /traces/abstract/osx-login-example/trace-full.txt file that is distributed has lines that looks like:
loginwindow[35]: Login Window Started Security Agent
May 20 16:15:27 my-mac SecurityAgent[130]: Showing Login Window
May 20 16:29:19 my-mac SecurityAgent[130]: User info context values set for jenny
May 20 16:29:19 my-mac authorizationhost[129]: Failed to authenticate user <jenny> (tDirStatus: -14090).
May 20 16:29:22 my-mac SecurityAgent[130]: User info context values set for jenny
May 20 16:29:22 my-mac SecurityAgent[130]: Login Window Showing Progress
May 20 16:29:22 my-mac SecurityAgent[130]: Login Window done
May 20 16:29:22 my-mac com.apple.SecurityServer[23]: Succeeded authorizing right 'system.login.console' by client '/System/Library/CoreServices/loginwindow.app' for authorization created by '/System/Library/CoreServices/loginwindow.app'
You can run Synoptic on /traces/abstract/osx-login-example/trace-full.txt with the commands: ./synoptic.sh -o osx-login-example -r ".+User\sinfo.+guest\$(?<TYPE=>guest_login)" -r ".+User\sinfo.+(?<TYPE=>login_attempt)" -r ".+Failed\sto\sauthenticate.+(?<TYPE=>failed_auth)" -r ".+Login\sWindow\sdone\$(?<TYPE=>authorized)" -s ".+Succeeded\sauthorizing.+" -i ./traces/abstract/osx-login-example/trace-full.txt
This command specifies four -r options to use three regex statements to parse the log file. The first regex ".+User\sinfo.+guest$(?<TYPE=>guest_login)" will match lines of the event type "guest_login". The second regex ".+User\sinfo.+(?<TYPE=>login_attempt)" will match lines of event type "login_attempt". The third regix ".+Failed\sto\sauthenticate.+(?<TYPE=>failed_auth)" will match all failed authorizations to type "failed_auth". And the fourth regex ".+Login\sWindow\sdone$(?<TYPE=>authorized)" will match all lines to event type "authorized".
The -s option commands Synoptic to separate the log lines above and below the matching regex into distinct partitions. For this log, Synoptic will group all lines above the line matching ".+Succeeded\sauthorizing.+" into one partition and all lines below it to another partition. You can then focus on the sequence of events that leads to an authorized login.
The log file contains lines that do not match any of the supplied regex, such as "loginwindow35: Login Window Started Security Agent". The -i option specifies Synoptic to ignore these non-matching lines.
The following invariants are mined by Synoptic given the above regex and log:
- INITIAL AlwaysFollowedBy(t) authorized
- authorized NeverFollowedBy(t) authorized
- authorized NeverFollowedBy(t) failed_auth
- authorized NeverFollowedBy(t) guest_login
- authorized NeverFollowedBy(t) login_attempt
- failed_auth AlwaysFollowedBy(t) authorized
- failed_auth NeverFollowedBy(t) guest_login
- guest_login AlwaysFollowedBy(t) authorized
- guest_login NeverFollowedBy(t) failed_auth
- guest_login NeverFollowedBy(t) guest_login
- guest_login NeverFollowedBy(t) login_attempt
- login_attempt AlwaysFollowedBy(t) authorized
- login_attempt AlwaysPrecedes(t) failed_auth
- login_attempt NeverFollowedBy(t) guest_login
After refinement, Synoptic will output the following model for /traces/abstract/osx-login-example/trace-full.txt
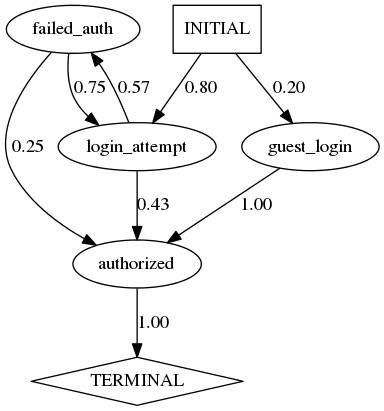
From the above graph, you can analyze the sequence of events that follow each other for an OSX login. The output also highlights a bug in the system, as a failed_authorization event can be followed by an authorized event. This information can be used to identify bugs in the system.