Hyperparameter optimization in machine learning intends to find the hyperparameters of a given machine learning algorithm that deliver the best performance as measured on a validation set. While model parameters are learned during training — such as the slope and intercept in a linear regression — hyperparameters must be set by the data scientist before training.
The core algorithms for hyperparameter optimization, found in the Scikit-learn package, are grid search and random search. Recently, the Scikit-learn contributors have also added the halving algorithm to improve the performances of both grid search and random search strategies.
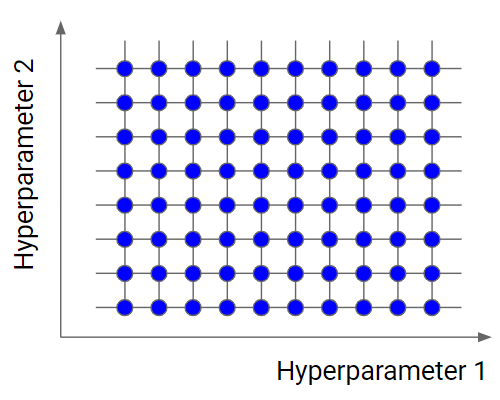
Grid search is a tuning technique that attempts to compute the optimum values of hyperparameters. It is an exhaustive search that is performed on a the specific parameter values of a model. The model is also known as an estimator.
Basically, we divide the domain of the hyperparameters into a discrete grid. Then, we try every combination of values of this grid, calculating some performance metrics using cross-validation. The point of the grid that maximizes the average value in cross-validation, is the optimal combination of values for the hyperparameters.
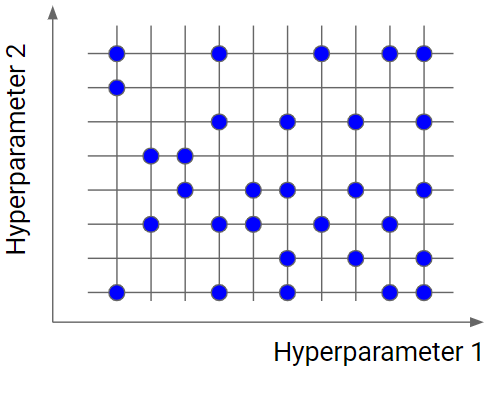
Random search is similar to grid search, but instead of using all the points in the grid, it tests only a randomly selected subset of these points. The smaller this subset, the faster but less accurate the optimization. The larger this dataset, the more accurate the optimization but the closer to a grid search.
Random search is a very useful option when you have several hyperparameters with a fine-grained grid of values. Using a subset made by 5-100 randomly selected points, we are able to get a reasonably good set of values of the hyperparameters. It will not likely be the best point, but it can still be a good set of values that gives us a good model.
Grid search and random search work in an uninformed way: if some tests find out that certain hyperparameters do not impact the result or that certain value intervals are ineffective, the information is not propagated to the following searches.
Scikit-learn has recently introduced the HalvingGridSearchCV and HalvingRandomSearchCV estimators, which can be used to search a parameter space using successive halving applied to the grid search and random search tuning strategies.
In halving, a large number of hyperparameter combinations are evaluated in an initial round of tests but using a small amount of computational resources.
In this notebook, I have written a class where we should input X, y, paramater space and metric score which hyperparamater optimization strategy should maximize. By using this class, we can compare all four basic methods on the provided dataset.
Class has two methods:
show_confusion_matrix() - run all strategies and evaluate models. Then show confusion matrix for each strategy.
run_and_show_results() - runs all strageties and return dataframe that has following features: name, best_params, best_score, run_time
We can change:
estimator - select your favorite estimator for modeling. :)
p_space - if you dont mind estimator, but want to change paramater space, just define a dictionary and write down your own space. ps: if you have changed estimator, dont forget to change p_space as well.
metric - Not sure about accuracy? No problem. Evaluate your strategies with roc_auc, f1_score, and etc.
The key idea behind Bayesian optimization is that we optimize a proxy function (the surrogate function) instead than the true objective function (what actually grid search and random search both do). This holds if testing the true objective function is costly (if it is not, then we simply go for random search.
Bayesian search balances exploration against exploitation. At start it randomly explores, doing so it builds up a surrogate function of the objective. Based on that surrogate function it exploits an initial approximate knowledge of how the predictor works in order to sample more useful examples and minimize the cost function at a global level, not a local one.
Bayesian Optimization uses an acquisition function to tell us how promising an observation will be. In fact, to rule the tradeoff between exploration and exploitation, the algorithm defines an acquisition function that provides a single measure of how useful it would be to try any given point.

Keras Tuner is an easy-to-use, distributable hyperparameter optimization framework that solves the pain points of performing a hyperparameter search. Keras Tuner makes it easy to define a search space and leverage included algorithms to find the best hyperparameter values. Keras Tuner comes with Bayesian Optimization, Hyperband, and Random Search algorithms built-in, and is also designed to be easy for researchers to extend in order to experiment with new search algorithms.
Hyperband optimization is a variation of random search with explore-exploit theory to find good hyperparameters settings. It focuses on speeding up random search through adaptive resource allocation and early stopping.
It randomly allocates resources like iterations, data samples, and features to different hyperparameters settings and tries to solve stochastic bandit problems where it keeps on eliminating underperforming settings.
On the other hand, Bayesian optimization uses Bayes theorem to find the best hyperparameters settings as we mentioned earlier.
The Hyperparameter Optimization for Machine Learning algorithm is an essential part of building ML models to enhance model performance. Tuning machine learning models manually can be a very time-consuming task. In this project, I have experimented optimization techniques both for classicial Machine Learning and Deep Learning models.