{kind=link}
The Llama_RAG_System is a robust retrieval-augmented generation (RAG) system designed to interactively respond to user queries with rich, contextually relevant answers. Built using the LLaMA model and Ollama, this system can handle various tasks, including answering general questions, summarizing content, and extracting information from uploaded PDF documents. The architecture utilizes ChromaDB for efficient document embedding and retrieval, while also incorporating web scraping capabilities to fetch up-to-date information from the internet.
Here’s a glimpse of the Gradio app interface:
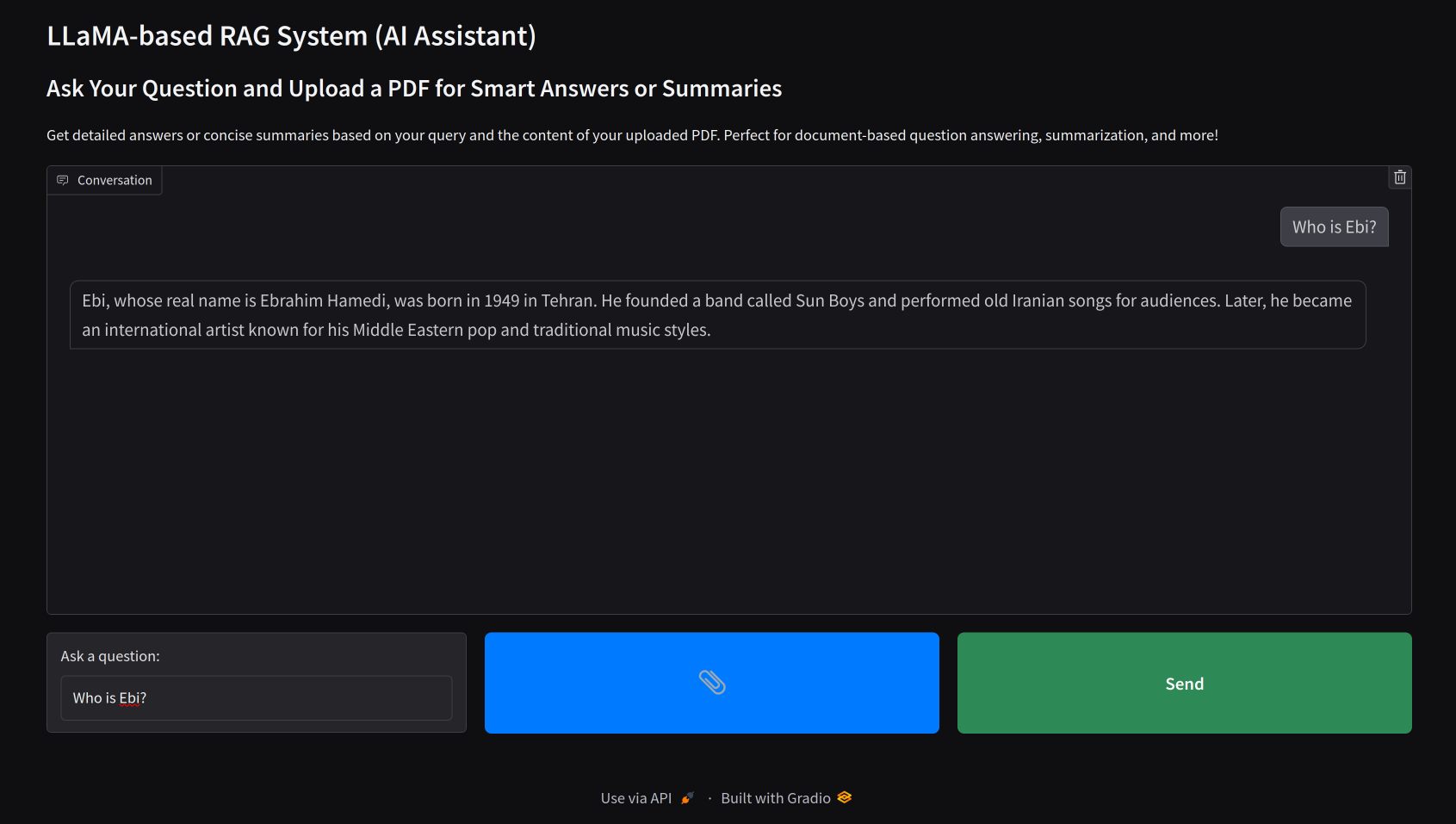
🚧 Please note: This project is currently in development. Your feedback and contributions are welcome!
- Local Model Execution with Ollama: Utilizes Ollama to run the LLaMA model locally, ensuring faster responses and enhanced privacy. By keeping the data processing local, users can maintain control over their information without sending it to external servers.
- Web Scraping for Updated Answers: Scrapes the internet to provide real-time, relevant information, allowing the system to deliver accurate responses based on the latest data.
- PDF Document Processing: Upload PDF files for automatic text extraction and embedding.
- Dynamic Query Handling: Automatically detects the type of user queries (general questions, summarization, chit-chat, etc.) and provides appropriate responses.
- Gradio and Flask Interfaces: User-friendly web interfaces for interacting with the model and uploading documents.
- Custom Embeddings: Utilizes ChromaDB to store and retrieve document embeddings efficiently.
Ollama is an excellent option for running machine learning models locally for several reasons:
- Privacy: Running the model on local infrastructure ensures that sensitive data remains within the user's environment, minimizing the risk of data breaches or leaks.
- Performance: Local execution reduces latency, allowing for quicker response times compared to cloud-based solutions.
- Customization: Users can fine-tune the model to meet specific needs without depending on external service providers.
The project is organized as follows:
project/
├── core/
│ ├── embedding.py # Embedding-related functionality
│ ├── document_utils.py # Functions to handle document loading and processing
│ ├── query.py # Query document functionality
│ ├── generate.py # Response generation logic
│ ├── web_scrape.py # Web scraping functionality
│
├── scripts/
│ ├── run_flask.py # Script to run Flask API
│ ├── run_gradio.py # Script to run Gradio interface
│
├── chromadb_setup.py # ChromaDB setup and connection
│
├── README.md # Project documentation
To set up the Llama_RAG_System, follow these steps:
-
Clone the repository:
git clone https://github.com/NimaVahdat/Llama_RAG_System.git cd Llama_RAG_System -
Ensure that ChromaDB and any other necessary services are running as needed.
To start the Flask API, run the following command:
python -m scripts.run_flaskTo launch the Gradio interface, execute:
python -m scripts.run_gradioAfter running either script, you will be able to interact with the system via the provided web interface.
Contributions are welcome! If you have suggestions for improvements or features, please fork the repository and submit a pull request.
This project is licensed under the MIT License - see the LICENSE file for details.
- LLaMA for the underlying model architecture.
- Ollama for local execution of machine learning models, enhancing privacy and performance.
- Gradio for the interactive interface.
- ChromaDB for efficient document storage and retrieval.
For any inquiries or support, please contact me.