Free, Real-time Flight Status Pipeline with Kafka, Schemas Registry, Avro, GraphQL, Postgres, and React Part 1
In an increasingly interconnected world, having real-time access to reliable and relevant information is no longer a luxury but a necessity. This is particularly true in the airline industry where thousands of flights are conducted every day worldwide. Passengers, airlines, airports, and even regulators require accurate and up-to-date flight status information. Flight delays can have significant consequences ranging from passenger irritation to major disruptions in the entire air transport system.
One of our clients, a major airline, recently approached us with a significant challenge: how could they provide their customers with real-time flight status information in a reliable and scalable manner? Their existing system, based on outdated technologies, couldn’t keep up with the growing demand for real-time data. Moreover, they struggled with the increasing complexity of data, with disparate data formats and a lack of clear standards.
To address this challenge, we designed and implemented a real-time data pipeline based on a combination of cutting-edge technologies: Kafka, Schemas Registry, Avro, GraphQL, Postgres, and React.
Apache Kafka was chosen as the backbone of our system due to its ability to handle large volumes of real-time data reliably and at scale. Kafka enabled us to capture and disseminate real-time flight status data from various sources.
Schemas Registry and Avro were used to manage the complexity of the data. Schemas Registry allowed us to define and manage data schemas centrally, thus ensuring data consistency and interoperability. Avro, on the other hand, enabled us to serialize data in a compact and efficient format.
For querying the real-time data, we used GraphQL. With GraphQL, we could provide a flexible and efficient query interface that allows clients to get exactly the information they need, without unnecessary overhead.
The data is stored in a Postgres database, known for its robustness, reliability, and ability to efficiently handle large volumes of data.
Finally, we used React to create an intuitive and responsive user interface that allows users to see the real-time flight status.
---
version: '3.9'
services:
zookeeper:
image: confluentinc/cp-zookeeper:${CONF_VER}
platform: linux/amd64
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
healthcheck:
test: nc -z localhost 2181 || exit -1
start_period: 15s
interval: 5s
timeout: 10s
retries: 30
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-server:${CONF_VER}
platform: linux/amd64
hostname: broker
container_name: broker
depends_on:
zookeeper:
condition: service_healthy
ports:
- "9092:9092"
- "9101:9101"
healthcheck:
test: nc -z localhost 9092 || exit -1
start_period: 15s
interval: 5s
timeout: 10s
retries: 30
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'false'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
schema-registry:
image: confluentinc/cp-schema-registry:${CONF_VER}
platform: linux/amd64
hostname: schema-registry
container_name: schema-registry
depends_on:
broker:
condition: service_healthy
ports:
- "8081:8081"
healthcheck:
test: nc -z localhost 8081 || exit -1
start_period: 30s
interval: 20s
timeout: 60s
retries: 300
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
kafdrop:
image: obsidiandynamics/kafdrop
restart: "no"
ports:
- "9090:9000"
environment:
KAFKA_BROKERCONNECT: broker:29092
JVM_OPTS: -Xms16M -Xmx48M -Xss180K -XX:-TieredCompilation -XX:+UseStringDeduplication -noverify
depends_on:
- broker
db:
image: postgres
restart: always
environment:
POSTGRES_PASSWORD: mysecretpassword
volumes:
- postgres_data:/var/lib/postgresql/data/
ports:
- 5433:5432
pgadmin:
image: dpage/pgadmin4
restart: always
environment:
PGADMIN_DEFAULT_EMAIL: [email protected]
PGADMIN_DEFAULT_PASSWORD: root
ports:
- 8088:80
volumes:
- pgadmin_data:/var/lib/pgadmin
depends_on:
- db
volumes:
postgres_data:
pgadmin_data:
file is defining a multi-container application for a real-time data pipeline system. Here’s a summary of the services it contains:
-
Zookeeper: This service uses the confluentinc/cp-zookeeper image and exposes port 2181. It's given a health check configuration to ensure it's running correctly. The environmental variables are setting the client port and tick time.
-
Broker: The Broker service is built on the confluentinc/cp-server image and depends on the Zookeeper service being healthy. This service exposes ports 9092 and 9101 and has several environmental variables for Kafka configuration. It also has a health check similar to the Zookeeper service.
-
Schema-Registry: This service uses the confluentinc/cp-schema-registry image and depends on the Broker service. It exposes port 8081 and is configured with environmental variables for the schema registry host name, bootstrap servers, and listeners. It has a health check configured similarly to the other services.
-
Kafdrop: Kafdrop is a web UI for viewing Kafka topics and browsing consumer groups. This service uses the obsidiandynamics/kafdrop image, exposes port 9090, and depends on the Broker service. It also has an environment variable to connect to the Kafka broker and to set JVM options.
-
db: This service is a Postgres database, using the standard postgres image. It restarts automatically if it stops, and it's configured with a password through an environment variable. The database data is stored on a Docker volume called postgres_data, and the service exposes port 5433.
-
pgadmin: This is a web-based PostgreSQL database browser. The dpage/pgadmin4 image is used for this service, and it also restarts automatically. It depends on the db service. Default email and password for pgAdmin are provided through environment variables. The pgadmin_data volume is used to persist pgAdmin data, and the service exposes port 8088.
-
Environment Setup: The script begins by loading the environment variables using dotenv. It specifically fetches an access_key from the environment variables, which will be used to make the API request to the Aviation Stack API.
-
Data Fetching: The script then sends a GET request to the Aviation Stack API to fetch the flight data. The request URL and parameters are set, with the access_key included in the parameters. If the request fails for any reason, the script will raise an exception.
-
AvroProducer Configuration: The script then defines the configuration for an AvroProducer. The bootstrap.servers and schema.registry.url are specified in the configuration.
-
Avro Schema Loading: The Avro schema for the flight data (both value schema and key schema) is loaded from the specified file paths.
-
Producer Initialization: An AvroProducer is then created using the configuration and schema.
-
Data Processing and Message Production: The script then iterates over the flight data fetched from the API. For each flight, it generates a unique id, checks and corrects the codeshared field if it's None, and converts the delay field to a string if it exists. It then sends a message to the Kafka topic named 'flights' with the flight id as the key and the flight data as the value.
-
Flush and Completion: The script ends by flushing the producer, which ensures that all messages are sent to Kafka. A message is then printed to indicate that the data has been sent.
import os import requests from dotenv import load_dotenv from confluent_kafka.avro import AvroProducer from confluent_kafka import avro
load_dotenv()
access_key = os.getenv('access_key') if access_key is None: raise ValueError("Missing environment variable: 'access_key'")
url = "http://api.aviationstack.com/v1/flights"
params = { 'access_key': access_key }
response = requests.get(url, params=params) response.raise_for_status()
data = response.json()producer_config = { 'bootstrap.servers': '172.23.0.5:9092', 'schema.registry.url': 'http://localhost:8081' }
value_schema = avro.load('flights-value.avsc')
key_schema = avro.load('key_schema.avsc')producer = AvroProducer(producer_config, default_key_schema=avro.load('key_schema.avsc'), default_value_schema=value_schema)
topic = 'flights'
for flight in data['data']: flight_date = flight.get('flight_date', '') or '' flight_number = (flight.get('flight', {}) or {}).get('number', '') or '' departure_scheduled = (flight.get('departure', {}) or {}).get('scheduled', '') or ''
flight_id = flight_date + '_' + flight_number + '_' + departure_scheduled flight['id'] = flight_id if flight['flight'].get('codeshared') is None: flight['flight']['codeshared'] = {} if 'departure' in flight and 'delay' in flight['departure']: flight['departure']['delay'] = str(flight['departure']['delay']) if flight['departure']['delay'] is not None else None producer.produce(topic=topic, key=flight_id, value=flight)producer.flush() print('Data sent to Kafka')
In this Avro schema, the top-level record is called “Flight” which has the following fields:
-
flight_date: A nullable string that defaults to null.
-
flight_status: A nullable string that defaults to null.
-
departure: A record with multiple fields related to the departure of the flight. All fields in the record are nullable strings that default to null.
-
arrival: Similar to the departure field, this is a record with multiple fields related to the arrival of the flight. Again, all fields are nullable strings that default to null.
-
airline: A record containing details about the airline. It includes name, iata, and icao, all of which are nullable strings that default to null.
-
flight: This is a record containing details about the flight itself. It includes number, iata, icao, and a nested record codeshared. The codeshared record contains details about the airline and flight in case the flight is codeshared. All fields are nullable strings that default to null.
{ "type": "record", "name": "Flight", "fields": [ { "name": "flight_date", "type": ["null", "string"], "default": null }, { "name": "flight_status", "type": ["null", "string"], "default": null }, { "name": "departure", "type": { "type": "record", "name": "Departure", "fields": [ {"name": "airport", "type": ["null", "string"], "default": null}, {"name": "timezone", "type": ["null", "string"], "default": null}, {"name": "iata", "type": ["null", "string"], "default": null}, {"name": "icao", "type": ["null", "string"], "default": null}, {"name": "terminal", "type": ["null", "string"], "default": null}, {"name": "gate", "type": ["null", "string"], "default": null}, {"name": "delay", "type": ["null", "string"], "default": null}, {"name": "scheduled", "type": ["null", "string"], "default": null}, {"name": "estimated", "type": ["null", "string"], "default": null}, {"name": "actual", "type": ["null", "string"], "default": null}, {"name": "estimated_runway", "type": ["null", "string"], "default": null}, {"name": "actual_runway", "type": ["null", "string"], "default": null} ] }, "default": { "airport": null, "timezone": null, "iata": null, "icao": null, "terminal": null, "gate": null, "delay": null, "scheduled": null, "estimated": null, "actual": null, "estimated_runway": null, "actual_runway": null } }, { "name": "arrival", "type": { "type": "record", "name": "Arrival", "fields": [ {"name": "airport", "type": ["null", "string"], "default": null}, {"name": "timezone", "type": ["null", "string"], "default": null}, {"name": "iata", "type": ["null", "string"], "default": null}, {"name": "icao", "type": ["null", "string"], "default": null}, {"name": "terminal", "type": ["null", "string"], "default": null}, {"name": "gate", "type": ["null", "string"], "default": null}, {"name": "baggage", "type": ["null", "string"], "default": null}, {"name": "delay", "type": ["null", "string"], "default": null}, {"name": "scheduled", "type": ["null", "string"], "default": null}, {"name": "estimated", "type": ["null", "string"], "default": null}, {"name": "actual", "type": ["null", "string"], "default": null}, {"name": "estimated_runway", "type": ["null", "string"], "default": null}, {"name": "actual_runway", "type": ["null", "string"], "default": null} ] }, "default": { "airport": null, "timezone": null, "iata": null, "icao": null, "terminal": null, "gate": null, "baggage": null, "delay": null, "scheduled": null, "estimated": null, "actual": null, "estimated_runway": null, "actual_runway": null } }, { "name": "airline", "type": { "type": "record", "name": "Airline", "fields": [ {"name": "name", "type": ["null", "string"], "default": null}, {"name": "iata", "type": ["null", "string"], "default": null}, {"name": "icao", "type": ["null", "string"], "default": null} ] }, "default": { "name": null, "iata": null, "icao": null } }, { "name": "flight", "type": { "type": "record", "name": "FlightInfo", "fields": [ {"name": "number", "type": ["null", "string"], "default": null}, {"name": "iata", "type": ["null", "string"], "default": null}, {"name": "icao", "type": ["null", "string"], "default": null}, { "name": "codeshared", "type": { "type": "record", "name": "Codeshared", "fields": [ {"name": "airline_name", "type": ["null", "string"], "default": null}, {"name": "airline_iata", "type": ["null", "string"], "default": null}, {"name": "airline_icao", "type": ["null", "string"], "default": null}, {"name": "flight_number", "type": ["null", "string"], "default": null}, {"name": "flight_iata", "type": ["null", "string"], "default": null}, {"name": "flight_icao", "type": ["null", "string"], "default": null} ] }, "default": { "airline_name": null, "airline_iata": null, "airline_icao": null, "flight_number": null, "flight_iata": null, "flight_icao": null } } ] }, "default": { "number": null, "iata": null, "icao": null, "codeshared": { "airline_name": null, "airline_iata": null, "airline_icao": null, "flight_number": null, "flight_iata": null, "flight_icao": null } } } ] }
-
Configuration: The script starts by defining the configuration for the AvroConsumer, including the bootstrap servers, group id, auto offset reset, and the URL of the schema registry.
-
Consumer Initialization: An AvroConsumer is created using the configuration, and it subscribes to the ‘flights’ topic.
-
Database Connection: The script then establishes a connection to the PostgreSQL database and creates a cursor object for executing SQL queries.
-
Message Processing: The script enters a loop where it continually polls for messages from the ‘flights’ topic. For each message, it extracts the key and value (the flight data), and processes the data.
-
Data Insertion: The processed flight data is then inserted into various tables in the PostgreSQL database. This includes the ‘airlines’ table, the ‘flights_codeshared’ table (if the flight is codeshared), and the ‘flights’ table. Each INSERT query is followed by a commit operation to ensure the data is saved to the database.
-
Error Handling: The script handles potential errors including message deserialization errors and interrupts from the keyboard (like Ctrl+C).
-
Cleanup: The script ends by closing the AvroConsumer and the PostgreSQL connection.
import psycopg2 import psycopg2.extras import json from confluent_kafka import KafkaError from confluent_kafka.avro import AvroConsumer from confluent_kafka.avro.serializer import SerializerError
consumer_config = { 'bootstrap.servers': '172.23.0.5:9092', 'group.id': 'flights-group', 'auto.offset.reset': 'earliest', 'schema.registry.url': 'http://localhost:8081' }
consumer = AvroConsumer(consumer_config)
consumer.subscribe(['flights'])
conn = psycopg2.connect("dbname=postgres user=postgres password=mysecretpassword host=localhost port=5433")
cur = conn.cursor()
try: while True: # Poll for messages msg = consumer.poll(1.0)
if msg is None: continue if msg.error(): if msg.error().code() == KafkaError._PARTITION_EOF: continue else: print(msg.error()) break # Extract the key and value key = msg.key() value = msg.value() # Insert the airline into the airlines table airline_id = value['airline']['iata'] cur.execute( "INSERT INTO airlines (id, name, iata, icao) VALUES (%s, %s, %s, %s) ON CONFLICT (id) DO NOTHING", (airline_id, value['airline']['name'], value['airline']['iata'], value['airline']['icao']) ) # Insert the codeshared flight into the flights_codeshared table if it exists codeshared_flight_id = None if value['flight']['codeshared'] is not None and 'flight_iata' in value['flight']['codeshared'] and value['flight']['codeshared']['flight_iata'] is not None: codeshared_flight_id = value['flight']['codeshared']['flight_iata'] data = (codeshared_flight_id, value['flight']['codeshared']['airline_iata'], value['flight']['codeshared']['flight_number'], value['flight']['codeshared']['flight_iata'], value['flight']['codeshared']['flight_icao']) print(f"Inserting into flights_codeshared: {data}") cur.execute( "INSERT INTO flights_codeshared (id, airline_id, flight_number, flight_iata, flight_icao) VALUES (%s, %s, %s, %s, %s) ON CONFLICT (id) DO NOTHING", data ) # Insert the flight into the flights table data = (key, value['flight_date'], value['flight_status'], value['departure']['airport'], value['departure']['timezone'], value['departure']['iata'], value['departure']['icao'], value['departure']['terminal'], value['departure']['gate'], value['departure']['delay'], value['departure']['scheduled'], value['departure']['estimated'], value['departure']['actual'], value['departure']['estimated_runway'], value['departure']['actual_runway'], value['arrival']['airport'], value['arrival']['timezone'], value['arrival']['iata'], value['arrival']['icao'], value['arrival']['terminal'], value['arrival']['gate'], value['arrival']['baggage'], value['arrival']['delay'], value['arrival']['scheduled'], value['arrival']['estimated'], value['arrival']['actual'], value['arrival']['estimated_runway'], value['arrival']['actual_runway'], airline_id, value['flight']['number'], codeshared_flight_id) print(f"Inserting into flights: {data}, length: {len(data)}") cur.execute( "INSERT INTO flights (id, flight_date, flight_status, departure_airport, departure_timezone, departure_iata, departure_icao, departure_terminal, departure_gate, departure_delay, departure_scheduled, departure_estimated, departure_actual, departure_estimated_runway, departure_actual_runway, arrival_airport, arrival_timezone, arrival_iata, arrival_icao, arrival_terminal, arrival_gate, arrival_baggage, arrival_delay, arrival_scheduled, arrival_estimated, arrival_actual, arrival_estimated_runway, arrival_actual_runway, airline_id, flight_number, codeshared_flight_id) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON CONFLICT (id) DO UPDATE SET flight_status = excluded.flight_status, departure_delay = excluded.departure_delay, departure_estimated = excluded.departure_estimated, departure_actual = excluded.departure_actual, departure_estimated_runway = excluded.departure_estimated_runway, departure_actual_runway = excluded.departure_actual_runway, arrival_delay = excluded.arrival_delay, arrival_estimated = excluded.arrival_estimated, arrival_actual = excluded.arrival_actual, arrival_estimated_runway = excluded.arrival_estimated_runway, arrival_actual_runway = excluded.arrival_actual_runway", data ) conn.commit()except SerializerError as e: print(f"Message deserialization failed: {e}") exit(1)
except KeyboardInterrupt: pass
finally: # Close down consumer to commit final offsets. consumer.close() # Close the PostgreSQL connection cur.close() conn.close()
In Avro, and by extension in Kafka, each message has a key and a value. The key is often used for things like partitioning, and the value is where the main message data is stored. This schema is specifying the structure of the key for each message. Given that it’s just a single string, the key for these messages could be something like a unique identifier for each flight.
{
"type": "string",
"name": "FlightKey"
}
CREATE TABLE flights (
id VARCHAR(255) PRIMARY KEY,
flight_date DATE,
flight_status VARCHAR(255),
departure_airport VARCHAR(255),
departure_timezone VARCHAR(255),
departure_iata VARCHAR(255),
departure_icao VARCHAR(255),
departure_terminal VARCHAR(255),
departure_gate VARCHAR(255),
departure_delay INTEGER,
departure_scheduled TIMESTAMP,
departure_estimated TIMESTAMP,
departure_actual TIMESTAMP,
departure_estimated_runway TIMESTAMP,
departure_actual_runway TIMESTAMP,
arrival_airport VARCHAR(255),
arrival_timezone VARCHAR(255),
arrival_iata VARCHAR(255),
arrival_icao VARCHAR(255),
arrival_terminal VARCHAR(255),
arrival_gate VARCHAR(255),
arrival_baggage VARCHAR(255),
arrival_delay INTEGER,
arrival_scheduled TIMESTAMP,
arrival_estimated TIMESTAMP,
arrival_actual TIMESTAMP,
arrival_estimated_runway TIMESTAMP,
arrival_actual_runway TIMESTAMP,
airline_id VARCHAR(255),
flight_number VARCHAR(255),
codeshared_flight_id VARCHAR(255)
);
CREATE TABLE airlines (
id VARCHAR(255) PRIMARY KEY,
name VARCHAR(255),
iata VARCHAR(255),
icao VARCHAR(255)
);
CREATE TABLE flights_codeshared (
id VARCHAR(255) PRIMARY KEY,
airline_id VARCHAR(255),
flight_number VARCHAR(255),
flight_iata VARCHAR(255),
flight_icao VARCHAR(255)
);
-
Airline, Airport, and Flight are defined as GraphQL ObjectTypes, each with various fields of different types. These classes define the structure of the data that can be queried from the API.
-
Query is also a GraphQL ObjectType, but it is special because it defines the entry points for the API. It has two fields, flight and flights, each with a corresponding resolver function.
The resolve_flight function queries the database for a specific flight based on the airline name and flight number. The resolve_flights function queries the database for all flights. The query results are then mapped to the Flight GraphQL ObjectType and returned.
A GraphQLView is then created with the Query class as the root schema. This view is added to the Flask app as the '/graphql' route.
In the context of a real-time flight status pipeline, using GraphQL instead of a REST API has several advantages:
-
Efficiency: Clients can specify exactly what data they need, which can reduce the amount of data that needs to be sent over the network. In contrast, REST APIs typically send fixed data structures.
-
Strong Typing: The schema defines what data is available and in what format, which can help prevent errors and misunderstandings.
-
Introspection: Clients can query the schema to discover what data is available.
-
Single Request: In GraphQL, you can get all the data you need in a single request by creating complex queries, whereas in REST, you may need to make multiple requests to different endpoints.
In the case of this pipeline, where we have flight data with multiple related entities (like airline, departure airport, and arrival airport), a GraphQL API can provide a more efficient and flexible way to query the data.
Example:
query {
flight(airlineName: "Spring Airlines", flightNumber: "6133") {
id
flightDate
flightStatus
departure {
airport
timezone
iata
icao
terminal
gate
}
arrival {
airport
timezone
iata
icao
terminal
gate
}
airline {
id
name
iata
icao
}
flightNumber
}
}
query {
flights {
id
flightDate
flightStatus
departure {
airport
timezone
iata
icao
terminal
gate
}
arrival {
airport
timezone
iata
icao
terminal
gate
}
airline {
id
name
iata
icao
}
flightNumber
}
}
-
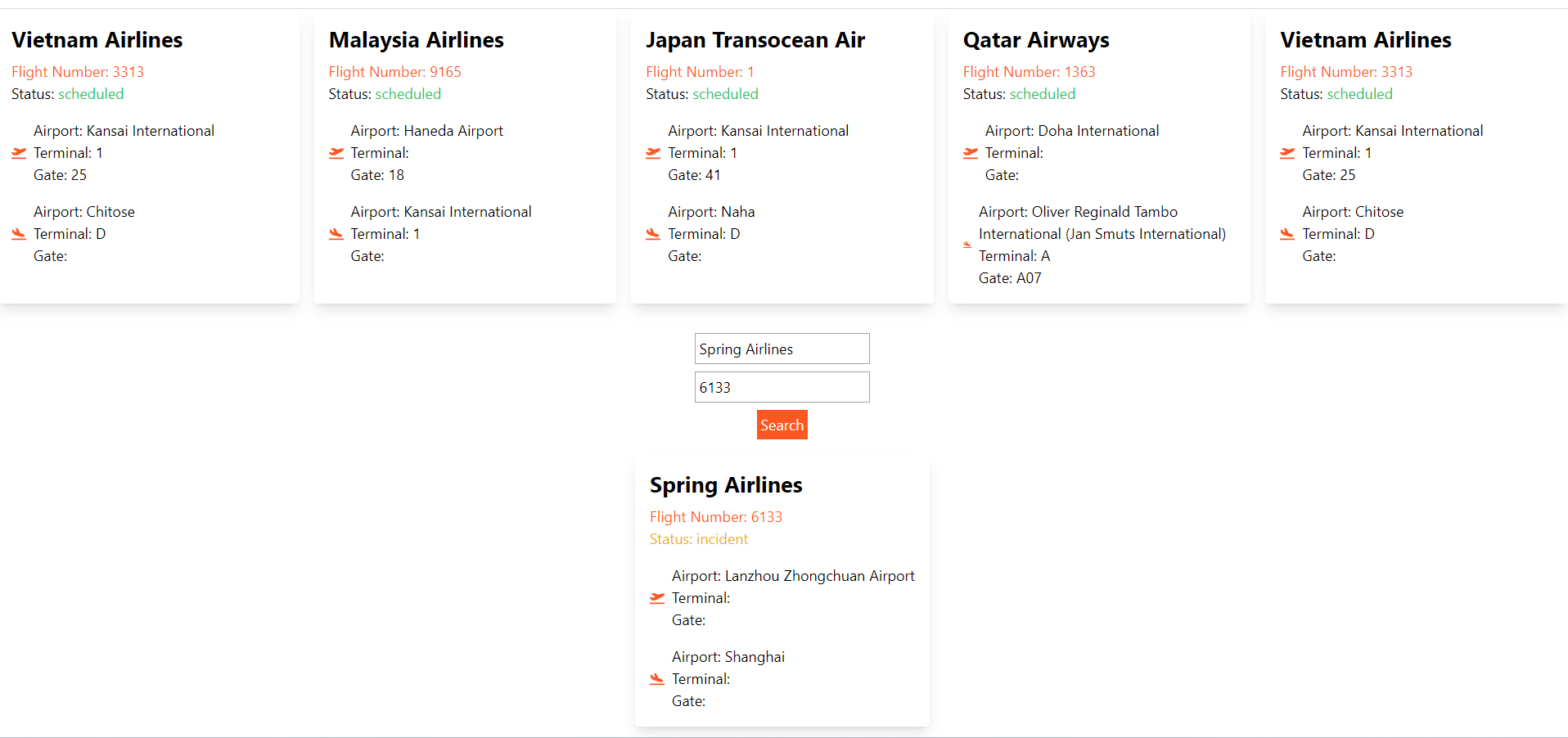
The first query is requesting information about a specific flight from Spring Airlines with flight number 6133. The client is specifying that they want the id, flightDate, flightStatus, departure, arrival, airline, and flightNumber fields for this flight. For the departure, arrival, and airline fields, which are objects, the client specifies the subfields they want (airport, timezone, iata, icao, terminal, gate for departure and arrival, and id, name, iata, icao for airline).
-
The second query is requesting information about all flights. The client is specifying that they want the same set of fields (id, flightDate, flightStatus, departure, arrival, airline, flightNumber) for each flight.
These queries demonstrate the flexibility and efficiency of GraphQL. The client can specify exactly what data they need, down to individual fields on nested objects. This can reduce the amount of data that needs to be sent over the network, especially in cases where the client only needs a subset of the available data.
Moreover, these queries will return all the requested data in a single request. This is in contrast to REST APIs, where you might need to make multiple requests to different endpoints to gather all the necessary data.
{
"data": {
"flight": {
"id": "2023-07-18_6133_2023-07-18T07:40:00+00:00",
"flightDate": "2023-07-18",
"flightStatus": "incident",
"departure": {
"airport": "Lanzhou Zhongchuan Airport",
"timezone": null,
"iata": "LHW",
"icao": "ZLLL",
"terminal": null,
"gate": null
},
"arrival": {
"airport": "Shanghai",
"timezone": "Asia/Shanghai",
"iata": "HFE",
"icao": "ZSOF",
"terminal": null,
"gate": null
},
"airline": {
"id": "9C",
"name": "Spring Airlines",
"iata": "9C",
"icao": "CQH"
},
"flightNumber": "6133"
}
}
}
{
"data": {
"flights": [
{
"id": "2023-07-18_2447_2023-07-18T07:30:00+00:00",
"flightDate": "2023-07-18",
"flightStatus": "scheduled",
"departure": {
"airport": "Lanzhou Zhongchuan Airport",
"timezone": null,
"iata": "LHW",
"icao": "ZLLL",
"terminal": "T2",
"gate": null
},
"arrival": {
"airport": "Nanjing Lukou International Airport",
"timezone": "Asia/Shanghai",
"iata": "NKG",
"icao": "ZSNJ",
"terminal": "2",
"gate": null
},
"airline": {
"id": "MU",
"name": "China Eastern Airlines",
"iata": "MU",
"icao": "CES"
},
"flightNumber": "2447"
},
{
"id": "2023-07-18_6305_2023-07-18T07:25:00+00:00",
"flightDate": "2023-07-18",
"flightStatus": "scheduled",
"departure": {
"airport": "Lanzhou Zhongchuan Airport",
"timezone": null,
"iata": "LHW",
"icao": "ZLLL",
"terminal": null,
"gate": null
},
"arrival": {
"airport": "Tianjin Binhai International",
"timezone": "Asia/Shanghai",
"iata": "TSN",
"icao": "ZBTJ",
"terminal": "T2",
"gate": null
},
"airline": {
"id": "9C",
"name": "Spring Airlines",
"iata": "9C",
"icao": "CQH"
},
"flightNumber": "6305"
},
{
"id": "2023-07-18_6187_2023-07-18T07:20:00+00:00",
"flightDate": "2023-07-18",
"flightStatus": "scheduled",
"departure": {
"airport": "Lanzhou Zhongchuan Airport",
"timezone": null,
"iata": "LHW",
"icao": "ZLLL",
"terminal": null,
"gate": null
},
"arrival": {
"airport": "Nanjing Lukou International Airport",
"timezone": "Asia/Shanghai",
"iata": "NKG",
"icao": "ZSNJ",
"terminal": "1",
"gate": null
},
"airline": {
"id": "9C",
"name": "Spring Airlines",
"iata": "9C",
"icao": "CQH"
},
"flightNumber": "6187"
},
{
"id": "2023-07-18_6488_2023-07-18T07:15:00+00:00",
"flightDate": "2023-07-18",
"flightStatus": "scheduled",
"departure": {
"airport": "Lanzhou Zhongchuan Airport",
"timezone": null,
"iata": "LHW",
"icao": "ZLLL",
"terminal": null,
"gate": null
},
"arrival": {
"airport": "Shanghai Pudong International",
"timezone": "Asia/Shanghai",
"iata": "PVG",
"icao": "ZSPD",
"terminal": "2",
"gate": null
},
"airline": {
"id": "9C",
"name": "Spring Airlines",
"iata": "9C",
"icao": "CQH"
},
"flightNumber": "6488"
} ...
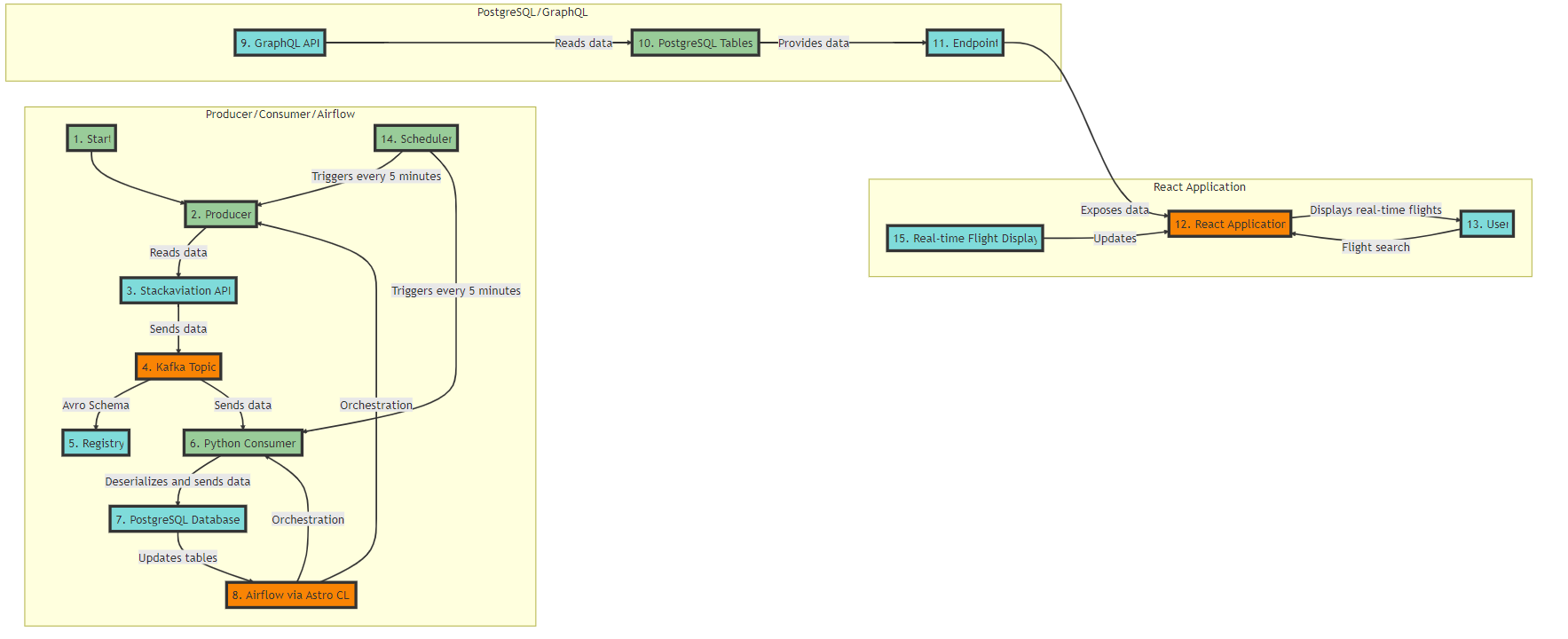
In conclusion, this article has covered the construction of a real-time flight status data pipeline using a myriad of technologies such as Kafka, Schema Registry, Avro, GraphQL, Postgres, and React. The pipeline fetches real-time data from an aviation API, processes it using a Kafka producer, stores it in a PostgreSQL database, and exposes it to clients through a GraphQL API. This pipeline provides an efficient and effective solution for tracking real-time flight data and offering clients the ability to access this information flexibly and efficiently.
Looking ahead, the second part of this series will delve into the orchestration of this pipeline using Astro — the CLI for data orchestration. Astro is a tool that makes working with Apache Airflow much more straightforward and is compatible with all Astronomer products. With the Astro CLI, we can automate and manage complex workflows more efficiently.
We’ll explore how to set up Directed Acyclic Graphs (DAGs) to automate our pipeline. Specifically, we’ll have a DAG that triggers every 5 seconds to fetch new data from the API and send it to a Kafka topic. Another DAG will be set up for the consumer, which will read the latest data from the Kafka topic and update the PostgreSQL database accordingly.
By introducing Astro into our pipeline, we’ll further increase its efficiency, maintainability, and reliability, making our real-time flight status pipeline even more robust. Stay tuned for this exciting next step in our data pipeline journey.