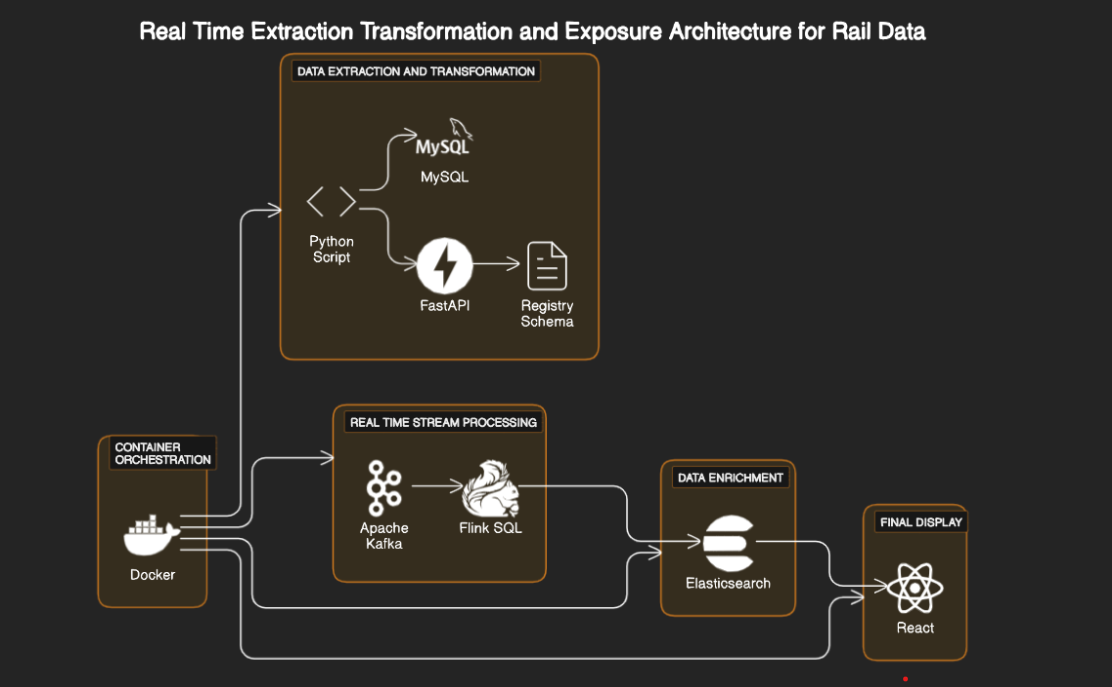
- Open a terminal.
- Run the following command to clone the repository:
git clone https://github.com/Stefen-Taime/Real-Time-Extraction-Transformation-and-Exposure-Architecture-for-Rail-Data.git - Navigate to the cloned project:
cd Real-Time-Extraction-Transformation-and-Exposure-Architecture-for-Rail-Data
In the project's root directory, launch the services using Docker Compose:
docker-compose up --build -d
After starting the services, configure and start the different project components in four separate terminals.
- Obtain the Docker container ID running Apache Flink with
docker ps. - Execute the Flink SQL client:
docker exec -it <container_id> /opt/flink/bin/sql-client.sh - Execute the SQL queries located in
jobs/job.sql.
- Navigate to the first API microservice:
cd apiMicroservice1 - Launch the microservice:
python main.py
- Navigate to the second API microservice:
cd apiMicroservice2 - Launch the microservice:
python app.py
- Navigate to the metro-status service:
cd metro-status - Clean the project and launch the application in development mode:
npm run clean npm run dev
- Flink Dashboard: Typically at
http://localhost:8085. - API Microservices:
http://localhost:<port>. - Next.js Application: Typically at
http://localhost:3000.