Building a Modern Data Pipeline: A Deep Dive into Terraform, AWS Lambda and S3, Snowflake, DBT, Mage AI, and Dash
This blog post will provide a detailed walkthrough of creating a modern data pipeline using a combination of Terraform, AWS Lambda and S3, Snowflake, DBT, Mage AI, and Dash.
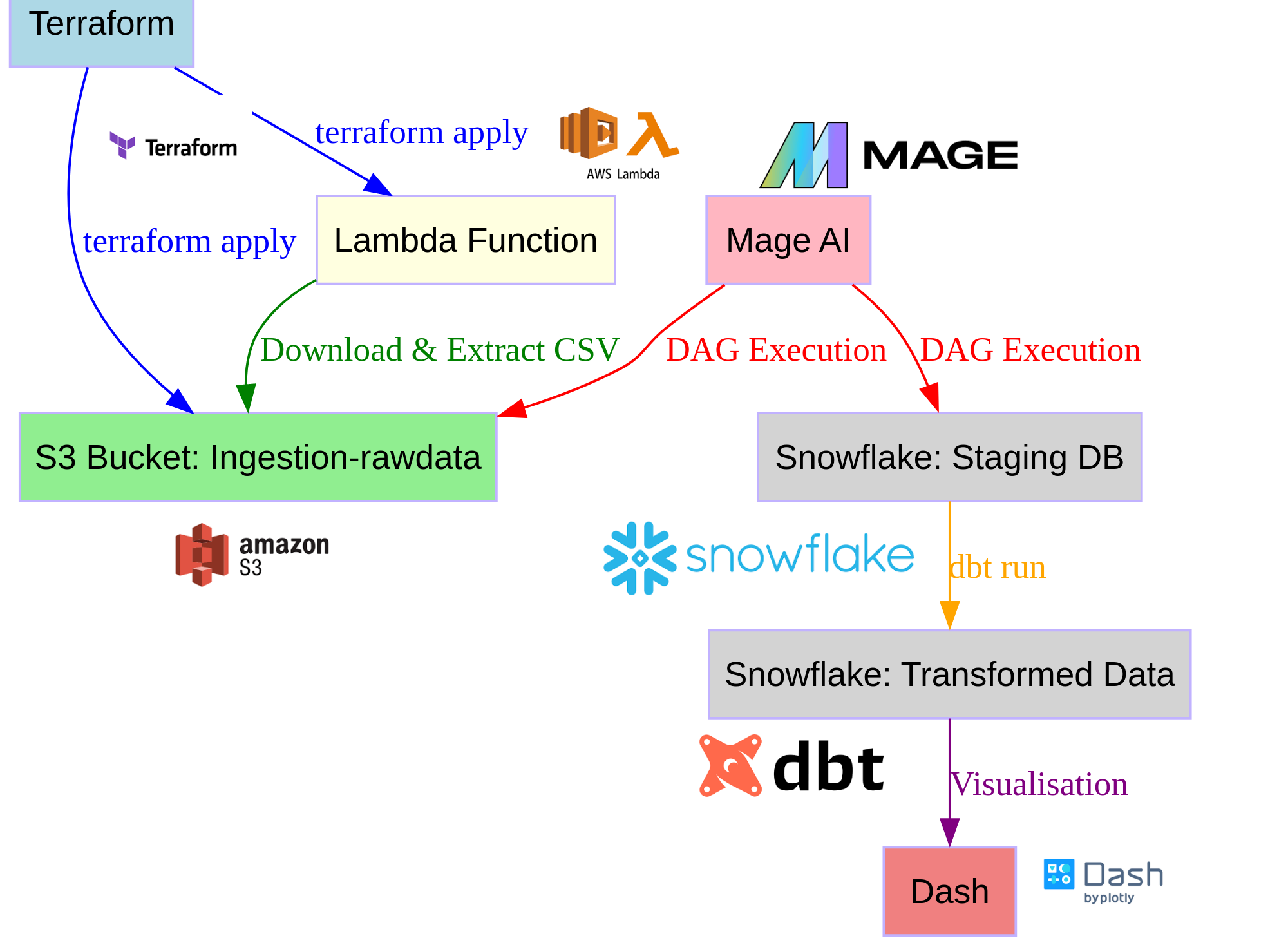
Our journey begins with the deployment of an Ingestion-rawdata S3 bucket and a Lambda function. This is achieved via a Terraform script. Terraform is an open-source infrastructure as code software tool that allows users to define and provide data center infrastructure using a declarative configuration language.
The AWS Lambda function is designed to download a zip file via HTTPS, decompress it, and load the CSV files into the Ingestion-rawdata S3 bucket. AWS Lambda is a serverless computing service that runs your code in response to events and automatically manages the underlying compute resources for you.
The S3 bucket serves as our initial data storage. Amazon S3 (Simple Storage Service) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
Once our data is securely stored in the S3 bucket, we turn to Mage AI for ingestion and orchestration. Mage AI is a robust alternative to Airflow, offering a streamlined and efficient approach to data management. It’s a modern data orchestration tool that allows you to schedule and monitor workflows and ensure data reliability.
In Mage AI, a Python script, annotated with @data_loader, reads the CSV data in the Ingestion-rawdata S3 bucket. It then creates the staging database and a stage in Snowflake to copy the CSV data. The script also creates tables and loads them into Snowflake. To simplify the process, each table is named after the original CSV file.
With our data now in Snowflake, we run our DBT models, which are connected to Snowflake. DBT (Data Build Tool) is a command-line tool that enables data analysts and engineers to transform data in their warehouses more effectively.

These models include DBT staging, which retrieves the raw data from the Snowflake staging database tables. The intermediate model applies a few transformations and joins. This step is crucial as it helps to refine and structure our data, making it more suitable for analysis.
Finally, we have the marts model, which creates the final views representing the metrics by linking the intermediate and staging models. Snowflake, a cloud-based data warehousing platform, provides the computational power and storage to execute these transformations and store the resulting data.

The final step in our pipeline is data visualization. For this, we use Dash, a Python framework for building analytical web applications. Dash connects to Snowflake using the views provided in the marts. This allows us to create interactive dashboards that can, for example, show which product categories sell the most or which cities have the most buyers.



In conclusion, creating a modern data pipeline might seem like a daunting task, but with the right tools and a clear roadmap, it becomes a manageable and even enjoyable process. The combination of Terraform, AWS Lambda and S3, Snowflake, DBT, Mage AI, and Dash provides a robust and flexible pipeline that can handle large volumes of data and deliver valuable insights.
Before you begin, ensure you have met the following requirements:
-
You have installed and configured the AWS CLI. If not, you can follow the instructions here.
-
You have installed Terraform. If not, you can follow the instructions here.
-
You have created a free account on Snowflake. You can sign up here.
-
You have installed Mage AI. Installation instructions can be found here.
Follow these steps to get your pipeline up and running:
git clone https://github.com/Stefen-Taime/modern-data-pipeline.git
-
. /build.sh -
terraform init terraform plan terraform apply
mage start demo_project
Important Note
Please remember to destroy your Terraform environment when you're done to avoid unnecessary AWS charges
terraform destroy
Contact
If you have any questions or issues, feel free to open an issue in this repository.