CPU optimizations build options
There are many processors architectures: x86 / x86-64 family, ARMv7, aarch64, etc. Each architecture may support different additional instruction sets (SSE/AVX for x86, NEON for ARMv7).
OpenCV goal is to provide effective processors support, including separate optimized code paths for newest instruction sets.
Some OpenCV functions contains multiple code paths specialized for different processors features / instruction sets. Selection of executed code path is based on auto-detection of available processor features.
These options are available since OpenCV <next release>.
Build options allow to specify minimal and dispatched optimization features sets:
-
Minimal is required set of processor features. Executable will not run if some of these options are not available on target processor.
-
Dispatched optimizations are additional code paths compiled into executable. They will be executed on supported processors only.
OpenCV uses these CMake variables to control supported optimization features:
-
CPU_BASELINE- minimal set of required optimizations (if they are supported by C++ compiler)CPU_BASELINE=SSE2 CPU_BASELINE=AVX -
CPU_DISPATCH- dispatched set of additional optimizations (if they are supported by C++ compiler)CPU_DISPATCH=SSE4_2,AVX CPU_DISPATCH=AVX CPU_DISPATCH=AVX,AVX2
Note: Flags ENABLE_AVX/ENABLE_AVX2/ENABLE_POPCNT/etc should not be used anymore. Use options above instead.
-
CPU_BASELINE_REQUIRE- list of required baseline (minimal set) optimizations. Build fails if compiler doesn't support some of these optimizations. -
CPU_DISPATCH_REQUIRE- list of additional (dispatched set) optimizations. Build fails if compiler doesn't support some of these optimizations. -
CPU_BASELINE_DISABLE- list of completely disabled optimizations -
CV_DISABLE_OPTIMIZATION- disable all explicit optimized code (useful for debugging purposes)
OpenCV configuration status contains lines like these:
-- CPU/HW features:
-- Baseline: SSE SSE2 SSE3 SSSE3
-- requested: SSSE3
-- Dispatched code generation: SSE4_1 AVX AVX2
-- requested: SSE4_1 AVX AVX2
In general, C++ compilers don't support code generation of multiple enabled instruction sets for single source file.
Current layout of source files is:
- main source file: "cvfunction.cpp" - contains code dispatcher (see below) and general implementation
- shared header file: "cvfunction.hpp" - contains shared declarations used by generic and optimized code
- several files with optimized code (suffix
.<lowercase optimization name>.cpp): "cvfunction.avx.cpp".
There is no requirement to implement all possible optimizations. Add function optimizations with better effort only.
Unwrapped version:
CV_CPU_CALL_AVX2(my_cv_function_avx2(...args...));
CV_CPU_CALL_FP16(my_cv_function_fp16(...args...));
CV_CPU_CALL_AVX(my_cv_function_avx(...args...));
CV_CPU_CALL_SSE4_2(my_cv_function_sse4_2(...args...));
CV_CPU_CALL_POPCNT(my_cv_function_popcnt(...args...));
CV_CPU_CALL_NEON(my_cv_function_neon(...args...));
... regular C++ implementation ...
These macro declarations are depend on CMake options:
- empty statement (in case of non-used or disabled optimization)
- conditional code execution:
if(checkHardwareSupport(CV_AVX)) ... - unconditional code execution in case of baseline optimization
Mixing of AVX and SSE code may provide significant performance reduction due registers sharing. Work around for this is to use _mm256_zeroupper() intrinsic:
#if CV_AVX && !defined CV_CPU_BASELINE_COMPILE_AVX
_mm256_zeroupper();
#endif
All non-inline templates used in optimized code must be wrapped into separate (or anonymous) namespaces to prevent conflicts (linker will use one template's implementation only).
Unfortunately, there is no any warning from linker about this.
-
OPENCV_CPU_DISABLE- allows to mask some processor features, so dispatched code doesn't runOPENCV_CPU_DISABLE=AVX2,AVX,FP16
This "How to" example is based on optimization of Hamming norm algorithm (core module, file stat.cpp).
-
Ensure that you have performance tests for selected functionality. Please don't waste your time and time of reviewer doing this without good performance tests.
-
Compile OpenCV performance test with different CPU baseline features with disabled dispatching (depends on your platform). I select on
x86-64platform:SSE3(minimal),SSE4.1,SSE4.2,AVX,AVX2(max level on my platform),DETECT(with-march=nativecompiler option). It is better to build these versions of OpenCV configuration in different folders. When run performance tests and build report like this:
-
On this report we can see on the second part (with
--progressoption):- We would gain performance improvement on dispatched
- SSE4.2 (
popcountinstruction,1.7-1.9speedup) - AVX for
normfunction only (1.3speedup over SSE4.2) - AVX2 (
~3total speedup,~1.5speedup after SSE4.2/AVX)
- SSE4.2 (
- Dispatching for SSE4.1 mode is useless.
- Dispatching for
NORM_HAMMING2will not increase speed, so we avoid it.
- We would gain performance improvement on dispatched
-
Let's extract implementations of interested functions into separate
.simd.hppfile "as is". This header file will be processed multiple times - so we will generate binary code with different optimization options using single source file. Refer to PR commit "move implementations into .hpp file w/o changes". -
After that we should "create dispatch.cpp file". It is simple helper file without algorithm logic, but it contains entry-points for optimized functions and dispatch rules.
-
We need to "remove useless checks" from
.hppfile, because these platform dependent checks is done in compile-time (controlled via defines). -
On the next step we should "register dispatched code, fix build".
- We should register our dispatched code from
.hppfile via CMake handler. Also we pass list of enabled optimizations:SSE4_2 AVX AVX2. - We reusing
popCountTablemultiple times from different compilations units, so we need to make it "external".
- We should register our dispatched code from
-
Mixing of SSE/AVX code during runtime usually provides significant performance impact. To workaround this problem we should use
vzeroupperinstruction. See commit: "add required CV_AVX_GUARD" -
Build performance tests:
- separate build directory
- check for enabled dispatching levels: "-DCPU_DISPATCH=SSE4_2;AVX;AVX2"
-
Run performance tests:
- without restrictions and save results to "avx2.xml"
- "avx.xml": mask AVX2 optimizations via environment variable:
OPENCV_CPU_DISABLE=AVX2 - "sse42.xml": mask optimizations via environment variable:
OPENCV_CPU_DISABLE=AVX2,AVX - "sse3.xml": mask optimizations via environment variable:
OPENCV_CPU_DISABLE=AVX,AVX2,SSE4.2
-
Result is here:

-
We can see that there is no improvements from dispatched AVX optimization, so we can remove it from CMake file: "optimize size of binaries, drop AVX dispatching"
- AVX-related issue is a compiler problem with processing of unrolled loops. Removal of these loops before generation of the first report resolves this strange behavior (slowdown of SSE4.2 code).
-
Final result is here:

{kind=link}
{kind=link}
{kind=link}
For reference, similar report for code without patch:
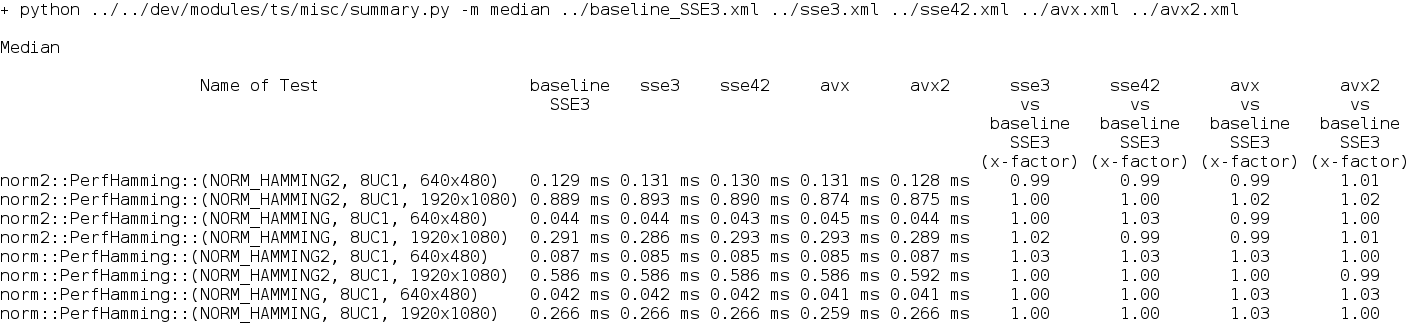
{kind=link}
Additional possible changes:
- support
NORM_HAMMING2too, but this will require additional optimizations (probably for AVX2 code only). - we can replace SSE4_2 to POPCNT dispatch level in CMake file.