This repository is based on the AWS Bedrock Agents Web Scraper example. I've modified it to use TypeScript and use more robust tooling for search and scraping.
Original Dev article here.
After all of the AWS product announcements at the NYC Summit last week, I wanted to start testing out AWS Bedrock Agents more thoroughly for myself. Something clients often ask for is the ability for their LLM workflows to have access to the web.
There is a web scraper example from AWS that covers this, but I wanted to make a version for NodeJS in TypeScript. I also wasn't happy with the Google search capability relying on web scraping, so I swapped it out for the Google custom search API. My solution will also be making use of the AWS CLI and Docker images to make things more consistent.
(GitHub project available at end of article)
Prerequisites:
- AWS CLI (v2)
- Docker
- NodeJS 20.x
- AWS Account
- Google Custom Search API Key
What we want to do is create a Bedrock agent and attach an action group with a Lambda function that can be called by the agent to perform google searches and scrape web content. We'll accomplish this by defining a Lambda function using Docker and then attaching that function to the agent.
Tasks:
- Write function(s) to perform web scraping and Google search
- Build Docker image to test functions locally
- Deploy Docker image to AWS ECR
- Creating Lambda function using ECR image as source
- Set up IAM roles/permissions
- Create Bedrock agent to use new Lambda function
Let's start by defining a Lambda function using Docker.
Why use Docker? Usually, I deploy Lambda-based apps using AWS SAM but I wanted to try something different this time. Plus docker images are easier to test with locally (in my experience).
We'll start by following the AWS documentation for deploying a Typescript on NodeJS container image.
I encourage you to read the AWS docs, but this is what we're going to do to get started (I'm using Node 20.x):
npm init
npm install @types/aws-lambda esbuild --save-dev
npm install @types/node --save-dev
npm install typescript --save-dev Let's also install cheerio since we'll need it for web scraping later:
npm install cheerioThen add a build script to the package.json file:
...
"scripts": {
"build": "esbuild index.ts --bundle --minify --sourcemap --platform=node --target=es2020 --outfile=dist/index.js"
}
...Create a Dockerfile. I modified the example Dockerfile from AWS to use the nodejs20 as base:
FROM public.ecr.aws/lambda/nodejs:20 as builder
WORKDIR /usr/app
COPY package.json ./
RUN npm install
COPY index.ts ./
RUN npm run build
FROM public.ecr.aws/lambda/nodejs:20
WORKDIR ${LAMBDA_TASK_ROOT}
COPY --from=builder /usr/app/dist/* ./
CMD ["index.handler"]Great, now create an index.ts. Here's the placeholder index.ts provided by AWS and is good for testing our setup:
import { Context, APIGatewayProxyResult, APIGatewayEvent } from 'aws-lambda';
export const handler = async (event: APIGatewayEvent, context: Context): Promise<APIGatewayProxyResult> => {
console.log(`Event: ${JSON.stringify(event, null, 2)}`);
console.log(`Context: ${JSON.stringify(context, null, 2)}`);
return {
statusCode: 200,
body: JSON.stringify({
message: 'hello world',
}),
};
};Build and run the container (name it whatever you like, I used bedrock-scraper:latest):
docker build --platform linux/amd64 -t bedrock-scraper:latest .
docker run --platform linux/amd64 -p 9000:8080 bedrock-scraper:latestIf we did everything properly we should be able to invoke the function and get our test result:
curl "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{}'And we should see:
{"statusCode":200,"body":"{\"message\":\"hello world\"}"}% Everything's working well! Now we can start writing the "functions" that our agent will eventually use.
We're going to use cheerio to parse the content from websites ("web scraping").
First, we'll add import and typing at the top so we don't forget to return all properties required by the Bedrock Agent.
import { Context, APIGatewayEvent } from 'aws-lambda';
import * as cheerio from 'cheerio';
interface BedrockAgentLambdaEvent extends APIGatewayEvent {
function: string;
parameters: any[];
actionGroup: string;
}
interface BedrockResult {
messageVersion: string;
response: {
actionGroup: string;
function: string;
functionResponse: {
responseState?: string;
responseBody: any;
}
}
}
...Then we can modify the lambda handler() function to accept the new event type and return the new result type:
...
export const handler = async (event: BedrockAgentLambdaEvent, context: Context): Promise<BedrockResult> => {
...How will our Lambda function know what URL to scrape? It will be passed from the Agent via the Event parameters. Inside our handler() we can add the following
let parameters = event['parameters'];Let's assume the to-be-implemented agent is going to pass us a url parameter. Based on the AWS docs, we can access this parameter like so:
let url = parameters.find(param => param.name === 'url')?.value || '';Next, we can get the html content using cheerio:
const response = await fetch(url);
const html = await response.text();
const $ = cheerio.load(html);Now let's parse out all the unnecessary tags and get the website text:
// Remove extraneous elements
$('script, style, iframe, noscript, link, meta, head, comment').remove();
let plainText = $('body').text();Finally we can return the content in the format that Bedrock needs:
let actionResponse = {
'messageVersion': '1.0',
'response': {
'actionGroup': event['actionGroup'] || '',
'function': event['function'] || '',
'functionResponse': {
'responseBody': {
'TEXT': {
'body': '',
}
}
}
}
};
actionResponse['response']['functionResponse']['responseBody']['TEXT']['body'] = JSON.stringify({
'text': plainText,
});
return actionResponse;Rebuild and rerun the container to test our changes:
docker build --platform linux/amd64 -t bedrock-scraper:latest .
docker run --platform linux/amd64 -p 9000:8080 bedrock-scraper:latestInvoke the scrape function, we need to pass the parameters the same way the agent will, in the format we defined above:
curl "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{"parameters":[{"name":"url","value":"https://google.com"}]}'We should get back some text that looks like the google home page.
{"messageVersion":"1.0","response":{"actionGroup":"","function":"","functionResponse":{"responseBody":{"TEXT":{"body":"{\"text\":\"Search Images Maps Play YouTube News Gmail Drive More »Web History | Settings | Sign in Advanced searchAdvertisingBusiness SolutionsAbout Google© 2024 - Privacy - Terms \"}"}}}}} Excellent, our web scraping function is setup! Let's move on to the Google search.
Before setting up search, you should follow Google's documentation on creating a search engine and obtaining an api key.
With our custom search ID and API key in-hand, it's simple to add a condition for it in our handler. I'm going to refactor the handler function a bit and add a new Google search section:
export const handler = async (event: BedrockAgentLambdaEvent, context: Context): Promise<BedrockResult> => {
let agentFunction = event['function'];
let parameters = event['parameters'];
let actionResponse = {
'messageVersion': '1.0',
'response': {
'actionGroup': event['actionGroup'] || '',
'function': event['function'] || '',
'functionResponse': {
'responseBody': {
'TEXT': {
'body': '',
}
}
}
}
};
if (agentFunction === 'scrape') {
// get URL from parameters
let url = parameters.find(param => param.name === 'url')?.value || '';
if (!url) {
actionResponse['response']['functionResponse']['responseState'] = 'FAILURE';
actionResponse['response']['functionResponse']['responseBody']['TEXT']['body'] = JSON.stringify({
'error': 'URL not found in parameters',
});
return actionResponse;
}
const response = await fetch(url);
const html = await response.text();
const $ = cheerio.load(html);
// Remove extraneous elements
$('script, style, iframe, noscript, link, meta, head, comment').remove();
let plainText = $('body').text();
console.log({plainText});
// Limit of Lambda response payload is 25KB
// https://docs.aws.amazon.com/bedrock/latest/userguide/quotas.html
const maxSizeInBytes = 20 * 1024;
if (Buffer.byteLength(plainText, 'utf8') > maxSizeInBytes) {
while (Buffer.byteLength(plainText, 'utf8') > maxSizeInBytes) {
plainText = plainText.slice(0, -1);
}
plainText = plainText.trim() + '...'; // Add an ellipsis to indicate truncation
}
console.log({plainText});
actionResponse['response']['functionResponse']['responseBody']['TEXT']['body'] = JSON.stringify({
'text': plainText,
});
return actionResponse;
} else if (agentFunction === 'google_search') {
let query = parameters.find(param => param.name === 'query')?.value || '';
if (!query) {
actionResponse['response']['functionResponse']['responseState'] = 'FAILURE';
actionResponse['response']['functionResponse']['responseBody']['TEXT']['body'] = JSON.stringify({
'error': 'Query not found in parameters',
});
return actionResponse;
}
const googleParams = {
key: process.env.GOOGLE_SEARCH_KEY,
cx: process.env.GOOGLE_SEARCH_CX,
q: query,
};
const queryString = Object.keys(googleParams)
.map(key => key + '=' + googleParams[key])
.join('&');
const response = await fetch(`https://www.googleapis.com/customsearch/v1?${queryString}`);
const data = await response.json();
if (data.items) {
// only return title and link of first 10 results for smaller response payload
const results = data.items.map((item: any) => {
return {
title: item.title,
link: item.link,
};
}).slice(0, 10);
actionResponse['response']['functionResponse']['responseBody']['TEXT']['body'] = JSON.stringify({
'results': results,
});
return actionResponse;
} else {
actionResponse['response']['functionResponse']['responseState'] = 'FAILURE';
actionResponse['response']['functionResponse']['responseBody']['TEXT']['body'] = JSON.stringify({
'error': 'No results found',
});
return actionResponse;
}
} else {
actionResponse['response']['functionResponse']['responseState'] = 'FAILURE';
actionResponse['response']['functionResponse']['responseBody']['TEXT']['body'] = JSON.stringify({
'error': 'Function not found',
});
return actionResponse;
}
};Interesting changes to point out:
- If condition based on the function name passed to our Lambda from Bedrock
- Use of environment variables instead of hardcoding our Google Search API key and Custom Search Engine ID
- Truncate the response for both
google_searchandscrapefunctions due to Lambda/Bedrock quota limits - Added some edge cases & error handling
Let's test it!
Now that we are dealing with API keys as env variables we should pass them in to docker at run time:
docker build --platform linux/amd64 -t bedrock-scraper:latest .
docker run -e GOOGLE_SEARCH_KEY=YOUR_SEARCH_KEY -e GOOGLE_SEARCH_CX=YOUR_CX_ID --platform linux/amd64 -p 9000:8080 bedrock-scraper:latestExample cURL to test
curl "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{"function":"google_search", "parameters":[{"name":"query","value":"safest cities in USA"}]}'My output
{"messageVersion":"1.0","response":{"actionGroup":"","function":"google_search","functionResponse":{"responseBody":{"TEXT":{"body":"{\"results\":[{\"title\":\"The 10 Safest Cities in America | Best States | U.S. News\",\"link\":\"https://www.usnews.com/news/cities/slideshows/safest-cities-in-america\"}...Perfect! Now let's deploy to Lambda so we can start using these functions.
Before connecting to Bedrock, we'll need to deploy our lambda function. To do this, we can continue with the AWS documentation for "Deploying the Image".
Start by creating an ECR repository and pushing our image to it.
(Be sure to replace 111122223333 and us-east-1 with your account ID and region)
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin 111122223333.dkr.ecr.us-east-1.amazonaws.com
aws ecr create-repository --repository-name bedrock-scraper --region us-east-1 --image-scanning-configuration scanOnPush=true --image-tag-mutability MUTABLE
docker tag bedrock-scraper:latest 111122223333.dkr.ecr.us-east-1.amazonaws.com/bedrock-scraper:latest
docker push 111122223333.dkr.ecr.us-east-1.amazonaws.com/bedrock-scraper:latestNext, create a role for the Lambda function and create the Lambda function itself:
(Remember to replace 111122223333 and us-east-1 with your account ID and region, YOUR_SEARCH_KEY and YOUR_CX_ID with your Google search key and CX ID)
aws iam create-role \
--role-name lambda-ex \
--assume-role-policy-document '{"Version": "2012-10-17","Statement": [{ "Effect": "Allow", "Principal": {"Service": "lambda.amazonaws.com"}, "Action": "sts:AssumeRole"}]}'
aws lambda create-function \
--function-name bedrock-scraper \
--package-type Image \
--code ImageUri=111122223333.dkr.ecr.us-east-1.amazonaws.com/bedrock-scraper:latest \
--role arn:aws:iam::111122223333:role/lambda-ex \
--timeout 30 \
--environment "Variables={GOOGLE_SEARCH_KEY=YOUR_SEARCH_KEY,GOOGLE_SEARCH_CX=YOUR_CX_ID}"After the Lambda is done creating, we can test using the AWS cli to make sure our function works in Lambda:
aws lambda invoke --function-name bedrock-scraper --cli-binary-format raw-in-base64-out --payload '{"function":"google_search", "parameters":[{"name":"query","value":"safest cities in USA"}]}' response.jsonIf we inspect response.json it should look something like:
{
"messageVersion": "1.0",
"response": {
"actionGroup": "",
"function": "google_search",
"functionResponse": {
"responseBody": {
"TEXT": {
"body": "{\"results\":[{\"title\":\"The 10 Safest Cities in America | Best States | U.S. News\",\"link\":\"https://www.usnews.com/news/cities/slideshows/safest-cities-in-america\"}..."
}
}
}
}
}Excellent - now let's expose this capability to a Bedrock agent.
We first need to create a basic Bedrock agent. We can do this via the CLI. If you'd like more details on this process see the AWS documentation on creating a Bedrock agent and adding an action group to a Bedrock Agent.
Start by creating a policy and role for the agent. This allows the agent to invoke the foundation model in Bedrock (Check your account to make sure the model you want is available in your region). I'll be naming mine BedrockAgentInvokeClaude and applying to a role called bedrock-agent-service-role.
(Remember to replace 111122223333 and us-east-1 with your account ID and region)
aws iam create-policy --policy-name BedrockAgentInvokeClaude --policy-document '{"Version":"2012-10-17","Statement":[{"Sid":"VisualEditor0","Effect":"Allow","Action":"bedrock:InvokeModel","Resource":["arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0","arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0","arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0","arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2","arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2:1","arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-instant-v1"]}]}'
aws iam create-role --role-name bedrock-agent-service-role --assume-role-policy-document '{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Principal":{"Service":"bedrock.amazonaws.com"},"Action":"sts:AssumeRole","Condition":{"StringEquals":{"aws:SourceAccount":"111122223333"},"ArnLike":{"AWS:SourceArn":"arn:aws:bedrock:us-east-1:111122223333:agent/*"}}}]}'
aws iam attach-role-policy --role-name bedrock-agent-service-role --policy-arn arn:aws:iam::111122223333:policy/BedrockAgentInvokeClaude Now we can create the Agent using Claude v3 sonnet as the model (you may need to request access to some models): (Be sure to use the ARN of your new role from above)
aws bedrock-agent create-agent \
--agent-name "scrape-agent" --agent-resource-role-arn arn:aws:iam::111122223333:role/bedrock-agent-service-role \
--foundation-model anthropic.claude-3-sonnet-20240229-v1:0 \
--instruction "You are a helpful agent that can search the web and scrape content. Use the functions available to you to help you answer user questions."Using the agentArn of our new agent, give it permission to invoke the lambda function:
(Remember to use your own agent ARN/ID here)
aws lambda add-permission \
--function-name bedrock-scraper \
--statement-id bedrock-agent-invoke \
--action lambda:InvokeFunction \
--principal bedrock.amazonaws.com \
--source-arn arn:aws:bedrock:us-east-1:111122223333:agent/999999Now, using our Lambda ARN from previously, let's add an action group: (Remember to use your own Lambda ARN and agent ID here)
aws bedrock-agent create-agent-action-group \
--agent-id 999999 \
--agent-version DRAFT \
--action-group-executor lambda=arn:aws:lambda:us-east-1:111122223333:function:bedrock-scraper \
--action-group-name "search-and-scrape" \
--function-schema '{"functions": [{"name":"google_search","description":"Search using google","parameters":{"query":{"description":"Query to search on Google","required":true,"type":"string"}}}, {"name":"scrape","description":"Scrape content from a URL","parameters":{"url":{"description":"Valid URL to scrape content from","required":true,"type":"string"}}}]}'Now prepare the agent: (Remember to use your own agent ID here)
aws bedrock-agent prepare-agent --agent-id 999999Now, FINALLY, we can test our agent.
It's easy to test the agent using the AWS console.
Go to Bedrock > Agents and you should see your new agent. Open it and click Test. Ask it a question only an agent with access to the web could answer:
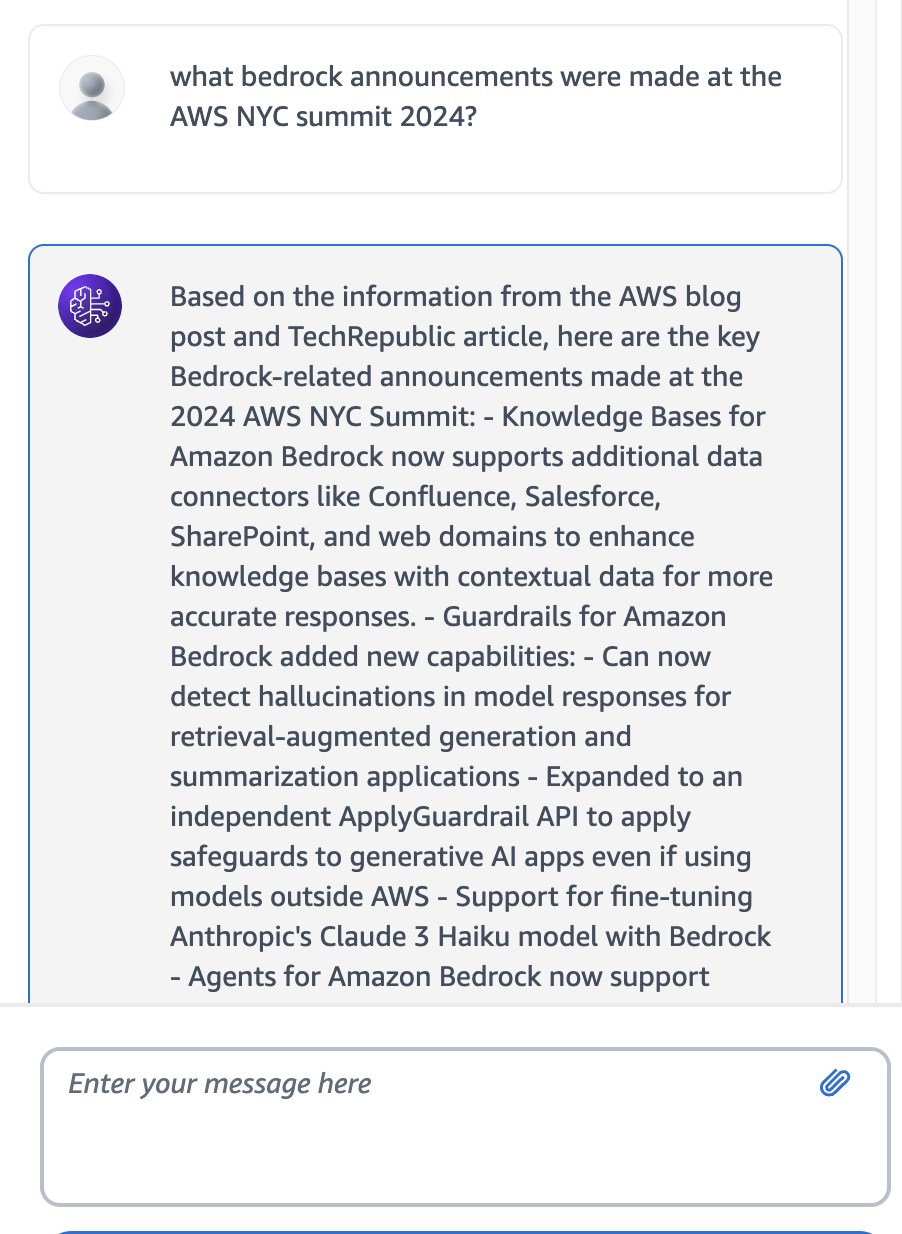
This was a quick-and-dirty way to get a Bedrock agent up and running. I will eventually turn this into a CloudFormation template to make it easier to deploy (star the GitHub for updates).
If you no longer want them, you can delete the Lambda function, ECR image, Bedrock agent, and IAM resources: (Don't forget to use your own account ID's and ARNs here)
aws bedrock-agent delete-agent --agent-id 999999
aws iam detach-role-policy --role-name bedrock-agent-service-role --policy-arn arn:aws:iam::111122223333:policy/BedrockAgentInvokeClaude
aws iam delete-policy --policy-arn arn:aws:iam::111122223333:policy/BedrockAgentInvokeClaude
aws iam delete-role --role-name bedrock-agent-service-role
aws lambda delete-function --function-name bedrock-scraper
aws iam detach-role-policy --role-name lambda-ex --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
aws iam delete-role --role-name lambda-ex
aws ecr delete-repository --repository-name bedrock-scraper --forceFor more information on Bedrock agents and how to use them, see the AWS documentation.
Full code available on GitHub.
Question? Comments? Let me know, I look forward to seeing what you build with Bedrock!