Chunyuan Li♠ Kurt Keutzer♣ Trevor Darrell♣ Ziwei Liu✉,♥
♣University of California, Berkeley ♠Microsoft Research, Redmond
*Equal Contribution †Project Lead ✉Corresponding Author
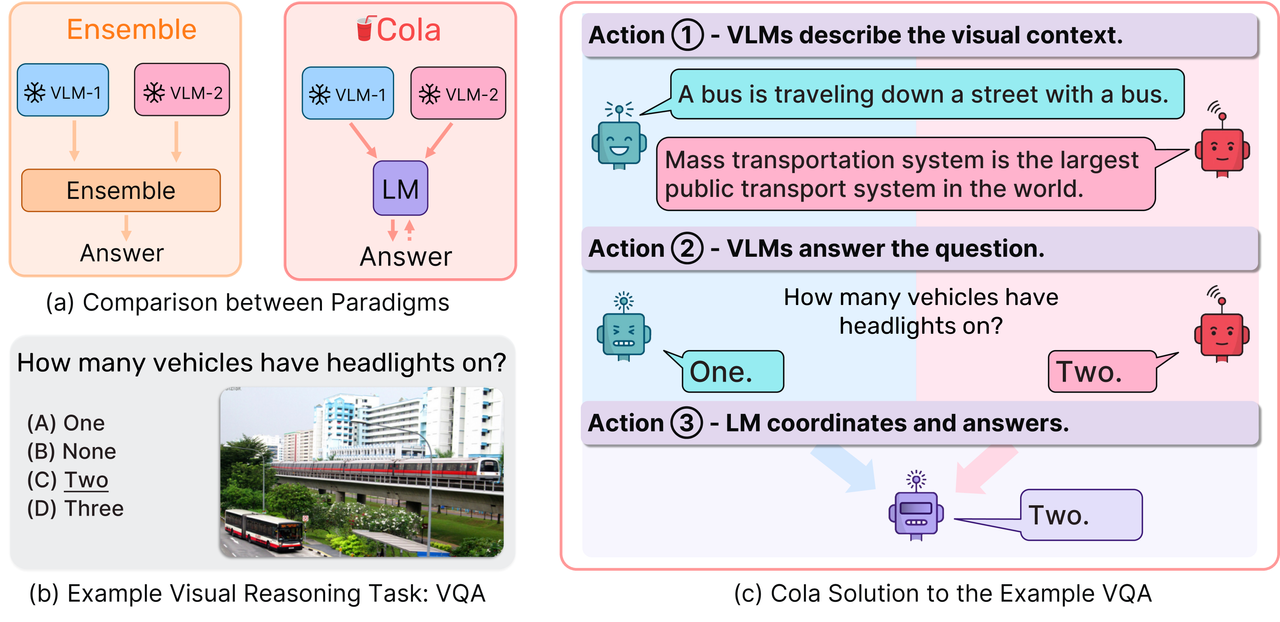
We use a language model (LM) to aggregate the outputs of 2+ vision-language models (VLMs). Our model assemble approach is named Cola (COordinative LAnguage model or visual reasoning). Cola is most effective with the LM finetuned (termed as Cola-FT). Cola is also effective with zero-shot or few-shot in-context learning (termed as Cola-Zero). Beside the performance gain, Cola is also more robust to the VLMs' errors. We show that Cola can be applied to various VLMs (including large multimodal models like InstructBLIP) and 7 datasets (VQA v2, OK-VQA, A-OKVQA, e-SNLI-VE, VSR, CLEVR, GQA), and it consistently improves the performance.
I highly recommend you to update NVIDIA drivers and CUDA to the latest version in case of weird bugs. See requirements.txt for the environment where the code is tested with.
conda env create -f cola.ymlWe use bf16 for inference and finetuning, which supports newer GPUs.
mkdir datasets
mkdir predictions
mkdir pretrained_modelsBelow are the datasets we tested, you don't have to download all. I suggest starting with A-OKVQA.
- A-OKVQA: download from official page
- OK-VQA: download from official page
- VQAv2: download from official page
- CLEVR: download from Kaggle
- COCO & GQA: download by LAVIS script
- VSR: download from official page
- e-SNLI-VE & Flickr30k: download from official page
We convert all the datasets to the format of A-OKVQA dataset. See ./data_utils for conversion scripts.
datasets
├── aokvqa
├── okvqa
├── coco
│ ├── train2017
│ ├── val2017
│ └── test2017
├── esnlive
│ └── flicr30k_images
├── vsr
│ └── trainval2017
├── vqav2
├── gqa
│ └── images
└── clevrDownload OFA model from Huggingface. Other models can be downloaded automatically.
cd ..
git lfs clone https://huggingface.co/OFA-Sys/ofa-large# 1. Get the plausible answers for the validation set
python query/query_blip.py --data-dir ./datasets/ --dataset-name aokvqa --split val --vlm-task vqa --bs 128 --prediction-out ./predictions/aokvqa_blip_vqa_val-da.json
python query/query_ofa.py --vlm-model-path ../OFA-large --data-dir ./datasets/ --dataset-name aokvqa --split val --vlm-task vqa --bs 128 --prediction-out ./predictions/aokvqa_ofa_vqa_val-da.json
# 2. Get the captions for the validation set
python query/query_blip.py --data-dir ./datasets/ --dataset-name aokvqa --split val --vlm-task caption --bs 128 --prediction-out ./predictions/aokvqa_blip_caption_val-da.json
python query/query_ofa.py --vlm-model-path ../OFA-large --data-dir ./datasets/ --dataset-name aokvqa --split val --vlm-task caption --bs 128 --prediction-out ./predictions/aokvqa_ofa_caption_val-da.json
# 3. Query the language model, Cola-Zero. Delete "--incontext --num-examples 2" for 0-shot inference.
python query/query_flan.py --data-dir ./datasets/ --dataset-name aokvqa --split val --vlm-task vqa --bs 128 --prediction-out ./predictions/aokvqa_cola2-da.json --max-new-tokens 250 --llm google/flan-t5-small --vlm1 ofa --vlm2 blip --include-profile --include-caption --include-choices --incontext --num-examples 2
## Another example: query Mistral-7B, with InstructBLIP-XL and XXL
python query/query_llm.py --data-dir ./datasets/ --dataset-name aokvqa --split val --vlm-task vqa --bs 128 --prediction-out ./predictions/aokvqa_mistral_cola2-da.json --max-new-tokens 250 --llm mistralai/Mistral-7B-v0.1 --vlm1 insblipt5xl --vlm2 insblipt5xxl --include-profile --include-caption --include-choices --incontext --num-examples 2
## Another example: query Mistral-7B, on test set of aokvqa
python query/query_llm.py --data-dir ./datasets/ --dataset-name aokvqa --split test --vlm-task vqa --bs 128 --prediction-out ./predictions/aokvqa_mistral_cola2_test-da.json --max-new-tokens 250 --llm mistralai/Mistral-7B-v0.1 --vlm1 insblipt5xl --vlm2 insblipt5xxl --include-profile --include-caption --include-choices --incontext --num-examples 2
## Another example: query Vicuna-7B, on test set of aokvqa
python query/query_llm.py --data-dir ./datasets/ --dataset-name aokvqa --split test --vlm-task vqa --bs 16 --prediction-out ./predictions/aokvqa_vicuna_cola2_test-da.json --max-new-tokens 250 --llm lmsys/vicuna-7b-v1.5-16k --vlm1 insblipt5xl --vlm2 insblipt5xxl --include-profile --include-caption --include-choices --incontext --num-examples 2
# 4. Evaluate the predictions (multiple choice), see "evaluate.sh" for direct answer evaluation.
export PYTHONPATH=.
export DATA_DIR=./datasets/
export DATASET=aokvqa
export SPLIT=val
export LOG_DIR=./logs/
export PREDS_DIR=./predictions
export PT_MODEL_DIR=./pretrained_models/
export PREFIX=aokvqa_cola0
python evaluation/prepare_predictions.py \
--data-dir ${DATA_DIR} --dataset ${DATASET} \
--split ${SPLIT} \
--da ${PREDS_DIR}/${PREFIX}-da.json \
--mc ${PREDS_DIR}/${PREFIX}-mc.json \
--out ${PREDS_DIR}/${PREFIX}.json
python evaluation/eval_predictions.py \
--data-dir ${DATA_DIR} --dataset ${DATASET} \
--split ${SPLIT} \
--preds ${PREDS_DIR}/${PREFIX}.json# Get the plausible answers and captions for both training and validation sets (see Step 1 and 2 of Inference)
# 1. Finetune the language model, Cola-FT. Delete "--include-choices" for direct answer datasets. Need to "wandb login" before finetuning.
export MODEL_NAME=aok_blip_ofa_ft
WANDB_RUN_ID=${MODEL_NAME} python query/finetune_flan.py \
--data-dir ./datasets/ --dataset-name aokvqa --split train --val-split val \
--bs 16 --llm google/flan-t5-xxl --vlm1 blip --vlm2 ofa \
--prediction-out placeholder --include-profile --include-caption --include-choices
# Another example: finetune Mistral-7B or other decoder-only models
export MODEL_NAME=aok_insblipt5xl_insblipt5xxl_mistral_ft
WANDB_RUN_ID=${MODEL_NAME} python query/finetune_llm.py --data-dir ./datasets/ --dataset-name aokvqa --split train --val-split val --bs 16 --llm mistralai/Mistral-7B-v0.1 --vlm1 insblipt5xl --vlm2 insblipt5xxl --prediction-out placeholder --include-profile --include-caption --include-choices
# 2. Query the finetuned model. We don't suggest using few-shot in-context learning for finetuned models.
python query/query_flan.py --data-dir ./datasets/ --dataset-name aokvqa --split val --vlm-task vqa --bs 128 --max-new-tokens 250 --prediction-out ./predictions/aokvqa_colaft-da.json --max-new-tokens 250 --llm pretrained_models/${MODEL_NAME}/{the_epoch_you_test} --vlm1 blip --vlm2 ofa --include-choices --include-profile --include-caption
# Another example: query vicuna model on the test set of aokvqa
python query/query_llm.py --data-dir ./datasets/ --dataset-name aokvqa --split test --vlm-task vqa --bs 16 --prediction-out ./predictions/aokvqa_vicuna_colaft-da.json --max-new-tokens 250 --llm ./pretrained_models/aok_insblipt5xl_insblipt5xxl_vicuna_ft/lmsys/vicuna-7b-v1.5-16k_language_profile_bs16_epoch0 --vlm1 insblipt5xl --vlm2 insblipt5xxl --include-profile --include-caption --include-choices
# 3. Evaluate. The evaluation script is the same as Step 4 of Inference.If you use this code in your research, please kindly cite this work.
@article{chen2023large,
title={Large Language Models are Visual Reasoning Coordinators},
author={Chen, Liangyu and Li, Bo and Shen, Sheng and Yang, Jingkang and Li, Chunyuan and Keutzer, Kurt and Darrell, Trevor and Liu, Ziwei},
journal={Advances in Neural Information Processing Systems},
year={2023}
}
@inproceedings{
chen2023language,
title={Language Models are Visual Reasoning Coordinators},
author={Liangyu Chen and Bo Li and Sheng Shen and Jingkang Yang and Chunyuan Li and Kurt Keutzer and Trevor Darrell and Ziwei Liu},
booktitle={ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models},
year={2023},
url={https://openreview.net/forum?id=kdHpWogtX6Y}
}Evaluation code is borrowed from aokvqa. Part of this README is borrowed from visual_prompt_retrieval.