{kind=link}
{kind=link}
{kind=link}
This Proof-of-Concept application is dedicated to demonstrating a compliance checking system based on the SAVE model as input and SHACL-AF (Advanced Features). The full model is planned according to the following figure:

A light demo with a number of saved requests is available at https://rune-278710.ew.r.appspot.com/save/compliance.
WARNING: if you are experiencing problems with the demo interface, e.g., after running the compliance check the results are not being displayed, please try another browser. The demo has been tested on Google Chrome Version 89.0.4389.114 (Official Build) (64-bit), for Ubuntu. The problems may appear when using Mozilla Firefox (Version 89.0.1 64-bit) for Ubuntu.
This module is designed to be executed upon each creation/update of a policy, therefore it does not put heavy constraints on performance. The module assumes an input of a SAVE policy (representing a policy extracted from natural language privacy policy or data processing agreement) and should include:
- automated conflict detection;
- expert-assisted conflict resolution;
- denormalization of conflicting rules - forming final compact and conflict-free policy;
- generation of compliance rules, enclosed in SHACL shapes graph.
This module is supposed to be deployed for on-demand compliance checking of input requests. The module assumes the following components:
- request preprocessing: incoming request can contain metadata and mention physical data sources - tables, columns, etc. The preprocessing is supposed to:
- use external Access Control tool to check user's permissions;
- if permissions were granted, the component uses external Business Catalog to link physical sources to SAVE concepts. The development of such catalog is out of the scope of this prototype;
- normalize the request into atomic subrequests in order to perform high granularity compliance checking.
- Compliance Checking: using the generated SHACL shapes, the component checks the request expressed in SAVE terms against the shapes and infers new triples containing the detailed response.
This first version of the prototype implements the following components:
- from Preprocessing module - Compliance Rules Generation and Conflict Detection (raw, no resolution yet). Therefore, current policies can potentially contain conflicts (i.e., incoming requests can be permitted and prohibited at the same time);
- and from Compliance Checking module - Request Preprocessing (normalization only) and Compliance Checking.
The SHACL-Core version of the compliance checking procedure follows the straightforward definition of compliance checking: it materializes each subrequest and checks it separately against the policy.
The SHACL-SPARQL version avoids materialization of subrequests and instead creates a "combined" normalized request using RDFList properties. SHACL core components are not capable of processing conditions for this type of properties, therefore the checking is done thorugh SPARQL constraints. Due to heavy usage of SPARQL this version is slower on atomic requests or requests with small number of subrequests, however it wins in performance on heavy requests.
Both versions provide, besides the answer to the request - granted, prohibited, partly-granted, etc. - a detailed report (as RDF triples) of which subrequests (or groups of subrequests) are "covered" by which rules. The format of the full report of both version may be slightly different due to implementation specifics.
The more detailed description of both procedures and examples can be found in the documentation below.
In order to demonstrate the capabilities of the current version, some tests have been prepared. All tests can be parametrized and rerun.
For convenience, a script (target/run.sh) is provided, where the test can be chosen and parameters set.
The following instructions detail the building and running the experiments. Then, each experiment is described in detail.
In order to run the experiments, you will need to have the following tools and libraries installed:
java(jdk if you wish to compile, jre otherwise). The exact version used by the authors to run the tests (oracle-jdk):The version is important, as the code contains block strings that are not available in the earlier versions.java 16 2021-03-16 Java(TM) SE Runtime Environment (build 16+36-2231) Java HotSpot(TM) 64-Bit Server VM (build 16+36-2231, mixed mode, sharing)
mavento build the jar with dependencies (only if rebuild is needed); version 3.6.3 was used in the project.- command line interpreter (shell) to run the test script;
- alternatively, the tests could be run from and IDE (such as IntelliJ Idea) by setting parameters in the Run interface, or using default parameters;
- the last option is to run tests through
docker, so if it is chosen, docker should be installed. Any version should do. WARNING! if you run the experiments with docker, it is run in headless mode, therefore the charts will not be available!
The original experiments were run on Linux machine:
- Ubuntu 18.04.5 LTS
- 15,6 GiB RAM
- Intel® Core™ i7-8550U CPU @ 1.80GHz × 8
The initial version of the project already has everything needed to run the tests in the target/ folder, so there is no need to rebuild the jar.
However, if the project needs to be recompiled due to jre versions mismatch or for whatever other reason, it can be done with Maven.
The jar needs to have all dependencies in it (jena, topquadrant-shacl, etc.), and all goals are already described in the pom.xml file, so all that is needed is to run the following command (from command line or from IDE, maven should be installed before):
mvn clean installExecuting this command will create the jar and all necessary file in the target/ forlder. The jar you need is called shacl-compl-1.0-SNAPSHOT.jar.
Additionally, maven will process files in the run_script/ folder (run.sh and Dockerfile) and put them in target/. They are needed to run the experiment.
The script run.sh is located in the target/ folder, along with the dockerfile.
To run the script, you need to run the following commands from the root of the project.
cd target/
sh run.shThe script has all the default parameters, so the default test (IMDB test requests) will run. Depending on the chosen parameters, the test will run either by executing java command (default), or by building and running a docker container.
The full list of parameters and their specification is inside the run.sh file.
The run.sh script contains the command to run the tests with the built jar. In order to run with jre, you need to set parameter use_docker=false.
Then, sh run.sh command will run the tests with jre by default.
If you cannot run the run.sh script, you can run the program without the script. You need to run the following command (from the target/ folder):
java -jar shacl-compl-1.0-SNAPSHOT.jar --mode=${mode} --outputFolder=${outputFolder} --sparql="${sparql}" --evalMode=${evalMode} --ultimate="${ultimate}" --seeds="${seeds}" --policySizes="${policySizes}" --nRules="${nRules}"Where each parameter should be set according to the format presented in run.sh script. If you want to stick to default parameters, you will
only need to set the two required parameters: outputFolder and mode (explained down below).
java -jar shacl-compl-1.0-SNAPSHOT.jar --mode=${mode} --outputFolder=${outputFolder} If you set use_docker=false, the tests will be run through docker container.
!WARNING: if you run with docker, there will be no charts generated for evaluation tests (docker java runs in headless mode)!.
In this case, run.sh will build the docker image and run it for you with the parameters specified in the script.
One important factor with docker: the outputFolder parameter should be relative to the shared_volume parameter, so that the container can write the output to the folder outside the container (see how outputFolder parameter is set in the script).
If you run with jre and not docker, you can set outputFolder to whatever folder on your disk (absolute path or relative to the target/ folder).
If you wish to run outside the script, make sure you build the image first using the Dockerfile in the target/ folder (not in run_script/) and spcify the shared_volume folder properly if you want to see any output.
You can use the following commands (together or one by one) and fill in the necessary parameter values:
docker build -t="shaclcompl/tests:latest" .
sleep 10
docker run --rm --name=shacl_compliance_container -v ${shared_volume}:/shared -it shaclcompl/tests:latest --mode=${mode} --outputFolder=${outputFolder} Other optional parameters besides mode and outputFolder may be appended at the end, in the same way as it is done in the java command.
If you edit the script and wish to rerun it, there are few steps to be considered:
- if the code has been changed, first rebuild the jar (
mvn clean install); if the code stayed unchanged go straight to the next point; - edit the parameters of
run.shscript in thetarget/folder and rerun the script withsh run.sh.
If only the parameters of the experiments change, there is no need to rebuild anything, only rerunning the script is necessary. Try to never edit the script in run_script/ directory, because it will require rebuilding the project, in order to copy it to the target/ folder.
Alternatively, if you wish to debug, the tests can be all run with an IDE, such as IntelliJ Idea. The main class is called SAVETests and it shpws all the declared tests and parameters and how they are used.
If you want to run th tests, you need to create a Run configuration in the IDE that would run SAVETests class. Then, you can add parameters into the CLI arguments box.
The short and full names of the arguments could be found in SAVETests.main method.
The SAVETests class and run.sh script lets you run 5 types of tests. We describe each test and its parameters and expected outputs below.
For each test a specific folder is created under outputFolder (and updated if the same tests is run repeatedly). Each test fills a SHACLComplianceResult object and writes the results into a file.
The contents of the file differs from test to another, depending on which values are important.
run.sh describes a set of parameters necessary to run each test. Here are the common parameters regardless of the test:
- script parameters:
use_docker=true/false(default): indicates whether or not to run the tests through docker;download_image=true/false(default): whether or not to build an image from sources or download from dockerhub;shared_volume: the folder on your disk that you wish to use. Important ifuse_docker = true.
SAVETestsinput parameters:mode=inf/eval/conflormode=0/1/2: choose if you want to run the test inference or conflict detection on IMDB requests or the evaluation tests. This parameter is required.outputFolder: the folder where the outputs of all tests should go. Inrun.shit is programmatically set to start withshared_volumeand reflect the experiment name and parameters. This parameter is required.eval_mode=imdb_simple/imdb_atomic/random_atomic: the type of evaluation experiment to run. The description of the modes is detailed below.
The script sets default parameters for everything, so there is no need to bother setting them. The information below is there for documentation and debugging purposes.
This test runs when mode=inf. It will perform compliance checking against the IMDB policy on test requests.
FYI the policy files are (no need to set anything, the test will know where to find the files):
src/main/resources/save.imdb.policy.ttl: original policy expressed in SAVE terms;src/main/resources/IMDBPolicy.shapes.core.ttl: SHACL shapes for the SHACL-Core compliance checking procedure;src/main/resources/IMDBPolicy.shapes.sparql.ttl: SHACL shapes for the SHACL-SPARQL compliance checking procedure.
The test runs either SHACL-Core or SHACL-SPARQL version, depending on the parameters set in run.sh. The necessary parameters:
sparql=true/false(default): whether to run the SHACL-Core or the SHACL-SPARQL version;ultimate=true/false(default): whether to run the "worst case" request. Iftrue, the request will be parsed from thesrc/main/resources/testIMDBRequestUltimate.ttlfile, iffalse- fromsrc/main/resources/testIMDBRequests.ttl. WARNING: The "worst case" request cannot be tested with the SHACL-Core procedure. The SHACL-SPARQL one should take about 5 min.
Note: since the conflict detection/resolution functionality is not integrated in this version, the IMDB policy in the tests contains conflicts. Therefore, any request checked against it can be both granted and prohibited at the same time. This is not an error in the algorithm, merely an indication of a conflict between the rules in the policy. Some prohibitions in the policy are very general, therefore almost any request to IMDB data will be at least partly prohibited.
The test file src/main/resources/testIMDBRequests.ttl contains 10 manually created requests that can be verified against IMDB policy.
src/main/resources/testIMDBRequestUltimate.ttl contains only one request with roots of SAVE taxonomies for hierarchical attributes, and one or more values for constant attributes.
It is intended to recreate the "worst case" situation where the number of subrequests explodes. This is the reason it cannot be run with the SHACL-Core procedure, only the onptimized one (should take roughly 5 min).
The output folder for this test (according to run.sh) will be called ${shared_volume}output_inf_sparql${sparql}_ultimate${ultimate} (or you can set it to whatever value suits you).
Inside this folder you will find several output files:
inference_core_test_requests.txt: output stats for the SHACL-Core version. The metrics calculated there are:- #Requests: how many requests were supposed to be processed;
- #Processed: how many were actually processed (without errors);
- Triples inferred: how many triples were inferred (may differ for SHACL-Core due to slightly different implementations);
- Total exec time: total time for the batch;
- Avg time per request: average time for one request;
- Avg time per subrequest: average time for one subrequest;
inference_core_test_requests_subrequests.ttl: file containing all subrequests for each request is SHACL-Core mode;inference_core_test_requests_triples.ttl: file containing all inferred triples with query answers for SHACL-Core mode. The triples are inferred for each subreqeust separately and then for the whole request. To find the final answer for a request, search for the name of the request WITHOUT the subrequest number at the end, i,.e.save-ex:Request_10_test, NOTsave-ex:Request_10_test_0.inference_sparql_test_requests.txt: output stats for the SHACL-SPARQL version. Contains the same metrics as the one for SHACL-Core version, except Avg time per subrequest is always 0, as there are no subrequests processed separately.inference_sparql_test_requests_subrequests.ttl: contains the "normalized" version of the request created for the SHACL-SPARQL version using RDFList properties;inference_sparql_test_requests_triples.ttl: inferred triples with answers to queries. The triples are in a different format than SHACL-Core version, but the final answer should be the same.
The same files with stats and results will be created for the ultimate request, but instead of "test_requests" they will say "ultimate_request".
The conflict detection is implemented as a proof-of-concept and is not integrated into the model yet.
This test runs when mode=confl.
It is included in the tests purely for demonstration purposes.
To be integrated, the resolution and denormalization parts need to be finalized, and it is in progress at the moment.
The detection is implemented using the Compliance Rules Generation and SHACL-SPARQL procedure for compliance checking.
0. The input is the policy where we wish to find conflicts (IMDB, src/main/resources/save.imdb.policy.ttl);
- The permissions of the policy are translated into SHACL rules using the SHACL-SPARQL procedure;
- The prohibitions of the policy become "requests";
- The "requests" are normalized and SHACL-SPARQL compliance checking procedure is applied to find "intersections" between the prohibitions and permissions.
- These "intersections" are the conflicting DPSs between permissions and prohibitions.
The execution logs will show for each prohibition, how many conflicts were found.
The conflicts themselves will be in the test_imdb_conflicts_stats_triples.ttl file.
The output folder for this test (according to run.sh) will be called ${shared_volume}output_confl_imdb (or you can set it to whatever value suits you).
Inside this folder you will find several output files:
test_imdb_conflicts_stats.txt: output stats. The metrics calculated there are:- Triples inferred: how many triples were inferred;
test_imdb_conflicts_stats_subrequests.ttl: file containing normalized version for each prohibition;test_imdb_conflicts_stats_triples.ttl: file containing all inferred triples - conflicting DPSs. The final result of the "compliace checking" in the file does not matter, what we are interested here are the conflicts themselves.
Note: the example rules in the paper (Permission1 and Prohibition8) were taken from IMDB policy, however they were modified for space saving, clarity and demonstration purposes. Hence, the conflicts found in this test may not be the same as the ones identified in the paper. Since the conflict-related functionaity is in progress, it still requires rigorous testing, which is palnned for the whole system as the near future work.
This test runs when mode=eval and eval_mode=imdb_atomic. The test generates batches of atomic requests and tests them against IMDB policy.
The parameters for this test:
seeds: the list of seeds to use (for reproducibility). List should be comma-separated without spaces;nRules: the list of batch sizes, comma-separated without spaces;
The output folder is called ${shared_volume}output_eval_imdb_atomic/ and contains the following files and folders:
logs/folder: contains all intermediate results for each seed/batch. Usually not needed.test_imdb_atomic_core_total_stats.txtandtest_imdb_atomic_core_total_stats.txt: output stats files for the two procedures. The metrics:- #Requests: total number of requests generated;
- #Processsed: total number of requests processed without errors;
- Triples inferred: total number of inferred triples (may differ between SHACL-Core and SHACL-SPARQL version due to differences in implementation);
- Total exec time: for all seeds and batches;
- Avg time per request: between all seeds and batches;
- Avg time per subrequest: will be 0 for SHACL-SPARQL version (no separate subrequests).
- Count per # of atomic requests in a batch: how many examples we have for each graph x point, in this case - number of seeds;
- Avg time per # of atomic requests in a batch: points for the graph;
test_imdb_atomic_core_total_triples.ttlortest_imdb_atomic_sparql_total_triples.ttl: total inferred triples for all seeds and batches;atomic.png: chart generated from the points. X - number of reqeusts in the batch, Y - avg time per batch.
This test runs when mode=eval and eval_mode=imdb_simple. The test generates a batch of simple requests per seed and tests it against IMDB policy.
The parameters for this test:
seeds: the list of seeds to use (for reproducibility). List should be comma-separated without spaces; In this test, to get more comprehensive results it is better to set more seeds, around 20 different.nRules: the batch size (just one);
The output folder is called ${shared_volume}output_eval_imdb_simple/ and contains the following files and folders:
logs/folder: contains all intermediate results for each seed. Usually not needed.test_imdb_simple_core_total_stats.txtandtest_imdb_simple_core_total_stats.txt: output stats files for the two procedures. The metrics:- #Requests: total number of requests generated (
nRules*seeds.size()); - #Processsed: total number of requests processed without errors;
- Triples inferred: total number of inferred triples (may differ between SHACL-Core and SHACL-SPARQL version due to differences in implementation);
- Total exec time: for all seeds and batches;
- Avg time per request: between all seeds and batches;
- Avg time per subrequest: will be 0 for SHACL-SPARQL version (no separate subrequests).
- Count per # of subrequests: how many examples we have for number of subrequests. Depends on the seeds (we cannot predict or "order" the number of subrequests in a random request).
- Avg time per # of subrequests: average time of execution for each number of sunrequests;
- Count per # of subrequests (binned): how many examples we have for number of subrequests (binned for convenience).
- Avg time per # of subrequests (binned): points for the graph.
- #Requests: total number of requests generated (
test_imdb_simple_core_total_triples.ttlortest_imdb_simple_sparql_total_triples.ttl: total inferred triples for all seeds and batches;simple_bin.png: chart generated from the points. X - number of subreqeusts in a request, Y - avg time per request. This chart needs to be binned, otherwise it has too little examples for averaging and the chart becomes hard to analyse. We make sure there is at least 10 examples for each number of subreqeusts, so there will be requests with different answers.
This test runs when mode=eval and eval_mode=random_atomic. The test firstly generates random policies of different sizes, consisting of simple rules, and then
batch of random atomic requests for them.
The parameters for this test:
seeds: the list of seeds to use (for reproducibility). List should be comma-separated without spaces. This experiment can be heavy on the memory, so smaller number of seeds can be used.nRules: the batch size (just one);
The output folder is called ${shared_volume}output_eval_random_atomic/ and contains the following files and folders:
generated_policies/folder: contains all generated random policies. Usually not needed, just fyi.logs/folder: contains all intermediate results for each seed. Usually not needed.test_random_atomic_core_total_stats.txtandtest_random_atomi_sparql_total_stats.txt: output stats files for the two procedures. The metrics:- #Requests: total number of requests generated;
- #Processsed: total number of requests processed without errors;
- Triples inferred: total number of inferred triples (may differ between SHACL-Core and SHACL-SPARQL version due to differences in implementation);
- Total exec time: for all seeds and batches;
- Avg time per request: between all seeds and batches;
- Avg time per subrequest: will be 0 for SHACL-SPARQL version (no separate subrequests).
- Count per # of simple rules in a policy: how many examples we have per policy size. Here -
seeds.size(). - Avg time per # of simple rules in a policy: average time of execution for each policy size, i.e., points for the graph.
test_random_atomic_core_total_triples.ttlortest_random_atomic_sparql_total_triples.ttl: total inferred triples;random_policies.png: chart generated from the points. X - number of simple rules in a policy, Y - avg time per request.
- Some parameters in
SAVETestsare required, some are optional. To make sure the program runs smoothly with your desired parameters it is best to use the provided scriptrun.sh- it runs the jar with all parameters specified in the correct form. - When changing parameters in the script, please make sure they are in the same format as the original ones. This way you will avoid malformed parameters.
In this prototype, the models are stored in memory and that is where all the execution happens. Therefore, some problems with memory may be expected in heavy experiments, although the default parameters in the provided scripts should not cause any issues on a machine comparable to ours. If you encounter memory problem while running a custom experiment, please decrease one of the parameters:
nRules: smaller value (inimdb_simpleorrandom_atomic) or less values inimdb_atomiccan decrease the memory usage.seeds: by decreasing the number of seeds the experiment will run faster and take less memory, but provide less values for averaging.policySizes(inrandom_atomic): by setting less values or decreasing the values themselves you can avoid memory issues.
- Make sure the output directory in the script can be written into.
If it requires root access, use
sudoto run the script (sudo sh run.sh). - The output directory is the root, and each experiment will have different subdirectory based in its name.
- The chart and final statistics and results can be found in the corresponding subdirectory, and logs per seed/parameter should be
/logsfolder.
- In case of permission issues with docker, try running the script in
sudomode (if docker was installed to run insudomode) -sudo sh run.sh. - If the image does not exist by the time the script tries to run it, it could be that the building process takes more time. Try to increase the
sleepinterval after thedocker buildcommand.
The project is the first version of the SHACL-based compliance checking system implementation, including automated SHACL shapes generation, request normalization and compliance checking using two procedures - SHACL-Core and SHACL-SPARQL.
The system is using SAVE model for privacy policies.
The SAVE ontology and IMDB policy expressed in SAVE terms was downloaded using available links in the model's documentation.
These files were then lightly preprocessed in order to be used in this system (prefixes were added, and examples separated from the ontology).
The resulting files are:
src/main/resources/save.ontology.ttl: SAVE ontology. Contains the names of the authors of SAVE.src/main/resources/save.imdb.policy.ttl: the IMDB policy, extracted from SAVE ontology file and separated.src/main/resources/dpv.ttl: the DPV ontology, imported by SAVE;src/main/resources/odrl_regulatory_profile_prefixed.ttl: the ORCP ontology, imported by SAVE;src/main/resources/save.shapes.ttl: file with the main shape for vaidation of any request, created manually by us.src/main/resources/testIMDBRequests.ttl: file with the test requests for IMDB policy, created manually by us.src/main/resources/testIMDBRequestUltimate.ttl: file with the "worst case" test request for IMDB policy, created manually by us.
The rest of the files were automatically generated by the system - policy shape files
src/main/resources/IMDBPolicy.shapes.core.ttl and src/main/resources/IMDBPolicy.shapes.sparql.ttl, for example. These files are used in the inference and evaluation tests.
These are all the files that are used by the code to reproduce the tests. Any other files found are there for debugging putposes.
The project has the following structure:
- root folder contains this README file, as well as
pom.xmlfor cmpiling and building the project. evaluation/folder: used for local tests wih IDE (needs to be set as theoutputFolderin the parameters).run_script/folder: contains the Dockerfile (raw, cannot be used) andrun.shscript. Both files are preprocessed and copied into thetarget/folder upon callingmvn clean install;src/: sources folder. The code is insrc/main/java, and resource files can be found insrc/main/resources.target/folder cotains the built jar, Dockerfile and executablerun.shfile for running the tests.
SAVETests is the main clas for running tests. Its main method declares and reads all the necessary parameters and calls the corresponding test.
The classes bearing the main functionality are the following:
org.example.SAVERule: the class representing both rule and request in SAVE;org.example.SAVERuleNormalized: the class representing normalized version of SAVE rule;org.example.SAVEPolicy: the class representing a policy in SAVE;org.example.SAVEVocabulary: the helper class containing names of properties and other useful fields;org.example.SAVENormalizer: functional class that takes a SAVE rule or request and normalizes it to the atomic level.org.example.SAVERuleGenerator: functional class that generates random SAVE rules/requests/policies;org.example.SHACLPolicyTranslator: functional class that takes a SAVE policy and generates corresponding policy in SHACL shapes.org.example.SHACLInferenceRunner: functional class that can run requests or batches of requests against a policy.org.example.SHACLComplianceResult: helper class for recording the results of experiments.org.example.SAVEConflictDetector: functional class for detecting conflicts in policies, usingorg.example.SHACLPolicyTranslatorandorg.example.SHACLInferenceRunnerin SHACL-SPARQL mode.
The helper classes:
org.example.BucketHashMap: generates binned data for charts;org.example.EvaluationChart: renders charts;org.example.JenaUtils: contains helper functions in Jena;org.example.ModelUtils: contains helper functions for loading/saving DRDF graph models;org.example.SPARQLUtils: contains helper functions with SPARQL queries;SAVEDebug: internal class for debugging new features.
The SHACL-Core procedure is straightforward according to definition of the check function in the paper. The steps required for checking 1 request:
- Request normalization: each attribute value is broken down into leaves.
- For eah combination of attribute values (i.e., for each atomic subrequest):
- create a SAVE request containing the correspoding combination of values;
- check the request against all rules in the policy, if needed - infer new triples;
- Check the parent request against "final" rule of the policy: go through all inferred triples and decide the final answer.
The SHACL-SPARQL procedure follows the same logic as the SHACL-Core one but performs chek on a combined normalized request (all combinations at once). The steps required for checking 1 request:
- Request normalization: each attribute value is broken down into leaves.
- Combine all leaves/attributes into one request using RDFList properties.
- Check the combined request against each policy rule:
- check whether each attribute of the rule subsumes at least one of the request's attribute leaves;
- if every attiribute check in (i) returns true, find and infer the exact "intersections" between request and rule (the exact subrequests that are part-of the rule).
- Check the combined request against the "final" rule of the policy: go through all inferred triples and decide the final answer.
In addition to the translation example, we want to illustrate some simle use-cases of SHACL shapes.
In our use-case, based on the IMDB policy, we have discovered a conflict between Permission1 and Prohibition8. The next figure shows the result of the conflict detection/resolution stage of our system. This particular conflict has been solved manually, as the conflict detection/resolution functionality is not finalized as of yet.
Let us assume that Permission1 > Prohibition8 in this case, which means that in order to resolve the conflict, we need to "subtract" the common DPSs from the prohibition. As a result, Identifying data type loses the Name child concept, and the prohibition is denormalized including all the other children of Identifying, but without Name. Permission1 stays unchanged, since it is the stronger rule.

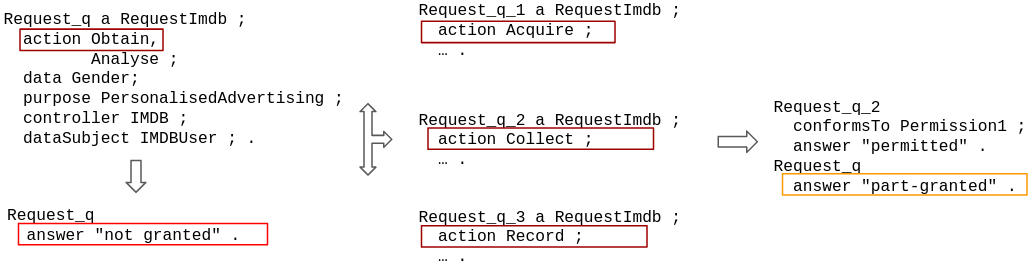
The next figure shows a request, similar to the request q from the paper, and it's compliance answer when it is not normalized against the normalized version. This example illustrates the need for normalization: the original request is deemed not granted, as there is no permission that mentions Obtain action; however, when the request is normalized, one of its leaf actions - Collect - is granted by Permission1, thus, resulting in part-granted response to the whole request.