


pg_view is a powerful command-line tool that offers a detailed, real-time view of your PostgreSQL database and system metrics. It combines the indicators commonly displayed by sar or iostat with output from PostgreSQL's process activity view, and presents global and per-process statistics in an easy-to-interpret way.
pg_view shows these types of data:
- per-process statistics, combined with
pg_stat_activityview output for the backend and autovacuum processes - global system stats
- per-partition information
- memory stats
pg_view can be especially helpful when you're monitoring system load, query locks and I/O utilization during lengthy data migrations. It's also useful when you're running servers 24x7 and aiming for zero downtime. Learn more about it at tech.zalando.com.
To run pg_view, you'll need:
- Linux 2.6
- Python >= 2.6
- psycopg2
- curses
By default, pg_view assumes that it can connect to a local PostgreSQL instance with the user postgres and no password. Some systems might require you to change your pg_hba.conf file or set the password in .pgpass. You can override the default user name with the -U command-line option or by setting the user key in the configuration file (see below).
pg_view queries system/process information files once per second. It also queries the filesystem to obtain postgres data directory and xlog usage statistics. Please note that the latter function might add an extra load to your disk subsystem.
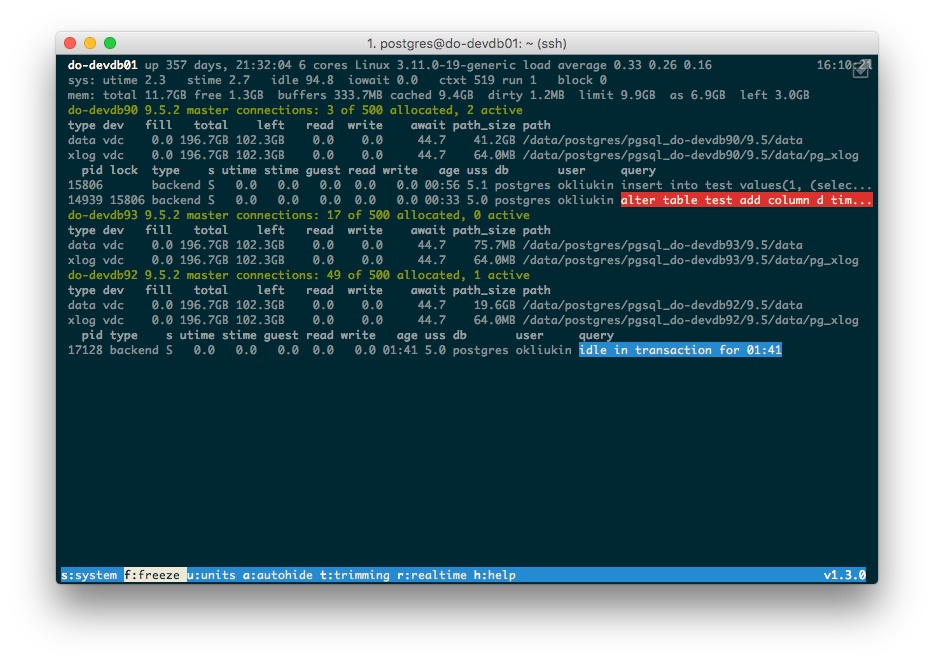
By default, pg_view tries to autodetect all PostgreSQL clusters running on the same host by performing the following steps (in order):
- reads /proc/ filesystem and detects pid files for the postmaster processes
- gets the working directories from the symlink at /proc/pid/cwd
- reads the PG_VERSION for PostgreSQL versions (if it doesn't exist, assume it's not a PostgreSQL directory, and skip)
- tries to collect from /proc/net/unix, /proc/net/tcp and /proc/net/tcp6 all the sockets the process is listening to. If that fails, and you are using version 9.1 or above, reads the connection arguments from postmaster.pid
- checks all arguments, picking the first that allows it to establish a connection
- if pg_view can't get either the port/host or port/socket_directory pair, bail out
If the program can't detect your connection arguments using the algorithm above, you can specify those arguments manually using the configuration file supplied with the -c option. This file should consist of one or more sections, each containing a key = value pair.
The title of each section represents a database cluster name (this name is for display purposes only). The dbname parameter is postgres by default, and specifies the actual name of the database to connect to. The key-value pairs should contain connection parameters.
The valid keys are:
- host: hostname or ip address, or unix_socket_directory path of the database server
- port: the port the database server listens to
- user: the database role name
The special 'DEFAULT' section contains the parameters that apply for every database cluster if the corresponding parameter is missing from the database-specific section. For instance:
[DEFAULT] port=5435 [testdb] host=localhost [testdb2] host=/tmp/test [testdb3] host=192.168.1.0 port=5433 dbname=test
Upon reading this file, the application will try using port 5435 (database postgres) to connect to both testdb and testdb2 clusters, and using the database name test port 5433 to connect to testdb3.
If the auto-detection code works for you, you can select a single database by specifying the database instance name (in most cases, it will match the last component of $PGDATA) with the -i command-line option. If there is more than a single instance with the same name, you can additionally specify the required PG version with -V.
You can get a short description of available configuration options with pg_view --help
pg_view supports three output methods:
- ncurses (default)
- console (
-o console) - json (
-o json)
Descriptions of some of the options:
- memory
- as (CommittedAs): the total amount of memory required to store the workload in the worst-case scenario (i.e., if all applications actually allocate all the memory they ask for during the startup).
- dirty: the total amount of memory waiting to be written on-disk. The higher the value, the more one has to wait during the flush.
- limit: the maximum amount of memory that can be physically allocated. If memory exceeds the limit, you will start seeing out of memory errors, which will lead to a PostgreSQL shutdown.
- For an explanation of other parameters, please refer to the Linux kernel documentation.
- partitions
- fill: the rate of adding new data to the corresponding directory (
/dataor/pg_xlog). - path_size: the size of the corresponding PostgreSQL directory.
- total, left, read, write: the amount of disk space available and allocated, as well as the read and write rates (MB/s) on a given partition. Write rate is different from fill rate, in that it considers the whole partition, not only the Postgres directories. Also, it shows data modifications. File deletion at the rate of 10MB/s will be shown as a positive write rate.
- type: either containing database data (data) or WAL (xlog).
- until_full: the time remaining before the current partition will run out of space, if we only consider writes to the corresponding data directory (
/dataor/pg_xlog). This column is only shown during the warning (3h) or critical (1h) conditions, and only considers momentary writes. If a single process writes 100MB/s on a partition with 100GB left for only two seconds, it will show a critical status during those two seconds.
- fill: the rate of adding new data to the corresponding directory (
- postgres processes
- age: length of time since the process started.
- db: the database the process runs on.
- query: the query the process executes.
- read, write: The amount of data read or written from the partition in MB/s.
- s: process state.
R- 'running',S- 'sleeping',D- 'uninterruptable sleep'; seeman psfor more details. - type: either a system process (autovacuum launcher, logger, archiver, etc.) or a process that executes queries (backend or autovacuum). By default, only user processes are shown in curses output mode (press 's' to add the system processes). Both system and user processes are shown in the console mode.
- utime, stime, guest: consumption of CPU resources by process. PostgreSQL backends can't use more than one CPU, so the percentage of a single CPU time is shown here.
- system
- ctxt: the number of context switches in the system.
- iowait: the percent of the CPU resources waiting on I/O.
- run, block: the number of running and waiting processes.
- For other parameters, please refer to man 5 proc and look for /proc/stat.
- a: auto-hide fields from the PostgreSQL output. Turning on this option hides the following fields:
type,s,utime,stime,guest. - f: instantly freezes the output. Press
fa second time to resume. - h: shows the help screen.
- u: toggle display of measurement units.
$ ./release.sh <NEW-VERSION>
pg_view welcomes contributions; simply make a pull request.