Vorschlag für Handhabung von mehrfach-transformierten Metadaten #17
Conversation
|
@lvg42 Vielen Dank für den Vorschlag, das sieht vielversprechend aus. Wer hätte denn die Autorität darüber ob ein geharvester Datensatz auf |
|
Wir in Ö haben das dadurch gelöst, dass die eindeutige ID des originären Systems immer mitübernommen werden muss. Indem die Daten digital sind, unterscheiden wir damit effektiv nicht zwischen Kopie und original. Dubletten gibt es damit nicht. Ich hoffe ich habe die Diskussion so richtig verstanden .... |
|
@the42 Dieses Feld existiert bereits in unserem Schema: Bei GovData.de steht dann aus, soll nun der Datensatz von Portal A oder Portal B bevorzugt werden? |
|
Klar, dass ist ein Problem. Eventuell per timestamp überprüfen, welcher der beiden der "jüngere" ist, oder eine Präferenz kodieren. |
|
In diesem Fall existieren zwei unterschiedliche Transformationen (Umformung der Metadaten zwischen unterschiedlichen Metadatenmodellen): Transformation A
Transformation B
Beide Transformationen liefern unterschiedliche Ergebnisse und somit keine "Kopien". Regeln:
Viele Grüße |
|
@lvg42 Danke für die Klärung Herr Weichand. Mir ist erst durch ihre Erklärung klar geworden, dass es sich nicht um Kopien handelt durch die unterschiedliche Abbildung des Metadatenformats CSW nach CKAN. Das Hinzufügen eines solchen Feldes wird in der nächsten Datenbereitstellerkonferenz besprochen. |
A new field is added to prevent possible duplicates which can result from harvesting other endpoints but CKAN. For instance, a CSV harvester has to perform a metadata mapping. If different portals do that it becomes unclear who 'owns' the dataset and which portal should be prioritized when harvesting these duplicates. See #17. Signed-off-by: Konrad Reiche <[email protected]>
Dubletten von transformierten Metadaten werden über die 'metadata_original_id' identifiziert. In diesem Fall werden durch den Autor ('author') bereitgestellte Metadaten bevorzugt.
Siehe Screenshot.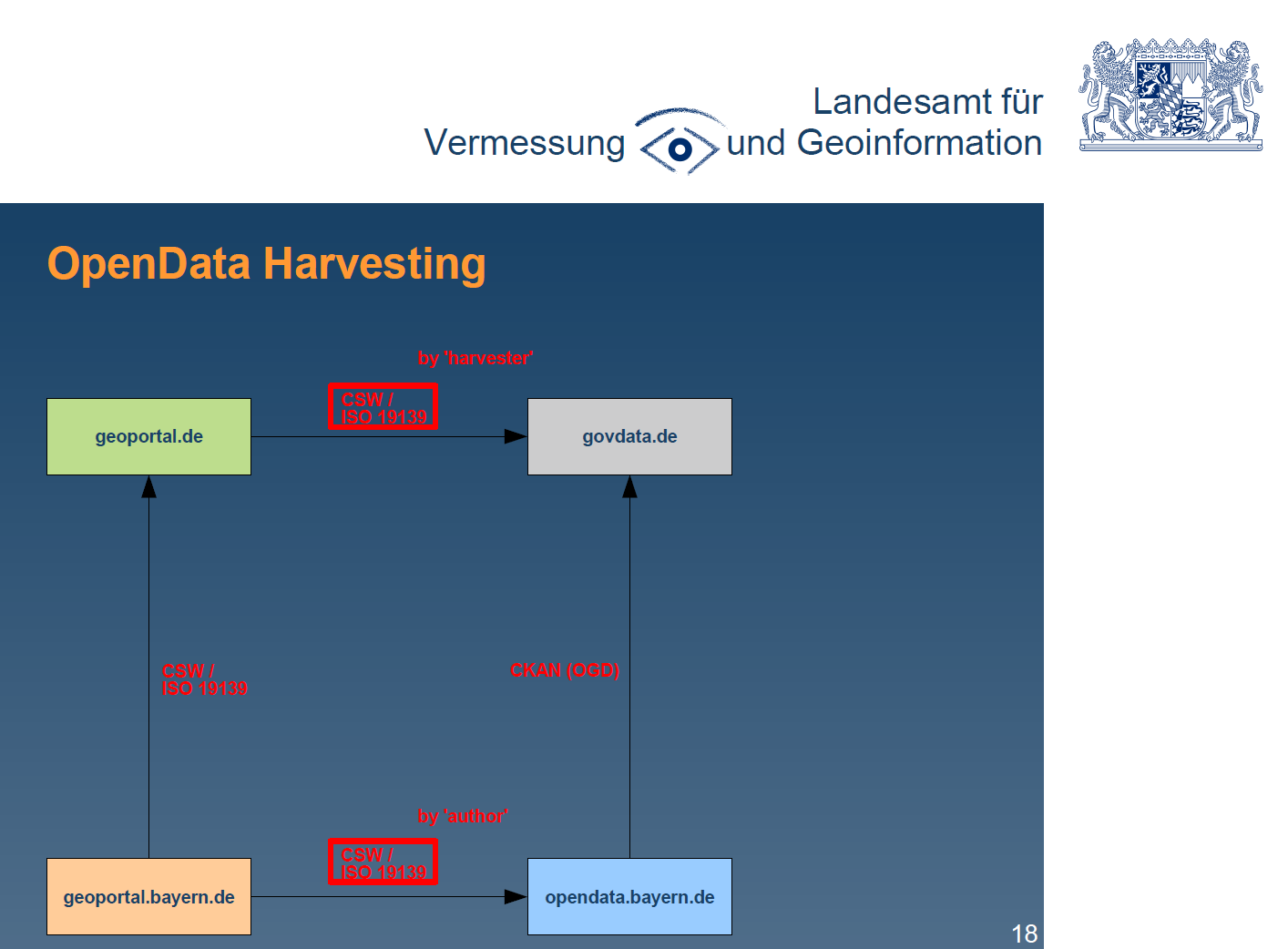
Viele Grüße
Jürgen Weichand