- Therac-25 incident (https://en.wikipedia.org/wiki/Therac-25)
- Northeast blackout of 2003
- Figure concurrency study from 2008 (MySQL/Apache/Mozilla/OpenOffice)
- Mars Pathfinder (https://en.wikipedia.org/wiki/Mars_Pathfinder#Software) 1997
- Introduction aux concepts de base tels que le parallélisme vs la concurrence, la synchronisation, la communication inter-processus, et les problèmes liés à la concurrence.
- Diner des philosophes: Un exemple classique de problème de synchronisation, qui peut être utilisé pour introduire les concepts de base de la programmation concurrente.
- Le problème du barbier endormi: Un autre exemple classique de problème de synchronisation, qui peut être utilisé pour introduire les concepts de base de la programmation concurrente.
- Le problème des producteurs-consommateurs
- Le problème de la cigarette des fumeurs : Dans ce scénario, il y a un agent et trois fumeurs. Chaque fumeur a un ingrédient (papier, tabac ou allumettes) et l'agent place aléatoirement deux des trois ingrédients sur la table. Le fumeur ayant le troisième ingrédient nécessaire fabrique et fume une cigarette, signalant ensuite à l'agent de mettre deux autres ingrédients aléatoires sur la table.
- Deadlocks et Livelocks : Les deadlocks surviennent lorsque deux threads ou plus attendent indéfiniment que l'autre libère une ressource. Les livelocks sont des situations similaires, mais avec les processus ou les threads continuant d'exécuter sans progression. Il est important de concevoir des systèmes qui peuvent détecter et récupérer de ces situations, ou mieux encore, les prévenir.
- Accès Atomique aux Données Partagées : Lorsque plusieurs threads ou processus accèdent et modifient des données partagées, il est crucial de s'assurer que ces opérations sont atomiques. Cela signifie que chaque opération sur les données partagées doit être complète sans interruption. Les mutex (verrous exclusifs) et les sémaphores sont souvent utilisés pour garantir cet accès atomique.
- Conditions de Course : Il est important de prévenir les conditions de course, qui se produisent lorsque plusieurs threads ou processus accèdent ou modifient des données partagées dans un ordre qui conduit à des résultats incohérents ou inattendus. La synchronisation correcte est essentielle pour éviter ces problèmes.
- Starvation : La starvation se produit lorsqu'un thread ou un processus n'est jamais capable d'acquérir une ressource nécessaire. Il est important d'implémenter des mécanismes d'équité pour s'assurer que chaque thread ou processus a une chance d'accéder aux ressources nécessaires.
- Outre les threads standard, vous pouvez également aborder les threads légers (par exemple, avec les bibliothèques Pthreads) et les threads basés sur des tâches (par exemple, avec la bibliothèque C++20
std::jthread). - En plus des mutex et des sémaphores, vous pourriez discuter d'autres primitives de synchronisation telles que les barrières, les variables conditionnelles, les verrous de spin, etc.
- Comment concevoir des programmes concurrents de manière efficace et sûre, en évitant les problèmes courants tels que les conditions de concurrence, les courses, les deadlocks, etc.
- Comment gérer efficacement les ressources partagées, telles que la mémoire, dans un environnement concurrent.
- Introduction à la programmation asynchrone et aux promesses/futures (utilisées en C++ avec std::future et std::promise).
- En plus de Pthreads, vous pouvez présenter des bibliothèques modernes de programmation concurrente, comme std::thread en C++11 et les fonctionnalités améliorées en C++20, telles que les coroutines (std::coroutine) et les "latches" (std::latch).
- L'enseignement de la programmation sur GPU avec des compute shaders peut être une excellente idée. Cela peut introduire les étudiants à la programmation hautement parallèle et au calcul général sur GPU.
- Étude de cas: Des exemples concrets de problèmes résolus de manière concurrente, tels que la parallélisation d'algorithmes de tri, la résolution de problèmes complexes avec des threads, etc. (Algorithme de tri bitonique, tri parallèle, etc.)
- Présentation d'outils et de bibliothèques utiles pour la programmation concurrente, tels que std::async, std::threadpool, ou des bibliothèques de haut niveau comme Intel TBB (Threading Building Blocks) ou OpenMP.
- Thread Safety ? : Il est important de noter que les threads ne sont pas toujours la meilleure solution pour la programmation concurrente. Dans certains cas, il peut être préférable d'utiliser des processus, des tâches, des événements, des canaux, des flux, etc. Il est important de choisir la bonne solution pour chaque problème.
-
TLS (Thread Local Storage)
- thread_local int var; // C++11
-
Algorithme de Lamport ?
-
Citer les avantages de certains langages comme Rust (robuste, pas de data races, multi-threadé, etc.)
-
Pas de sémaphore dans C++11 ? Counting semaphore à partir de c++20.

Le reigne de la loi de Moore approche de sa fin. Les processeurs ne sont plus plus rapides mais ils sont de plus en plus parallèles. La programmation concurrente est un paradigme de programmation qui s'impose par la force des choses.
La figure suivante illustre la courbe...
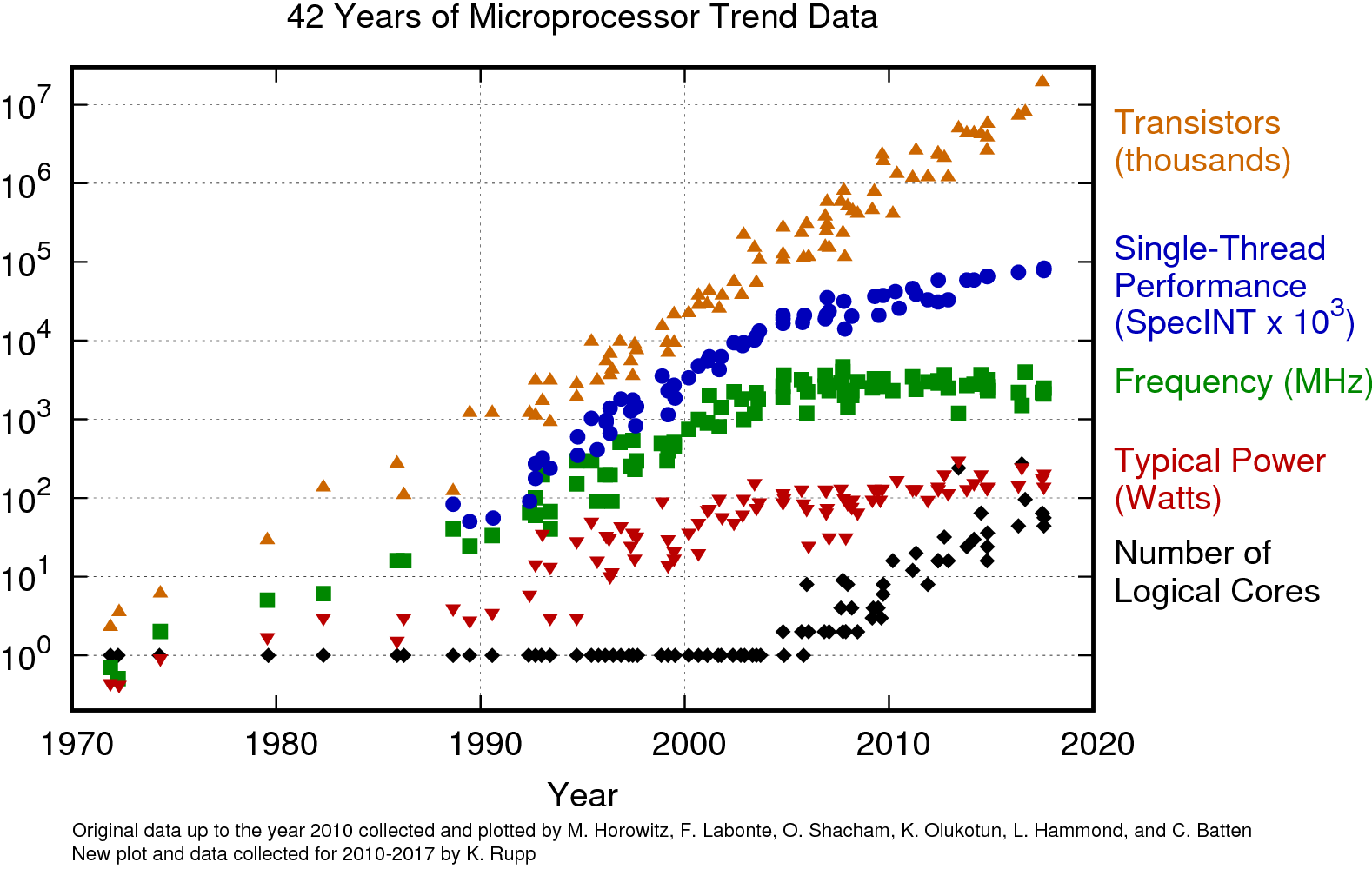
La programmation concurrente est un paradigme de programmation dans lequel plusieurs piles sémantiques nommées threads peuvent être exécutées en parallèle.
- Concurrence disjointe : les entités concurrentes ne communiquent pas et n'interagissent pas entre elles ;
- Compétitive : un ensemble d'entités concurrentes en compétition pour l'accès à certaines ressources partagées (CPU, port E/S, mémoire, etc.) ;
- Coopérative : un ensemble d'entités concurrentes qui coopèrent pour atteindre un objectif commun.
La concurrence forme un inderminisme de l'ordre d'exécution des instructions qui se manifeste dans les formes compétitives et coopératives. Des primitives de synchronisation sont nécessaires pour contrôler l'ordre d'exécution des instructions elles sont utilisées pour protéger les ressources partagées et pour coordonner les interactions entre les entités concurrentes et s'appellent des barrières.
Les problèmes principaux sont au nombre de deux :
- Les interblocages (deadlocks) : un ensemble de threads qui attendent indéfiniment les uns les autres pour libérer une ressource ;
- les famines (starvations) : un thread qui attend indéfiniment pour acquérir une ressource.
La famine se produit lorsqu'un thread ou un processus n'est jamais capable d'acquérir une ressource nécessaire. Il est important d'implémenter des mécanismes d'équité pour s'assurer que chaque thread ou processus a une chance d'accéder aux ressources nécessaires.
Il est difficile de concevoir dessystèmes concurrent à l'abri de famines de nombreux cas d'études existent ayant causé la mort ou la destruction d'équipements. Le plus connu est le Therac-25 incident (https://en.wikipedia.org/wiki/Therac-25).
La garantie d'absence de famine est possible avec des algorithmes tels que Dekker et Peterson mais ils sont très coûteux en terme de performance car ils sont basés sur une attente active (busy waiting).
L'étreinte fatale, le deadlock, sont des situations dans lesquelles deux ou plusieurs threads sont bloqués indéfiniment, chacun attendant que l'autre libère une ressource. Les deadlocks sont un problème courant dans les systèmes concurrents et peuvent être difficiles à détecter et à résoudre.
Une situation de compétition ou race condition est une situation dans laquelle le comportement d'un programme dépend de l'ordre d'exécution des instructions. Les conditions de course sont un problème courant dans les systèmes concurrents et peuvent être difficiles à détecter et à résoudre.
?
- 1965 : Edsger Dijkstra, The Structure of the "THE"-Multiprogramming System
- 1965 : Per Brinch Hansen, The nucleus of a multiprogramming system
- 1965 : C.A.R. Hoare, Monitors: An Operating System Structuring Concept
L'atomicité est une propriété d'une opération qui s'exécute comme une seule unité indivisible. Une opération atomique ne peut pas être interrompue par une autre opération. Cela signifie que l'opération doit être complètement terminée ou pas du tout. Les opérations atomiques sont généralement implémentées en utilisant des instructions de verrouillage matérielles, telles que les instructions CMPXCHG (x86) ou LDREX/STREX (ARM).
Ce terme dérive de ατομος (atomos), un mot grec qui signifie « indivisible ».
Il s'agit d'un fondement de la programmation concurrente. Deux threads qui stoquerait une valeur dans une variable partagée, sans atomicité, pourrait produire une valeur incohérente. Prenons l'exemple d'une variable 64-bits sur une architecture matérielle 32-bits. Le bus mémoire est de 32-bit et par conséquent l'enregistrement du résultat d'une opération 64-bit doit être effectuée en deux fois. Nous en convenons la probabilité qu'un thread soit interrompu pile au milieu de l'opération est très faible, mais elle existe et selon la loi de Murphy, elle se produira, au pire moment.
Certaines instructions assembleur sont spécifiquement conçues pour être atomiques. Dans le cas d'une exclusion mutuelle, nous nous reposons sur l'algorithme suivant :
- Test si le drapeau est levé (et donc si la ressource est occupée) ;
- Si le drapeau est levé, on attend ;
- Si le drapeau est baissé, on le lève et on accède à la ressource ;
- On travaille dans la section critique sans risque d'interblocage ;
- On baisse le drapeau pour libérer la ressource.
Le point 3 est le plus critique car il pourrait être interrompu entre le moment ou on a testé la disponibilité de la ressource et le moment ou on lève le drapeau. Si un autre thread a eu le temps de lever le drapeau, on aura deux threads qui accèdent à la ressource en même temps. Il faudrait donc rendre cette opération atomique mais au niveau du processeur.
Heureusement les instruction test-and-set et compare-and-swap sont faites pour cela:
| Opération | X86 | ARM | | --- | --- | --- | --- | | Test-and-set | xchg | ldrex/strex | | Compare-and-swap | cmpxchg | ldrex/strex |
Il est important de noter qu'il n'est pas suffisant d'imaginer qu'il existe une instruction assembleur atomique pour une opération donnée. Prenons l'exemple de l'incrémentation d'un compteur:
static int counter = 0;
void increment() { counter++; }Le compilateur va probablement générer le code suivant:
increment():
add DWORD PTR counter[rip], 1
retNéanmoins, quelle est la garantie qu'il le fasse ainsi ? La réponse est qu'il n'y a aucune garantie. Dans le code for (int i = 0; i < 42; ++i) counter++; le compilateur pourrait très bien faire l'hypothèse d'optimisation que le code est exécuté par un seul thread et donc générer le code suivant: add DWORD PTR counter[rip], 42, ou counter = 42; ou même counter = 0; si le compilateur estime que le code est inutile.
Nous l'avons vu, plus haut, une section critique est une partie de code qui ne peut pas être exécutée de manière atomique sans moyens de protection externes.
Une section critique est donc une portion de code dans laquelle il doit être garanti qu'il n'y aura jamais plus d'un thread en même temps.
La protection se fait au moyen de primitives de synchronisation tels qu'un mutex ou un sémaphore.
Il est important de noter que puisqu'une section critique n'est pas parallélisable, il est important de la rendre aussi petite que possible sinon elle deviendrait un goulot d'étranglement impactant les performances de tout le programme.
La réentrance est la propriété d'un code qui peut être appelé par plusieurs threads en même temps sans risque d'interblocage. De manière générale un code réentrant ne doit pas utiliser de variables globales ou statiques. L'exemple d'un générateur congruentiel linéaire est un bon exemple de code réentrant:
uint32_t lcg(uint32_t seed) {
static uint32_t state = seed;
state = 1664525 * state + 1013904223;
return state;
}La variable statique state est partagée entre tous les appels de la fonction. Si deux threads appellent la fonction en même temps, le résultat sera incohérent.
Certains langage de programmation tel que Java ou C# ont introduit le mot clé synchronized pour définir des méthodes réentrantes. C'est un concept qui a été introduit avec le langage Ada en 1983 et qui a été repris par Java en 1995. Voici l'exemple ci-dessus en Ada:
function lcg(seed: uint32_t) return uint32_t is
state: uint32_t := seed;
begin
state := 1664525 * state + 1013904223;
return state;
end;Le bloc begin ... end est réentrant par défaut. Il est possible de le rendre non réentrant en utilisant le mot clé protected:
Plutôt que de réentrance on parle plus volontiers de thread safety.
Un code thread safe est un code qui peut être appelé par plusieurs threads en même temps sans risque d'interblocage. Beaucoup de fonctions de la bibliothèque standard C sont thread safe. Par exemple, la fonction strlen est thread safe car elle ne modifie pas de variables globales ou statiques. Par contre, la fonction strtok n'est pas thread safe car elle modifie une variable statique interne. Il est fondamental de comprendre que la thread safety est une propriété du code et non pas des données. Une variable globale peut être thread safe si elle est protégée par un mutex.
Pour savoir si une fonction est thread safe, on peut voir dans le manuel:
$ man strtok | grep -A 9 'ATTRIBUTES'
ATTRIBUTES
For an explanation of the terms used in this section, see attributes(7).
┌───────────┬───────────────┬───────────────────────┐
│Interface │ Attribute │ Value │
├───────────┼───────────────┼───────────────────────┤
│strtok() │ Thread safety │ MT-Unsafe race:strtok │
├───────────┼───────────────┼───────────────────────┤
│strtok_r() │ Thread safety │ MT-Safe │
└───────────┴───────────────┴───────────────────────┘La fonction strtok n'est pas thread safe car elle n'est pas protégée par un mutex. Par contre, la fonction strtok_r est thread safe car elle est protégée par un mutex. Il va de même avec d'autres fonctions de la bibliothèque standard C comme strtok_r, strerror_r, rand_r, etc.
Un mutex (Mutual exclusion) est un mécanisme de synchronisation qui permet à un thread d'attendre qu'un autre thread produise un résultat. Les mutex sont généralement utilisés pour communiquer entre les threads et pour partager des données entre les threads.
L'algorithme de Peterson est un algorithme de synchronisation pour deux threads. Il est utilisé pour résoudre le problème de la section critique et la course aux ressources partagées dans les environnements multithread. L'algorithme de Peterson est l'un des plus anciens algorithmes de synchronisation pour les threads. Il a été inventé par Gary L. Peterson en 1981. Il est garanti d'être libre d'interblocage et de famine.
Soit un ensemble de deux threads, P0 et P1, qui partagent une variable booléenne flag et un tableau d'entiers turn. L'algorithme de Peterson est implémenté comme suit:
#include <atomic>
class PetersonMutex {
std::atomic<bool> flag[2]; // Want to enter in critical section?
std::atomic<int> turn; // Whose turn is it?
public:
PetersonMutex() {
// Initially no thread is interested in critical section
flag[0].store(false);
flag[1].store(false);
// P0's turn to enter in critical section
turn.store(0);
}
void lock(int thread) {
flag[thread].store(true);
turn.store(1 - thread);
while (flag[1 - thread].load() && turn.load() == 1 - thread)
{}
}
void unlock(int thread) {
flag[thread].store(false);
}
};
L'algorithme de Dekker est un algorithme de synchronisation pour deux threads. Il a été inventé par Edsger W. Dijkstra en 1965. Il est garanti d'être libre d'interblocage et de famine.
A la différence de l'algorithme de Peterson, l'algorithme de Dekker ne nécessite pas de variables atomiques. Il est implémenté comme suit:
class DekkerMutex {
bool flag[2]; // Want to enter in critical section?
int turn; // Whose turn is it?
public:
DekkerMutex() {
// Initially no thread is interested in critical section
flag[0] = false;
flag[1] = false;
// P0's turn to enter in critical section
turn = 0;
}
void lock(int thread) {
flag[thread] = true;
while (flag[1 - thread] && turn == 1 - thread)
{}
}
void unlock(int thread) {
flag[thread] = false;
}
};Il a l'avantage d'être simple mais il a l'inconvénient d'avoir une attente active (busy waiting) qui est une perte de temps CPU.
Si on compare

Un sémaphore est un mécanisme de synchronisation qui permet à un thread d'attendre qu'un autre thread produise un résultat. Les sémaphores sont généralement utilisés pour communiquer entre les threads et pour partager des données entre les threads.
Historiquement trois opérations sont prises en charge par un sémaphore:
P(SEM)(Proberen) : tester si le sémaphore est disponible, si oui, le prendre ;V(SEM)(Verhogen) : libérer le sémaphore ;Init(SEM, VAL)(Initialiser) : initialiser le sémaphore avec une valeur donnée.
On initialise un sémaphore qu'une seule fois à une valeur donnée. Cette valeur initialise un compteur interne. Lorsqu'un thread appelle P(SEM) le compteur est décrémenté. Si le compteur est négatif, le thread est mis en attente. Lorsqu'un thread appelle V(SEM) le compteur est incrémenté. Si le compteur est positif, le thread est réveillé. Pour ces raisons, il est courant dans la nomenclature du noyau Linux de parler de up et down au lieu de V et P.
#include <mutex>
#include <condition_variable>
class Semaphore {
std::mutex mutex;
std::condition_variable cv;
int count;
public:
Semaphore(int initial_count = 0) : count(initial_count) {}
void Init(int new_count) {
std::lock_guard<std::mutex> lock(mutex);
count = new_count;
cv.notify_all();
}
void P() {
std::unique_lock<std::mutex> lock(mutex);
cv.wait(lock, [this]() { return count > 0; });
--count;
}
void V() {
std::lock_guard<std::mutex> lock(mutex);
++count;
cv.notify_one();
}
};
Note: Les noms P et V viennent du néerlandais et signifient respectivement "proberen" (essayer) et "verhogen" (augmenter).. Dijkstra a choisi ces noms car il a écrit son premier article sur les sémaphores alors qu'il travaillait aux Pays-Bas.
Un spinlock est un mécanisme de synchronisation qui permet à un thread d'attendre qu'un autre thread produise un résultat. Les spinlocks sont généralement utilisés pour communiquer entre les threads et pour partager des données entre les threads.
Une barrière de synchronisation est un point de synchronisation qui bloque l'exécution des threads jusqu'à ce que tous les threads aient atteint la barrière. Une fois que tous les threads ont atteint la barrière, ils sont tous libérés en même temps. Les barrières de synchronisation sont généralement utilisées pour synchroniser les threads avant et après une section critique.
Pour réaliser une barrière de synchronisation, il faut utiliser un compteur et un mutex. Le compteur est incrémenté à chaque fois qu'un thread atteint la barrière. Lorsque le compteur atteint le nombre de threads, le mutex est libéré et tous les threads sont libérés en même temps.
Un moniteur est un mécanisme de synchronisation qui permet à un thread d'attendre qu'un autre thread produise un résultat. Les moniteurs sont généralement utilisés pour communiquer entre les threads et pour partager des données entre les threads.
Un moniteur est composé d'une section critique et d'une variable conditionnelle. La section critique est utilisée pour protéger les données partagées. La variable conditionnelle est utilisée pour attendre qu'un thread produise un résultat.
Les futures et les promesses sont des primitives de synchronisation qui permettent à un thread d'attendre qu'un autre thread produise un résultat. Les futures et les promesses sont généralement utilisés pour communiquer entre les threads et pour partager des données entre les threads.
#include <iostream>
#include <future>
#include <thread>
#include <chrono>
int snailTask(int x) {
std::this_thread::sleep_for(std::chrono::seconds(2));
return x * 2;
}
int slothTask(int y) {
std::this_thread::sleep_for(std::chrono::seconds(1));
return y + 3;
}
int main() {
std::future<int> result1 = std::async(std::launch::async, longRunningTask, 5);
int output1 = result1.get();
std::future<int> result2 = std::async(std::launch::async, slothTask, output1);
int output2 = result2.get();
std::cout << output2 << std::endl;
}Certains langage comme le JavaScript utilisent une syntaxe plus simple pour les futures et les promesses:
function snailTask(x) {
return new Promise(resolve => {
setTimeout(() => { resolve(x * 2); }, 2000);
});
}
function slothTask(y) {
return new Promise(resolve => {
setTimeout(() => { resolve(y + 3); }, 1000);de 1 seconde
});
}
snailTask(5)
.then(output1 => slothTask(output1))
.then(output2 => console.log(output2));L'étude des algorithmes de Dekker et Peterson est historiquement importante dans le domaine de la programmation concurrente, car ils sont parmi les premiers algorithmes développés pour résoudre le problème de la section critique et la course aux ressources partagées dans les environnements multithread. Cependant, leur utilisation dans la pratique moderne est relativement limitée, car ils présentent des limitations et des inconvénients importants par rapport aux solutions de synchronisation plus récentes.
Il peut être utile d'introduire brièvement Dekker et Peterson pour donner aux étudiants une compréhension historique de la programmation concurrente et des concepts de base de la synchronisation. Cela peut également aider à expliquer pourquoi des solutions plus modernes et efficaces ont été développées par la suite.
Cependant, il est important de noter que Dekker et Peterson sont des algorithmes relativement simples et ne sont généralement pas utilisés dans des applications réelles en raison de leurs limitations. Les étudiants peuvent bénéficier davantage de l'apprentissage des concepts et des techniques de synchronisation plus modernes et robustes, tels que l'utilisation de mutex, de sémaphores, de variables conditionnelles, etc.
Dans l'ensemble, il est utile d'inclure Dekker et Peterson dans le contexte de l'histoire de la programmation concurrente, mais cela ne devrait pas être le point central de votre cours. Concentrez-vous davantage sur les techniques de synchronisation actuelles et les meilleures pratiques pour gérer la concurrence de manière efficace et sûre dans les applications modernes.
- QThread (Qt Bien pas bien?)
- Pthreads (POSIX Threads) est une bibliothèque de threads standard pour les systèmes d'exploitation de type Unix. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows (via Cygwin).
- OpenMP est une API de programmation parallèle pour les langages C, C++ et Fortran. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows (via Cygwin).
- thread est une bibliothèque de threads standard pour C++11 et les versions ultérieures. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows.
- std::jthread est une bibliothèque de threads standard pour C++20 et les versions ultérieures. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows.
- std::async est une bibliothèque de threads standard pour C++11 et les versions ultérieures. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows.
- std::future est une bibliothèque de threads standard pour C++11 et les versions ultérieures. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows.
- std::promise est une bibliothèque de threads standard pour C++11 et les versions ultérieures. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows.
- std::latch est une bibliothèque de threads standard pour C++20 et les versions ultérieures. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows.
- std::barrier est une bibliothèque de threads standard pour C++20 et les versions ultérieures. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows.
- std::coroutine est une bibliothèque de threads standard pour C++20 et les versions ultérieures. Il est disponible sur la plupart des systèmes d'exploitation modernes, y compris Linux, macOS et Windows.
- Tentative de protection d'un compteur
- Un nombre est-il premier ou non?
- Gestion d'un téléphone
- Gestion de locomotives sur une maquette de train
- Covoiturage
- Pool the threads pour répartition des tâches
- Ordonnanceur de programme multi-threadé
Un facteur important à prendre en compte est le nombre de hardware threads disponibles sur la machine. Par exemple, si la machine dispose de 4 threads, il est inutile de créer plus de 4 threads, car cela ne fera qu'augmenter les coûts de commutation de contexte et de synchronisation. En général, il est préférable de créer un nombre de threads égal au nombre de threads matériels disponibles sur la machine.
| Name | Description |
|---|---|
| std::thread | représente un thread d'exécution. |
| std::jthread | représente un thread d'exécution avec un gestionnaire de durée de vie. |
| Name | Description |
|---|---|
| std::this_thread::get_id | obtient l'identifiant du thread appelant. |
| std::this_thread::sleep_for | bloque l'exécution du thread appelant pendant au moins la durée spécifiée. |
| std::this_thread::sleep_until | bloque l'exécution du thread appelant jusqu'à ce que le moment spécifié soit atteint. |
| std::this_thread::yield | conseille au planificateur d'ordonnancement de donner la priorité à l'exécution d'un autre thread. |
La notion cache sharing signifie que les caches de plusieurs processeurs peuvent contenir des copies de la même adresse mémoire. Lorsqu'un processeur modifie une adresse mémoire, il doit s'assurer que les autres processeurs ne conservent pas de copies obsolètes de cette adresse mémoire. Cela peut être réalisé en utilisant des protocoles de cohérence de cache, tels que le protocole MSI (Modified/Shared/Invalid).
Prévenir le false sharing c'est éviter que deux threads accèdent à des données qui se trouvent dans la même ligne de cache. Cela peut être réalisé en utilisant des techniques de padding, de partitionnement de données, etc.
Encourager le true sharing c'est encourager les threads à accéder à des données qui se trouvent dans la même ligne de cache. Cela peut être réalisé en utilisant des techniques de partitionnement de données, de placement de données, etc.
Ce que l'on définit par atomicité c'est le fait qu'une opération ne peut pas être interrompue par une autre opération. Cela signifie que l'opération doit être complètement terminée ou pas du tout. Les opérations atomiques sont généralement implémentées en utilisant des instructions de verrouillage matérielles, telles que les instructions CMPXCHG (x86) ou LDREX/STREX (ARM).
Utiliser std::atomic<Foo> au lieu de Foo pour les types de données partagés. Cela garantit que les opérations sur les données partagées sont atomiques et que les données sont correctement synchronisées entre les threads.
En bas niveau, on peut montrer que http://www.intel.com/Assets/PDF/manual/253668.pdf §8.1.1:
8.1.1 Guaranteed Atomic Operations
The Intel486 processor (and newer processors since) guarantees that the following basic memory operations will always be carried out atomically:
Reading or writing a byte Reading or writing a word aligned on a 16-bit boundary Reading or writing a doubleword aligned on a 32-bit boundary The Pentium processor (and newer processors since) guarantees that the following additional memory operations will always be carried out atomically:
Reading or writing a quadword aligned on a 64-bit boundary 16-bit accesses to uncached memory locations that fit within a 32-bit data bus The P6 family processors (and newer processors since) guarantee that the following additional memory operation will always be carried out atomically:
Unaligned 16-, 32-, and 64-bit accesses to cached memory that fit within a cache line
#include <iostream>
int64_t sharedValue;
void storeValue()
{
sharedValue = 0x100000002;
}// X86-64 GCC 10.2
sharedValue:
.zero 8
storeValue():
push rbp
mov rbp, rsp
movabs rax, 4294967298
mov QWORD PTR sharedValue[rip], rax // Instruction atomique
nop
pop rbp
ret// Arm GCC 32 bits
storeValue():
movw r3, #:lower16:.LANCHOR0 // Si interrompu après cette instruction, la valeur sera 0x00000002
movt r3, #:upper16:.LANCHOR0
movs r0, #2
movs r1, #1
strd r0, [r3]
bx lr
sharedValue:
.space 8#include <iostream>
#include <thread>
#include <atomic>
struct Foo {
int value = 0;
void increment() { value++; }
};
int main() {
std::atomic<Foo> foo;
std::jthread t1([&foo]() {
for (int i = 0; i < 100000; ++i) {
foo.increment();
}
});
std::jthread t2([&foo]() {
for (int i = 0; i < 100000; ++i) {
foo.increment();
}
});
t1.join();
t2.join();
std::cout << "Final value: " << foo.value.load() << std::endl;
return 0;
}
PcoThread : Permet d'instrumenter le code pour les tests et faire des interactions graphiques.
- ISBN 978-0-12-415950-1 The Art of Multiprocessor Programming, Revised Reprint
- Concurrent Programming: Algorithms, Principles, and Foundations
- https://www.karlrupp.net/2018/02/42-years-of-microprocessor-trend-data/