This is an attempt at implementing Sequence to Sequence Learning with Neural Networks (seq2seq) and reproducing the results in A Neural Conversational Model (aka the Google chatbot).
The Google chatbot paper became famous after cleverly answering a few philosophical questions, such as:
Human: What is the purpose of living?
Machine: To live forever.
The model is based on two LSTM layers. One for encoding the input sentence into a "thought vector", and another for decoding that vector into a response. This model is called Sequence-to-sequence or seq2seq.
Source: http://googleresearch.blogspot.ca/2015/11/computer-respond-to-this-email.html
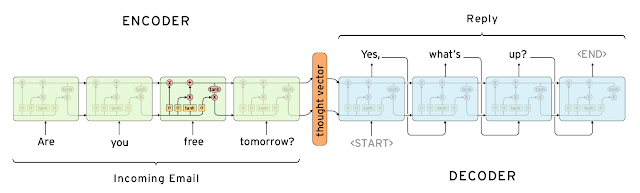
In this experiment, we train the seq2seq model with movie dialogs from the Cornell Movie-Dialogs Corpus. The lines are shortened to the first sentence.
Here's a sample conversation after training for 10 epoch with only 5000 examples, using the following command:
th train.lua --cuda --dataset 5000 --hiddenSize 1000me: Hi
bot: Hey.me: What's your name?
bot: Pris.me: How old are you?
bot: Thirty five eleven.me: What's 2 + 2?
bot: Nothing.me: That's funny.
bot: No.me: Where are you from?
bot: Helsinki, there!me: That's a nice place.
bot: Yes.me: How long have you been living in Helsinki?
bot: Thirty years.me: Talk to you later.
bot: What?me: I'm leaving.
bot: Leaving what?me: Leaving this conversation.
bot: Yes.
(Disclaimer: nonsensical responses have been removed.)
The results are fun but far less impressive than in the paper. This is probably because of the extremely small dataset and small network I used.
Sadly, my graphic card doesn't have enough memory to train larger networks.
If you manage to run it on a larger network do let me know!
-
Install the following additional Lua libs:
luarocks install nn luarocks install rnn luarocks install penlight
To train with CUDA install the latest CUDA drivers, toolkit and run:
luarocks install cutorch luarocks install cunn
-
Download the Cornell Movie-Dialogs Corpus and extract all the files into data/cornell_movie_dialogs.
th train.lua [-h / options]Use the --dataset NUMBER option to control the size of the dataset. Training on the full dataset takes about 5h for a single epoch.
The model will be saved to data/model.t7 after each epoch if it has improved (error decreased).
To load the model and have a conversation:
th -i eval.lua
# ...
th> say "Hello."Copyright Marc-Andre Cournoyer [email protected].
Thanks to rnn, Torch, The Unreasonable Effectiveness of Recurrent Neural Networks, Understanding LSTM Networks, TensorFlow seq2seq tutorial, Computer, respond to this email - Google Research Blog and papers mentioned above.