A PyTorch 0.4 implementation of DenseNets, optimized to save GPU memory.
- Now works on PyTorch 0.4! It uses the checkpointing feature, which makes this code WAY more efficient!!!
- No longer works with PyTorch 0.3.x. If you are using an old version of PyTorch, check out the pytorch_0.3.1 tag for an older version of this code.
models/densenet_efficient.pyis now depricated.models/densenet.pycan handle both the efficient and original implementations.
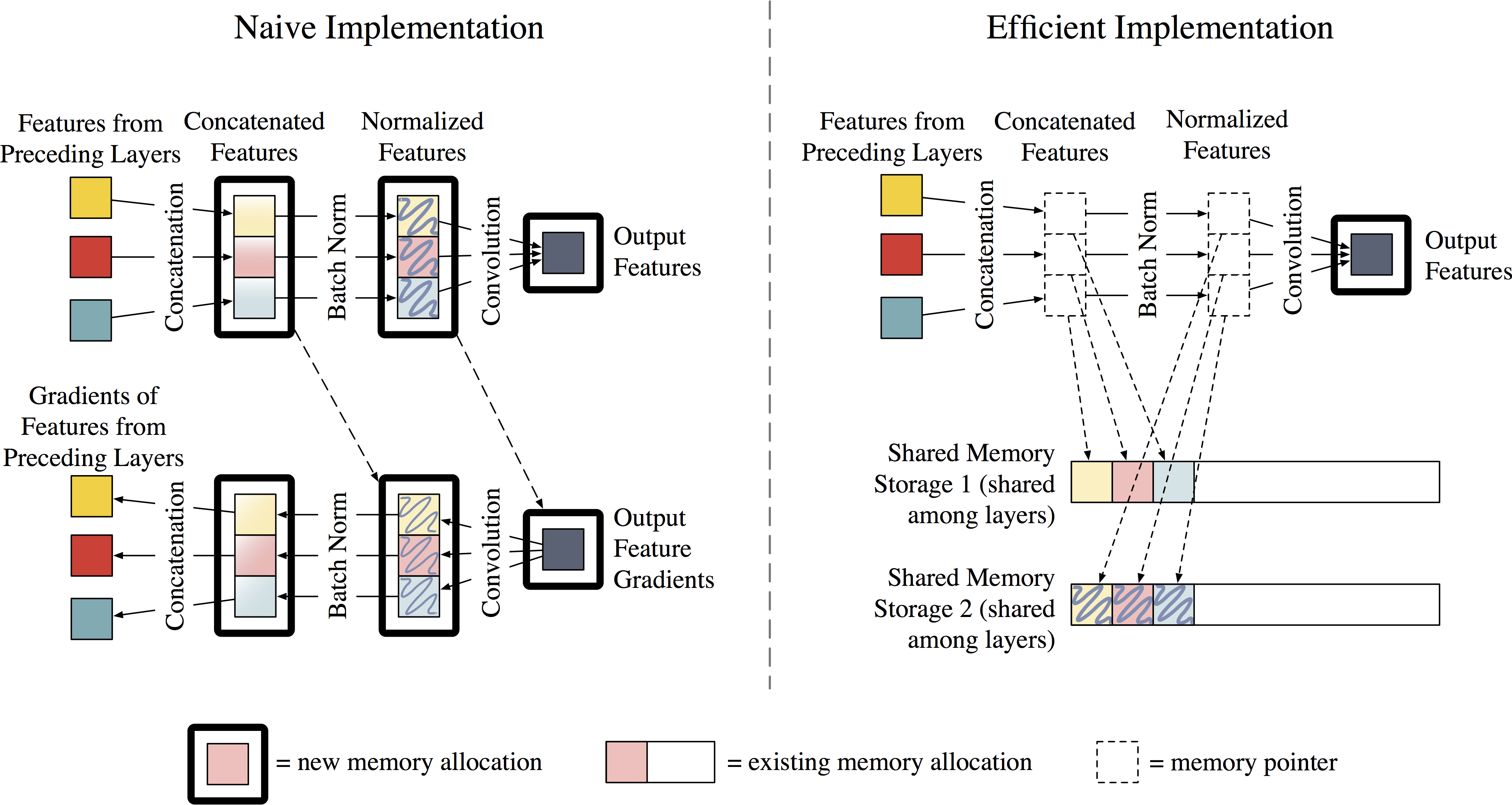
While DenseNets are fairly easy to implement in deep learning frameworks, most implmementations (such as the original) tend to be memory-hungry. In particular, the number of intermediate feature maps generated by batch normalization and concatenation operations grows quadratically with network depth. It is worth emphasizing that this is not a property inherent to DenseNets, but rather to the implementation.
This implementation uses a new strategy to reduce the memory consumption of DenseNets. We assign all intermediate feature maps to two shared memory allocations, which are utilized by every Batch Norm and concatenation operation. Because the data in these allocations are temporary, we re-populate the outputs during back-propagation. This adds 15-20% of time overhead for training, but reduces feature map consumption from quadratic to linear.
For more details, please see the technical report.
- PyTorch 0.4
- CUDA
N.B. If you are using PyTorch 0.3.x, please check out the 0.3.x compatible version.
In your existing project:
There is one file in the models folder.
models/densenet.pyis an implementation based off the torchvision and project killer implementations.
If you care about speed, and memory is not an option, pass the efficient=False argument into the DenseNet constructor.
Otherwise, pass in efficient=True.
Options:
- All options are described in the docstrings of the model files
- The depth is controlled by
block_configoption efficient=Trueuses the memory-efficient version- If you want to use the model for ImageNet, set
small_inputs=False. For CIFAR or SVHN, setsmall_inputs=True.
Running the demo:
The only extra package you need to install is python-fire:
pip install fire- Single GPU:
CUDA_VISIBLE_DEVICES=0 python demo.py --efficient True --data <path_to_folder_with_cifar10> --save <path_to_save_dir>- Multiple GPU:
CUDA_VISIBLE_DEVICES=0,1,2 python demo.py --efficient True --data <path_to_folder_with_cifar10> --save <path_to_save_dir>Options:
--depth(int) - depth of the network (number of convolution layers) (default 40)--growth_rate(int) - number of features added per DenseNet layer (default 12)--n_epochs(int) - number of epochs for training (default 300)--batch_size(int) - size of minibatch (default 256)--seed(int) - manually set the random seed (default None)
A comparison of the two implementations (each is a DenseNet-BC with 100 layers, batch size 64, tested on a NVIDIA Pascal Titan-X):
| Implementation | Memory cosumption (GB/GPU) | Speed (sec/mini batch) |
|---|---|---|
| Naive | 2.863 | 0.165 |
| Efficient | 1.605 | 0.207 |
| Efficient (multi-GPU) | 0.985 | - |
- LuaTorch (by Gao Huang)
- Tensorflow (by Joe Yearsley)
- MxNet (by Danlu Chen)
- Caffe (by Tongcheng Li)
@article{pleiss2017memory,
title={Memory-Efficient Implementation of DenseNets},
author={Pleiss, Geoff and Chen, Danlu and Huang, Gao and Li, Tongcheng and van der Maaten, Laurens and Weinberger, Kilian Q},
journal={arXiv preprint arXiv:1707.06990},
year={2017}
}