WriteAlgorithms.md
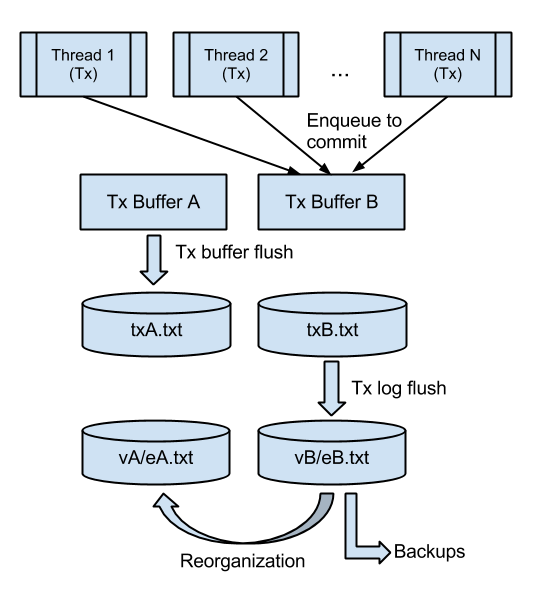
Bitsy is a durable in-memory database. The vertices and edges in the graph are maintained in various Java Map data structures. Changes made to the database are logged to files. These files are routinely compacted and re-organized to remove obsolete information. The rest of this section describes the various algorithms involved in writing transactions to files. The following illustration describes the various buffers and processes.
A transactional context is tied to every thread that operates on Bitsy. When the vertices and edges are queried in a transaction, the elements are copied to the transaction context along with the version number.
When a transaction is committed, the database performs the following steps:
- Serialize all updated vertices and edges using the [Jackson JSON processor], after incrementing the version number
- Grab an exclusive lock on the graph
- Check to see if all updated vertices and edges have the same version number at time of the commit operation
- Apply the changes to the in-memory database
- Release the exclusive lock on the graph
- Enqueue the transaction details to a transaction buffer
- Wait till the transaction buffer is flushed to the file
The commit algorithm tries to minimize the time for which the exclusive write lock is held. It also ensures that the method does not return till the commits are written (and forced) to disk.
There are two transaction buffers (A/B) which are in-memory queue implementations. One of them is the enqueue buffer to which transaction details are enqueued. The other buffer is called the flush buffer.
A transaction-buffer flusher thread, named MemToTxLogWriter-, runs in the background performing the following steps in an infinite loop:
- Wait till the enqueue buffer has more than one transaction
- Swap the enqueue/flush buffers (A -> B or B -> A)
- Pick up transactions from the flush buffer and write them to a transaction log (see next section)
- Force the updates to disk
- Notify all the processed transactions (see step 7 in the previous section)
The idea behind the dual queue system is to:
- avoid the file write operations from blocking the transaction commit operations,
- reduce rotational latency by writing as much as possible at once and then forcing the updates to disk, and
- maximize the throughput when there are a lot of queued-up transactions.
The write throughput in the benchmarks page shows the decreasing impact of rotational latency as the number of concurrently writing threads increases.
The transaction logs are organized in a similar fashion to the transaction buffers. There are two files (txA.txt and txB.txt). One of them is the enqueue log and the other one is flush log.
When the enqueue transaction log exceeds the transaction log threshold (configurable with a default of 4MB), the transaction-log flusher thread, named TxFlusher-, wakes up and performs the following steps:
- Swap the enqueue/flush transaction logs: This is not a file rename operation. It simply instructs the transaction-log flusher to use the other log file.
- Read records from the flush transaction log and write the up-to-date vertices and edges to the vertex and edge logs. The obsolete vertices and edges are ignored.
The vertex and edge logs are organized in a similar fashion to the transaction logs. There are two sets of vertex and edge files, named vA.txt and vB.txt, and eA.txt and eB.txt. One of the sets of logs is the enqueue logs to which the transaction logs are flushed.
When the total number of vertices and edges in the vertex/edge logs exceeds the previously known size (say N) by the reorganization factor times N, a thread named the VEReorg- wakes up and performs the following steps:
- Block all further transaction log flushes
- Read all vertices from the enqueue vertex log and write the up-to-date records to the flush vertex log
- Perform a similar copy operation on the edge logs
- Delete the old enqueue logs
- Swap the enqueue/flush status of the V/E logs so that future transaction log flushes will go to the correct file
Unlike the previous two dual-queue systems, a re-organization of the vertex and edge logs will block flushes from the transaction logs. However, this doesn't adversely affect performance as long as the file operations catch up with the updates
When an online backup operation is triggered through the JMX console, the database performs the following steps:
- Trigger a transaction flush and wait for it to complete
- Copy the "enqueue" vertex and edge logs to the given backup directory
This algorithm ensures that a valid snapshot of the database is copied to the given backup directory. All transaction log flush operations will wait till step 2 is complete. To restore the database, you simply have to delete the contents of the database directory and overwrite it with the contents of the backup directory.