The code is structured as a set of scripts. The following diagram captures the dependency structure of the scripts (the following script depends on the output of the previous script):
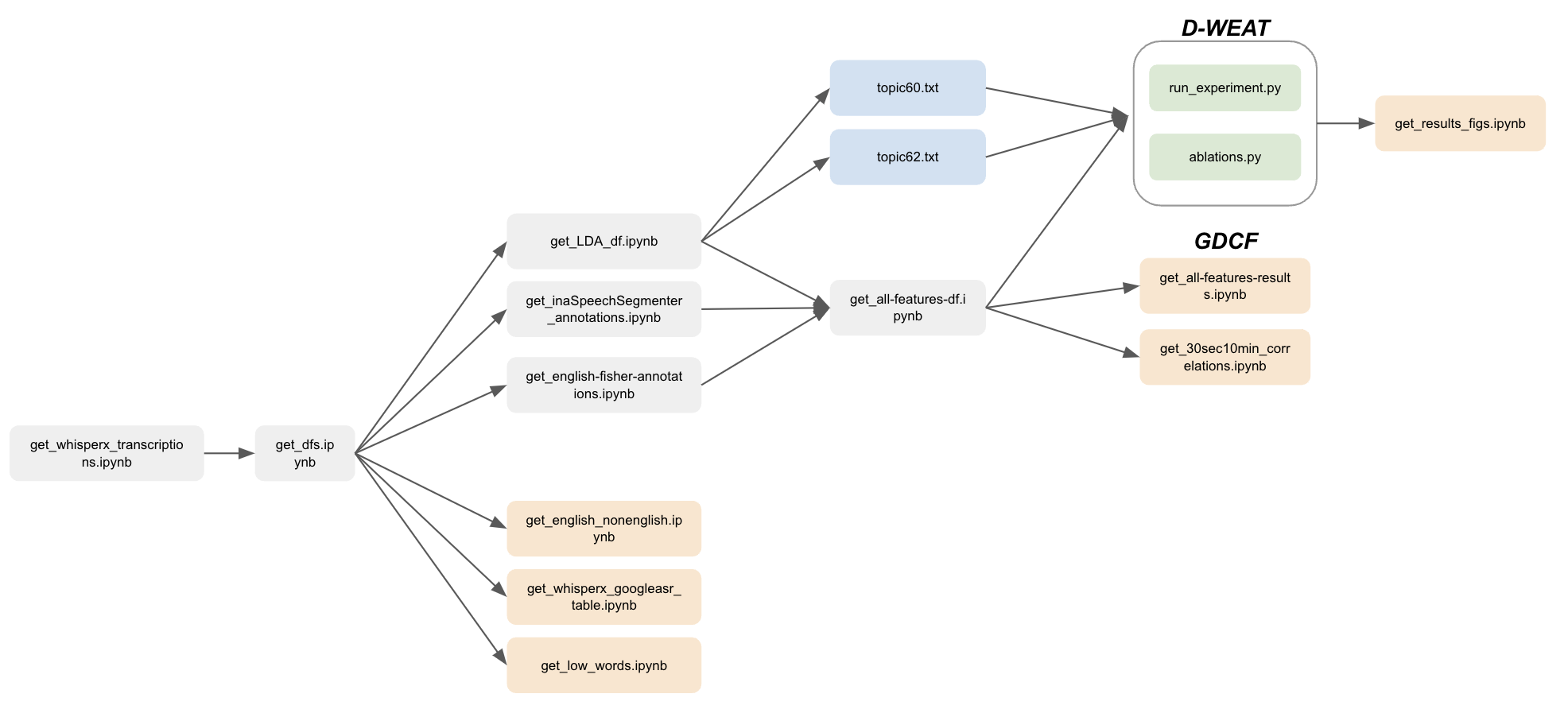
For D-WEAT: The results were plotted in get_results_figs.ipynb. For GDCF: The final csvs from get_all-features-results.ipynb were imported into Google Sheets, and analyzed there.
Link: https://github.com/ina-foss/inaSpeechSegmenter
Link: https://github.com/pariajm/english-fisher-annotations
We had to modify this code, so we provide the code here as a subdirectory.
Link: https://podcastsdataset.byspotify.com/
This dataset is maintained by Spotify, and access to the dataset is determined by Spotify.