Fluke
Note: this is largely irrelevant now, use as ideas for structuring Memory.md and API.md
Our work hinges on two primary properties of such systems: state encapsulation and border control.
The property of state encapsulation is the ability to encapsulate or “nest” one process inside another so that the entire state of a child process and all its descendants is logically a subset of the state of the parent process. This property allows the parent process to treat an entire child process hierarchy as merely a chunk of data that can be moved, copied, deleted, etc., while remaining oblivious to the implementation details of the child. Of primary interest are the following three specific aspects of this property: hierarchical resource management, state visibility, and reference relativity.
- HRM: Some operating systems, such as L3 [39], directly support a hierarchical virtual machine-like process model in which a parent process can destroy a child process and be assured that all of the child’s descendants will also go away and their resources will be freed. Other systems support a hierarchical resource pool abstraction from which the resources used to create processes are allocated; destroying a pool destroys any sub-pools created from it as well as all processes created from these pools. For example, KeyKOS space banks [6, 27] serve this purpose, as do ledgers in OSF’s MK++ [43]. This hierarchical resource management property is a critical prerequisite for many of the applications described in this paper; without it, a parent process cannot even identify all of the state representing a child process subtree, let alone manage it coherently.
- State visibility: the ability of a parent process to “get at” the state of a child process subtree rather than merely having control over its lifetime. State visibility is needed by any application that manages child process state, such as demand paging, debugging, checkpointing, process migration, replication, and DSM. Pure virtual machine simulators obviously satisfy this property since all of the state of a virtual machine is merely part of the simulator’s variables. Same-architecture hypervisors that “delegate” to the base processor the job of executing unprivileged instructions depend on the processor to reveal the child’s full register state through trap frames or shadow registers. With notable exceptions such as the Cache Kernel [14] and Amoeba [47], most operating systems are not as good about making a child process’s state visible to its parent. For example, although most kernels at least allow a process to manipulate a child’s user-mode register state (e.g., Unix’s ptrace() facility), other important state is often unavailable, such as the implicit kernel state representing outstanding long-running system calls the child may be engaged in. While these facilities are sufficient for many applications such as debugging, other applications such as process migration and checkpointing require access to all of the child’s state.
- Reference relativity: While full state visibility is a necessary condition to move or copy a child process, it is also necessary that its references are relative to its own scope and are not absolute references into larger scopes such as the machine or the world. A “reference” for this purpose is any piece of state in the child process that refers to some other piece of state or “object.” For example, virtual addresses, unique identifiers, and file descriptors are different forms of references. An internal reference is a reference in the child to some other object in the same process; an external reference is a reference to an object in an outer scope (e.g., in an ancestor or sibling process).""
Whereas the state encapsulation property allows the parent to control state inside the boundary, border control allows the parent to control the child’s view of the world outside the boundary.
The Fluke architecture is the common interface between each of the stackable layers in the system and consists of three components: the basic computational instruction set, the low-level system call API, and the IPC-based Common Protocols.
The key parts of Fluke (Nested Process) architecture:
-
Basic Computational Instruction Set (x86 or Java bytecode for example)
-
Low-level API (These primitives are always implemented by the microkernel directly; therefore it is critical that they be designed to support all of the virtualization properties in Section 3. The reward for carefully designing the low-level API in this way is that it is never necessary for a parent process to interpose on the kernel calls made by child processes; instead, it is always sufficient for the parent process merely to retain control over the resources to which the system calls refer.)
-
Address Spaces (Unlike most operating systems, address spaces in Fluke are defined relative to other spaces. The low-level API does not include system calls to allocate or free memory; it only provides primitives to remap a given virtual address range from one space into another space, possibly at a different virtual address range or with reduced permissions.) Similar to recursive address spaces in L4 - grant/map/demap fits this model.
-
Kernel objects (All low-level API calls are operations on a few types of primitive kernel objects, such as address spaces and threads. All active kernel objects are logically associated with, or “attached to,” a small chunk of physical memory; this is reminiscent of tagged processor architectures) A process can invoke kernel operations on kernel objects residing on pages mapped into its address space by specifying the virtual address of the object as a parameter to the appropriate system call. Since kernel objects are identified by local virtual addresses, this design satisfies the relativity property for user-mode references to kernel objects. In addition, there are system calls that a process can use to determine the location of all kernel objects within a given range of its own virtual address space, as well as system calls to examine and modify the state of these objects [51].
-
Thread Objects (Unlike in most systems, Fluke threads provide full state visibility: a parent process can stop and examine the state of the threads in a child process at any time, and be assured of promptly receiving all relevant child state; i.e., everything necessary to transplant the child nondestructively. One implication of this property, which affects the low-level API pervasively, is that all states in which a thread may have to wait for events caused by other processes must be explicitly representable in the saved-state structure the kernel provides to a process examining the thread.)
-
Scheduling (The final type of resource with which the Fluke kernel deals directly is CPU time. As with memory and communication, the kernel provides only minimal, completely relative scheduling facilities. Threads can act as schedulers for other threads, donating their CPU time to those threads according to some high-level scheduling policy; those threads can then further subdivide CPU time among still other threads, etc., forming a scheduling hierarchy. The scheduling hierarchy usually corresponds to the nested process hierarchy, but is not required to do so.) Prototype nesting scheduler not in Fluke yet - [21].
[21] B. Ford and S. Susarla. CPU Inheritance Scheduling. In Proc. of the Second Symp. on Operating Systems Design and Implementation, Seattle, WA, Oct. 1996. USENIX Assoc. [inherit-sched.pdf]
- High-level Protocols (Common Protocols) The most basic interface, the Parent interface, is used for direct parent/child communication, and effectively acts as a first-level “name service” interface through which the child requests access to other services. This is the only interface that all nesters interpose on; nesters selectively interpose on other interfaces only as necessary to perform their function. The cost of interposition on the Parent interface is minimal because the child usually makes only a few requests on this interface, during its initialization phase, to find other interfaces of interest.
[atomic-osdi99.pdf]
We have defined and implemented a kernel API that makes every exported operation fully interruptible and restartable, thereby appearing atomic to the user. To achieve interruptibility, all possible kernel states in which a thread may become blocked for a “long” time are represented as kernel system calls, without requiring the kernel to retain any unexposable internal state.
Execution model: process (one stack per thread) <---> interrupt (one stack per CPU, continuations)
API model: conventional <---> atomic
Supporting a purely atomic API slightly increases the width and complexity of the kernel interface but provides important benefits to user-level applications in terms of the power, flexibility, and predictability of system calls.
In addition, Fluke supports both the interrupt and process execution models through a build-time configuration option affecting only a small fraction of the source, enabling a comparison between them. Fluke demonstrates that the two models are not necessarily as different as they have been considered to be in the past; however, they each have strengths and weaknesses. Some processor architectures inherently favor the process model and process model kernels are easier to make fully preemptible. Although full preemptibility comes at a cost, this cost is associated with preemptibility, not with the process model itself. Process model kernels use more per-thread kernel memory, but this is unlikely to be a problem in practice except for power-constrained systems. We show that while an atomic API is beneficial, the kernel’s internal execution model is less important: an interrupt-based organization has a slight size advantage, whereas a process-based organization has somewhat more flexibility.
Finally, contrary to conventional wisdom, our kernel demonstrates that it is practical to use legacy process-model code even within interrupt-model kernels. The key is to run the legacy code in user mode but in the kernel’s address space.
Draves et. al. also identified the optimization of continuation recognition, which exploits explicit continuations to recognize the computation a suspended thread will perform when resumed, and do part or all of that work by mutating the thread’s state without transferring control to the suspended thread’s context. Though it was used to good effect within the kernel, user-mode code could not take advantage of this optimization technique because the continuation information was not available to the user. In Fluke, the continuation is explicit in the user-mode thread state, giving the user a full, well-defined picture of the thread’s state.
An atomic API provides four important and desirable properties: prompt and correct exportability of thread state, and full interruptibility and restartability of system calls and other kernel operations.
One natural implication of the Fluke API’s promptness and correctness requirements for thread control is that all system calls a thread may make must either appear completely atomic, or must be cleanly divisible into user-visible atomic stages.
Table 1 breaks the Fluke system call API into four categories, based on the potential length of each system call. “Trivial” system calls are those that will always run to completion without putting the thread to sleep. For example, Fluke’s thread_self (analogous to Unix’s getpid) will always fetch the current thread’s identifier without blocking. “Short” system calls usually run to completion immediately, but may encounter page faults or other exceptions during processing. If an exception happens then the system call will roll back and restart. “Long” system calls are those that can be expected to sleep for an extended period of time (e.g., waiting on a condition variable). “Multi-stage” system calls are those that can cause the calling thread to sleep indefinitely and can be interrupted at various intermediate points in the operation.
Table 1
| Type | Examples | Count | Percent |
|---|---|---|---|
| Trivial | thread_self | 8 | 7% |
| Short | mutex_trylock | 68 | 64% |
| Long | mutex_lock | 8 | 7% |
| Multi-stage | cond_wait, IPC | 23 | 22% |
| Total | 107 | 100% | |
| Intermediate | 5 |
The Fluke kernel directly supports nine primitive object types, listed in Table 2. All types support a common set of operations including create, destroy, “rename,” “point-a-reference-at,” “get objstate,” and “set objstate.” Obviously, each type also supports operations specific to its nature; for example, a Mutex supports lock and unlock operations (the complete API is documented in [15]). The majority of kernel operations are transparently restartable. For example, port reference, a “short” system call, takes a Port object and a Reference object and “points” the reference at the port. If either object is not currently mapped into memory, a page fault (In Fluke, kernel objects are mapped into the address space of an application with the virtual address serving as the “handle” and memory protections providing access control.) IPC will be generated by the kernel after which the reference extraction will be restarted. In all such cases page faults are generated very early in the system call, so little work is thrown away and redone.
Table 2: The primitive object types exported by the Fluke kernel.
| Object | Description |
|---|---|
| Mutex | A kernel-supported mutex which is safe for sharing between processes. |
| Cond | A kernel-supported condition variable. |
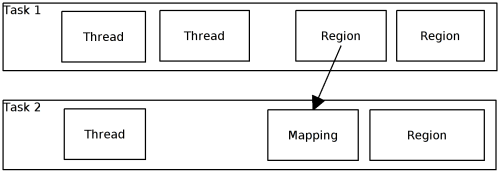
| Mapping | Encapsulates an imported region of memory; associated with a Space (destination) and Region (source). |
| Region | Encapsulates an exportable region of memory; associated with a Space. |
| Space | Associates memory and threads (task). |
| Thread | A thread of control, associated with a Space. |
| Port | Server-side endpoint of an IPC. |
| Portset | A set of Ports on which a server thread waits. |
| Reference | A cross-process handle on a Mapping, Region, Port, Thread or Space. Most often used as a handle on a Port that is used for initiating client-side IPC. |
More discussion of consequences of providing atomic API: [31] P. Tullmann, J. Lepreau, B. Ford, and M. Hibler. User-level Checkpointing Through Exportable Kernel State. In Proc. Fifth International Workshop on Object Orientation in Operating Systems, pages 85–88, Seattle, WA, Oct. 1996. IEEE. [iwooos96-flobs.pdf, iwooos96-slides.ps]
Full Fluke objects API description: [15] B. Ford, M. Hibler, and Flux Project Members. Fluke: Flexible mu-kernel Environment (draft documents). University of Utah. Postscript and HTML available under http://www.cs.utah.edu/projects/flux/fluke/, 1996. [not available]
[!] Preemptibility: It is easier to make a process-model kernel preemptible, regardless of the API it exports; however, it is easy to make interrupt-model kernels partly preemptible by adding preemption points. A fully-preemptible process-model kernel provides the lowest latency.
Table 4: Labels and characteristics for the different Fluke kernel configurations used in test results.
| Configuration | Description |
|---|---|
| Process NP | Process model with no kernel preemption. Requires no kernel-internal locking. Comparable to a uniprocessor Unix system. |
| Process PP | Process model with “partial” kernel preemption. A single explicit preemption point is added on the IPC data copy path, checked after every 8k of data is transferred. Requires no kernel locking. |
| Process FP | Process model with full kernel preemption. Requires blocking mutex locks for kernel locking. |
| Interrupt NP | Interrupt model with no kernel preemption. Requires no kernel locking. |
| Interrupt PP | Interrupt model with partial preemption. Uses the same IPC preemption point as in Process PP. Requires no kernel locking. |
However, real production systems may need larger stacks and also may want them to be a multiple of the page size in order to use a “red zone.”
The Fluke kernel uses a different approach, which keeps the “core” interrupt-model kernel simple and uncluttered while effectively supporting something almost equivalent to kernel threads. Basically, the idea is to run process-model “kernel” threads in user mode but in the kernel’s address space. In other words, these threads run in the processor’s unprivileged execution mode, and thus run on their own process-model user stacks separate from the kernel’s interrupt-model stack; however, the address translation hardware is set up so that while these threads are executing, their view of memory is effectively the same as it is for the “core” interrupt-model kernel itself. This design allows the core kernel to treat these process-level activities just like all other user-level activities running in separate address spaces, except that this particular address space is set up a bit differently.
==== From Fluke ====
General operations on a kernel object over the low-level API:
- create
- create with hash
- destroy
- move from one va to another
- create a reference
- get state
- set state
The Fluke kernel directly supports nine primitive object types, listed in Table 2. All types support a common set of operations including create, destroy, “rename,” “point-a-reference-at,” “get objstate,” and “set objstate.” Obviously, each type also supports operations specific to its nature; for example, a Mutex supports lock and unlock operations (the complete API is documented in ![15]). The majority of kernel operations are transparently restartable. For example, port reference, a “short” system call, takes a Port object and a Reference object and “points” the reference at the port. If either object is not currently mapped into memory, a page fault IPC will be generated by the kernel after which the reference extraction will be restarted. In all such cases page faults are generated very early in the system call, so little work is thrown away and redone.
Generic port-based IPC: [client: ipc_send_bla] --> client thread blocked --> [server portset] --> [server thread on port] --> [server thread serving request and sending ipc_ack to client] --> client thread woken up --> [client: receive ipc_reply]
Migrating threads based IPC: [client: ipc_request] --> client thread migrating to server PD --> client thread serving request --> client thread returning to client PD --> [client: receive results]