This repository represents the implementation of the paper:
Ye Hong, Yatao Zhang, Konrad Schindler, Martin Raubal
| MIE, ETH Zurich | FRS, Singapore-ETH Centre | PRS, ETH Zurich |
This code has been tested on
- Python 3.11, Geopandas 0.14.4, trackintel 1.3.1, PyTorch 2.3.1, cudatoolkit 11.8, transformers 4.41.2, GeForce RTX 3090 and GeForce RTX 4090
To create a virtual environment and install the required dependences please run:
git clone https://github.com/mie-lab/mobility_generation
cd mobility_generation
conda env create -f environment.yml
conda activate mobility_generation
pip install -e .
pip install -e improved-diffusionin your working terminal. The MobilityGen implementation is built on top of the improved-diffusion package by https://github.com/openai/improved-diffusion.
For projecting locations into s2grid, the s2geometry Python package needs to be build from source and available in the virtual environment. Check the installation guide in https://github.com/google/s2geometry.
The respective code files are stored in seperate modules:
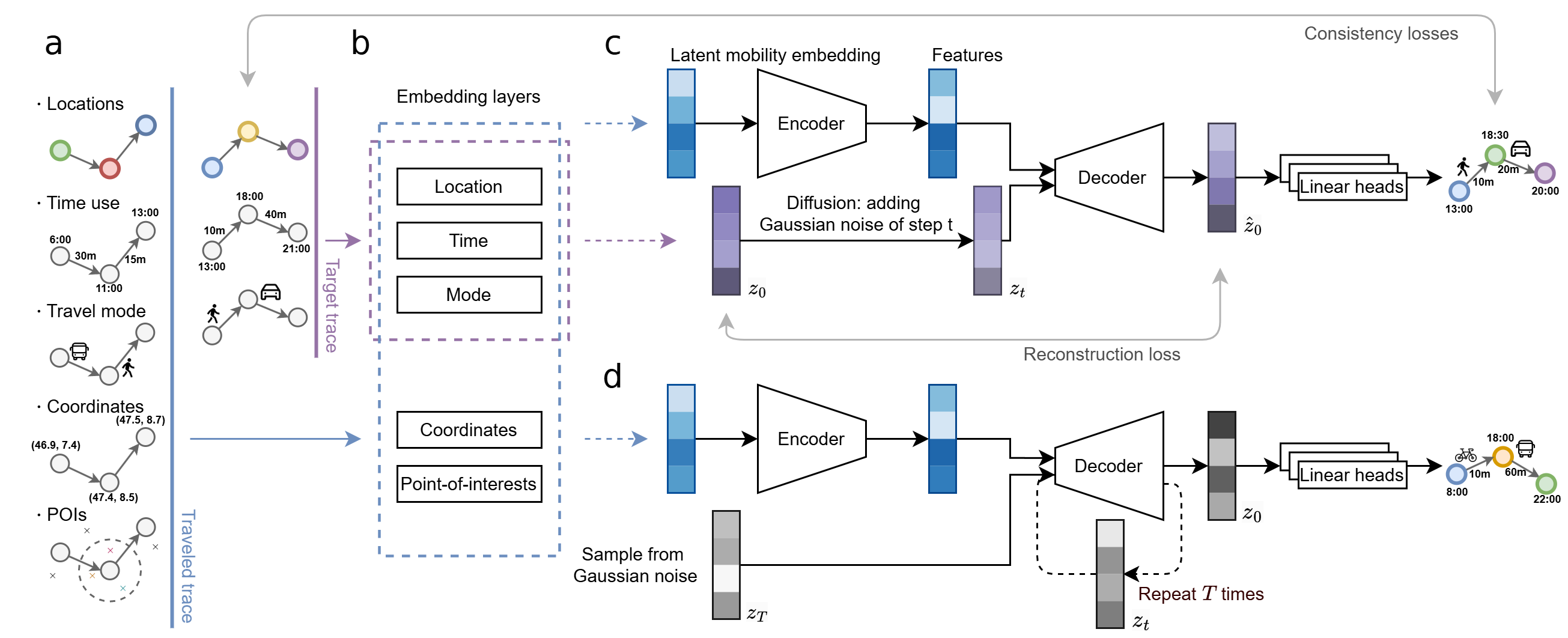
/preprocess/*. Functions that are used for preprocessing the dataset. Should be executed before training a model.01_project_s2.pyincludes functions to project locations into s2geometery locations (require the s2geometry library to be installed, seeRequirements and dependencies).02_poi.pyincludes POI preprocessing and embedding methods (LDA).10_geolife.pyand11_generate_data_geolife.pyinclude functions for preprocessing the raw Geolife dataset into formats that are acceptable by MobilityGen (SeeReproducing on the Geolife dataset)/diffusion/*. Implementation of MobilityGen model./config/*. Hyperparameter settings are saved in the.ymlfiles under the respective dataset folder underconfig/. For example,/config/diff_geolife.ymlcontains hyperparameter settings for the geolife dataset./utils/*. Helper functions that are used for model training./evaluate/*. Evaluation of the simulated sequences using MobilityGen.entropy.pyincludes functions to calculate the random, uncorrelated and real entropy.stats.pyincludes functions to calculate the mobility motifs.
The results in the paper are obtained from the MOBIS dataset that are not publicly available. We provide a runnable example of the pipeline on the Geolife dataset. The travel mode of the Geolife users are determined through the provided mode labels and using the trackintel function trackintel.analysis.predict_transport_mode. The steps to run the pipeline are as follows:
- Download the repo, install neccessary
Requirements and dependencies.
- Download the Geolife GPS tracking dataset from here. Unzip and copy the
Datafolder intodata/geolife/. The file structure should look likedata/geolife/Data/000/.... - Create file
paths.json, and define your working directories by writing:
{
"raw_geolife": "./data/geolife"
}- run
python preprocess\10_geolife.py --epsilon 20for obtaining the staypoints and location sequences for the geolife dataset. Note that the locations are directly generated from user tracking data, without the s2geometry projection. The process takes 15-30min. loc_geolife.csv and sp_geolife_all.csv will be created under data/ folder.
- run
python preprocess/11_generate_data_geolife.py --src_min_days 7 --src_max_days 21 --tgt_min_days 3 for obtaining the train, validation, and test staypoint sequences (source sequence and target sequences). Due to the data quality of OSM at the tracking period, we choose not to attached POIs to the locations. train_7_3_geolife.pk, valid_7_3_geolife.csv, and test_7_3_geolife.pk will be created under data/ folder.
- Configure the network parameters in
config/diff_geolife.yml, and run
python run_diff.py --config config/diff_geolife.ymlfor starting the training process.
- Alternatively, specify the number of GPUs with
nproc_per_nodefor training with Distributed Data Parallel:
python -m torch.distributed.launch --nproc_per_node=1 run_diff.py --config config/diff_geolife.ymlThe configuration of the current run, the network paramters and the log information will be stored under run/ folder.
With a trained model, new sequences can be obtained with the parameters defined in config/diff_sample_geolife.yml. In the config file, specify the path and name of the trained model, and run
python run_diff_sample.py --config config/diff_sample_geolife.ymlfor starting the simulation process. Simulated traces will be stored json format under run/ folder.
If you have any questions, please let me know:
- Ye Hong {[email protected]}