SolrWayback bundle release 5.1.2 can be downloaded here: https://github.com/netarchivesuite/solrwayback/releases/tag/5.1.2
The bundle is the recommended way to get started with SolrWayback. You download the bundle, follow the installation guide and index your own WARC files. Then you are up to speed.
SolrWayback is a web application for browsing historical harvested ARC/WARC files similar to the Internet Archive Wayback Machine. SolrWayback runs on a Solr server containing ARC/WARC files indexed using the warc-indexer.
SolrWayback comes with multiple features:
- Free text search in all resources (HTML pages, PDFs, metadata for different media types, URLs, etc.)
- Interactive link graph (ingoing/outgoing) for domains.
- Export of search results to a WARC file through streaming download, which means that there is no limit to the size of the resultset.
- Zip export of files from search result (e.g. export of HTML, image content, video etc. in native formats).
- CSV text export of search result with custom field selection.
- Wordcloud generation for domain.
- N-gram search visualisation.
- Visualisation of search result by domain.
- Visualisation of various domain statistics over time such as size, number of in- and outgoing links.
- Large scale export of link graphs in Gephi format. (See https://labs.statsbiblioteket.dk/linkgraph/)
- Image search similar to google images.
- Image geo search by location on map using EXIF metadata information in images.
- Search by upload of a file. (e.g., image, PDF) to see if the resource has been harvested and find HTML pages using the image.
- View all fields indexed for a resource and show warc-header for records.
- Configure alternative playback engine to any playback engine using the playback-API such as OpenWayback or pywb.
The National Széchényi Library of Hungary has kindly set up the following demo site for SolrWayback: https://webadmin.oszk.hu/solrwayback/
The International Internet Preservation Consortium (IIPC) has also made multiple of their collections available for browsing through SolrWayback. These collections can be found here: https://netpreserve.org/projects/collections-access/
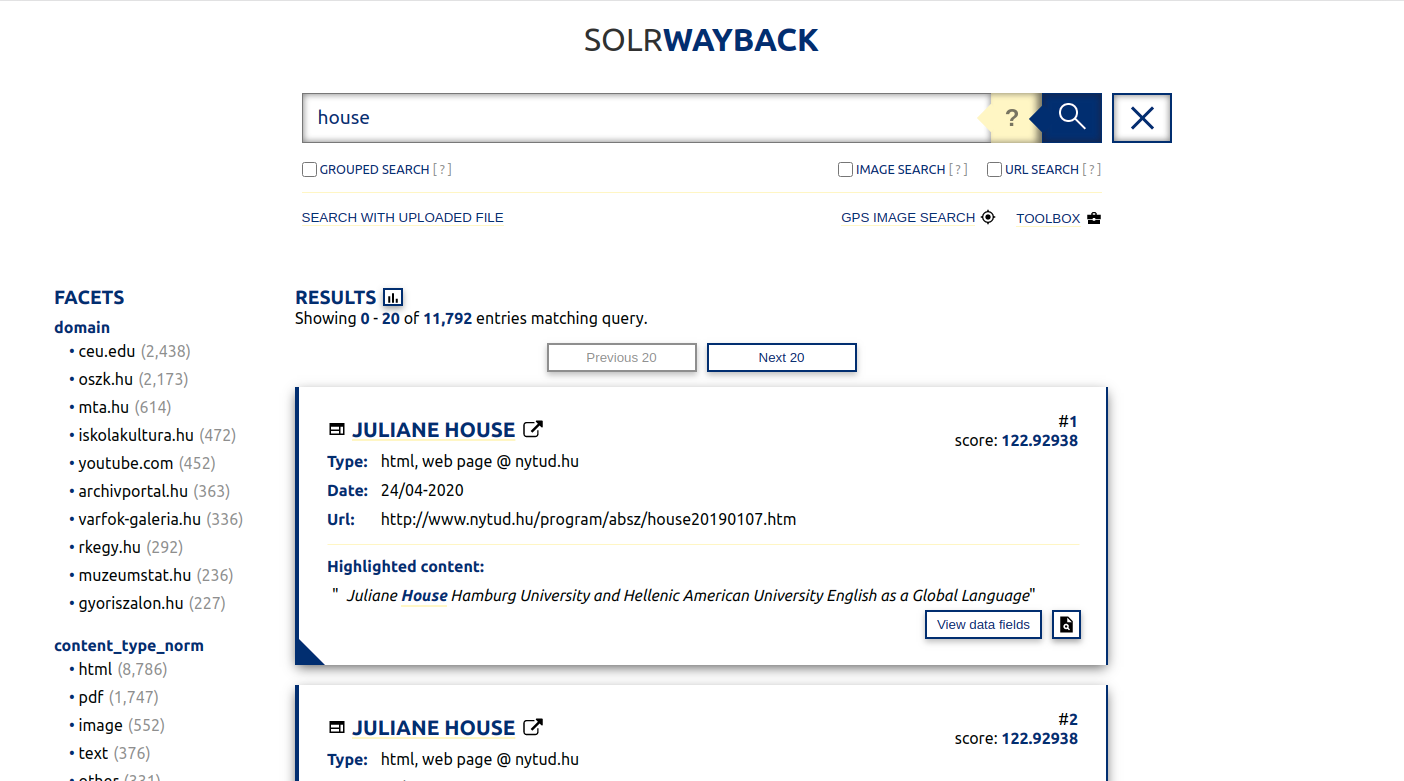
Lising of search results with facets.

Image search, show only images as results.
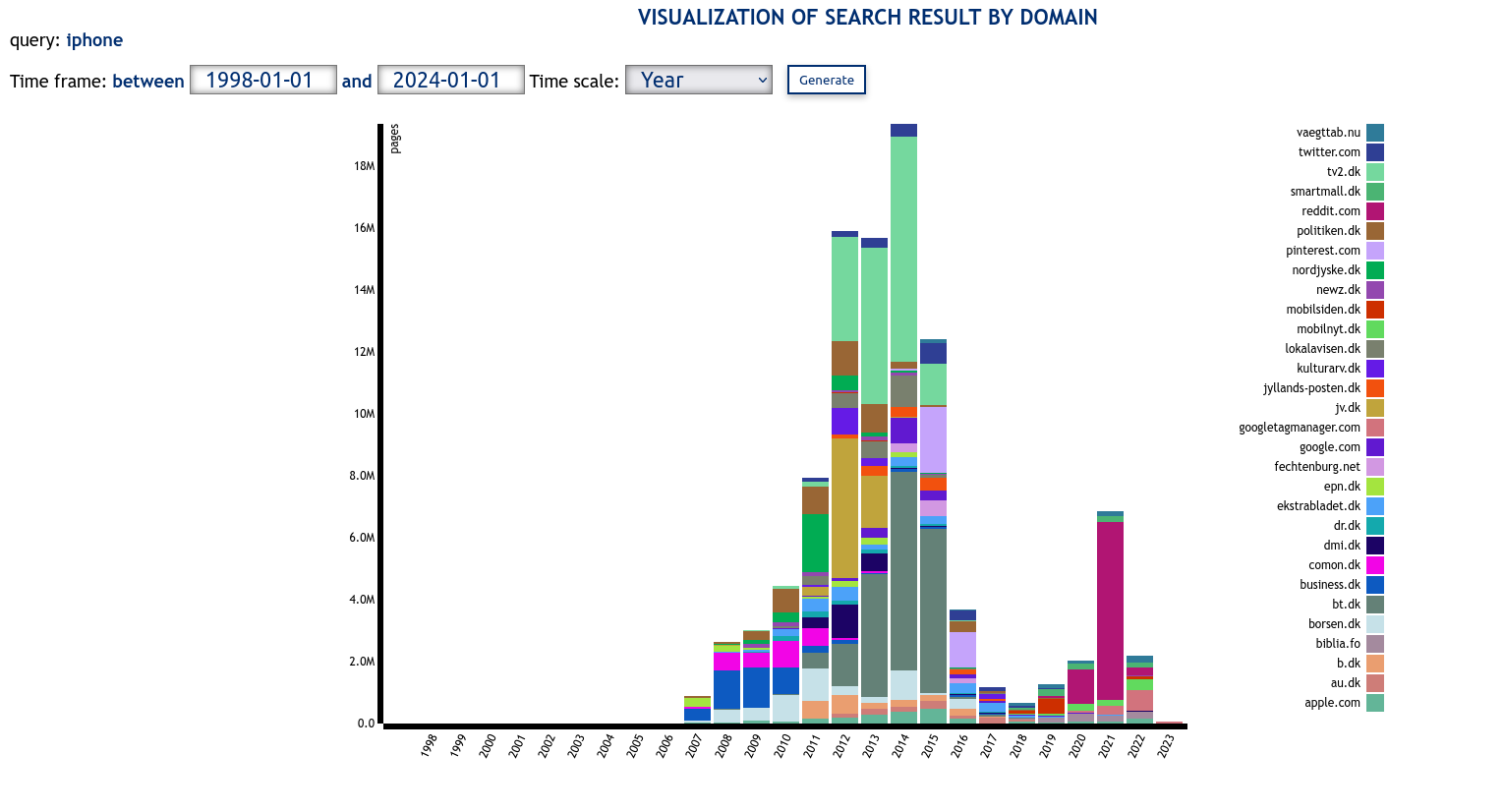
Visualization of results by domain over time.

Solrwayback showing the playback of an archived webpage with playback toolbox overlay.
gui

Interactive domain link graph

Github like visualization of crawltimes
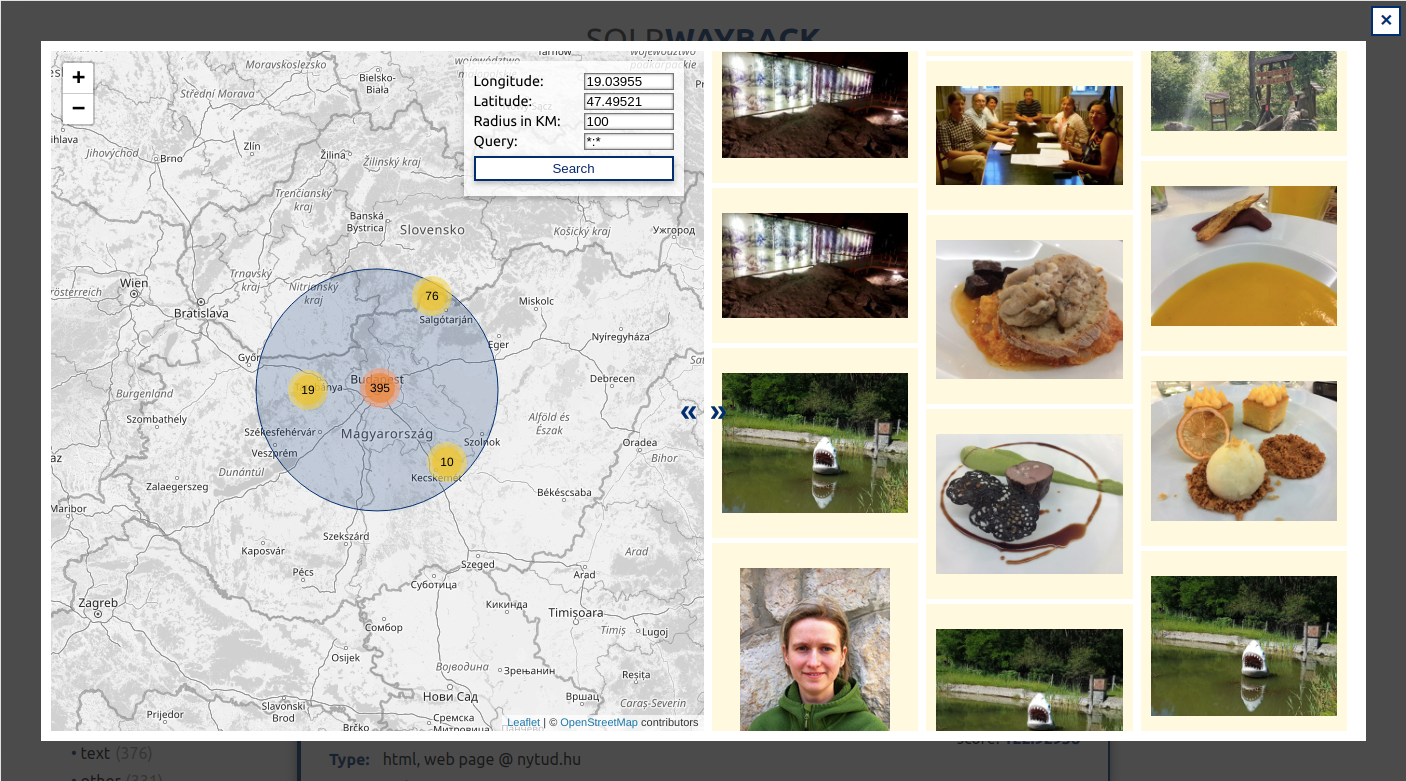
Search in images by gps location in images having exif location information about the location.
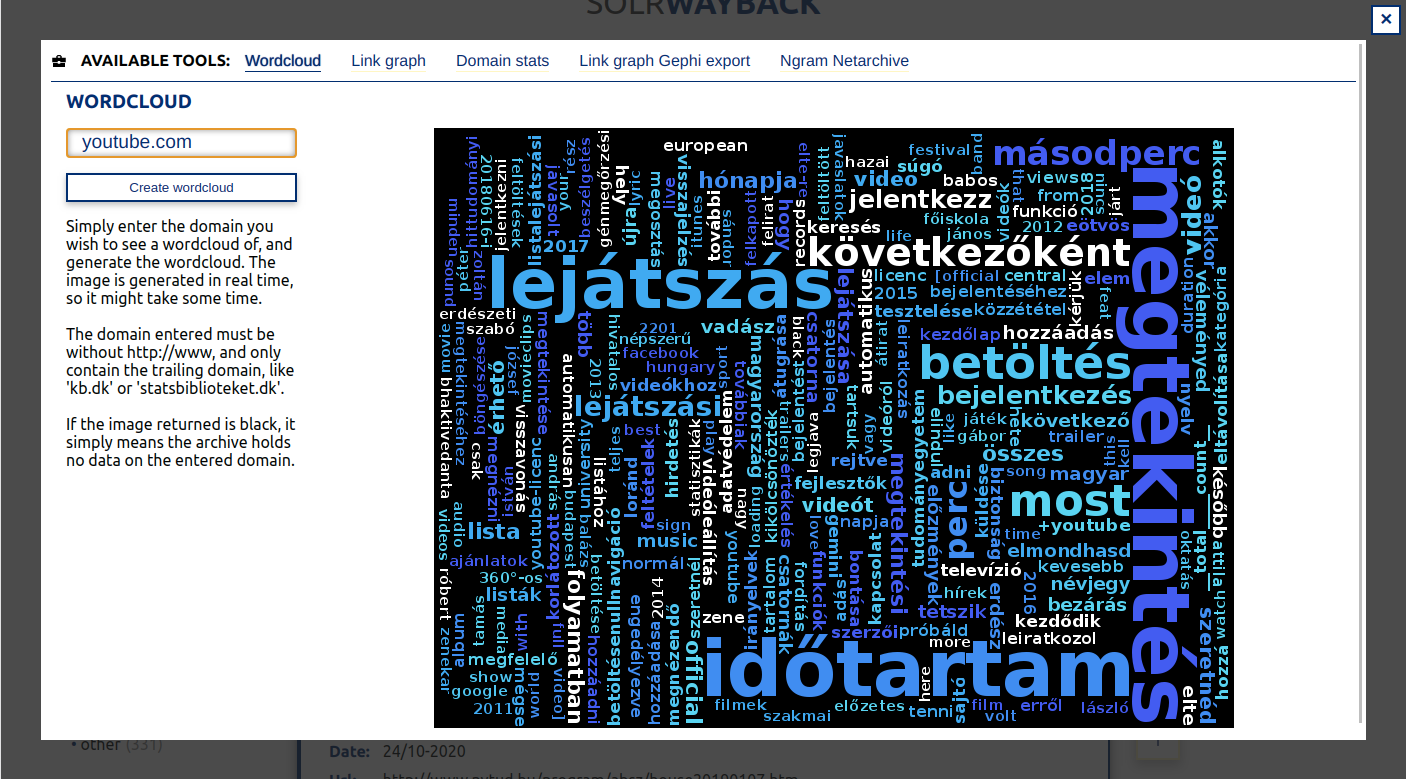
Generate a wordcloud for a domain
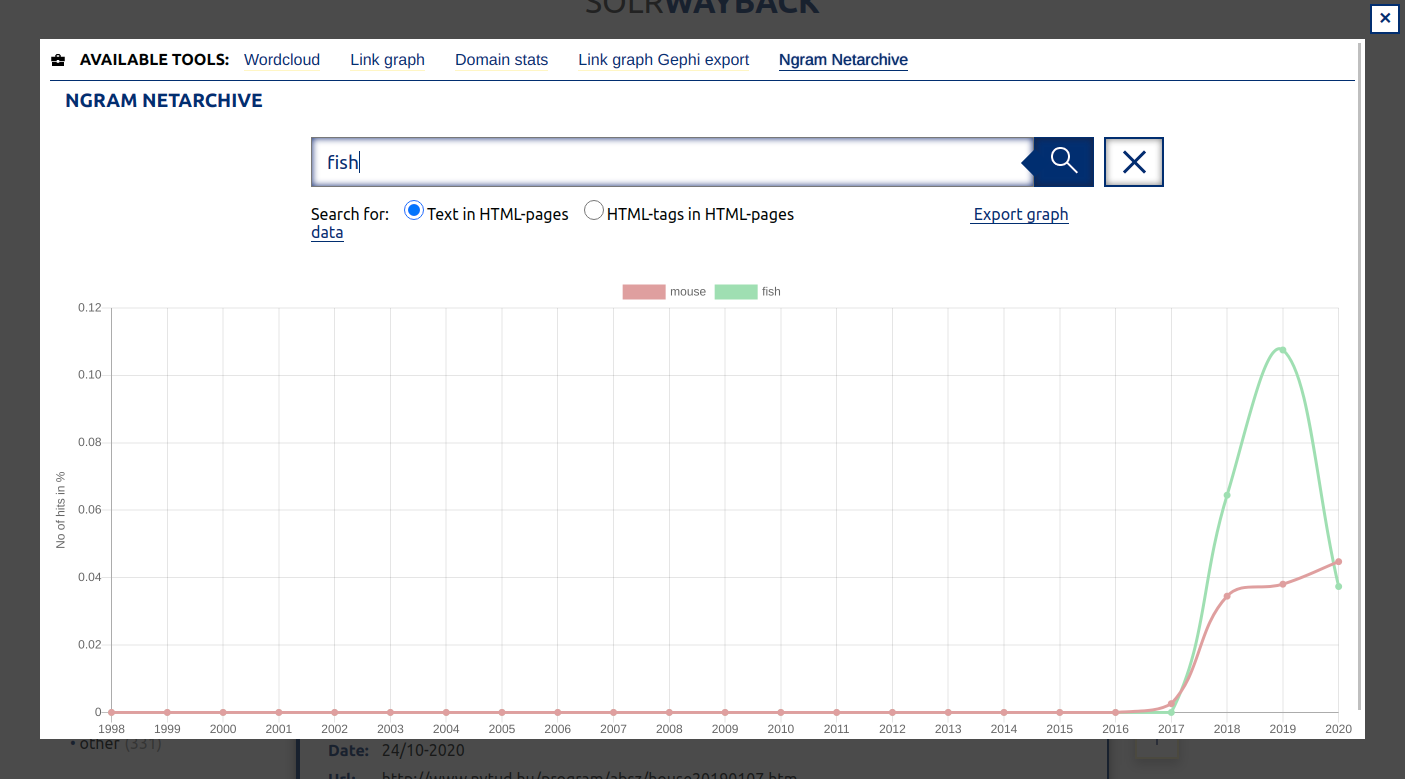
n-gram visualization of results by year, relative to the number of results that year.
The API for linking to and browsing archived webpages is the same as for Internet Archive:
- Internet Archive: https://web.archive.org/web/20080213093319/http://www.statsbiblioteket.dk/
- SolrWayback: http://server/solrwayback/services/web/20140515140841/http://statsbiblioteket.dk/
For modern browsers that supports Serviceworkers, the root servlet will be obsolete. But for better playback in legacy browsers, the root servlet can improve the playback of archived sites. See https://caniuse.com/serviceworkers to see if your browser supports serviceworkers.
Installing the root-servlet will improve playback of sites that are leaking URLs. The root-servlet will catch relative leaks (same domain) even without using proxy mode. The leaks will then be redirected back into SolrWayback to the correct URL and correct crawl time. The root-servlet is included in the bundle install. In Tomcat it must be named ROOT.war.
Link to SolrWayback root proxy: https://github.com/netarchivesuite/solrwaybackrootproxy
Absolute URL live-leaks (starting with http://domain...) will not be caught and can leak to the open and live web. Open the network tab (F12) in your browser to see if any resources are leaking, or turn-off the internet connection to be sure there are no live leaks during playback.
Documents in SolrWayback are indexed through the warc-indexer, which is maintained by The British Library. This is a fundamental tool for indexing WARC files in SolrWayback and furthermore it is included in the SolrWayback bundle.
- Works on macOS/Linux/Windows
- Java 11 (tested with OpenJDK)
- A nice collection of ARC/WARC files or harvest your own with Heritrix, Webrecorder, Brozzler, Wget, etc.
- Tomcat 9+ or another J2EE server for deploying the WAR-file
- A Solr 9+ server with the index build from the Arc/Warc files using the Warc-Indexer version 3.2.0-SNAPSHOT+
- (Optional) chrome/(chromium) installed for page previews to work. (headless chrome)
- Make sure to use a supported Java version, if necessary set the
JAVA_HOMEaccordingly (e.g.export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.23.0.9-1.fc39.x86_64) - Build the application with:
mvn package - Deploy the
target/solrwayback-*.warfile in a web-container - Copy
properties/solrwayback.propertiesandproperties/solrwaybackweb.propertiesto theuser/home/folder. - Modify the property files. (default all urls http://localhost:8080)
- Open search interface: http://localhost:8080/solrwayback
The docker container will download the SolrWayback bundle 5.1.2. You can index WARC files from a folder outside the docker container and index them. A containerized sample can be found here Read the docker file for documentation.
Thomas Egense ([email protected]) Feel free to send emails with comments or questions.
Through this bundle download you will have a fully working SolrWayback installation. Here you are able to index, search and playback web pages from your WARC files. The bundle contains Solr, the warc-indexer tool and SolrWayback installed on a Tomcat webserver. Unzip the bundle and copy two property files to your home directory and explore your WARC files.
Download the newest version of the bundle here.
Unzip and follow the instructions below.
-
Copy
properties/solrwayback.propertiesandproperties/solrwaybackweb.propertiesto theuser/home/folder. -
Windows only: Create an enviroment value that points to the folder with java11 or java 17 :
JAVA_HOME=C:\Program Files\Java\jdk-11 -
Optional: For screenshot previews to work you may have to edit the file
properties/solrwayback.propertiesand change the value of the last two properties :chrome.commandandscreenshot.temp.imagedir. Chrome(Chromium) must be installed for preview of images to work.
If you encounter any errors when running a script during installation or setup, try change the permissions for the file (startup.sh etc.). On Linux and mac, this can be done with the following command: chmod +x filename.sh
SolrWayback requires both Solr and Tomcat to be running. These processes are started and stopped separately with the following commands:
- Start tomcat:
tomcat-9/bin/startup.sh - Stop tomcat:
tomcat-9/bin/shutdown.sh - (For windows navigate to
tomcat-9\bin\and typestartup.batorshutdown.bat) - To see Tomcat is running open: http://localhost:8080/solrwayback/
- Start solr:
solr-9/bin/solr start -c -m 4g(start with 8g or 16g if you have an index with over 100M records.) - Stop solr:
solr-9/bin/solr stop -all - (For windows navigate to
solr-9\bin\and typesolr.cmd start -c -m 4gorsolr.cmd stop -all) - To see Solr is running open: http://localhost:8983/solr/#/netarchivebuilder
- For Solrwayback bundle version before v.5 the '-c' parameter must be omitted.
SolrWayback uses a Solr index of WARC files to support freetext search and more complex queries.
If you do not have existing WARC files, see steps below on harvesting with wget.
Indexing can take up to 20 minutes for 1GB warc-files. After indexing, the warc-files must stay in the same folder since SolrWayback is using them during playback etc.
Having whitespace characters in WARC file names can result in pagepreviews and playback not working on some systems. There can be up to 5 minutes delay before the indexed files are visible from search.
The script warc-indexer.sh in the indexing-folder allows for multiprocessing and keeps track of already
indexed files, so the collection can be extended by adding more WARCs and running the script again.
For more information about the warc-indexer see: https://github.com/ukwa/webarchive-discovery/wiki/Quick-Start
How to index on Linux and Mac:
Call indexing/warc-indexer.sh -h for usage and how to adjust the number of processes to use for indexing. We recommend moving your WARC files to the folders warcs1 or warcs2 and use the example below for your first time indexing.
Here is an example that will index all WARC-files in the warcs1 folder:
THREADS=2 ./warc-indexer.sh warcs1/*
This will start indexing files from the folder warcs1 using 2 threads. Assigning a higher number of threads than CPU cores available will result in slower indexing. Each indexing job require 1GB of RAM, so this can also be a limiting factor.
To create custom collections in your index, you can populate the collection and collectionid field in Solr with custom values. This can be done with the following command during indexing:
THREADS=4 INDEXER_CUSTOM="--collection_id collection1 --collection corona2021" ./warc-indexer.sh warcs1/*
You can then enable faceting on these fields in the property file: solrwaybackweb.properties.
How to index on Windows:
Indexing works a little different on Windows. This also works on Linux and Mac, however we recommend using the warc-indexer.sh as above.
- Step 1: Copy ARC/WARC files into the folder:
indexing\warcs1 - Step 2: To index the files call
indexing\batch_warcs1_folder.bat(batch_warcs1_folder.sh for Linux and Mac) - Note: There is a batch_warcs2_folder.sh similar script to show how to easily add new WARC files to the collection without indexing the old ones again.
As mentioned above there can be a 5-minute delay for files to be visible in SolrWayback after indexing has finished. To remove this wait time visit this url after index job have finished to commit them instantly: http://localhost:8983/solr/netarchivebuilder/update?commit=true. Your WARCS should now be visible in SolrWayback at: http://localhost:8080/solrwayback/
Index logging:
The indexing script keeps track of processed files by checking if a log from a previous analysis is available. The logs are stored
in the status-folder (this can be changed using the STATUS_ROOT variable). To re-index a WARC file, delete the
corresponding log file.
The SolrWayback log-file is in the folder tomcat-9/logs. See solrwayback.log or solrwayback_error.log The Solr log-file is in the folder solr-9/server/logs. See solr.log or solr-8983-console.log.
Many custom properties in solrwaybackweb.properties can be changed. There are documention above most of the properties. Tomcat needs to be restart to load changes. Here are a few properties that must collections want to customize. This is a list of properties most collections want to change.
Collection start year:
Start year used in visualizations can be changed. Property: 'archive.start.year=1998'
** Custom logo:**
Custom logo in the top left corner can be replaced with an image on the file system. Use absolute file path. Property: 'top.left.logo.image'
Link when clicking on the custom logo: Property 'top.left.logo.image.link'
Various text descriptions:
The following properties can be changed to use a file on the file system. HTML formatting is allowed but no and tag must be present
Properties:
'about.text.file'
'search.help.text.file'
'collection.text.file'
Image geo search starting position: Change the 'maps'-properties.
Word cloud: For other languages that english change the wordcloud stopword list in the property 'wordcloud.stopwords'
Renaming the solrwayback.war to collection1#solrwayback.war in the tomcat/webapps/ folder will have tomcat mapping the
application from 'http://localhost:8080/solrwayback/' to 'http://localhost:8080/collection1/solrwayback/'. This requires
defining the property in solrwaybackweb.properties: webapp.prefix=/collection1/solrwayback/
The wayback.baseurl in solrwayback.properties also needs to be fixed to match.
It will not work if you try renaming a Tomcat deployment descriptor to collection1#solrwayback.xml. (hopefull fixed in a later release)
The two property files must then be placed in the a /collection1 folder in the home-directory. This way multiple SolrWayback instances can be
running on the same Tomcat server. None of the two property files must exist in the home-directory with this setup.
The stand alone Solr-server and indexing workflow using warc-indexer.sh can scale up to 20000 WARC files of size 1GB. Using 20 threads indexing a collection of this size can take up to 3 weeks. This will result in an index of about 1TB having 500M documents and this requires changing the Solr memory allocation to at least 12GB.
Storing the index on a SSD drive is required to reach acceptable performance for searches. For collections larger than this limit Solr Cloud is required instead of the stand alone Solr that comes with the SolrWayback Bundle. A more advanced distributed indexing flow can be handled by the archon/arctika index workflow. See: https://github.com/netarchivesuite/netsearch
If you want to remove and old index and create a new index from scratch, this can be done by following these steps:
- Stop solr
- Delete the folder
solr-9/server/solr/netarchivebuilder_shard1_replica_n1/data/index/(or rename toindex1etc, if you want to switch back later) - Start solr
- Start the indexing script
For experienced Solr users only that want to tweak the Solr configuration.
If you want to make changes to schema.xml or solrconfig.xml you must use the cloud update script on a running Solr Cloud.
Changes to schema.xml must be done before starting indexing. Changes to SolrConfig.xml can be done run time.
To update the configuration use the following two commands. (replace paths to your system)
bin/solr zk upconfig -n netarchivebuilder_conf -d "/home/xxx/solrwayback/solrwayback_package_5.1.2/solr_config/conf" -z localhost:9983
curl -X POST "http://localhost:8983/api/collections/netarchivebuilder/" -H 'Content-Type: application/json' -d '{"modify":{"config": "netarchivebuilder_conf" } }
A powerful laptop can handle up to 8 simultaneous indexing processes with Solr running on the same laptop. Using an SSD for the Solr-index will speed up indexing and also improve search/playback performance drastically.
Click the question mark in the search-field in SolrWayback to get help with the search syntax for more complex queries and using field queries.
The toolbar icon opens a menu with the available tools.
How to create your own harvest of websites (macOS/Linux only):
- macOS user may have to install wget first (use Homebrew)
- Using the wget command is an easy way to harvest websites and create WARC files. The WARC files can then be indexed into SolrWayback.
- Create a new folder, since there will be several files written in this folder. Navigate to that folder in a prompt.
- Create a text file called
url_list.txtwith one URL per line in that folder. - Type the following in a prompt:
wget --span-hosts --warc-cdx --page-requisites --warc-file=warcfilename --warc-max-size=1G -i url_list.txt
The script will harvest all pages in the url_list.txt file with all resources required for that page (images, CSS, etc.) and be written to a WARC file called warcfilename.warc.
The optional --span-hosts parameter will also harvest resources outside the domain of the page and can be removed
- To perform a multi-level harvest:
wget --span-hosts --level=1 --recursive --warc-cdx --page-requisites --warc-file=warcfilename --warc-max-size=1G -i url_list.txt
wherelevel=1means "starting URLs and the first level of URLs linked from the starting URLs". This will substantially increase the size of the WARC file(s).