This repository has been archived.
If you are looking for a Python API on top of OPTD data, you can check out NeoBase.

This project provides tools to play with geographical data. It also works with non-geographical data, except for map visualizations :).
There are embedded data sources in the project, but you can easily play with your own data in addition to the available ones. After data loading, you can:
- perform various types of queries (find this key, or find keys with this property)
- make fuzzy searches based on string distance (find things roughly named like this)
- make phonetic searches (find things sounding like this)
- make geographical searches (find things next to this place)
- get results on a map, or on a graph, or export it as csv data, or as a Python object
This is entirely written in Python. The core part is a Python package, but there is a command line tool as well! Get it with easy_install, then you can see where are airports with international in their name:
$ GeoBase --fuzzy international --map
You can perform all types of queries:
$ GeoBase --base cities --fuzzy "san francisko" # typo here :)Of course, you can use your own data for map display:
$ cat coords.csv
p1,48.22,2.33
p2,49.33,2.24
$ cat coords.csv | GeoBase --mapAnd for every other thing as well:
$ cat edges.csv
A,B
A,C
D,A
$ cat edges.csv | GeoBase --graph
Administrate the data sources:
$ GeoBase --adminWe are currently gathering input from the community to define the next version features, so do not hesitate to open issues on the github page.
Here are some useful links:
- the API documentation for the Python package
- the wiki pages for any question!
- the twitter account for the latest news
These prerequisites are very standard packages which are often installed by default on Linux distributions. But make sure you have them anyway.
First you need to install setuptools (as root):
$ apt-get install python-setuptools # for debian
$ yum install python-setuptools.noarch # for fedoraThen you need some basics compilation stuff to compile dependencies (also as root):
$ apt-get install python-dev g++ # for debian
$ yum install python-devel gcc-c++ # for fedoraYou can install it from PyPI:
$ easy_install --user -U GeoBasesThere is a development version also on PyPI (dev):
$ easy_install --user -U GeoBasesDevYou can clone the project from github:
$ git clone https://github.com/opentraveldata/geobases.gitThen install the package and its dependencies:
$ cd geobases
$ python setup.py install --user # for user spaceA script is put in ~/.local/bin, to be able to use it, put
that in your ~/.bashrc or ~/.zshrc:
export PATH=$PATH:$HOME/.local/bin
export BACKGROUND_COLOR=black # or 'white', your callIf you use zsh and want to get awesome autocomplete for the main script, add this to
your ~/.zshrc:
# Add custom completion scripts
fpath=(~/.zsh/completion $fpath)
autoload -U compinit
compinitThere is Python 3 and Pypy support, you can try it by changing branch before installation.
For Python 3, you have to install setuptools and python3-dev as prerequisites, then:
$ git checkout 3000
$ python3 setup.py install --userYou can also install the package for Python 3 from PyPI (3K):
$ easy_install-3.2 --user -U GeoBases3KFor Pypy, after pypy and pypy-dev installation:
$ git checkout pypy
$ sudo pypy setup.py installYou can also install the package for Pypy from PyPI (pypy):
$ easy_install --user -U GeoBasesPypyRun the tests:
$ python test/test_GeoBases.py -v>>> from GeoBases import GeoBase
>>> geo_o = GeoBase(data='ori_por', verbose=False)
>>> geo_a = GeoBase(data='airports', verbose=False)
>>> geo_t = GeoBase(data='stations', verbose=False)You can provide other values for the data parameter. All data sources are documented in a single YAML file:
- data="ori_por" will load a local version of this file, this is the most complete source for airports, use it!
- data="airports" will use geonames as data source for airports
- data="stations" will use RFF data, from the open data website, as data source for french train stations
- data="stations_nls" will use NLS nomenclature as data source for french train stations
- data="stations_uic" will use UIC nomenclature as data source for french train stations
- data="countries" will load data on countries
- data="capitals" will load data on countries capitals
- data="continents" will load data on continents
- data="timezones" will load data on timezones
- data="languages" will load data on languages
- data="cities" will load data on cities, extracted from geonames
- data="currencies" will load data on currencies, extracted from wikipedia
- data="airlines" will load data on airlines, extracted from that file
- data="cabins" will load data on cabins
- data="locales" will load data on locales
- data="location_types" will load data on location types
- data="feature_classes" will load data on feature classes
- data="feature_codes" will load data on feature codes
- data="ori_por_non_iata" will load some non-iata data excluded from ori_por
- data="geonames_MC" will load MC data of geonames
- data="geonames_FR" will load FR data of geonames
- data="postal_codes_MC" will load MC postal codes data
- data="postal_codes_FR" will load FR postal codes data
- data="feed" will create an empty instance
All features are unaware of the underlying data, and are available as long as
the headers are properly set in the configuration file, or from the Python API.
For geographical features, you have to name the latitude field lat, and the
longitude field lng.
>>> geo_o.get('CDG', 'city_code')
'PAR'
>>> geo_o.get('BRU', 'name')
'Bruxelles National'
>>> geo_t.get('frnic', 'name')
'Nice-Ville'
>>> geo_t.get('fr_not_exist', 'name', default='NAME')
'NAME'You can put your own data in a GeoBase class, either by loading
your own file when creating the instance, or by creating an empty instance
and using the set method.
>>> conditions = [('city_code', 'PAR'), ('location_type', ('H',))]
>>> list(geo_o.findWith(conditions, mode='and'))
[(2, 'JDP'), (2, 'JPU')]
>>>
>>> conditions = [('city_code', 'PAR'), ('city_code', 'LON')]
>>> len(list(geo_o.findWith(conditions, mode='or')))
33>>> geo_o.distance('CDG', 'NCE')
694.5162...>>> # Paris, airports <= 40km
>>> [k for _, k in sorted(geo_a.findNearPoint((48.84, 2.367), 40))]
['ORY', 'LBG', 'TNF', 'CDG']
>>>
>>> # Nice, stations <= 4km
>>> iterable = geo_t.findNearPoint((43.70, 7.26), 4)
>>> [geo_t.get(k, 'name') for _, k in iterable]
['Nice-Ville', 'Nice-St-Roch', 'Nice-Riquier']>>> sorted(geo_a.findNearKey('ORY', 50)) # Orly, airports <= 50km
[(0.0, 'ORY'), (18.8..., 'TNF'), (27.8..., 'LBG'), (34.8..., 'CDG')]
>>>
>>> sorted(geo_t.findNearKey('frnic', 3)) # Nice station, <= 3km
[(0.0, 'frnic'), (2.2..., 'fr4342'), (2.3..., 'fr5737')]>>> list(geo_a.findClosestFromPoint((43.70, 7.26))) # Nice
[(5.82..., 'NCE')]
>>>
>>> list(geo_a.findClosestFromPoint((43.70, 7.26), N=3)) # Nice
[(5.82..., 'NCE'), (30.28..., 'CEQ'), (79.71..., 'ALL')]>>> geo_t.fuzzyFind('Marseille Charles', 'name')[0]
(0.8..., 'frmsc')
>>> geo_a.fuzzyFind('paris de gaulle', 'name')[0]
(0.78..., 'CDG')>>> geo_t.visualize()
* Added lines for duplicates linking, total 0
* Could not detect geocode support in join fields.
> Affecting category None to color blue | volume 3190
<BLANKLINE>
* Now you may use your browser to visualize:
./example_map.html ./example_table.html
<BLANKLINE>
* If you want to clean the temporary files:
rm ./example_map.json ...
<BLANKLINE>
(['map', 'table'], (['./example_map.html', './example_table.html'], ['./example_map.json', ...]))
Installation of the package will also deploy a standalone script named GeoBase:
$ GeoBase ORY CDG # query on the keys ORY and CDG
$ GeoBase --closest CDG # closest from CDG
$ GeoBase --near LIG # near LIG
$ GeoBase --fuzzy marseille # fuzzy search on 'marseille'
$ GeoBase --admin # to administrate data sources
$ GeoBase --ask # interactive learning mode
$ GeoBase --help # your best friend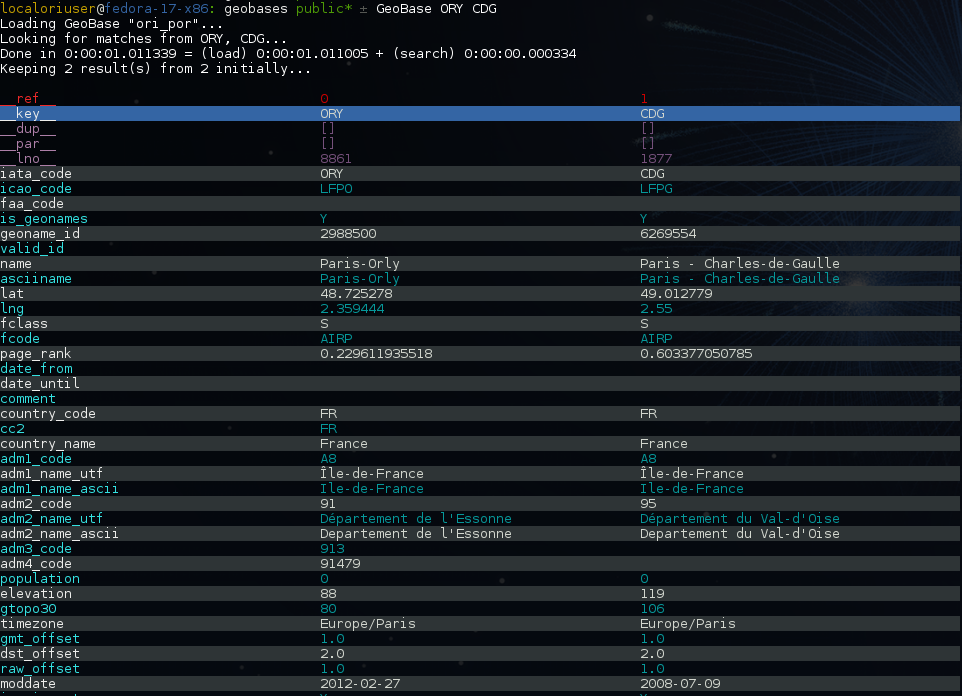
In the previous picture, you have an overview of the command line verbose display. Three displays are available for the command line tool:
- the verbose display
- the csv display with
--quiet - the map display with
--map - the graph display with
--graph
With the verbose display, entries are displayed on each column,
and the available fields on each line. Fields starting with __ like __field__ are
special. This means they were added during data loading:
__key__is the field containing the id of the entry. Ids are defined with a list of fields in the configuration file.__dup__is the field containing a list of duplicated keys. Indeed there is mechanism handling duplicated keys by default, which creates new keys if the key already exists in theGeoBase.__par__is the field containing the parent key if the key is duplicated.__lno__is the field containing the line number during loading.__gar__is the field containing the data which was not loaded on the line (this can be because the line was not well formatted, or because there were missing headers).
More examples here, for example how to do a search on a field, like admin_code (B8 is french riviera):
$ GeoBase -E adm1_code -e B8Same with csv output (customized with --show):
$ GeoBase -E adm1_code -e B8 --quiet --show __ref__ iata_code nameAdd a fuzzy search:
$ GeoBase -E adm1_code -e B8 --fuzzy sur merAll heliports under 200 km from Paris:
$ GeoBase --near PAR -N 200 -E location_type@raw -e 'H'50 train stations closest to a specific geocode:
$ GeoBase -E location_type@raw -e R --closest '48.853, 2.348' -C 50Countries with non-empty postal code regex:
$ GeoBase -b countries -E postal_code_regex -e '' --reverse --quietReading data input on stdin:
$ echo -e 'ORY^Orly\nCDG^Charles' | GeoBaseDisplay on a map:
$ GeoBase -b stations --mapMarker-less map for a specific GMT offset:
$ GeoBase -E gmt_offset -e 1.0 --map -M _ _ country_code __none__Display your data on a map:
$ cat coords.csv
p1,48.22,2.33
p2,49.33,2.24
$ cat coords.csv | GeoBase --mapDisplay your data on a graph:
$ cat edges.csv
A,B
A,C
D,A
$ cat edges.csv | GeoBase --graphThe MANIFEST.in file is used to determine which files will be
included in a source distribution.
package_data directive in setup.py file is about which file will
be exported in site-package after installation.
So you really need both if you want to produce installable packages like
rpms or zip which can be installed afterwards.
You will also find a Rakefile at the
root of the project. This can be used to build and deploy the packages.
Deployment can be done using webdav, and the Rakefile expects nd to be
installed (this is a webdav client).
To install nd, fetch the sources and compile them.
Virtualenv still has some bugs on 64 bits systems, if you are using such a system, you absolutely need to upgrade to the very last unreleased version of virtualenv, before executing rake:
$ pip uninstall virtualenv
$ pip install https://github.com/pypa/virtualenv/tarball/develop