This work has been published in the Proceedings of the 2019 World Wide Web Conference (WWW’19) https://doi.org/10.1145/3308558.3313652
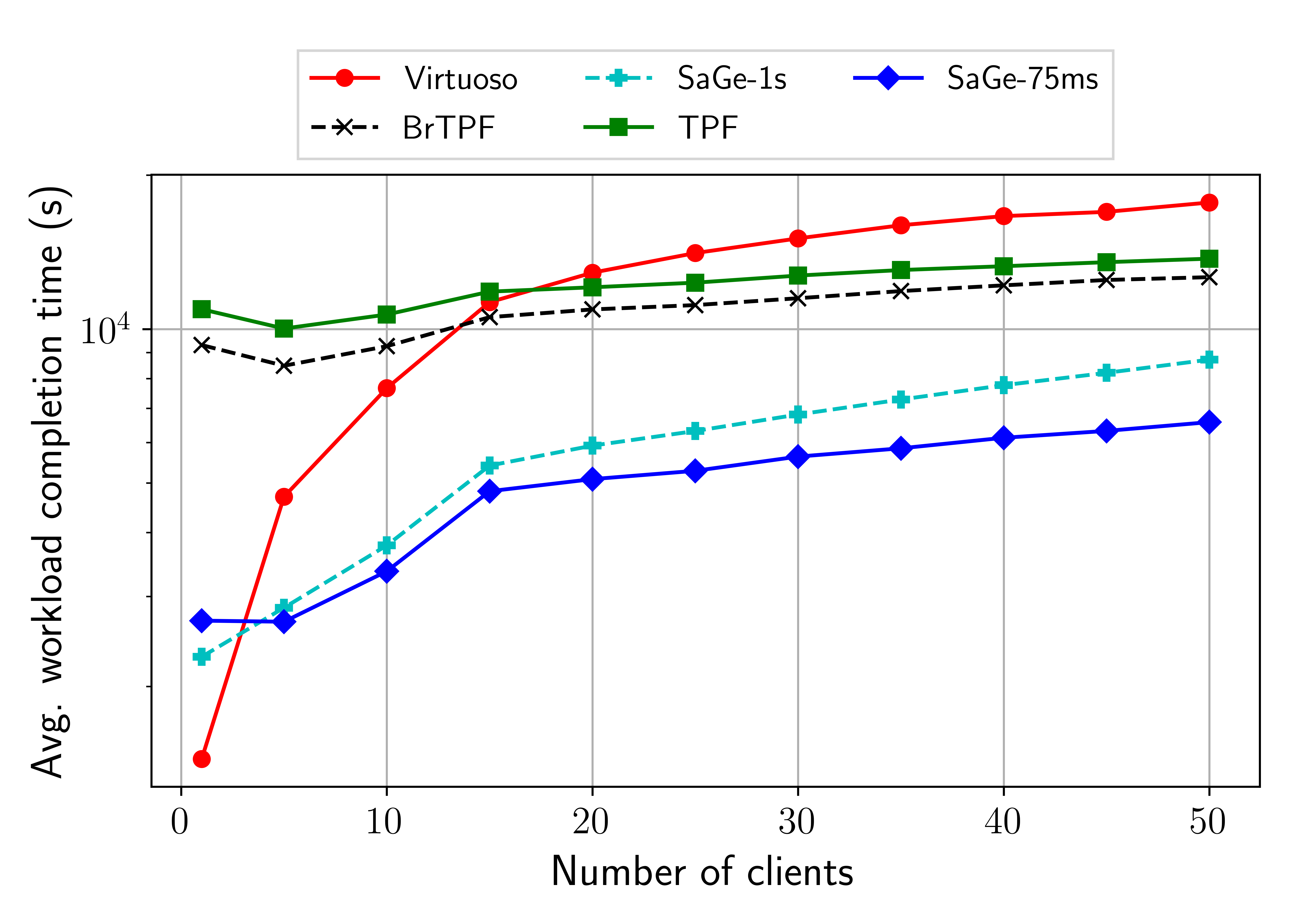
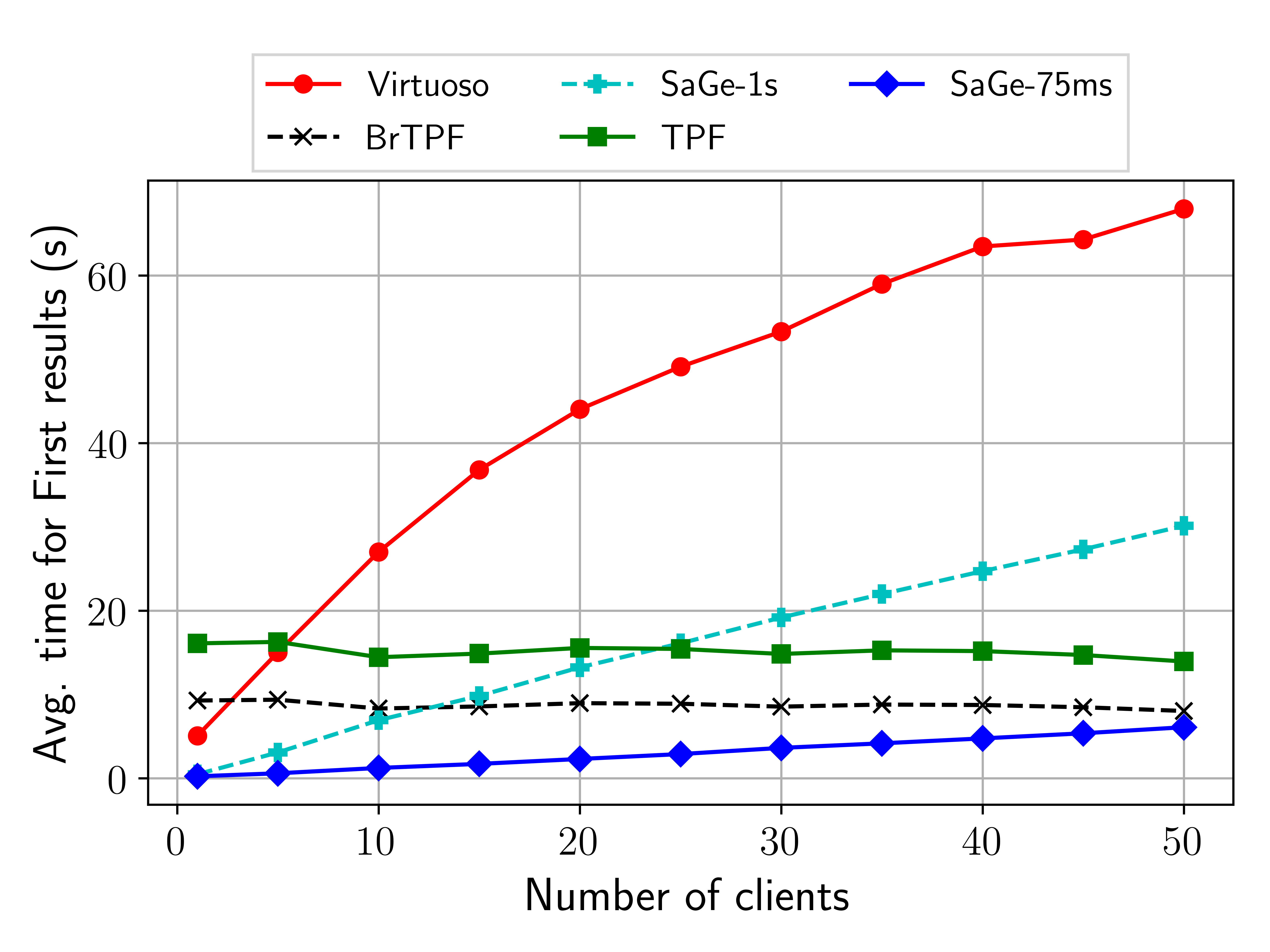
To preserve the availability of SPARQL query services, data providers enforce quotas on server usage. Queries which exceed these quotas are interrupted and delivers partial results. Such interruption is not an issue if it is possible to resume the query execution afterwards. Unfortunately, there is no preemption model for the web that allows to suspend and resume SPARQL queries. In this paper, we present a model for Web preemption and SaGe, a SPARQL query service that supports such preemption. SPARQL queries are suspended by the web server after a fixed quantum of time and resumed upon client request. Web preemption is tractable only if its cost in time is negligible compared to the time quantum. Thus, the challenge is to support full SPARQL query language while keeping the cost of preemption negligible. Extensive experimentations demonstrate that SaGe outperforms existing approaches by several order of magnitude in term of average total query execution time, time for first results and data transferred per query.
An online demonstration is available at http://sage.univ-nantes.fr/.
All scripts used during experiments are available in the scripts directory.
- SaGe python server
- SaGe java client
- Virtuoso v7.2.4
- TPF server v2.2.3
- TPF client v2.0.5
- BrTPF client + server
We used the Waterloo SPARQL Diversity Tests suite (WatDiv) RDF dataset, encoded in HDT format. The dataset contains 10^7 triples, and the queries used are conjunctive SPARQL queries with STAR, PATH and SNOWFLAKE shapes. They are taken from the BrTPF experimental study. These queries vary in complexity, with very high and very low selectivity. All queries are available in the watdiv_queries.zip archive.