Hogwarts Library Web Portal
http://irma-dev.s3-website-us-east-1.amazonaws.com

Named after Madam Irma Pince who oversees The Hogwarts Library, this web application aims at reducing the stress that Madam Pince is under by allowing students and faculty to view, borrow, and return books. It also allows users to see the status and activites of all the books we have.
Donations are welcome as always!
*requires serverless framework installed
git clone [email protected]:samazadi/irma.git
cd irma
npm run install:all
npm run startYou can find a postman collection to hit the API directly in the root of this project.
*requires serverless framework installed as well as the AWS CLI
npm run deploy
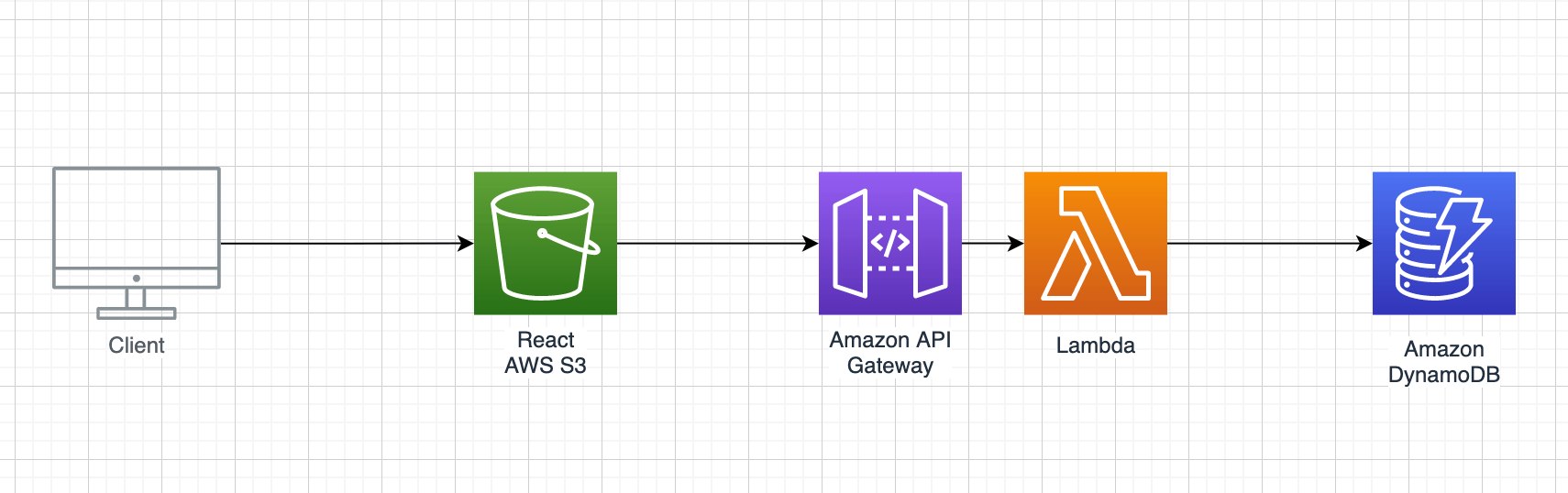
React was used for the front end of this app.
- Can be easily hosted in AWS S3 providing extremely high availability/durability
- Tons of great NPM modules to use
- Easy scalability with the correct directory structure
- Typescript for type safety
- Virtual DOM for performant DOM manipulation
API Gateway was used as the API layer with Serverless Framework used for management
- Easily manage and deploy API using serverless CLI
- Highly scalable
- Allows for versioning and multiple stages/environments
- Seamless integration with Lambdas
- Pay per request
For the database I decided to stay with the serverless model and went with AWS Dynamo DB. This helped me avoid needing to set up any database servers and was able to deploy everything directly using a single serverless.yml file. DynamoDB with Serverless also provides great offline support, helping improve my development speed and experience.
The fact that there was only one entity (a Book) helped confirm my decision of using a NoSQL database such as DynamoDB.
Next I reviewed the read/write patterns. The limited amount of complex queries I needed to do meant that my decision to use DynamoDB was feasible. My only remaining concern with DynamoDB was the searching capability I wanted to introduce. This meant that for fuzzy searches I would need to scan the entire database, which can be costly as the database grows (this is a major limitation of DynamoDB).
I decided to continue with DynamoDB because I knew the data would be very limited starting off, and if it were to grow, ElasticSearch can be easily integrated with DynamoDB to offload the expensive search queries.
I also made sure to implement a repository to abstract any communication with the database, allowing me to change the database if needed with minimal code changes.