Jul 08, 2013 - Searchdaimon is an open source search engine for corporate data and websites. It aims to be as simple to use as your favorite Internet search engine, yet has the added power of delivering results from numerous systems with standardized attribute navigation.
It comes with a powerful administrator interface and can index websites and several common enterprise systems like SharePoint, Exchange, SQL databases, Windows file shares etc. The ES supports many data sources (e.g., Word, PDF, Excel) and the possibility of faceted search, attribute navigation and collection sorting.
You can setup your development environment directly on the ES with little effort. Then tweak and change what you want.
More information about the product and screenshots are available at the bottom of this page.
- Official website
- Documentation
- Road map to the future
- When to use and not to use the ES
- Help us translate the user interface to different languages
- How to upgrade existing installations to the open source version
- How Searchdaimon As, our company will make money
We have released all our source code related to the Searchdaimon enterprise search engine to GitHub, with full commit history. We will from now on be using this GitHub repository internally as our only source code repository. It is currently about 100K lines of code. These is the full source code, tools and build chain to build the ES.
The only exception is that we unfortunately have had to hold on to some related source code that uses proprietary code from 3-partys. However none of thus are essential, and binaries are made freely available for most of it. A list of non-released code is available at: Statement on non-open source code.
The ES software is currently about 100K lines of code and is mostly written in C and Perl.
C: 72.00% Perl: 18.79% Yacc: 5.93% Lex: 2.58% sh: 0.35% Java: 0.16% C++: 0.13% AWK: 0.04%
It is super easy to get started to develop on the ES. As the ES comes as a virtual machine with all software installed, all you need to get a development environment up and running is just to add the development plugin, then checkout the source code with git.
- Obtain a running ES Download an ES virtual machine image from http://www.searchdaimon.com/download/ or use on of the torrents in the torrent folder. Import and run on VMware/Xen/VirtualBox. Alternatively you can run a version on Amazon Web Services or install from an iso image.
- Log in as root (the password will be visible in the console). Use yum to setup the development environment and dependencies:
yum install boitho-devel - Become the boitho user:
su – boitho
cd /home/boitho/boithoTools/ - Setup git and import the code from GitHub:
sh script/setup-dev-github.sh - Compile the source code:
make
You may also want to enable ssh login as root. As root run:
sh /home/boitho/boithoTools/script/enable-root-login.sh
Remember to change the root password!
You most disable automatic updates to prevent that new official ES updates overwrite your changes. Open the searchdaimon.repo file for editing:
nano -w /etc/yum.repos.d/searchdaimon.repo
Find the [boitho-production] section and set it from “enabled=1” to “enabled=0”.
yum uses http and git has its own port at 9418, so remember to open ports 80 and 9418 if you have an external firewall.
The ES uses many 3-party libraries for data conversion and connecting to data sources. This makes it hard to build on arbitrary systems. For this first release we have decided to only support building of the source code on an existing ES installation. The easiest is to get a virtual machine version running and use the exiting rpms to setup your development environment.
As our software become more wide spread we plan to add support for other *nix environments also. The first step will probably be to start using a new CentOS version that has a life cycle of 10 years as the underlying operating system. Then slowly move to a user-space software only version.
Crawlers should be developing as plugins so there part of the system can be changed without interfering. The preferred whey is to use Perl as described in the “Creating your own data connector” section of the ES manual http://www.searchdaimon.com/documentation/ .
The ES is licensed under the GNU General Public License version 2 (GPLv2).
Please see our manual at http://www.searchdaimon.com/documentation/
Talk with the ES staff, users and other developers at http://www.searchdaimon.com/forum/ .
You can restrict your search to type of document, data source, date and meta-information such as contacts, customers, sales and projects. You can also sort on date or relevancy.
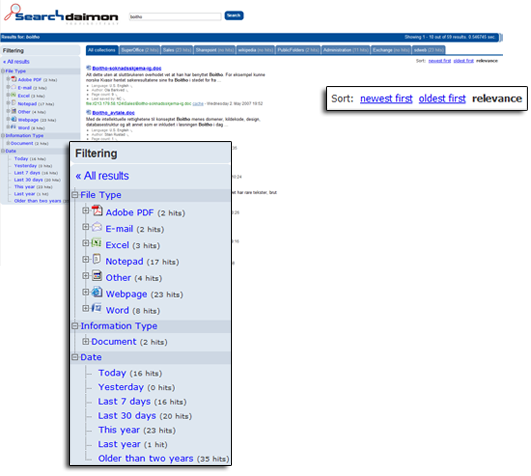
In the above picture, you can see the results of the query "enterprise search". The search has been further broken down to only include documents from the "Sales" collection. You can also filter the search to only include documents from a file type like Excel or PowerPoint, or from a date interval like this year or older than two years.
Structured data can be presented as a table among the results. Often you'll see the information you need in the user interface, without having to open the data source itself.
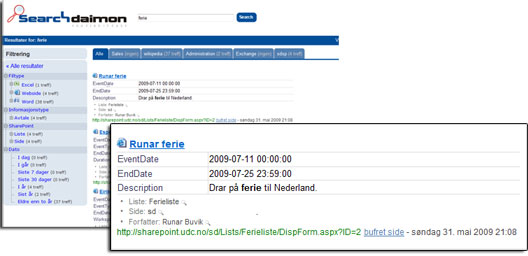
Above you see a search which gives hits in a holiday schedule. The schedule is a structurized list in SharePoint. We can see that Runar Buvik is entered for a trip to the Netherlands from 07-11-2009 to 07-25-2009.
The ES suggests query words while you are writing. The words proposed are fetched from documents the user has access to, so that domain and product names, which you can't find in traditional dictionaries, are included.

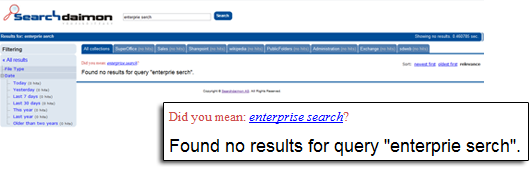
The ES can propose correctly spelled words if you have misspelled a word. For example correcting "enterprie serch" to enterprise search. As for Suggest, the dictionary is built from indexed documents.
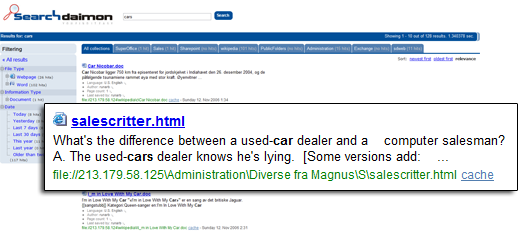
Searching for "car" also shows documents containing "cars", etc.
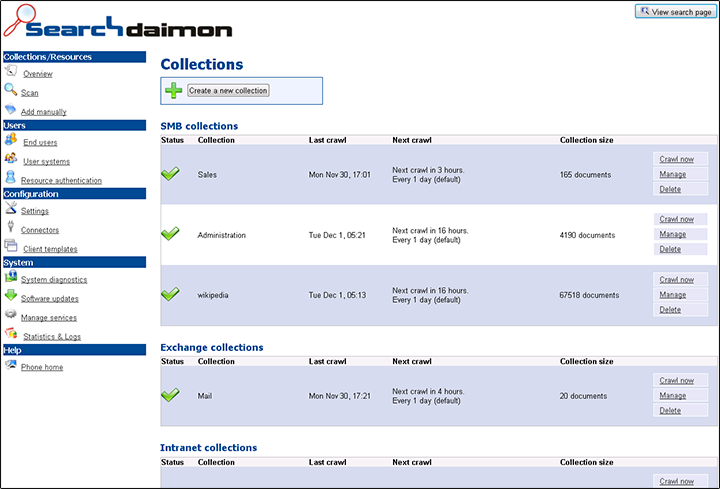
The ES comes with a strong intuitive web interface for administration.
Show status and allow you to configure your collections. Collections are grouped by type of crawler (SMB, Exchange etc.).
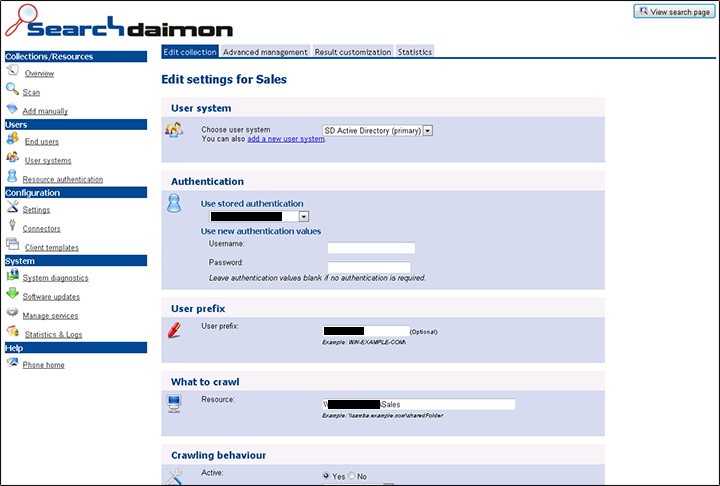
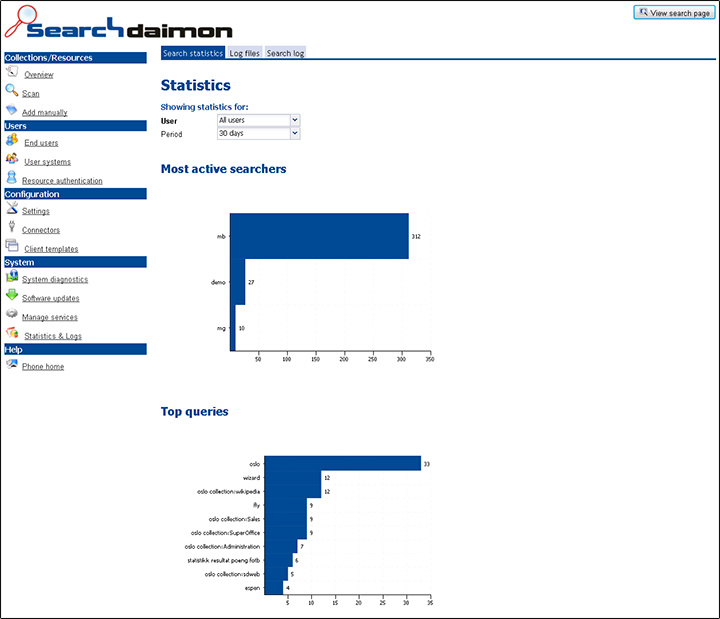
View aggregated and raw data to see which users are the most active, what the most popular queries are, and how many searches are performed every day.