This repository contains the term project for neural networks class (IFT780) at Université de Sherbrooke (Winter 2021).
- Abir Riahi (https://github.com/riaa3102)
- Nicolas Raymond (https://github.com/Rayn2402)
- Simon Giard-Leroux (https://github.com/sgiardl / https://github.com/gias2402)
This project implements active learning methods for deep neural networks. The goal is to compare different active learning sampling criteria using different models and datasets for the image classification task.
This figure shows the implemented pool-based active learning framework:
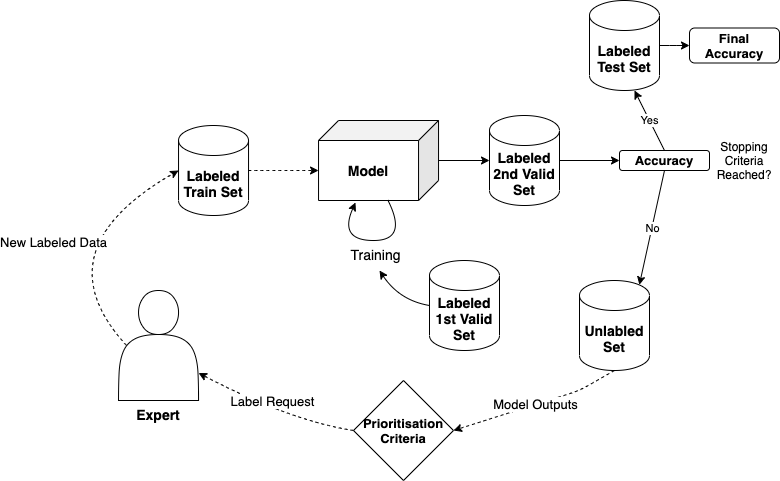
Models:
- ResNet34
- SqueezeNet 1.1
Datasets:
- EMNIST 'balanced' split (62 classes)
- CIFAR10 (10 classes)
Query strategies:
- Least Confidence
- Margin Sampling
- Entropy Sampling
- Random Sampling
Install dependencies on a python environment
$ pip3 install -r requirements.txt
This program enables users to experiment different models of classification using passive or active learning.
| Short | Long | Type | Default | Choices | Description |
|---|---|---|---|---|---|
-m |
--model |
str | 'SqueezeNet11' |
['SqueezeNet11', 'ResNet34'] |
Name of the model to train |
-d |
--dataset |
str | 'CIFAR10' |
['CIFAR10', 'EMNIST'] |
Name of the dataset to learn on |
-ns |
--n_start |
int | 100 |
The number of items that must be randomly labeled in each class by the Expert | |
-nn |
--n_new |
int | 100 |
The number of new items that must be labeled within each active learning loop | |
-e |
--epochs |
int | 50 |
Number of training epochs in each active learning loop | |
-qs |
--query_strategy |
str | 'least_confident' |
['random_sampling', 'least_confident', 'margin_sampling', 'entropy_sampling'] |
Query strategy of the expert |
-en |
--experiment_name |
str | 'test' |
Name of the active learning experiment | |
-p |
--patience |
int | 4 |
Maximal number of consecutive rounds without improvement | |
-b |
--batch_size |
int | 50 |
Batch size of dataloaders storing train, valid and test set | |
-lr |
--learning_rate |
float | 0.0001 |
Learning rate of the model during training | |
-wd |
--weight_decay |
float | 0 |
Regularization term | |
-pt |
--pretrained |
boolean | False | Boolean indicating if the model used must be pretrained on ImageNet | |
-da |
--data_aug |
boolean | False | Boolean indicating if we want data augmentation in the training set | |
-nr |
--n_rounds |
int | 3 |
Number of active learning rounds | |
-s |
--init_sampling_seed |
int | None | Seed value set when the expert labels items randomly in each class at start |
-h, --help
show this help message and exit
To run a single experiment:
python3 experiment.py
python3 experiment.py --model='SqueezeNet11' --dataset='CIFAR10' --epochs=50
To run the generalization experiments batch:
python3 Experiments/Generalization.py
To run the pretraining experiments batch:
python3 Experiments/Pretraining.py
To run the query strategy experiments batch:
python3 Experiments/QueryStrategy.py
This program enables users to extract results and plot a learning curve for specific experiments that have been performed previously.
| Short | Long | Type | Default | Choices | Description |
|---|---|---|---|---|---|
-m |
--model |
str | 'SqueezeNet11' |
['SqueezeNet11', 'ResNet34'] |
Name of the model to train |
-fp |
--folder_prefix |
str | 'generalization' |
Start of the folders name from which to extract results | |
-c |
--curve_label |
str | query_strategy |
Labels to use in order to compare validation accuracy curve | |
-s |
--save_path |
str | accuracy_curve |
Name of the file containing the resulting plot |
-h, --help
show this help message and exit
To plot the active learning curve for a particular experiments batch:
python3 extract_results_plots.py -m='SqueezeNet11' -fp='generalization' -c='query_strategy' -s='gen_accuracy'
├── data
│ └── raw <- The original, immutable data dump, where the data gets downloaded.
│
├── Experiments <- Scripts to run the experiments as stated in the report.
│ └── Generalization.py <- Generalization experiments.
│ └── Helpers.py <- Helper functions.
│ └── Pretraining.py <- Pretraining experiments.
│ └── QueryStrategy.py <- Query strategy experiments.
│
│── figures <- Generated figures.
│
├── models <- Trained and serialized models, model predictions, or model summaries
│
├── reports <- Generated analysis as PDF and LaTeX.
│
├── src <- Source code for use in this project.
│ ├── data <- Scripts to download or generate data
│ │ ├── DataLoaderManager.py
│ │ ├── DatasetManager.py
│ │ └── constants.py
│ │
│ ├── models <- Scripts to train models and then use trained models to make predictions
│ │ ├── ActiveLearning.py
│ │ ├── Expert.py
│ │ ├── TrainValidTestManager.py
│ │ └── constants.py
│ │
│ └── visualization <- Scripts to create exploratory and results oriented visualizations
│ └── VisualizationManager.py
│
├── .gitignore <- File that lists which files git can ignore.
│
├── README.md <- The top-level README for developers using this project.
│
├── experiment.py <- Argument parser to get command line arguments
│
├── extract_results_plots.py <- File to load results and plot active learning curves.
│
├── requirements.txt <- The requirements file for reproducing the analysis environment,
│ generated with `pipreqs path/to/folder`
│
└── test_environment.py <- Test environment to test the active learning loop.
Project based on the cookiecutter data science project template.