arch v1
- Default configuration files should be defined in yaml
- Component configuration should be read from the configuration service
- Messages between services should be formatted as JSON and sent via HTTP
- Logs should be sent to logstash as JSON via the TCP Input
- Messages into Storm should be via AMQP using RabbitMQ
- RabbitMQ: the message queue that interfaces between the collectors and the rt processing pipeline
- Titan: the distributed graph database that stores the knowledge graph, accessible through the query-service
- Logstash: tool for collecting and managing log files from stucco components using elasticsearch and kibana
- etcd: tool for sharing configuration and service discovery from stucco components
The collectors pull data or process data streams and push the collected data (documents) into the message queue. Each type of collector is independent of others. The collectors can be implemented in any language.
Collectors can either send messages with data or messages without data. For messages without data, the collector will add the document to the document store and attach the returned id to the message.
Collectors can either be stand-alone and run on any host, or be host-based and designed to collect data specific to that host.
Web collectors pull a document via HTTP/HTTPS given a URL. Documents will be decompressed, but no other processing will occur.
Various (e.g. HTML, XML, CSV).
Scrapers pull data embedded within a web page via HTTP/HTTPS given a URL and an HTML pattern.
HTML.
RSS collectors pull an RSS/ATOM feed via HTTP/HTTPS given a URL.
XML.
Twitter collectors pull Tweet data via HTTP from the Twitter Search REST API given a user (@username), hashtag (#keyword), or search term.
JSON.
Netflow collectors will collect from Argus. The collector will listen for argus streams using ra tool and convert to XML and pipe to send the flow data to the message queue as a string.
TODO.
Host-based collectors collect data from an individual host using agents.
Host-based collectors should be able to collect and forward:
- System logs
- Hone data
- Installed packages
If we are writing the collector, JSON. If not, whatever format the agent uses.
Stand-alone collectors may require state state (state should be stored with the scheduler, such as the last time a site was downloaded). Host-based collectors may need to store state (e.g. when the last collection was run).
Input transport protocol will depend on the type of collector.
Input format will depend on the type of collector.
Advanced Message Queuing Protocol (AMQP), as implemented in RabbitMQ. See the concepts documentation for information about AMQP and RabbitMQ concepts. See the protocol documentation for more on AMQP. Examples below are in Go using the amqp package. Other libraries should implement similar interfaces.
The RabbitMQ exchange is exchange-type of topic with the exchange-name of stucco.
The exchange declaration options should be:
"topic", // type
true, // durable
false, // auto-deleted
false, // internal
false, // noWait
nil, // arguments
The publish options should be:
stucco, // publish to an exchange named stucco
<routingKey>, // routing to 0 or more queues
false, // mandatory
false, // immediate
The <routingKeys> format should be: stucco.in.<data-type>.<source-name>.<data-name (optional)>, where:
- data-type (required): the type of data, either 'structured' or 'unstructured'
- source-name (required): the source of the collected data, such as cve, nvd, maxmind, cpe, argus, hone.
- data-name (optional): the name of the data, such as the hostname of the sensor.
The message options should be:
DeliveryMode: 1, // 1=non-persistent, 2=persistent
Timestamp: time.Now(),
ContentType: "text/plain",
ContentEncoding: "",
Priority: 1, // 0-9
HasContent: true, // boolean
Body: <payload>,
DeliveryMode should be 'persistent'.
Timestamp should be automatically filled out by your amqp client library. If not, the publisher should specify.
ContentType should be "text/xml" or "text/csv" or "application/json" or "text/plain" (i.e. collectorType from the output format). This is dependent on the data source.
ContentEncoding may be required if things are, for example, gzipped.
Priority is optional.
HasContent is an application-specific part of the message header that defines whether or not there is content as part of the message. It should be defined in the message header field table using a boolean: HasContent: true (if there is data content) or HasContent: false (if the document service has the content). The spout will use the document service accordingly. This is the only application-specific data needed.
Body is the payload, either the document itself or the id if HasContent is false.
The corresponding binding keys for the queue defined in the spout will can use the wildcards to determine which spout should handle which messages:
-
- (star) can substitute for exactly one word.
For example, stucco.in.# would listen for all input.
There are two types of output messages: (1) messages with data and (2) messages without data that reference an ID in the document store.
The message queue accepts input (documents) from the collectors and pushes the documents into the processing pipeline. The message queue is implemented with RabbitMQ, which implements the AMQP standard.
The queue should hold messages until they have been processed by the Storm Spout.
Input and output protocol is AMQP 0-9-1.
The message queue should pass on the data as is from collectors.
RT is the Real-time processing component of Stucco implemented as a Storm cluster.
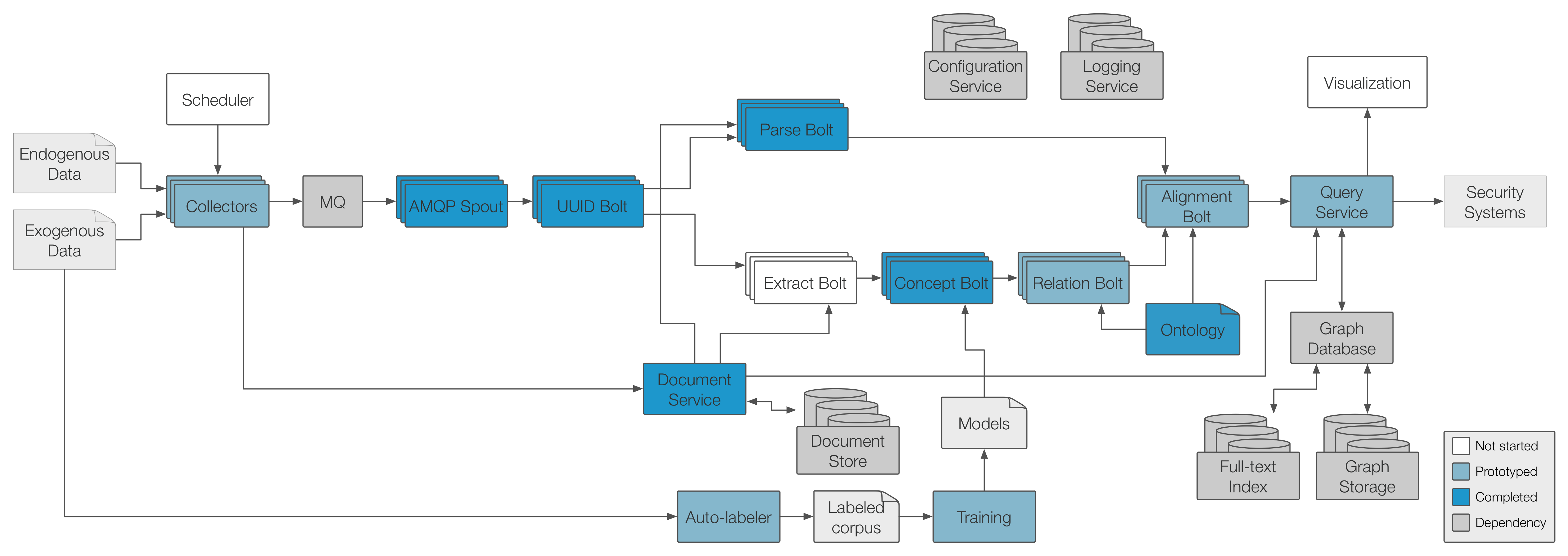
This diagram shows how all the RT components are connected. The diagram at the very top shows how RT connects to the other components described in this document.
If the data it receives is not already included in the document store, it will be added.
The data it receives will be transformed into a graph, consistent with the ontology definition, and then added into graph store.
The spout will send an acknowledgement to the queue when the messages are received, so that the queue can release these resources.
RT will also add the raw documents it receives to the document store if needed.
RT may add additional intermediate output (eg. partially labeled text documents) to the document store if needed.
The AMQP spout pulls messages off the queue and uses the routing key contained in the message to push it to the appropriate UUID Bolt.
Advanced Message Queuing Protocol (AMQP)
JSON object with the following fields:
-
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise
The UUID bolt generates and appends a universally unique identifier (UUID) to the message tuples.
The UUID is generated by computing a SHA-1 hash of the input string so that the UUID is deterministic based on the input.
JSON object with the following fields:
-
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise
The Parse bolt parses a structured document and produces its corresponding subgraph.
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
graph(string) - the GraphSON version of the structured document -
timestamp(long) - the timestamp indicating when the message was collected
The Extract bolt extracts an unstructured document's content either from the message, or by requesting the document from the document-service. The document content is then passed to bolts that can find domain-specific concepts.
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise -
text(string) - the extracted text, if the original data was included in the message; the document id for the extracted text within the document service, otherwise
The Concept bolt finds domain-specific concepts within unstructured text.
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise -
text(string) - the extracted text, if the original data was included in the message; the document id for the extracted text within the document service, otherwise
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise -
text(string) - the extracted text, if the original data was included in the message; the document id for the extracted text within the document service, otherwise -
concepts(string) - JSON object representing the domain-specific concepts
The Relation bolt discovers relationships between the concepts and constructs a subgraph of this knowledge.
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
source(string) - the routing key -
timestamp(long) - the timestamp indicating when the message was collected -
contentIncl(boolean) - indicates if the data is included in the message -
message(string) - the data, if included in the message; the document id to retrieve the data, otherwise -
text(string) - the extracted text, if the original data was included in the message; the document id for the extracted text within the document service, otherwise -
concepts(string) - JSON object representing the domain-specific concepts
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
graph(string) - the GraphSON representation of the unstructured document's concepts (nodes) and relationships (edges) -
timestamp(long) - the timestamp indicating when the message was collected
The Alignment bolt aligns and merges the new subgraph into the full knowledge graph.
JSON object with the following fields:
-
uuid(string) - the hash value of the message -
graph(string) - the GraphSON subgraph representing a document -
timestamp(long) - the timestamp indicating when the message was collected
HTTP/REST
GraphSON subgraph representing a document
The document-service stores and makes available the raw documents. The backend storage is on the local filesystem.
Be sure to set the content-type of the HTTP header when adding documents to the appropriate type (e.g. content-type: application/json for JSON data or content-type: application/pdf for PDF files.
Routes:
- PUT
server:port/document- add a document and autogenerate an id - PUT
server:port/document/id- add a document with a specific id
The accept-encoding can be set to gzip to compress the communication (i.e., accept-encoding: application/gzip).
The accept command can be one of the following: application/json, text/plain, or application/octet-stream. Use application/octet-stream for PDF files and other binary data.
Routes:
- GET
server:port/document/id- retrieve a document based on the specific id
HTTP.
HTTP.
JSON.
The Query Service provides the API for the Graph Store to allow the Alignment bolt, the Visualization/UI, and any third-party applications to interface with the graph database, implemented in Titan.
This API provides a GraphSON interface over HTTP.
The API will provide functions that facilitate common operations (eg. get a node by ID) and also allow arbitrary Gremlin queries. (As the API matures, the use of arbitrary Gremlin queries will be removed or restricted to the Alignment bolt only.)
The API will be implemented with Rexter and a set of Rexter Extensions.
-
host:port/graphs/graph/type/<typename>
Returns a list of all nodes of type<typename> -
host:port/graphs/graph/node/<nodename>
Returns the node with the specified<nodename> -
host:port/graphs/graph/tp/gremlin?<gremlinquery>
Runs the given<gremlinquery>and returns any results
HTTP.
GraphSON.
The configuration service hosts configuration information for all services. It is implemented in etcd.
The etcd configuration is described here. The default stucco configuration is loaded into etcd when instantiated by the config-loader. The default stucco configuration, stucco.yml is in the config repo; edit that file to have the configuration changes loaded. The nested configuration in the stucco.yml gets translated to the url path, so,
stucco
document-service
port
Would be accessible using the following URL: http://127.0.0.1:4001/v2/keys/stucco/document-service/port.
To communicate with the configuration service, either use HTTP or use a client library that supports version 2. There is also a command line client. To test with HTTP, use curl:
curl -L http://127.0.0.1:4001/v2/keys/mykey -XPUT -d value="this is awesome"
curl -L http://127.0.0.1:4001/v2/keys/mykey
HTTP/REST or using client library.
JSON (for HTTP), or specific to the client library used.
JSON (for HTTP), or specific to the client library used.
HTTP/REST or using client library.
The logging service collects and aggregates logs from each of the components. The log server is implemented as a logstash server with an elasticsearch backend.
Sending logs to the server should be done via the TCP input plugin. The port number for the development environment can be found in the logstash configuration section of the Vagrantfile.
The Vagrant VM is set up with a logstash server to aggregate log files. Log files can be input in multiple ways. There is a simple configuration set up in the Vagrantfile. The easiest way to send logs is to send them over a TCP connection. For an example in node.js and python, see https://gist.github.com/jgoodall/6323951
TCP.
JSON. The log message should be a stringified JSON object with the log message in the @message field. Optionally, an array of tags can be added to the @tags field. Additional fields can be added as an object to the @fields field as key-value pairs.
To view the logs, use HTTP with a web browser. The web interface to logstash is implemented by kibana (v3). For the kibana port number in the development environment, see webserver_port in the kibana configuration section of the Vagrantfile.