This repository contains the code for ACL2021 paper: Keep It Simple: Unsupervised Simplification of Multi-Paragraph Text.
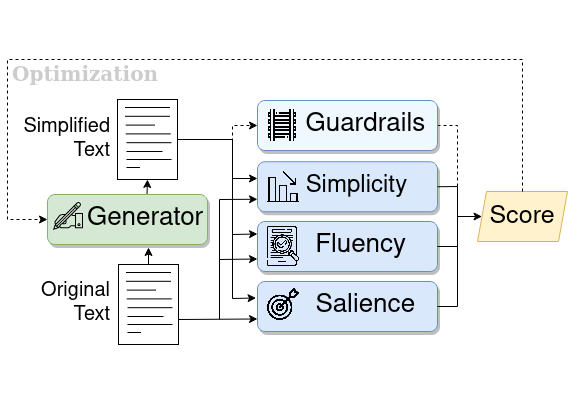
The easiest way to use the model is through the hosted Hub model: https://huggingface.co/philippelaban/keep_it_simple The basic use would be:
tokenizer = AutoTokenizer.from_pretrained("philippelaban/keep_it_simple")
kis_model = AutoModelForCausalLM.from_pretrained("philippelaban/keep_it_simple")
See the model card for a detailed example.
To simplify text with a trained model, an example script is provided:
python run_keep_it_simple.py --model_card gpt2-medium --model_file /home/phillab/models/ACL2021/gpt2_med_keep_it_simple.bin
The script outputs several candidate simplifications for a given input paragraph, emphasizing the insertions and deletions made by the model using color (green, red).
In the Keep it Simple Release, we provide a model checkpoint we trained using the Keep it Simple procedure that achieves a high-average reward on news paragraphs: gpt2_med_keep_it_simple.bin (this is identical to the model card on the HuggingFace Hub).
The requirements.txt provides the list of pip packages required to use and train models.
One must also install a spaCy model:
python -m spacy download en_core_web_sm
Must also manually install the apex library, used for mixed-precision training (see: https://github.com/nvidia/apex), as it is not avaiable on pip.
For training, two pre-trained models are needed, which we provide in the Keep it Simple Release:
coverage_roberta.bin: A model compatible with aroberta-baseof the Roberta HuggingFace implementation, used for the salience scorer (coverage model).gpt2_med_cp90.bin: A model compatible with agpt2-mediumof the GPT2 HuggingFace implementation, used as the initial model for the generator.
Once the packages are installed, and the models are downloaded, the training script can be run:
python train_keep_it_simple.py --experiment initial_run --model_start_file /path/to/gpt2_med_cp90.bin
See the script for additional hyper-parameters. With the default hyperparameters provided, the script should converge within 16-24 hours to a model achieving a strong (yet not optimal) score, when trained using a single V-100 or equivalent.
The provided training script uses CCNews as a rudimentary demonstration dataset, and was not the one used to obtain results in our experiments (we use a larger news corpus that we cannot release due to copyright). We recommend replacing CCNews with in-domain data for better results.
To ease with debugging and reproducibilty, we release the log of an example training run of Keep it Simple. It can be accessed as a view-only Wandb report.
The /study_interface folder contains details from the usability, including: the HTML / Javascript used during the study, as well as all the data simplification_user_study.json used during the study, including all model candidate simplifications, the comprehension questions used and distractors.
If you make use of the code, models, or algorithm, please cite our paper:
@inproceedings{laban2021keep_it_simple,
title={Keep It Simple: Unsupervised Simplification of Multi-Paragraph Text},
author={Philippe Laban and Tobias Schnabel and Paul N. Bennett and Marti A. Hearst},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics},
volume={1},
year={2021}
}
If you'd like to contribute, or have questions or suggestions, you can contact us at [email protected]. All contributions welcome! For example, if you have a type of text data on which you want to apply Keep it Simple.