维基百科语料下载地址 : dumps.wikimedia.org/zhwiki
有很多链接,下载比如 https://dumps.wikimedia.org/zhwiki/20200701/zhwiki-20200701-pages-articles.xml.bz2
然后,用如下命令安装 txtcn_wiki ( 请用 python3 的 pip,有些系统上直接是 pip3)
pip install txtcn_wiki
安装成功后,用如下方式即可抽取。
txtcn_wiki /share/wiki/zhwiki-20200701-pages-articles.xml.bz2
小技巧:维基百科打包打包很大,但是不需要完全下载也可以运行以上命令(会报错,但能部分输出)。
会在bz2的同目录输出两个文件
- 条目正文:zhwiki-20200701-pages-articles.title.txt.zd
- 条目标题:zhwiki-20200701-pages-articles.txt.zd
.zd文件是Zstandard压缩后的纯文本文件 ( 参见 Zstandard - Real-time data compression algorithm )
使用本软件包附带的 zdcat 命令可以查看, 比如:
zdcat /share/wiki/zhwiki-20200701-pages-articles.title.txt.zd
在条目正文中,条目的标题以 "➜ " 开头。
在程序中读取zd文件,可用如下方法(zd可以单独安装,比如pip install zd,源码见gitee.com/znlp/zd)
import zd
with zd.open(
"/share/wiki/zhwiki-20200701-pages-articles.txt.zd"
) as f:
for i in f:
print(i)
如使用有问题请到 github.com/txtcn/wiki 发帖。
代码改编自 《获取并处理中文维基百科语料 - 科学空间|Scientific Spaces》
网上有一些中文语料库,但是居然都不是自动更新的。
是可忍,孰不可忍。我想自动挖掘研究市场热点炒股票,没有新数据搞毛线。
于是,有了这个项目 : 《中文语料库-每日自动更新版》。
核心思想,通过RSS订阅,存档内容。
然后通过GitHub Actions来实现每日运行,这样就实现了一个无服务器的自动更新语料库。
2. 谷歌浏览器实用插件:六度空间 · 短链接
可以生成短链接(短网址)、二维码,一键复制标题和链接。
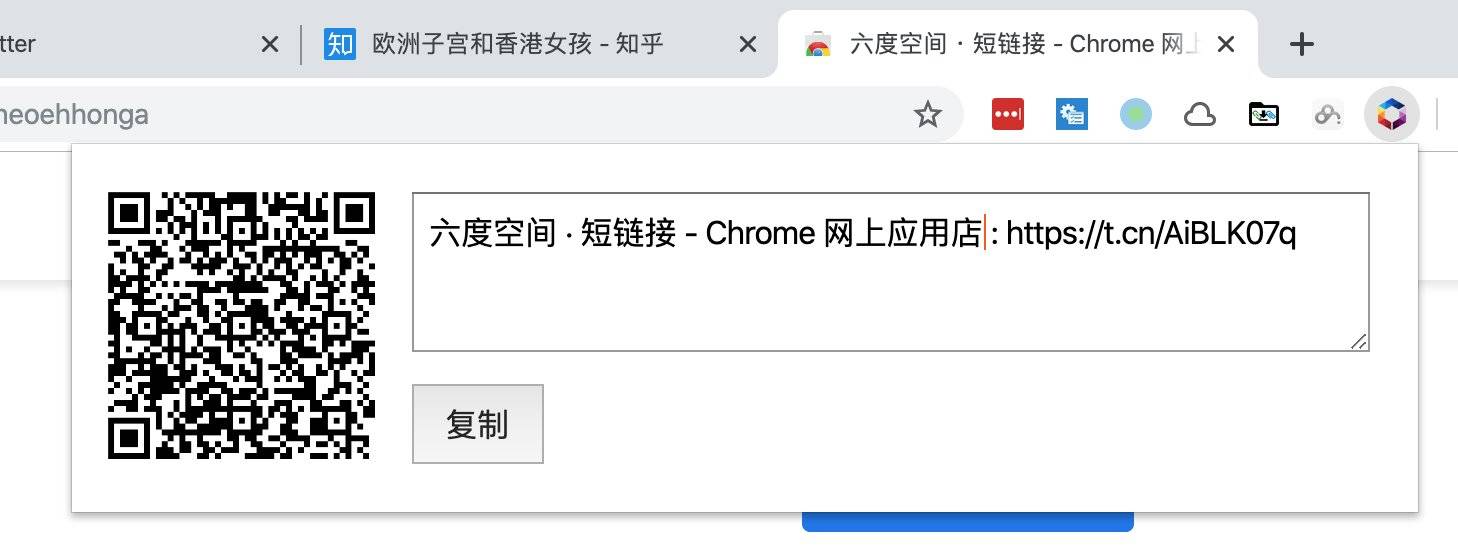
现有的chrome插件,没有一个能自动复制并带上标题的,所以自己写了一个,很实用,欢迎试用。
安装地址:Chrome 网上应用店
如果没法访问Chrome网上应用店,可以按照以下步骤安装。
点击这里下载源码 ,并解压
在Chrome浏览器中输入 chrome://extensions ,并开启开发者模式(点击右上角)
点击「加载已解压的扩展程序」选择刚刚解压的目录。
这是开源项目,欢迎参与改进。
张沈鹏 ,欢迎扫码关注我的微信公众号。
