___________ ___________.__.__
\__ ___/____\_ _____/|__| | ____
| | / ___/| __) | | | _/ __ \
| | \___ \ | \ | | |_\ ___/
|____|/____ >\___ / |__|____/\___ > version 1.0.0
\/ \/ \/
TsFile is a columnar storage file format designed for time series data, which supports efficient compression, high throughput of read and write, and compatibility with various frameworks, such as Spark and Flink. It is easy to integrate TsFile into IoT big data processing frameworks.
Time series data is becoming increasingly important in a wide range of applications, including IoT, intelligent control, finance, log analysis, and monitoring systems.
TsFile is the first existing standard file format for time series data. Despite the widespread presence and significance of temporal data, there has been a longstanding absence of standardized file formats for its management. The advent of TsFile introduces a unified file format to facilitate users in managing temporal data.
TsFile offers several distinctive features and benefits:
-
Multi Language Independent Use: Multiple language SDK can be used to directly read and write TsFile, making it possible for some lightweight data reading and writing scenarios.
-
Efficient Writing and Compression: A column storage format tailored for time series, organizing data by device and ensuring continuous storage of data for each sequence, minimizing storage space. Compared to CSV, the compression ratio can be increased by more than 90%.
-
High Query Performance: By indexing devices, measurement, and time dimensions, TsFile implements fast filtering and querying of temporal data based on specific time ranges. Compared to general file formats, query throughput can be increased by 2-10 times.
-
Open Integration: TsFile is the underlying storage file format of the temporal database IoTDB, which can form a pluggable storage computing separation architecture with IoTDB. TsFile supports compatibility with Spark Flink and other big data software establish seamless ecosystem integration to ensure compatibility and interoperability across different data processing environments, and achieve deep analysis of temporal data across ecosystems.
TsFile can manage the time series data of multiple devices. Each device can have different measurement.
Each measurement of each device corresponds to a time series.
The TsFile Scheme defines a set of measurement for all devices, as shown in the table below (m1~m5)
| Time | deviceId | m1 | m2 | m3 | m4 | m5 |
|---|---|---|---|---|---|---|
| 1 | device1 | 1 | 2 | 3 | ||
| 2 | device1 | 1 | 2 | 3 | ||
| 3 | device2 | 1 | 3 | 4 | 5 | |
| 4 | device2 | 1 | 3 | 4 | 5 | |
| 5 | device3 | 1 | 2 | 3 | 4 | 5 |
Among them, Time and deviceId are built-in fields that do not need to be defined and can be written directly.
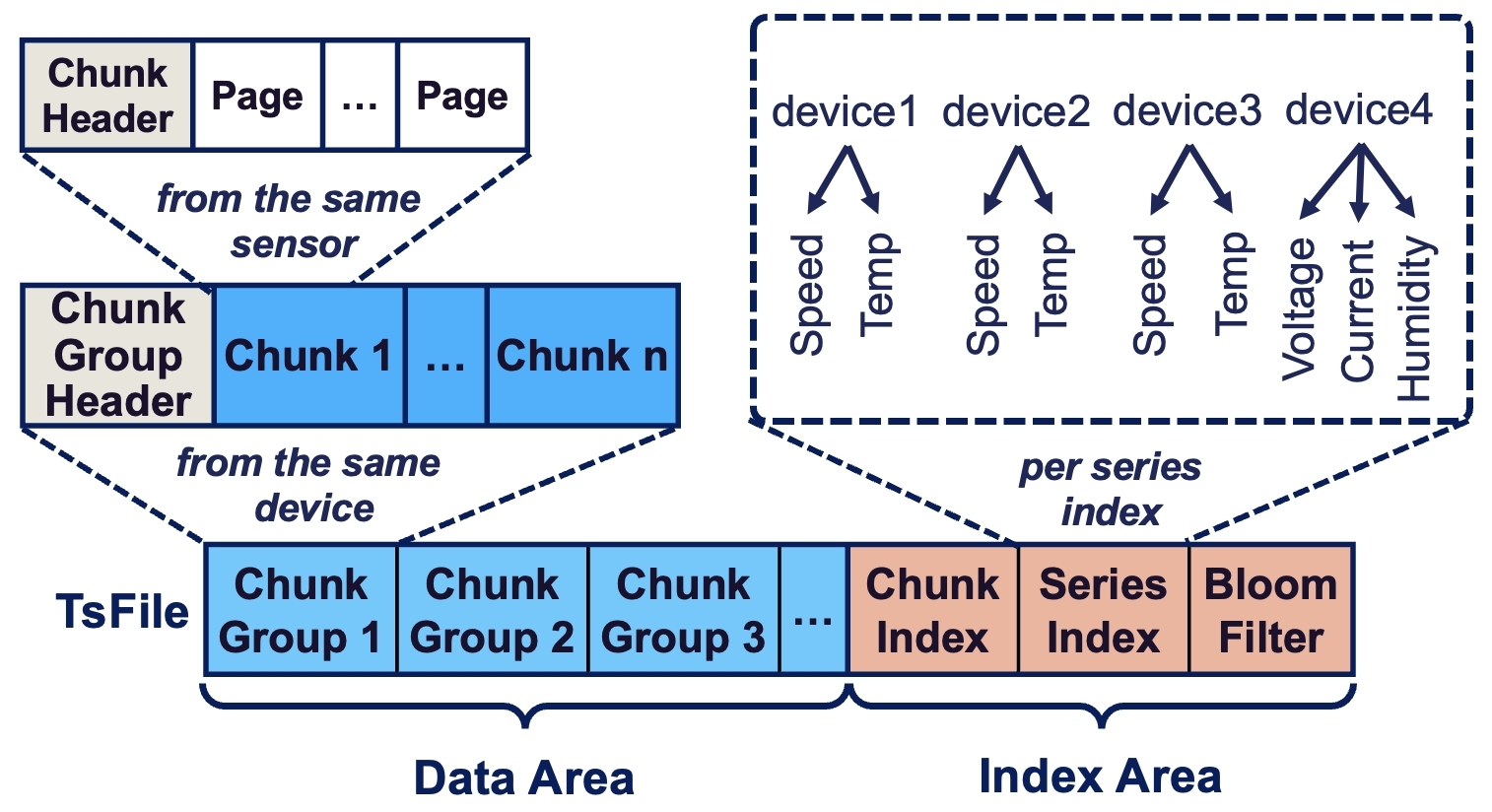
TsFile adopts a columnar storage design, similar to other file formats, primarily to optimize time-series data's storage efficiency and query performance. This design aligns with the nature of time series data, which often involves large volumes of similar data types recorded over time. However, TsFile was developed particularly with a structure of page, chunk, chunk group, and index:
-
Page: The basic unit for storing time series data, sorted by time in ascending order with separate columns for timestamps and values.
-
Chunk: Comprising metadata headers and several pages, each chunk belongs to one time series, with variable sizes allowing for different compression and encoding methods.
-
Chunk Group: Multiple chunks within a chunk group belong to one or multiple series of a device written in the same period, facilitating efficient query processing.
-
Index: The file metadata at the end of TsFile contains a chunk-level index and file-level statistics for efficient data access.
TsFile employs advanced encoding and compression techniques to optimize storage and access for time series data. It uses methods like run-length encoding (RLE), bit-packing, and Snappy for efficient compression, allowing separate encoding of timestamp and value columns for better data processing. Its unique encoding algorithms are designed specifically for the characteristics of time series data in IoT scenarios, focusing on regular time intervals and the correlation among series.
Its uniqueness lies in the encoding algorithm designed specifically for time series data characteristics, focusing on the correlation between time attributes and data.
The table below compares 3 file formats in different dimensions.
TsFile, CSV and Parquet in Comparison
| Dimension | TsFile | CSV | Parquet |
|---|---|---|---|
| Data Model | IoT | Plain | Nested |
| Write Mode | Tablet, Line | Line | Line |
| Compression | Yes | No | Yes |
| Read Mode | Query, Scan | Scan | Query |
| Index on Series | Yes | No | No |
| Index on Time | Yes | No | No |
Its development facilitates efficient data encoding, compression, and access, reflecting a deep understanding of industry needs, pioneering a path toward efficient, scalable, and flexible data analytics platforms.
| Data Type | Recommended Encoding | Recommended Compression |
|---|---|---|
| INT32 | TS_2DIFF | LZ4 |
| INT64 | TS_2DIFF | LZ4 |
| FLOAT | GORILLA | LZ4 |
| DOUBLE | GORILLA | LZ4 |
| BOOLEAN | RLE | LZ4 |
| TEXT | DICTIONARY | LZ4 |
more see Docs