


Neural Machine Translation with Keras (+ Theano backend).
Library documentation: nmt-keras.readthedocs.io
If you use this toolkit in your research, please cite:
@misc{nmt-keras2017,
author = {Peris, {\'A}lvaro},
title = {{NMT}-{K}eras},
year = {2017},
publisher = {GitHub},
note = {GitHub repository},
howpublished = {\url{https://github.com/lvapeab/nmt-keras}},
}
- Online learning and Interactive neural machine translation (INMT). See the interactive NMT branch.
- Attention model over the input sequence of annotations.
- ❗ Also supports double stochastic attention (Eq. 14 from arXiv:1502.03044)
- Peeked decoder: The previously generated word is an input of the current timestep.
- Beam search decoding.
- Ensemble decoding (sample_ensemble.py).
- Featuring length and source coverage normalization (reference).
- Translation scoring (score.py).
- Support for GRU/LSTM networks:
- Regular GRU/LSTM units.
- Conditional GRU/LSTM units in the decoder.
- Multilayered residual GRU/LSTM networks (and their Conditional version).
- N-best list generation (as byproduct of the beam search process).
- Unknown words replacement (see Section 3.3 from this paper)
- Use of pretrained (Glove or Word2Vec) word embedding vectors.
- MLPs for initializing the RNN hidden and memory state.
- Spearmint wrapper for hyperparameter optimization.
Assuming that you have pip installed, run:
git clone https://github.com/lvapeab/nmt-keras
cd nmt-keras
pip install -r requirements.txtfor obtaining the required packages for running this library.
NMT-Keras requires the following libraries:
- Our version of Keras (Recommended v. 2.0.6 or newer)
- Multimodal Keras Wrapper (v. 2.0 or newer) (Documentation and tutorial)
- Coco-caption evaluation package (Only required to perform evaluation)
-
Set a training configuration in the
config.pyscript. Each parameter is commented. See the documentation file for further info about each specific hyperparameter. You can also specify the parameters when calling themain.pyscript following the syntaxKey=Value -
Train!:
python main.py
Once we have our model trained, we can translate new text using the sample_ensemble.py script. Please refer to the ensembling_tutorial for more details about this script.
In short, if we want to use the models from the first three epochs to translate the examples/EuTrans/test.en file, just run:
python sample_ensemble.py
--models trained_models/tutorial_model/epoch_1 \
trained_models/tutorial_model/epoch_2 \
--dataset datasets/Dataset_tutorial_dataset.pkl \
--text examples/EuTrans/test.enThe score.py script can be used to obtain the (-log)probabilities of a parallel corpus. Its syntax is the following:
python score.py --help
usage: Use several translation models for scoring source--target pairs
[-h] -ds DATASET [-src SOURCE] [-trg TARGET] [-s SPLITS [SPLITS ...]]
[-d DEST] [-v] [-c CONFIG] --models MODELS [MODELS ...]
optional arguments:
-h, --help show this help message and exit
-ds DATASET, --dataset DATASET
Dataset instance with data
-src SOURCE, --source SOURCE
Text file with source sentences
-trg TARGET, --target TARGET
Text file with target sentences
-s SPLITS [SPLITS ...], --splits SPLITS [SPLITS ...]
Splits to sample. Should be already includedinto the
dataset object.
-d DEST, --dest DEST File to save scores in
-v, --verbose Be verbose
-c CONFIG, --config CONFIG
Config pkl for loading the model configuration. If not
specified, hyperparameters are read from config.py
--models MODELS [MODELS ...]
path to the models
Other features such as online learning or interactive NMT protocols are implemented in the interactiveNMT branch.
-
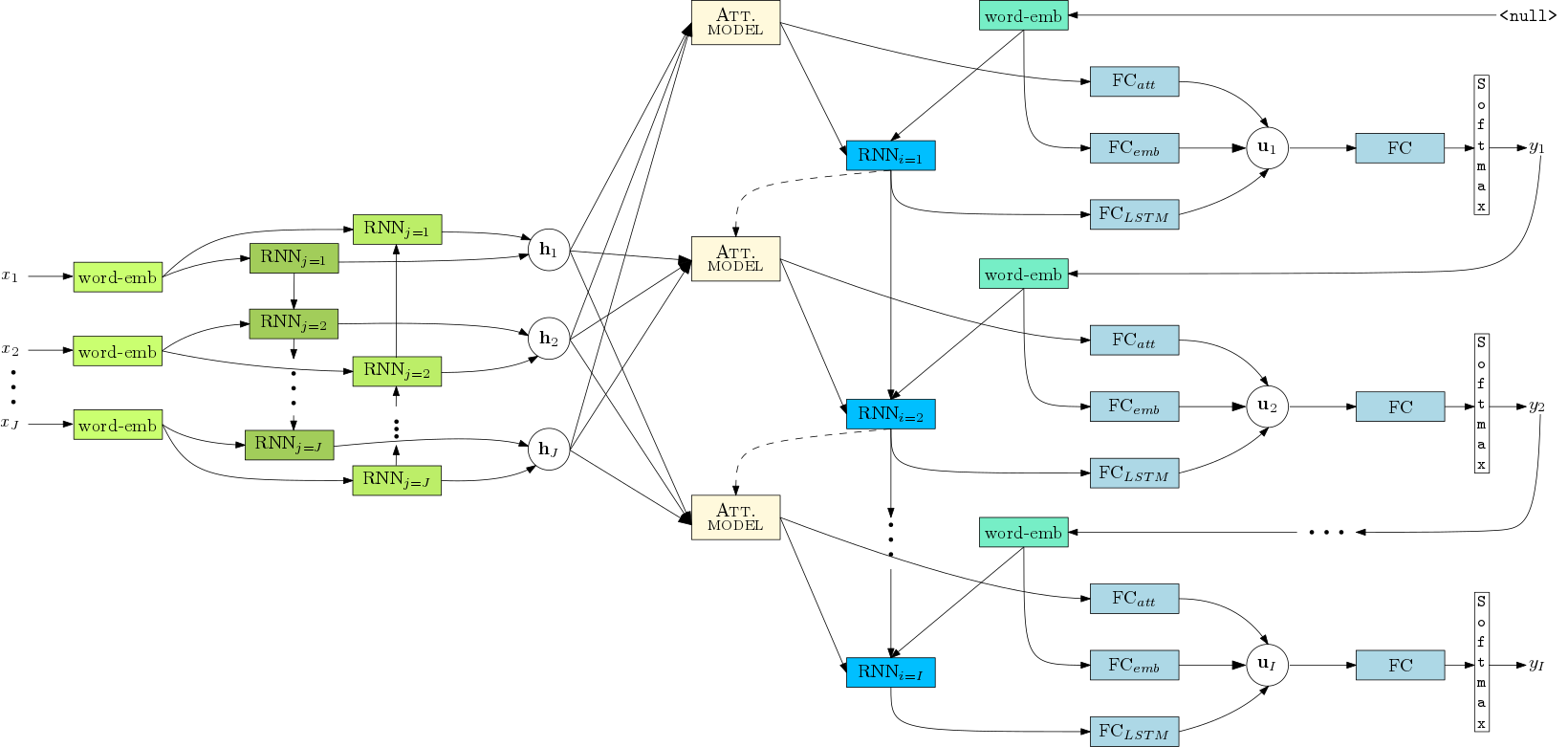
In examples/documentation/neural_machine_translation.pdf you'll find an overview of an attentional NMT system.
-
In the examples folder you'll find some tutorials for running this library. They are expected to be followed in order:
-
Dataset set up: Shows how to invoke and configure a Dataset instance for a translation problem.
-
Training tutorial: Shows how to call a translation model, link it with the dataset object and construct calllbacks for monitorizing the training.
-
Decoding tutorial: Shows how to call a trained translation model and use it to translate new text.
-
NMT model tutorial: Shows how to build a state-of-the-art NMT model with Keras in few (~50) lines.
-
Much of this library has been developed together with Marc Bolaños (web page) for other sequence-to-sequence problems.
To see other projects following the philosophy of NMT-Keras, take a look here:
TMA for egocentric captioning based on temporally-linked sequences.
VIBIKNet for visual question answering.
ABiViRNet for video description.
Sentence SelectioNN for sentence classification and selection.
Álvaro Peris (web page): [email protected]