Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data
As a premier global online shopping community, Poizon is grappling with notable technical challenges due to its expanding user base and data growth. Currently, Poizon's observability platform produces petabytes of Trace data and trillions of Span records daily, necessitating proficient real-time processing capabilities and cost-efficient data storage solutions.
The conventional compute-storage unified architecture integrates compute and storage resources, exhibiting challenges when data scale escalates:
-
**Scalability Constraints: ** Compute and storage resources lack independent scalability, driving synchronized expansion and potentially escalating costs.
-
**Low resource utilization: ** The inability to dynamically adjust compute and storage resources results in wasted idle resources.
-
**Operational Complexity: ** The process of scaling clusters in and out, which includes intricate resource migration, elevates the operational challenge.
To address these challenges, Poizon's observability platform implemented a compute-storage separation architecture. It utilized AutoMQ, Kafka, and ClickHouse storage technology to achieve efficient resource management and performance optimization.
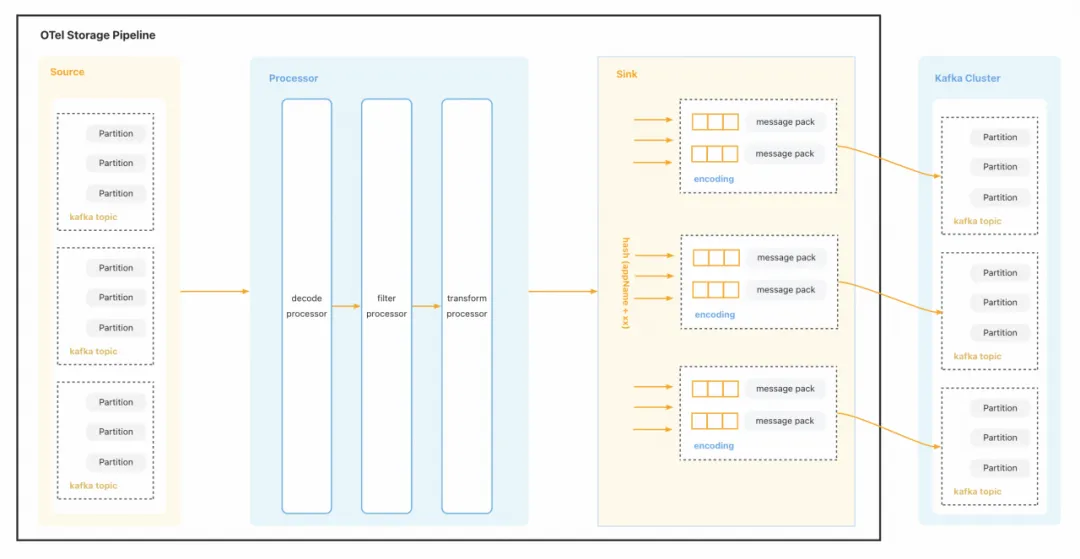
Apache Kafka serves as the vital data link in the field of physical observatory business.
In Poizon's observability platform, Apache Kafka plays a critical role in data collection, processing, and distribution. Yet, as business data volume escalates, Kafka's architecture reveals several challenges:
-
**Elevated Storage Costs: ** The storage component of Kafka significantly contributes to cloud resource expenditures (exhibiting a computing-to-storage cost ratio of 1:3). To manage expenses, adjustments have been made to Kafka's data TTL and replica configurations, yet storage costs persist at a high level.
-
Performance bottleneck in cold-read scenarios : Disk throughput often hits its maximum capacity in these instances, resulting in reduced efficiency.

Poizon Kafka High Risk Disk Alarm
- Operational Complexity Escalation: Cluster expansion amplifies the complexity of scaling Kafka clusters, thereby elevating operational risks.
The observed challenges arise from Kafka's native architecture constraints, notably its Shared-Nothing design tailored for IDC environments. This architecture faces difficulties meeting the elasticity and scalability requirements typical of the cloud computing era.
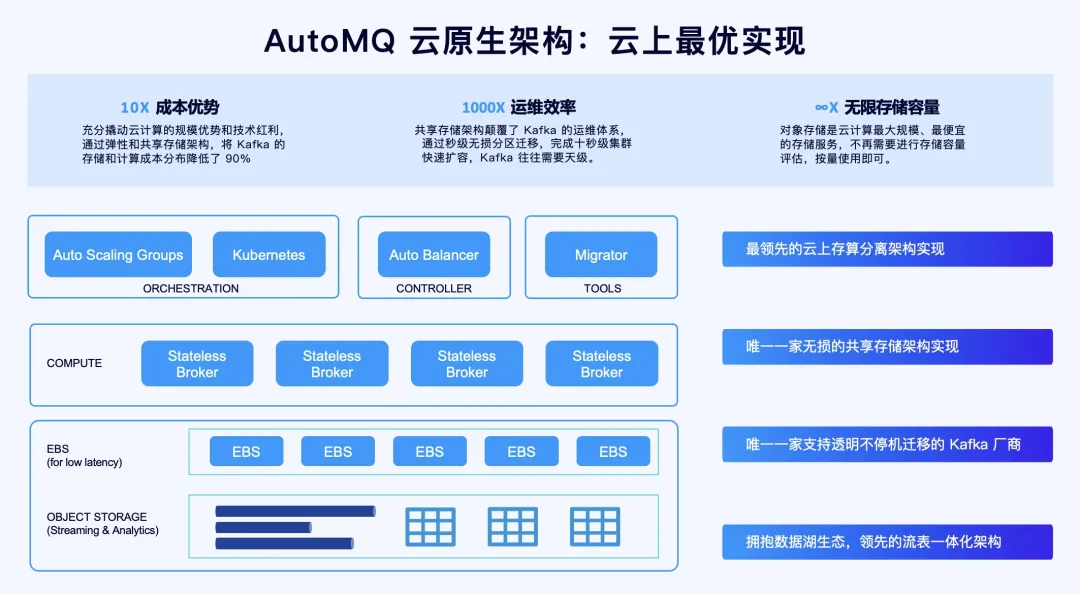
AutoMQ Cloud Native Architecture
To tackle Kafka's large-scale data processing challenges, the Observable Platform has opted for AutoMQ as an alternative. AutoMQ's benefits encompass:
-
**Kafka Protocol Compatibility: ** AutoMQ ensures seamless migration with full compatibility with Kafka clients and ecosystem tools, eliminating the need for extensive modifications.
-
Storage-Compute Decoupling Architecture: Through the disentanglement of storage and compute, AutoMQ has pioneered an innovative shared stream storage library, S3Stream[1], leveraging object and EBS storage. This novel approach supersedes Apache Kafka's existing storage layer, drastically diminishing storage expenditures and facilitating autonomous scalability of storage and compute.
-
**Elastic scalability: ** AutoMQ enables dynamic resource modification, negating the need for data migration or downtime, thus enhancing resource efficiency.
-
**Scalability for future growth: ** AutoMQ accommodates expansion in large-scale data volumes and seamlessly integrates with cutting-edge storage and compute resources to cater to evolving needs.
In cold reading scenarios, Apache Kafka encounters notable performance challenges. The KAFKA-7504 issue can cause cold read operations to disrupt real-time writing, drastically diminishing cluster throughput at times. AutoMQ has implemented optimizations for this issue as follows:
-
Storage and Computation Isolation: This complete disassociation between storage and computation safeguards write performance from being impacted by cold reads.
-
Optimized Query Performance: AutoMQ ensures stable cold read performance, even under high concurrency situations, through advanced query optimization.
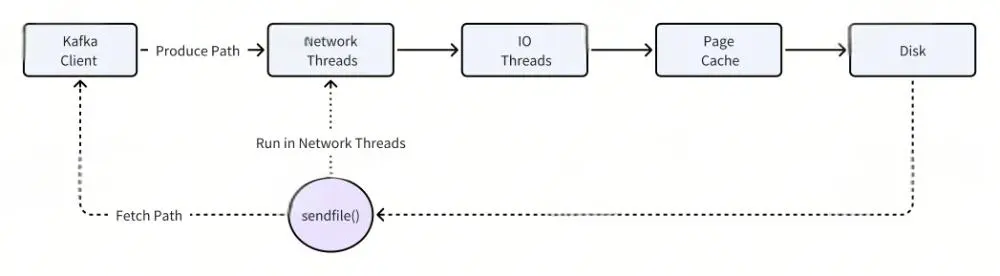
- Read-Write I/O Path of Apache Kafka*
Apache Kafka optimizes read-write operations utilizing two pivotal technologies: Page Cache and zero-copy SendFile system calls.
-
Page Cache streamlines memory management for Kafka, with complete oversight by the kernel. However, it has the limitation of not differentiating between hot and cold data. In scenarios where a service consistently conducts cold reads, memory resources are contested with hot data, resulting in a continuous drop in tail read capability.
-
SendFile, instrumental for Kafka's zero-copy mechanism, operates within Kafka's network thread pool. Should SendFile require disk data copying (in a cold read scenario), it can potentially block this thread pool. Given that this thread pool serves as the entry point for Kafka requests, inclusive of write requests, any blockage by SendFile can substantially impair Kafka's write operations.
Under identical load and machine conditions, AutoMQ delivers cold read performance on par with Kafka, without impacting write throughput and latency[5].

In cold-read situations, AutoMQ substantially improves performance, boosting cold-read efficiency about 5-fold compared to Kafka, without affecting real-time write operations.
Observable platform's business traffic exhibits prominent peak-valley variations. AutoMQ, utilizing a compute-storage separation architecture, demonstrates exceptional elasticity in dynamic scaling.
-
**Swift Scale-Out: ** During business peaks, it enables rapid expansion of storage or compute resources, maintaining optimal system performance.
-
**Intelligent Scale-in: ** Post-peak, it promptly reclaims idle resources, minimizing waste and operational load.
AutoMQ's scalability harnesses second-level partition migration technology[6]. When expanding, partitions migrate in batches to fresh nodes through Auto Scaling Groups (ASG)[7] or Kubernetes HPA, accomplishing swift traffic balancing, generally within seconds. During contraction, partitions from nodes slated for offlining quickly relocate to other nodes, achieving near-instantaneous offlining.
AutoMQ, leveraging shared storage architecture, enhances scalability efficiency and prevents data rebalancing[9], unlike Apache Kafka that requires data duplication for scalability. This denotes a significant divergence from Apache Kafka's approach.
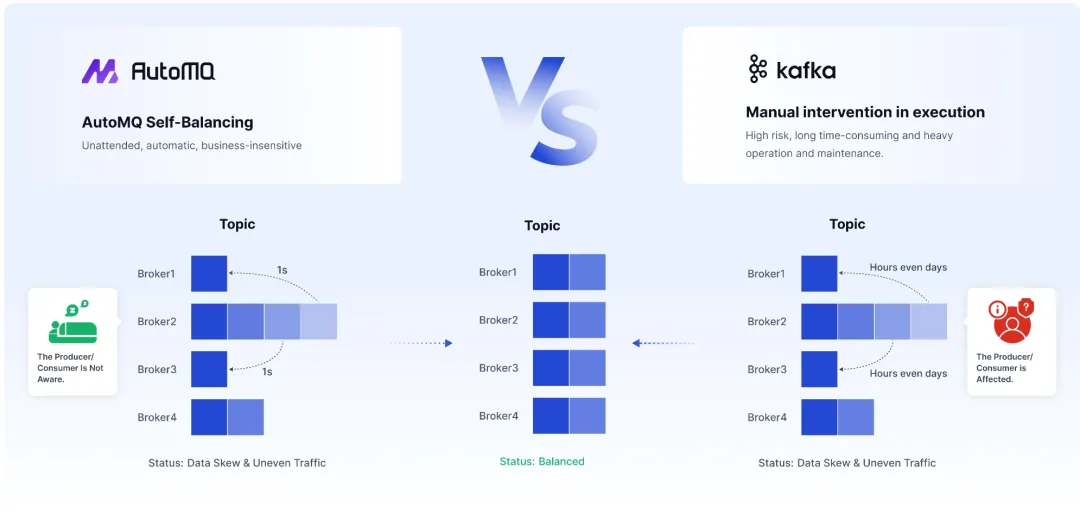
AutoMQ Automatic Traffic Rebalancing vs. Apache Kafka Manual Migration
Case Study
AutoMQ intelligently scales based on cluster traffic and CPU metrics. Upon reaching the scale-up threshold, Broker nodes are automatically added to the system. Conversely, when traffic falls to the scale-down threshold, partitions are seamlessly migrated from the Broker set for offlining to other Brokers. This round-robin migration occurs at the second level, ensuring balanced traffic.
Since the introduction of AutoMQ on the Observability platform half a year ago, it has systematically supplanted Apache Kafka's role within the overall observability architecture. The architecture, now anchored by AutoMQ, functions as follows: AutoMQ cluster processes all observability data produced by microservices, further enabling precise lookups and data analysis capabilities leveraging ClickHouse.
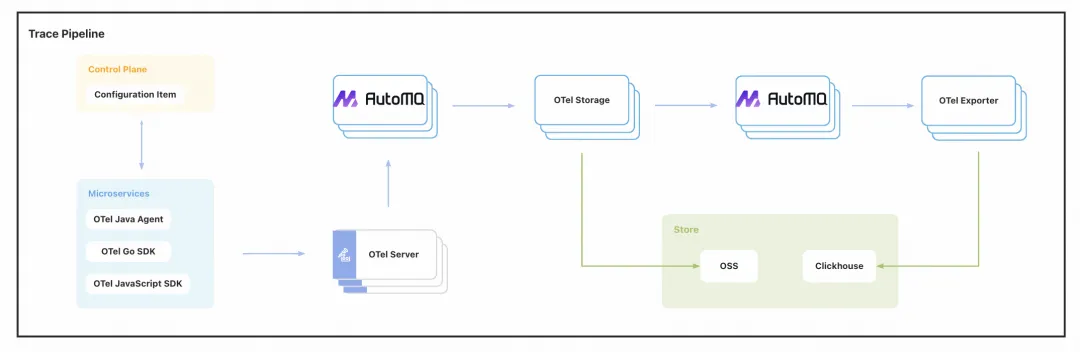
Poizon's Observable Architecture, underpinned by AutoMQ.
AutoMQ has also brought about the following significant results for the observability platform:
-
over 50% year-on-year reduction in cloud billing costs, along with a substantial increase in operational efficiency.
-
Nearly a thousand cores of computing resources have been replaced, achieving an overall throughput of tens of GiB/s.
AutoMQ Implementation Results: Successfully sustained 100% traffic load during the Double Eleven peak period.
Besides substantial cost reduction, AutoMQ architecture played a pivotal role in this year's Double Eleven event, eliminating the necessity for extensive capacity assessment and early expansion operational costs. Since the inception of AutoMQ cluster, it has demonstrated high availability with zero downtime throughout the Double Eleven period, accommodating 100% of the traffic. It maintained stable load even during peak times without any performance volatility. The ensuing diagram illustrates one of the clusters in the AutoMQ setup of Poizon's observable platform, demonstrating GiB-level throughput.

One of the AutoMQ clusters in Poizon at the GiB level.
Poizon effectively mitigated several obstacles associated with large-scale data processing in Apache Kafka by implementing AutoMQ. In real-world use cases, AutoMQ demonstrated substantial benefits on the Poizon observability platform, not only diminishing storage and computational expenses, but also substantially improving resource utilization and operational efficiency. The platform, leveraging AutoMQ's storage-computation separation structure, circumvents Kafka's constraints on scalability, storage costs, and operational intricacy, facilitating dynamic resource modifications and efficient cold read optimization. Amid the peak period of Double 11, AutoMQ's exceptional performance and flexible scaling capacities guaranteed system reliability and steadiness, nullifying the necessity for taxing capacity evaluations and pre-expansion procedures. This technological implementation yielded considerable cost reductions and performance enhancements for Poizon, establishing a robust foundation for anticipated data growth. It also provides invaluable insights and solutions for other enterprises in efficient resource management and performance optimization.
[1]AutoMQ Shared Stream Repository based on S3:https://docs.automq.com/automq/architecture/s3stream-shared-streaming-storage/overview
[2]Source of Kafka's Cold Read Performance Issues:https://issues.apache.org/jira/browse/KAFKA-7504
[3]Linux Page Cache: https://en.wikipedia.org/wiki/Page_cache
[4]Linux SendFile: https://man7.org/linux/man-pages/man2/sendfile.2.html
[5]AutoMQ Performance Whitepaper:https://docs.automq.com/automq/benchmarks/benchmark-automq-vs-apache-kafka
[6]AutoMQ Second-Level Partition Migration:https://docs.automq.com/automq/architecture/technical-advantage/partition-reassignment-in-seconds
[7]AWS Auto Scaling Groups: https://docs.aws.amazon.com/autoscaling/ec2/userguide/auto-scaling-groups.html
[8]HPA Component for Kubernetes Scaling:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
[9]AutoMQ Continuous Data Rebalancinghttps://docs.automq.com/automq/architecture/technical-advantage/continuous-self-balancing