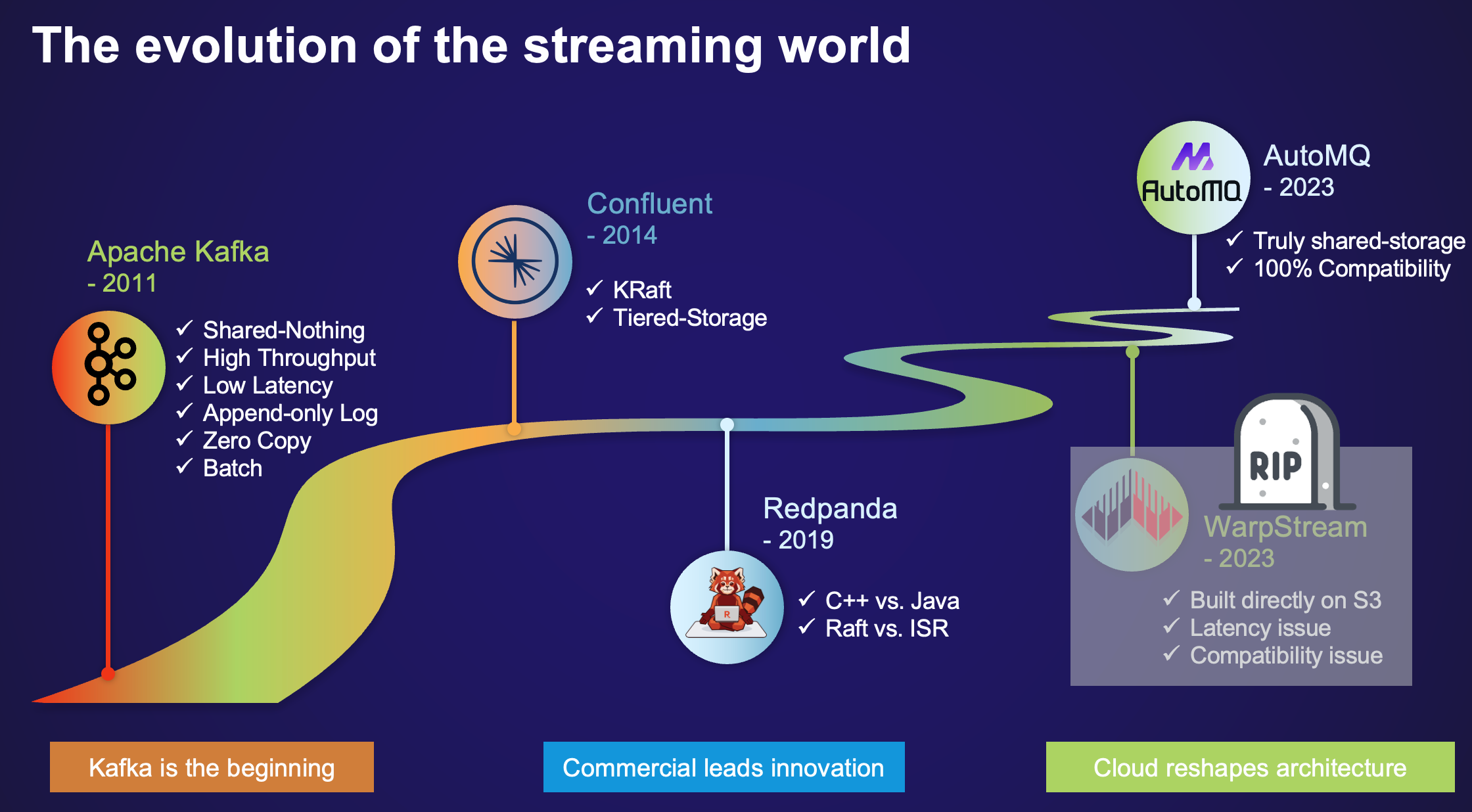
WarpStream is dead, long live AutoMQ
In August 2023, WarpStream made its debut with the blog post "Kafka is dead, long live Kafka"[1] quickly gaining attention in the streaming storage space with its innovative approach. Just a year later, in September 2024, Confluent acquired WarpStream, concluding its journey with the blog post "WarpStream is dead, long live WarpStream"[2]. WarpStream's innovative approach significantly advanced the industry, demonstrating the potential of cloud-native technologies.
Around the same time(October 2023), we at AutoMQ launched our own cloud-native architecture on GitHub[3], aiming to revolutionize Apache Kafka’s deployment on the cloud. Although our architectures have distinct differences, both share a common vision: harnessing cloud-native technologies such as elastic compute (EC2) and shared storage (S3, EBS) to deliver tenfold cost advantages and instantaneous elasticity for Apache Kafka on the cloud.
Understanding what it means to be cloud-native from a SaaS perspective is crucial for leveraging the full potential of cloud computing. At its core, cloud-native SaaS services are defined by how effectively they utilize cloud-based storage and computing resources.
The greatest advantage of cloud computing lies in its economies of scale, which in turn enable elasticity. Data-intensive software fundamentally relies on two pillars: computation and storage. So, what does cloud elasticity mean for these two components?
For computation, AWS's EC2, or Elastic Compute Cloud, exemplifies the power of cloud computing by aggregating vast waves of computational resources. This massive pool of compute power can be accessed on-demand through APIs, effectively providing users with an elastic and seemingly inexhaustible supply of computational resources.
For storage, cloud providers aggregate vast amounts of storage resources into shared storage systems. This approach not only makes object storage services like S3 highly elastic but also provides significant cost advantages due to the shared nature of the infrastructure.
So, what is cloud-native? From the perspective of Kafka, we believe that a cloud-native Kafka offloads its native replicated storage onto shared cloud storage. This transformation renders the brokers stateless, enabling them to scale up or down effortlessly using EC2. In essence, cloud-native Kafka can be defined by the formula:
Cloud-Native Kafka = Elastic Brokers + Shared Cloud Storage
By decoupling storage from the brokers and leveraging the cloud's inherent elasticity, we can achieve unprecedented levels of scalability and cost efficiency for Kafka deployments.
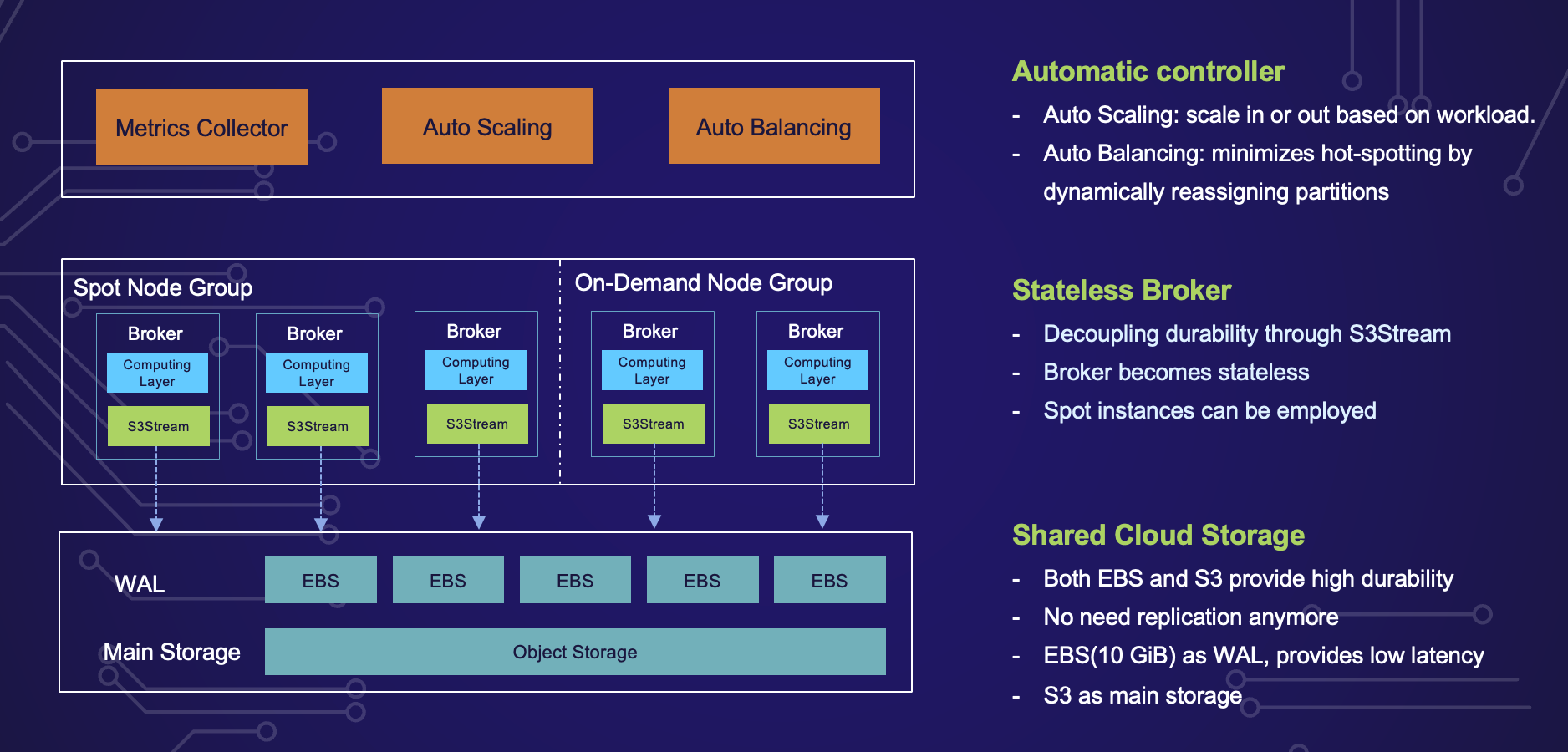
The cloud-native architecture of AutoMQ is a result of careful design decisions, innovative approaches, and the strategic use of cloud storage technologies. We aimed to create a system that could leverage the benefits of the cloud while overcoming the limitations of traditional stream storage solutions.
The first step in realizing the cloud-native architecture of AutoMQ was to decouple durability to cloud storage. Unlike the typical decoupling of storage, where we refer to separating the storage to a distributed and replicated storage software, decoupling durability takes it a step further. In the former case, we are left with two types of clusters that need to be managed, as seen in Apache Pulsar, where you need to manage both the broker cluster and the bookkeeper cluster.
However, AutoMQ has taken a different route, opting to decouple durability to cloud storage, with S3 serving as the epitome. S3 already offers a durability rate of 99.999999999%, making it a reliable choice for this purpose. In the realm of cloud computing, merely decoupling storage is insufficient; we must also decouple durability to cloud storage.
The essence of the Decoupling Durability architecture lies in its reliance on cloud storage for durability, eliminating the need for replication protocols such as Raft. This approach is gaining traction over the traditional Decoupling Storage architecture. Guided by this philosophy, we developed S3Stream, a stream storage library that combines the advantages of EBS and S3.
With S3Stream in place, we replaced the storage layer of the Apache Kafka broker, transforming it from a Shared-Nothing architecture to a Shared-Storage architecture, and in the process, making the Broker stateless. This is a significant shift, as it reduces the complexity of managing the system. In the AutoMQ architecture, the Broker is the only component. Once it becomes stateless, we can even deploy it using cost-effective Spot instances, further enhancing the cost-efficiency of the system.
The final step in realizing the cloud-native architecture of AutoMQ was to automate everything to achieve an elastic architecture. Once AutoMQ became stateless, it was straightforward to automate various aspects, such as auto-scaling and auto-balancing of traffic.
We have two automated controllers that collect key metrics from the cluster. The auto-scaling controller monitors the load of the cluster and decides whether to scale in or scale out the cluster. The auto-balancing controller minimizes hot-spotting by dynamically reassigning partitions across the entire cluster. This level of automation is integral to the flexibility and scalability of AutoMQ, and it is also the inspiration behind its name.

AutoMQ offers several compelling benefits that make it an excellent choice for modern data streaming and messaging needs:
-
10x Cost Effective: By leveraging cloud elasticity and shared storage, AutoMQ reduces storage and computing expenses by a factor of ten. This approach allows for significant cost savings while maintaining high performance, optimizing both budget and operational efficiency.
-
Instant Elastic Efficiency: AutoMQ decouples storage from the computational layer using cloud services like AWS S3, making Kafka fully stateless. This design enables rapid scaling of clusters and reassignment of partitions within seconds, providing instant elasticity and efficiency to adapt to changing workloads.
-
100% Compatibility: AutoMQ replaces Kafka's storage layer with S3Stream while keeping the computation layer intact, ensuring full compatibility with Kafka’s protocols and features. This allows existing Kafka applications to transition seamlessly to AutoMQ without requiring extensive rewrites or adjustments.
AutoMQ, our cloud-native solution, is more than an alternative to existing technologies—it's a leap forward in the realm of data-intensive software. It promises cost savings, operational efficiency, and seamless compatibility.
We envision a future where data effortlessly streams into data lakes, unlocking the potential of real-time generative AI. This approach will enhance the utility of big data, leading to more comprehensive analyses and insights.
Finally, we invite you to join us on this journey and contribute to the evolution of AutoMQ. Visit our website to access the GitHub repository and join our Slack group for communication: https://www.automq.com/. Let's shape the future of data together with AutoMQ.
-
The borned blog of WarpStream: https://www.warpstream.com/blog/kafka-is-dead-long-live-kafka
-
The death blog of WarpStream: https://www.warpstream.com/blog/warpstream-is-dead-long-live-warpstream
-
AutoMQ Repository: https://github.com/AutoMQ/automq
-
AutoMQ Architecture Overview: https://docs.automq.com/automq/architecture/overview
-
AutoMQ S3Stream Overview: https://docs.automq.com/automq/architecture/s3stream-shared-streaming-storage/overview
-
AutoMQ Technical Advantages: https://docs.automq.com/automq/architecture/technical-advantage/overview
-
The Difference between AutoMQ and Kafka: https://docs.automq.com/automq/what-is-automq/difference-with-apache-kafka
-
The Difference between AutoMQ and WarpStream: https://docs.automq.com/automq/what-is-automq/difference-with-warpstream
-
The Difference between AutoMQ and Tiered Storage: https://docs.automq.com/automq/what-is-automq/difference-with-tiered-storage
-
AutoMQ Customers: https://www.automq.com/customer