OriginTrail Incentive model v1
This paper is the result of an ongoing research into securing the service availability of the OriginTrail network protocol. OriginTrail is a purpose built protocol for trusted supply chain data sharing, utilizing global standards and based on blockchain.
The peer-to-peer decentralized network operates as a serverless supply chain data storage, validation and serving network with built in fault-tolerance, DDoS resistance, tamper-proof resistance and self-sustaining based on the incentive system explained in this document. The incentive tool utilized within the protocol is the Trace token.
The intention of this paper is to document the research findings and mechanics behind the incentive model of OriginTrail, as well as to attract opinions and feedback from the community and researchers interested in the topic.
In order to better understand the OriginTrail P2P network structure and the incentive mechanisms within the protocol we have to understand all different roles within the context of the system.
The main premise is that the different nodes have different interests given their roles. In order to provide fair play on the network and provide a fair market, we have to understand different entities, their aims, needs and relationships. Above all we have to understand possibilities of collusion of different entities and their possible motives and therefore construct incentives in order to mitigate them.
It is important to state that all the nodes are operated by the same software, but rather their function in the context of observed data determines how the nodes are perceived - one node can have different roles within different deals. Below is a list of different entities and their roles in the system.
The data provider (DP) - is an entity that publishes supply chain data to the network. A typical scenario would be a company that would like to publish and share its data from their ERP system about the products that are part of the supply chain. Data providers can also be consumers which are interacting with the network through applications, or devices such as sensors which provide information about significant events in the supply chain.
The interest of the data provider is to be able to safely store the data on the network as well as to be able to connect it and cross-check with the data of other DPs within the network. Depending on the use case, providing the data to the network can be incentivised with the Trace token.
The Data Creator node (DC) - is an entity that represents a node which will be responsible for importing the data provided by the DP, making sure that all the criteria of DP are met - such as availability of the data on the network for a desired time and a factor of replication. While we expect typically that Data Providers will run their own Data Creator nodes, it is not a requirement - third party DC nodes may provide the service for one or several Data Providers. The DC node is an entry point of the information to the network and the relationship between the DP and DC is not regulated by the protocol.
The responsibility of the DC node is to negotiate, establish and maintain the service requested by the DP in relationship with its associated Data Holder nodes (DH). Furthermore, DC nodes are responsible to check if data is available on the network during the time of service and initiate the litigation process in case of any disputes.
The Data Holder (DH) is a node that has committed itself to store the data provided by a DC node for a requested period of time and make it available for the interested parties (which can also be the DC node). For this service the Data Holder will be compensated in TRAC tokens. The DH node has the responsibility to preserve the data intact in its unaltered, original form, as well as to provide high availability of the data in terms of bandwidth and uptime.
It is important to note that the DH node can be a DC node at the same time, in the context of the data that it has introduced to the network. As noted, the same software runs on all the nodes in the network, providing for symmetrical relations and thus not limiting scalability.
The Data Holder may also wish to find the data not directly delivered by DCs, but that is popular, and offer it to the interested parties. Therefore it is probable that Data Holders will listen to the network, search for data that is frequently requested, and replicate it from other Data Holders to also store them, process and offer them to the Data Viewers. However, since such Data Holders are not bound by the smart contract to provide the service, there is a certain risk that these Data Holders may offer false data or temper the data, or even pretend to have the data that they don’t have.
To mitigate this risk, a node will be required to deposit a stake. This stake will be stored in case it is proven that Data Holder tried to sell the data which is altered while Data Viewers will have a mechanism to check if all the chunks of the data are valid and initiate a litigation procedure in case of any inconsistencies. Furthermore, Data Holders will be able to provide larger stake if they want to demonstrate their quality of the service to the Data Viewers.
The Data Viewer (DV) is an entity that requests the data from any network node able to provide that data. The Data Viewer will be able to send two types of queries to the network. The first type is a request for a specific set of batch identifiers of the product supply chain they are interested in, where they will be able to retrieve the all connected data of the product trail. The second type are custom queries asking for specific connections between the data. In both cases, the Data Viewer will receive the offers from all the nodes that have the data together with charges for reading and structure of the data that will be sent. The Data Viewer can decide which offers it will accept and deposit the requested compensation funds on the escrow smart contract. The providing node then sends the encrypted data in order for the Data Viewer to test the validity of data. Once the validity of the data is confirmed, the Data Viewer will get the key to decrypt the data while the smart contract will unlock the funds for the party that provided the data.
The interest of the Data Viewer is to get the data as affordable as possible, but also to be sure that the provided data is genuine. Therefore, the Data Viewer will also have an opportunity to initiate the litigation procedure in case that received data is not valid. If that happens, and it is proved that Data Viewer received the false data, the stake of the corresponding DH node is lost.
The complete picture of interaction between participants in OriginTrail system is presented on data flow diagram (Figure 1).

To get data onto OriginTrail network, the Data provider sends tokens and data to the chosen DC node. The data creator sends tokens to the smart contract with tailored escrow functionalities and broadcasts a data holding request with the required terms of cooperation. All interested DH node candidates then respond with their requirements by submitting their applications to the smart contract - price of the service per data unit and minimum time of providing the service.
The minimum factor of replication is 2N+1, where the minimum value for N is yet to be determined, while the actual factor may be larger as it is decided by the Data Creator. To mitigate the possibility of fixing the results of the public offering, only when a certain number of Data Holders answer the call, which is greater than the requested replication factor, the smart contract will close the application procedure. Once the application procedure is finished, the smart contract selects the required number of Data Holders so a potential malicious Data Creator who might own several DH nodes can’t influence the process and pick its own nodes.
The Data Creator will deposit the compensations in tokens for the Data Holders on an escrow smart contract that Data Holders will be able to progressively withdraw from as the time passes, and up to the full amount once the period of service is successfully finished. The smart contract will take care that the funds are unlocked incrementally. It is up to the Data Holder to decide how often it will withdraw the funds for the part of the service that is already delivered.
In order to participate in the service, the Data Holder will also have to deposit a stake in the amount proportional to the amount of the job value. This stake is necessary as a measure of security that data will not be deleted or tempered in any way, and that it will be provided to third parties according to the requirements.
After the agreement between Data creator and Data holders has been created, the Data holder prepares data by splitting graph vertex data into blocks and calculating a root hash which is then stored on the blockchain. The root hash is stored permanently for everyone to be able to prove the integrity of data. The data is then encrypted using RSA encryption and encryption key appended to it. A Merkle tree is again created for the encrypted data blocks, proving integrity of data that will be sent to Data holder. The root hash of the encrypted data is written to the escrow contract and finally the data can be sent to Data holder. Upon receiving data, the Data holder is verifying that root hash of received data is indeed the one written into escrow contract and if it is a match the testing and payment process can begin.
To ensure that the service is provided as requested, the Data creator is able to test Data holders by sporadically asking them for a random encrypted data block. In case when the Data creator has a suspicion that the data is not available anymore or is altered in any way, it is able to initiate the litigation procedure in which the smart contract will decide if the Data holder is able to prove that it still has the data available.
The litigation procedure involves a smart contract as a validator of the service. When the Data creator is challenging the Data holder to prove to the smart contract that it is storing the agreed upon data, it sends a test question to the smart contract in a form of requested data block number. In response, the Data holder sends the requested block to the smart contract. Data creator then sends the Merkle proof for the requested data block and the smart contract calculates if the hash of requested block fits the proof.
If the proof is not valid for a data block hash there are two options - the first is that the Data holder is not storing agreed upon data, thus not being able to submit the correct answer, and the second is that the Data creator has created and submitted a false (unanswerable) test. The dilemma is solved by the Data creator sending the correct data block, that fits the already submitted Merkle proof and Merkle root hash to the smart contract. If the Data holder’s block is incorrect for the given proof than the Data holder loses it’s deployed stake and the stake is transferred to Data creator. In the other way, if Data creator is not able to prove it’s own proof than it has sent a false test and its stake is transferred to the Data holder. In case that it is proven that DH does not have the original data anymore, the smart contract will initiate the procedure of DH replacement.
The Merkle tree for data blocks <B1, B2, … , Bn> is a balanced binary hash tree where each of internal node is calculated as a SHA3 hash of the concatenated child nodes. The i-th leaf node Li is calculated as Li = SHA3(Bi, i). The root hash R of the Merkle tree is SHA3 hash of the roots child nodes. The Merkle proof for block Bi is tuple of hashes <P(0), P(1), .. , P(h−1)> where h is the height of the Merkle tree. For the proof to be valid, it needs to satisfy the tuple of tests <T(0), T(1), .. , T(h-1)> such that T(0) = SHA3(Li, P(0)) and T(i) = SHA3(P(i), T(i−1)), for i > 0, and T(h-1) = R. To prove the integrity of the answer block Bk, the smart contract calculates the hash _a = L(k) _and calculates proof T(h-1). If the proof is correct then the answer blocks integrity is unchanged from when it was created. The diagram of the proving mechanism is shown on Figure 2.
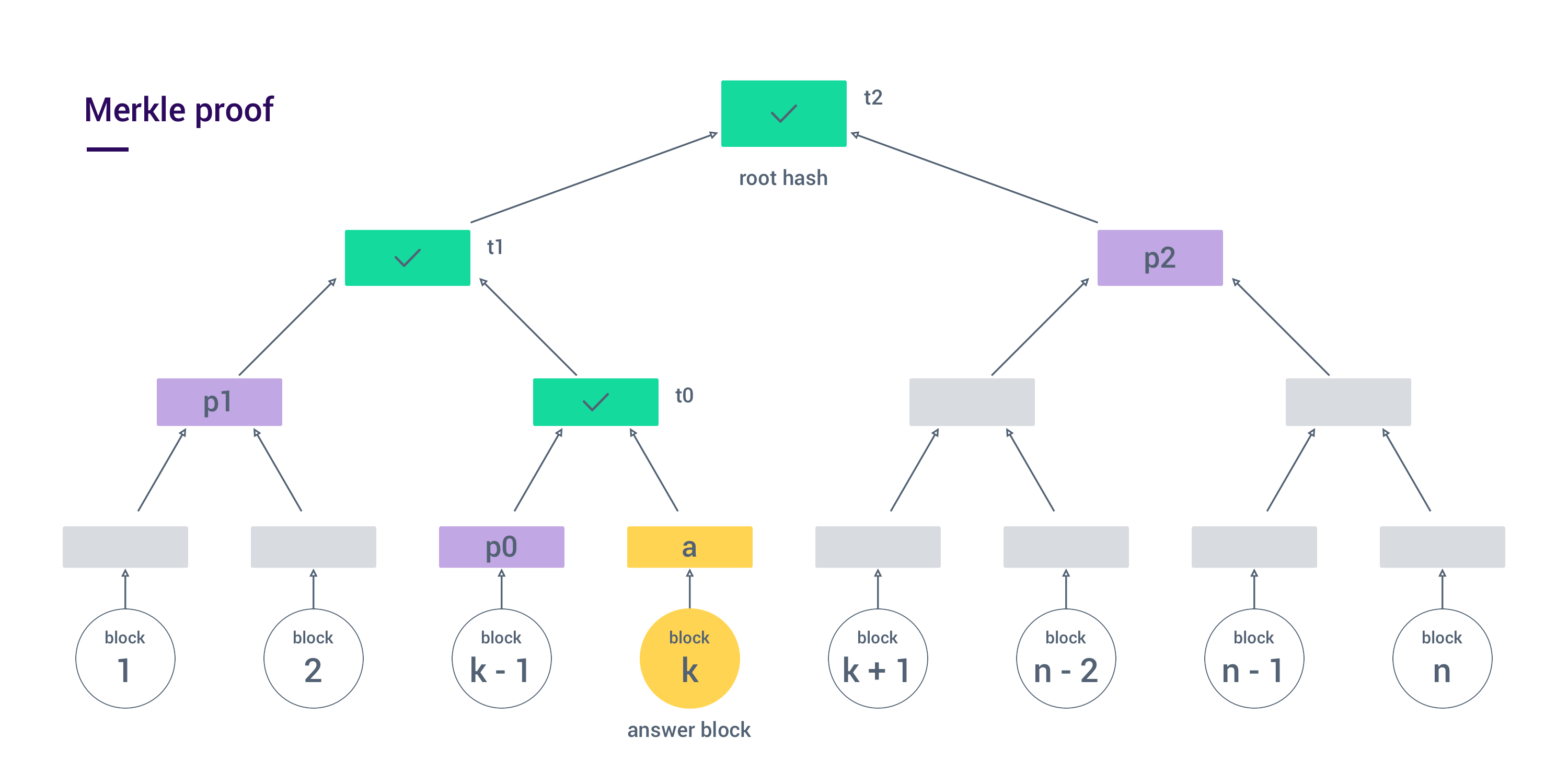
Figure 2. Merkle proof diagram
Data consumer broadcasts a query for the data it needs through its associated node. Any DH that stores the data can reply to the broadcast. The data consumer then selects a DH by his own criteria, creates an escrow contract and deploys tokens for payment. The DH sends the encrypted data to the Data consumer, and the Data consumer randomly selects one data block to send it to the escrow contract together with the block number. After sending, the DH needs to reply with the unencrypted block, the key that was used for encryption and the Merkle path proof for proving that block is valid. If everything is valid, tokens are transferred to the DH node and the Data consumer can take the key for unlocking data.
This document represents the first version of the incentive mechanism and is intended to illustrate network mechanics. The focus of the upcoming research in the incentive model will be on simulating the activities in the network based on a larger scale tests in real network conditions. We invite the community to provide opinions, ideas and feedback to further improve the model and document.