多机、多集群、多项目组 部署调度
公有云,单机,多机,多集群,分布式存储,私有仓库,gpu,功能初步验证
本地调试时:(启动方式:install/docker/目录下执行docker-compose up)
- k8s集群的config文件:在install/docker/kubeconfig/下面
- 配置文件config.py文件:在install/docker/config.py中
- 启动文件entrypoint.sh文件:在install/docker/entrypoint.sh中
线上部署时:(启动方式:install/kubernetes/目录下执行 kubectl apply -k cube/overlays)
- k8s集群的config文件:在install/kubernetes/kubeconfig/下面
- 配置文件config.py文件:在install/kubernetes/cube/overlays/config/config.py中
- 启动文件entrypoint.sh文件:在install/kubernetes/cube/overlays/config/entrypoint.sh中
机器通过label进行管理,所有的调度机器由平台控制,不由用户直接控制。
开发训练服务机器管理:
- 对于cpu的train/notebook/service会选择cpu=true的机器
- 对于gpu的train/notebook/service会选择gpu=true的机器
- 对于vgpu的service会选择vgpu=true的机器
- 对于rdma网络的pod会选择rdma=true的机器
- 训练任务会选择train=true的机器
- notebook会选择notebook=true的机器
- 服务化会选择service=true的机器
- 不同资源组的任务会选择对应org=xx的机器。默认为org=public
- 可以通过gpu-type=xx表示gpu的型号,比如gpu-type=V100或gpu-type=T4,在配置gpu算力时也可以同步配置gpu型号。例如2(T4)表示2张T4卡。
控制器机器管理:
- mysql=true 部署mysql服务的机器
- redis=true 部署mysql服务的机器
- kubeflow-dashobard=true 部署cube服务的机器
- kubeflow=true 部署kubeflow的机器
- isito=true 部署istio的机器
- monitoring=true 部署prometheus的机器
实现原理:
需要部署分布式的情况下,需要先部署分布式存储。先在每台机器上部署分布式存储,可以参考cube-studio-enterprise/install/kubernetes/nfs /NFS离线部署.md部署nfs。主节点上部署及配置服务端,其他节点部署配置客户端。
目前机器学习平台依赖强io性能的分布式存储。
参考分布式存储部署
!!!重要:分布式文件系统需要挂载到每台机器的/data/k8s/下面,当然也可以挂载其他目录下,以软链的形式链接到/data/k8s/下 (如果使用juicefs,则不需要这一步)
需要每台机器都有对应的目录/data/k8s为分布式存储目录(如果使用juicefs,则不需要这一步)
mkdir -p /data/k8s/kubeflow/minio
mkdir -p /data/k8s/kubeflow/global
mkdir -p /data/k8s/kubeflow/pipeline/workspace
mkdir -p /data/k8s/kubeflow/pipeline/archives 在主节点上单机部署cube studio,之后进行扩容。
基础准备:主机/data/k8s目录下需为分布式存储
1、初始化机器
先部署docker,拉取代码文件。
在新机器上只需要拉取rancher镜像
cd install/kubernetes/rancher
sh pull_rancher_images.sh
在新机器上只需要拉取cube-studio镜像
cd install/kubernetes/
bash init_node.sh2、添加k8s,只需要worker角色
在主节点已部署的rancher server的web界面,将新机器加入rancher集群,新机器只需要为worker,并且为机器添加label。
操作路径:左侧边栏“集群管理”-“集群”-“注册”-只选择“Worker”角色,点击加入集群命令。在新机器上执行复制的命令+"--node-name 新机器内网ip"即可。
如果遇到docekr的bug,先systemctl restart docker,再重新执行命令试一试。
3、 为机器添加标签
service=true train=true notebook=true org=public cpu=true # 按需 gpu=true # 按需 gpu-type=A100 # 按需
可以在rancher中加,也可以通过kubectl命令加。
实现原理:
在每个集群完成平台部署。但仅保留其中一个web端。web端所在集群我们成为主集群,其他为远程集群。
现在新集群上部署k8s和cube-studio
1、远程k8s集群卸载非必要组件
# 删除web
kubectl delete -k cube/overlays
# 删除mysql和redis
kubectl delete -f redis/redis.yaml
kubectl delete -f mysql/deploy.yaml
# 删除labelstudio
kubectl delete -f labelstudio/postgresql.yaml
kubectl delete -f labelstudio/labelstudio.yaml
2、修改远程k8s集群分布式存储配置
如果想主k8s集群和远程k8s集群使用相同的分布式存储,需要将同一个分布式存储挂载到主k8s集群和从k8s集群的主机的/data/k8s目录下
挂载相同分布式存储后,为新的k8s集群中的prometheus创建新的分布式存储目录
# 创建新k8s集群的监控存储目录
mkdir -p /data/k8s/monitoring/prometheus-cluster2
chmod -R 777 /data/k8s/monitoring/prometheus-cluster2
# 修改新k8s集群的prometheus的pv
kubectl delete -f cube-studio/install/kubernetes/prometheus/prometheus/prometheus-main.yml
kubectl delete pvc -n monitoring prometheus-k8s-db-prometheus-k8s-0
kubectl delete -f cube-studio/install/kubernetes/prometheus/prometheus/pv-pvc-hostpath.yaml
修改cube-studio/install/kubernetes/prometheus/prometheus/pv-pvc-hostpath.yaml
将pv存储地址/data/k8s/monitoring/prometheus 改为 /data/k8s/monitoring/prometheus-cluster2
然后重新部署新k8s集群中的prometheus
kubectl create -f cube-studio/install/kubernetes/prometheus/prometheus/pv-pvc-hostpath.yaml
kubectl create -f cube-studio/install/kubernetes/prometheus/prometheus/prometheus-main.yml3、添加配置文件
3.1、需要把在主k8s集群的install/kubernetes/kubeconfig目录下面粘贴远程k8s集群的config文件,并规范命名,比如有个远程k8s集群,这里起名为dev1集群,那么将config文件粘贴到install/kubernetes/kubeconfig/dev1-kubeconfig中
在主k8s集群生成新的kubeconfig配置项
cd install/kubernetes
kubectl delete configmap kubernetes-config -n infra
kubectl create configmap kubernetes-config --from-file=kubeconfig -n infra
3.2、修改config.py配置文件:
# 所有训练集群的信息
CLUSTERS={
# 和project expand里面的名称一致
"dev":{
"NAME":"dev",
"KUBECONFIG":'/home/myapp/kubeconfig/dev-kubeconfig',
"HOST": 'xx.xx.xx.xx',
# "SERVICE_DOMAIN": 'service.remote.com' # 泛域名
},
"dev1":{
"NAME": "dev1",
"KUBECONFIG": '/home/myapp/kubeconfig/dev1-kubeconfig',
"HOST": 'xx.xx.xx.xx',
# "SERVICE_DOMAIN": 'service.remote.com' # 泛域名
}
}
config.py文件更新到k8s可以使用
kubectl delete -k cube/overlays
kubectl apply -k cube/overlays或者直接线上修改infra/kubeflow-dashboard-config-xx这个configmap,修改后再重启infra/kubeflow-dashboard*相关的pod
然后就可以在整体资源界面看到不同集群的资源使用情况了。
这样cube就可以调度多个k8s集群了,但是还需要在项目中指定当前项目组下面的notebook/pipeline/service在哪个k8s集群调度。需要在项目组的扩展参数中添加
{
"cluster": "dev1"
}

3.3、添加新集群的watch组件
复制infra/kubeflow-watch 的 deployment,修改名称和环境变量ENVIRONMENT为新k8s集群的名称
3.4、仓库秘钥重新生成
建议重新保存一遍仓库中的秘钥,因为保存秘钥的动作会在所有的k8s集群相关命名空间下创建对应的hubescret
3.5、将新集群的minio 替换为主机群的地址
先将主机群的kubeflow命名空间的service minio 修改为nodeport方式
修改新集群kubeflow命名空间下的configmap workflow-controller-configmap其中minio的地址改为主机群的nodeport地址,然后重启workflow-controller的pod
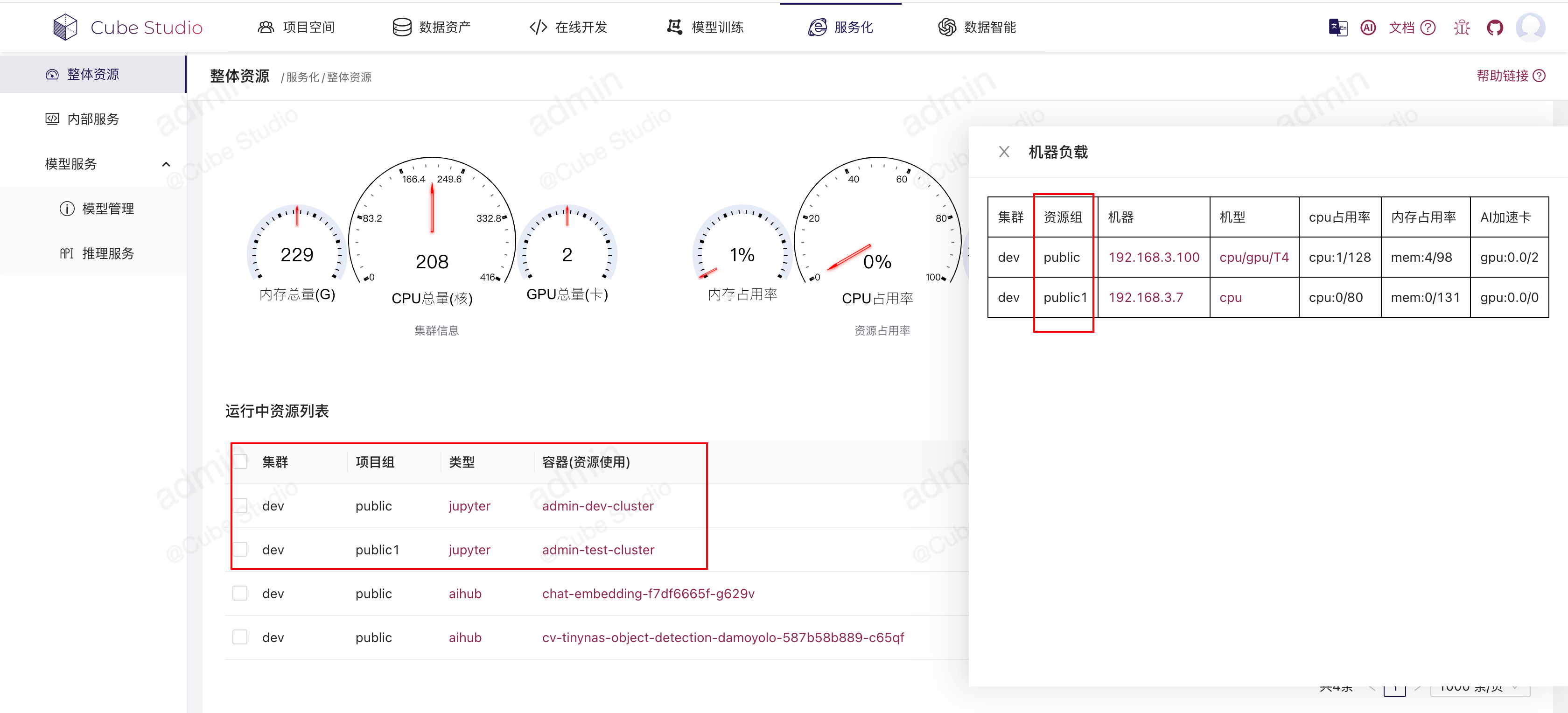
每个k8s集群的算力都可以划分为多个资源组。这些划分是通过机器label来实现的。
为机器添加标签org=xx其中xx为资源组名称,
添加机器标签后,在项目组中添加资源组配置为上面的xx,然后保存项目组配置后,该项目组下的成员就会自动使用这一波资源组算力了。
多项目组之间的算力的均衡通过schedules.py中的adjust_node_resource任务实现。
基本原则是每5分钟,将可共享的机器(lable包含share=true),从当前负载最小的项目组划分到负载最高的项目组,同时保证项目组的最小可用算力
