[statistics] p value
- summary
- real statistic(예를 들면, 평균 m)은 모르는 값(unknown)이므로 이 값이 어떨 것이다 라고 가정(hypothesis)할 수 있다.
- 예를 들어, 실제 평균값(real mean)을 m으로 가정하자. 이걸 귀무가설(null hypothesis)이라고 한다.
- 이런 상태에서 샘플 데이터를 확보
- 예를 들면, `sample size = s`, n번 샘플링
- 샘플 데이터로부터 관측된 평균값(observed mean) m'을 계산한다.
- 이제 여기서 문제
- 이 관측된 평균값을 어느 정도 신뢰할 수 있을까?
- 우선 이렇게 생각해 볼 수 있다.
1) m과 m'의 차이가 큰 경우 : 가정했던 m이 잘못되었을 것이다. 이를 null hypothesis를 reject한다.
2) m과 m'의 차이가 작은 경우 : 가정했던 m이 그럴듯하다. null hypothesis를 accept한다.
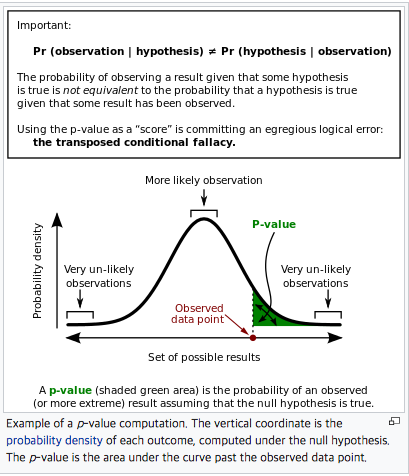
- 이를 계량적으로 표현하면 `m'이 m보다 어느 정도 큰가`로 바꿀 수 있는데, 이것이 p-value이다.
우리가 가정했던 m이 정규분포를 따른다면, 위 그림과 같은 정규분포를 그려볼 수 있는 데,
여기서 관측된 m'보다 더 큰 영역이 바로 `m'이 m보다 큰 확률`이 될 것이다.