Releases: JohnSnowLabs/nlu
Multilingual DeBERTa Transformer Embeddings for 100+ Languages, Spanish Deidentification and NER for Randomized Clinical Trials - John Snow Labs NLU 3.4.2
Multilingual DeBERTa Transformer Embeddings for 100+ Languages, Spanish Deidentification and NER for Randomized Clinical Trials - John Snow Labs NLU 3.4.2
We are very excited NLU 3.4.2 has been released.
On the open source side we have 5 new DeBERTa Transformer models for English and Multi-Lingual for 100+ languages.
DeBERTa improves over BERT and RoBERTa by introducing two novel techniques.
For the healthcare side we have new NER models for randomized clinical trials (RCT) which can detect entities of type
BACKGROUND, CONCLUSIONS, METHODS, OBJECTIVE, RESULTS from clinical text.
Additionally, new Spanish Deidentification NER models for entities like STATE, PATIENT, DEVICE, COUNTRY, ZIP, PHONE, HOSPITAL and many more.
New Open Source Models
Integrates models from Spark NLP 3.4.2 release
| Language | NLU Reference | Spark NLP Reference | Task | Annotator Class |
|---|---|---|---|---|
| en | en.embed.deberta_v3_xsmall | deberta_v3_xsmall | Embeddings | DeBertaEmbeddings |
| en | en.embed.deberta_v3_small | deberta_v3_small | Embeddings | DeBertaEmbeddings |
| en | en.embed.deberta_v3_base | deberta_v3_base | Embeddings | DeBertaEmbeddings |
| en | en.embed.deberta_v3_large | deberta_v3_large | Embeddings | DeBertaEmbeddings |
| xx | xx.embed.mdeberta_v3_base | mdeberta_v3_base | Embeddings | DeBertaEmbeddings |
New Healthcare Models
Integrates models from Spark NLP For Healthcare 3.4.2 release
| Language | NLU Reference | Spark NLP Reference | Task | Annotator Class |
|---|---|---|---|---|
| en | en.med_ner.clinical_trials | bert_sequence_classifier_rct_biobert | Text Classification | MedicalBertForSequenceClassification |
| es | es.med_ner.deid.generic.roberta | ner_deid_generic_roberta_augmented | De-identification | MedicalNerModel |
| es | es.med_ner.deid.subentity.roberta | ner_deid_subentity_roberta_augmented | De-identification | MedicalNerModel |
| en | en.med_ner.deid.generic_augmented | ner_deid_generic_augmented | ['Named Entity Recognition', 'De-identification'] | MedicalNerModel |
| en | en.med_ner.deid.subentity_augmented | ner_deid_subentity_augmented | ['Named Entity Recognition', 'De-identification'] | MedicalNerModel |
Additional NLU resources
- 140+ NLU Tutorials
- NLU in Action
- Streamlit visualizations docs
- The complete list of all 4000+ models & pipelines in 200+ languages is available on Models Hub.
- Spark NLP publications
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
1 line Install NLU on Google Colab
!wget https://setup.johnsnowlabs.com/nlu/colab.sh -O - | bash
1 line Install NLU on Kaggle
!wget https://setup.johnsnowlabs.com/nlu/kaggle.sh -O - | bash
Install via PIP
! pip install nlu pyspark streamlit==0.80.0
22 New models for 23 languages including various African and Indian languages, Medical Spanish models and more in NLU 3.4.1
We are very excited to announce the release of NLU 3.4.1
which features 22 new models for 23 languages where the
The open-source side covers new Embeddings for Vietnamese and English Clinical domains and Multilingual Embeddings for 12 Indian and 9 African Languages.
Additionally, there are new Sequence classifiers for Multilingual NER for 9 African languages,
German Sentiment Classifiers and English Emotion and Typo Classifiers.
The healthcare side covers Medical Spanish models, Classifiers for Drugs, Gender, the Pico Framework, and Relation Extractors for Adverse Drug events and Temporality.
Finally, Spark 3.2.X is now supported and bugs related to Databricks environments have been fixed.
General NLU Improvements
- Support for Spark 3.2.x
New Open Source Models
Based on the amazing 3.4.1 Spark NLP Release
integrates new Multilingual embeddings for 12 Major Indian languages,
embeddings for Vietnamese, French, and English Clinical domains.
Additionally new Multilingual NER model for 9 African languages, English 6 Class Emotion classifier and Typo detectors.
New Embeddings
- Multilingual ALBERT - IndicBert model pretrained exclusively on 12 major Indian languages with size smaller and performance on par or better than competing models. Languages covered are Assamese, Bengali, English, Gujarati, Hindi, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, Telugu.
Available with xx.embed.albert.indic - Fine tuned Vietnamese DistilBERT Base cased embeddings. Available with vi.embed.distilbert.cased
- Clinical Longformer Embeddings which consistently out-performs ClinicalBERT for various downstream
tasks and on datasets. Available with en.embed.longformer.clinical - Fine tuned Static French Word2Vec Embeddings in 3 sizes, 200d, 300d and 100d. Available with fr.embed.word2vec_wiki_1000, fr.embed.word2vec_wac_200 and fr.embed.w2v_cc_300d
New Transformer based Token and Sequence Classifiers
- Multilingual NER Distilbert model which detects entities
DATE,LOC,ORG,PERfor the languages 9 African languages (Hausa, Igbo, Kinyarwanda, Luganda, Nigerian, Pidgin, Swahili, Wolof, and Yorùbá).
Available with xx.ner.masakhaner.distilbert - German News Sentiment Classifier available with de.classify.news_sentiment.bert
- English Emotion Classifier for 6 Classes available with en.classify.emotion.bert
- **English Typo Detector **: available with en.classify.typos.distilbert
| Language | NLU Reference | Spark NLP Reference | Task | Annotator Class |
|---|---|---|---|---|
| xx | xx.embed.albert.indic | albert_indic | Embeddings | AlbertEmbeddings |
| xx | xx.ner.masakhaner.distilbert | xlm_roberta_large_token_classifier_masakhaner | Named Entity Recognition | DistilBertForTokenClassification |
| en | en.embed.longformer.clinical | clinical_longformer | Embeddings | LongformerEmbeddings |
| en | en.classify.emotion.bert | bert_sequence_classifier_emotion | Text Classification | BertForSequenceClassification |
| de | de.classify.news_sentiment.bert | bert_sequence_classifier_news_sentiment | Sentiment Analysis | BertForSequenceClassification |
| en | en.classify.typos.distilbert | distilbert_token_classifier_typo_detector | Named Entity Recognition | DistilBertForTokenClassification |
| fr | fr.embed.word2vec_wiki_1000 | word2vec_wiki_1000 | Embeddings | WordEmbeddingsModel |
| fr | fr.embed.word2vec_wac_200 | word2vec_wac_200 | Embeddings | WordEmbeddingsModel |
| fr | fr.embed.w2v_cc_300d | w2v_cc_300d | Embeddings | WordEmbeddingsModel |
| vi | vi.embed.distilbert.cased | distilbert_base_cased | Embeddings | DistilBertEmbeddings |
New Healthcare Models
Integrated from the amazing 3.4.1 Spark NLP For Healthcare Release.
which makes 2 new Annotator Classes available, MedicalBertForSequenceClassification and MedicalDistilBertForSequenceClassification,
various medical Spanish models, RxNorm Resolvers,
Transformer based sequence classifiers for Drugs, Gender and the PICO framework,
and Relation extractors for Temporality and Causality of Drugs and Adverse Events.
New Medical Spanish Models
- Spanish Word2Vec Embeddings available with es.embed.sciwiki_300d
- Spanish PHI Deidentification NER models with two different subsets of entities extracted, available with ner_deid_generic and ner_deid_subentity
New Resolvers
- RxNorm resolvers with augmented concept data available with en.med_ner.supplement_clinical
New Transformer based Sequence Classifiers
- Adverse Drug Event Classifier Biobert based available with en.classify.ade.seq_biobert
- Patient Gender Classifier Biobert and Distilbert based available with en.classify.gender.seq_biobert
and available with en.classify.ade.seq_distilbert - PiCO Framework Classifier available with en.classify.pico.seq_biobert
New Relation Extractors
- Temporal Relation Extractor available with en.relation.temporal_events_clinical
- Adverse Drug Event Relation Extractors one version Biobert Embeddings and one non-DL version available with en.relation.adverse_drug_events.clinical available with [en.relation.adverse_drug_events.clinical.biobert](https://nlp.johnsnowlabs.com/2021/07/12/redl_ade_biobert_en.html...
1 line to OCR for images, PDFS and DOCX, Text Generation with GPT2 and new T5 models, Sequence Classification with XlmRoBerta, RoBerta, Xlnet, Longformer and Albert, Transformer based medical NER with MedicalBertForTokenClassifier, 80 new models, 20+ new languages including various African and Scandinavian and much more in John Snow Labs NLU 3.4.0 !
We are incredibly excited to announce John Snow Labs NLU 3.4.0 has been released!
This release features 11 new annotator classes and 80 new models, including 3 OCR Transformers which enable you to extract text
from various file types, support for GPT2 and new pretrained T5 models for Text Generation and dozens more of new transformer based models
for Token and Sequence Classification.
This includes 8 new Sequence classifier models which can be pretrained in Huggingface and imported into Spark NLP and NLU.
Finally, the NLU tutorial page of the 140+ notebooks has been updated
New NLU OCR Features
3 new OCR based spells are supported, which enable extracting text from files of type
JPEG, PNG, BMP, WBMP, GIF, JPG, TIFF, DOCX, PDF in just 1 line of code.
You need a Spark OCR license for using these, which is available for free here and refer to the new
OCR tutorial notebook
Find more details on the NLU OCR documentation page
New NLU Healthcare Features
The healthcare side features a new MedicalBertForTokenClassifier annotator which is a Bert based model for token classification problems like Named Entity Recognition,
Parts of Speech and much more. Overall there are 28 new models which include German De-Identification models, English NER models for extracting Drug Development Trials,
Clinical Abbreviations and Acronyms, NER models for chemical compounds/drugs and genes/proteins, updated MedicalBertForTokenClassifier NER models for the medical domains Adverse drug Events,
Anatomy, Chemicals, Genes,Proteins, Cellular/Molecular Biology, Drugs, Bacteria, De-Identification and general Medical and Clinical Named Entities.
For Entity Relation Extraction between entity pairs new models for interaction between Drugs and Proteins.
For Entity Resolution new models for resolving Clinical Abbreviations and Acronyms to their full length names and also a model for resolving Drug Substance Entities to the categories
Clinical Drug, Pharmacologic Substance, Antibiotic, Hazardous or Poisonous Substance and new resolvers for LOINC and SNOMED terminologies.
New NLU Open source Features
On the open source side we have new support for Open Ai's GPT2 for various text sequence to sequence problems and
additionally the following new Transformer models are supported :
RoBertaForSequenceClassification, XlmRoBertaForSequenceClassification, LongformerForSequenceClassification,
AlbertForSequenceClassification, XlnetForSequenceClassification, Word2Vec with various pre-trained weights for various problems!
New GPT2 models for generating text conditioned on some input,
New T5 style transfer models for active to passive, formal to informal, informal to formal, passive to active sequence to sequence generation.
Additionally, a new T5 model for generating SQL code from natural language input is provided.
On top of this dozens new Transformer based Sequence Classifiers and Token Classifiers have been released, this is includes for Token Classifier the following models :
Multi-Lingual general NER models for 10 African Languages (Amharic, Hausa, Igbo, Kinyarwanda, Luganda, Nigerian, Pidgin, Swahilu, Wolof, and Yorùbá),
10 high resourced languages (10 high resourced languages (Arabic, German, English, Spanish, French, Italian, Latvian, Dutch, Portuguese and Chinese),
6 Scandinavian languages (Danish, Norwegian-Bokmål, Norwegian-Nynorsk, Swedish, Icelandic, Faroese) ,
Uni-Lingual NER models for general entites in the language Chinese, Hindi, Islandic, Indonesian
and finally English NER models for extracting entities related to Stocks Ticker Symbols, Restaurants, Time.
For Sequence Classification new models for classifying Toxicity in Russian text and English models for
Movie Reviews, News Categorization, Sentimental Tone and General Sentiment
New NLU OCR Models
The following Transformers have been integrated from Spark OCR
| NLU Spell | Transformer Class |
|---|---|
nlu.load(img2text) |
ImageToText |
nlu.load(pdf2text) |
PdfToText |
nlu.load(doc2text) |
DocToText |
New Open Source Models
Integration for the 49 new models from the colossal Spark NLP 3.4.0 release
| Language | NLU Reference | Spark NLP Reference | Task | Annotator Class |
|---|---|---|---|---|
| en | en.gpt2.distilled | gpt2_distilled | Text Generation | GPT2Transformer |
| en | en.gpt2 | gpt2 | Text Generation | GPT2Transformer |
| en | en.gpt2.medium | gpt2_medium | Text Generation | GPT2Transformer |
| en | en.gpt2.large | gpt_large | Text Generation | GPT2Transformer |
| en | en.t5.active_to_passive_styletransfer | t5_active_to_passive_styletransfer | Text Generation | T5Transformer |
| en | en.t5.formal_to_informal_styletransfer | t5_formal_to_informal_styletransfer | Text Generation | T5Transformer |
| en | en.t5.grammar_error_corrector | t5_grammar_error_corrector | Text Generation | T5Transformer |
| en | en.t5.informal_to_formal_styletransfer | t5_informal_to_formal_styletransfer | Text Generation | T5Transformer |
| en | en.t5.passive_to_active_styletransfer | t5_passive_to_active_styletransfer | Text Generation | T5Transformer |
| en | en.t5.wikiSQL | t5_small_wikiSQL | Text Generation ... |
48 new Transformer based models in 9 new languages, including NER for Finance, Industry, Politcal Policies, COVID and Chemical Trials, various clinical and medical domains in Spanish and English and much more in NLU 3.3.1
We are incredibly excited to announce NLU 3.3.1 has been released with 48 new models in 9 languages!
It comes with 2 new types of state-of-the-art models,distilBERT and BERT for sequence classification with various pre-trained weights,
state-of-the-art bert based classifiers for problems in the domains of Finance, Sentiment Classification, Industry, News, and much more.
On the healthcare side, NLU features 22 new models in for English and Spanish with
with entity Resolver Models for LOINC, MeSH, NDC and SNOMED and UMLS Diseases,
NER models for Biomarkers, NIHSS-Guidelines, COVID Trials , Chemical Trials,
Bert based Token Classifier models for biological, genetical,cancer, cellular terms,
Bert for Sequence Classification models for clinical question vs statement classification
and finally Spanish Clinical NER and Resolver Models
Once again, we would like to thank our community for making another amazing release possible!
New Open Source Models and Features
Integrates the amazing Spark NLP 3.3.3 and 3.3.2 releases, featuring:
- New state-of-the-art fine-tuned
BERT models for Sequence ClassificationinEnglish,French,German,Spanish,Japanese,Turkish,Russian, and multilingual languages. DistilBertForSequenceClassificationmodels inEnglish,FrenchandUrduWord2Vecmodels.classify.distilbert_sequence.banking77:Banking NER modeltrained on BANKING77 dataset, which provides a very fine-grained set of intents in a banking domain. It comprises 13,083 customer service queries labeled with 77 intents. It focuses on fine-grained single-domain intent detection. Can extract entities like activate_my_card, age_limit, apple_pay_or_google_pay, atm_support, automatic_top_up, balance_not_updated_after_bank_transfer, balance_not_updated_after_cheque_or_cash_deposit, beneficiary_not_allowed, cancel_transfer, card_about_to_expire, card_acceptance, card_arrival, card_delivery_estimate, card_linking, card_not_working, card_payment_fee_charged, card_payment_not_recognised, card_payment_wrong_exchange_rate, card_swallowed, cash_withdrawal_charge, cash_withdrawal_not_recognised, change_pin, compromised_card, contactless_not_working, country_support, declined_card_payment, declined_cash_withdrawal, declined_transfer, direct_debit_payment_not_recognised, disposable_card_limits, edit_personal_details, exchange_charge, exchange_rate, exchange_via_app, extra_charge_on_statement, failed_transfer, fiat_currency_support, get_disposable_virtual_card, get_physical_card, getting_spare_card, getting_virtual_card, lost_or_stolen_card, lost_or_stolen_phone, order_physical_card, passcode_forgotten, pending_card_payment, pending_cash_withdrawal, pending_top_up, pending_transfer, pin_blocked, receiving_money,classify.distilbert_sequence.industry:Industry NER modelwhich can extract entities like Advertising, Aerospace & Defense, Apparel Retail, Apparel, Accessories & Luxury Goods, Application Software, Asset Management & Custody Banks, Auto Parts & Equipment, Biotechnology, Building Products, Casinos & Gaming, Commodity Chemicals, Communications Equipment, Construction & Engineering, Construction Machinery & Heavy Trucks, Consumer Finance, Data Processing & Outsourced Services, Diversified Metals & Mining, Diversified Support Services, Electric Utilities, Electrical Components & Equipment, Electronic Equipment & Instruments, Environmental & Facilities Services, Gold, Health Care Equipment, Health Care Facilities, Health Care Services.xx.classify.bert_sequence.sentiment:Multi-Lingual Sentiment ClassifierThis a bert-base-multilingual-uncased model finetuned for sentiment analysis on product reviews in six languages: English, Dutch, German, French, Spanish and Italian. It predicts the sentiment of the review as a number of stars (between 1 and 5). This model is intended for direct use as a sentiment analysis model for product reviews in any of the six languages above, or for further finetuning on related sentiment analysis tasks.distilbert_sequence.policy:Policy ClassifierThis model was trained on 129.669 manually annotated sentences to classify text into one of seven political categories: ‘Economy’, ‘External Relations’, ‘Fabric of Society’, ‘Freedom and Democracy’, ‘Political System’, ‘Welfare and Quality of Life’ or ‘Social Groups’.classify.bert_sequence.dehatebert_mono:Hate Speech ClassifierThis model was trained on 129.669 manually annotated sentences to classify text into one of seven political categories: ‘Economy’, ‘External Relations’, ‘Fabric of Society’, ‘Freedom and Democracy’, ‘Political System’, ‘Welfare and Quality of Life’ or ‘Social Groups’.
Complete List of Open Source Models :
2000%+ Speedup on small data, 63 new models for 100+ Languages with 6 new supported Transformer classes including BERT, XLM-RoBERTa, alBERT, Longformer, XLnet based models, 48 NER profiling helathcare pipelines and much more in John Snow Labs NLU 3.3.0
We are incredibly excited to announce NLU 3.3.0 has been released!
It comes with a up to 2000%+ speedup on small datasets, 6 new Types of Deep Learning transformer models, including
RoBertaForTokenClassification,XlmRoBertaForTokenClassification,AlbertForTokenClassification,LongformerForTokenClassification,XlnetForTokenClassification,XlmRoBertaSentenceEmbeddings.
In total there are 63 NLP Models 6 New Languages Supported which are Igbo, Ganda, Dholuo, Naija, Wolof,Kinyarwanda with their corresponding ISO codes ig, lg, lou, pcm, wo,rw
with New SOTA XLM-RoBERTa models in Luganda, Kinyarwanda, Igbo, Hausa, and Amharic languages and 2 new Multilingual Embeddings with 100+ supported languages via XLM-Roberta are available.
On the healthcare NLP side we are glad to announce 18 new NLP for Healthcare models including
NER Profiling pretrained pipelines to run 48 different Clinical NER and 21 Different Biobert Models At Once Over the Input Text
New BERT-Based Deidentification NER Model, Sentence Entity Resolver Models For German Language
New Spell Checker Model For Drugs , 3 New Sentence Entity Resolver Models (3-char ICD10CM, RxNorm_NDC, HCPCS)
5 New Clinical NER Models (Trained By BertForTokenClassification Approach)
,Radiology NER Model Trained On cheXpert Datasetand New UMLS Sentence Entity Resolver Models
Additionally 2 new tutorials are avaiable, NLU & Streamlit Crashcourse and NLU for Healthcare Crashcourse of every of the 50 + healthcare Domains and 200+ healthcare models
New Features and Improvements
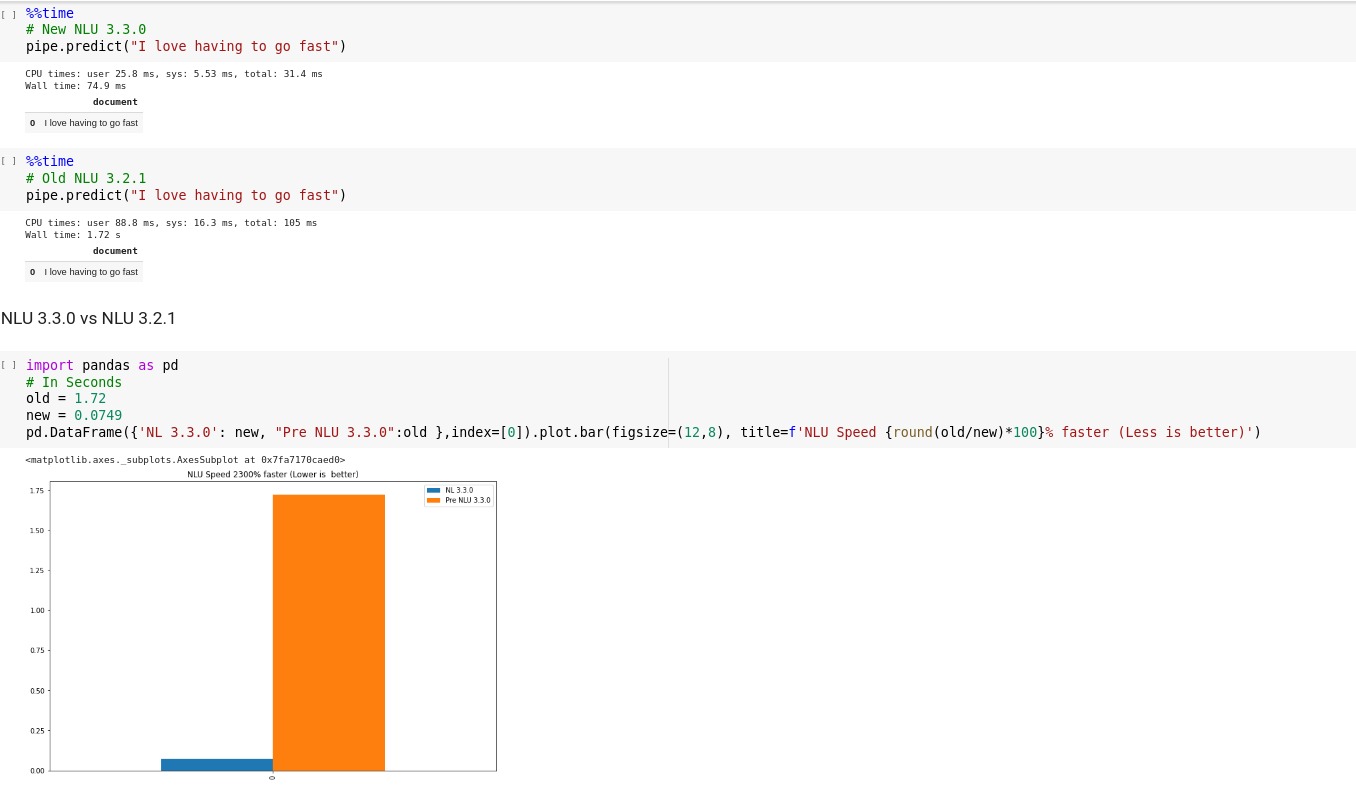
2000%+ Speedup prediction for small datasets
NLU pipelines now predict up to 2000% faster by optimizing integration with Spark NLP's light pipelines.
NLU will configure usage of this automatically, but it can be turned off as well via multithread=False
50x faster saving of NLU Pipelines
Up to 50x faster saving Spark NLP/ NLU models and pipelines! We have improved the way we package TensorFlow SavedModel while saving Spark NLP models & pipelines. For instance, it used to take up to 10 minutes to save the xlm_roberta_base model before Spark NLP 3.3.0, and now it only takes up to 15 seconds!
New Annotator Classes Integrated
The following new transformer classes are available with various pretrained weights in 1 line of code :
- RoBertaForTokenClassification
- XlmRoBertaForTokenClassification
- AlbertForTokenClassification
- LongformerForTokenClassification
- XlnetForTokenClassification
- XlmRoBertaSentenceEmbeddings
New Transformer Models
The following models are available from the amazing Spark NLP
3.3.0 and
3.3.1 releases
which includes NLP models for
Yiddish, Ukrainian, Telugu, Tamil, Somali, Sindhi, Russian, Punjabi, Nepali, Marathi, Malayalam, Kannada, Indonesian, Gujrati, Bosnian, Igbo, Ganda, Dholuo, Naija, Wolof,Kinyarwanda
27 new models in 7 Languages, including Japanese NER, resolution models for SNOMED, ICDO, CPT and RxNorm codes and much more in NLU 3.2.1
We are very excited to announce NLU 3.2.1!
This release comes with models 27 new models for 7 languages which are transformer based.
New NER-Classifiers, BertSentenceEmbeddings, BertEmbeddings and BertForTokenClassificationEmbeddings
for Japanese, German, Dutch, Swedish, Spanish, French and English.
For healthcare there are new Entity Resolvers and MedicalNerModels
for Snomed Conditions, Cpt Measurements, Icd0, Rxnorm Dispositions, Posology and Deidentification.
Finally, a new tutorial notebook and a webinar are available, which showcase almost every feature of NLU
for the over 50 Domains in Healthcare/Clinical/Biomedical/etc..
New Transformer Models
Models in Japanese, German, Dutch, Swedish, Spanish, French and English from the great Spark NLP 3.2.3 release
New Healthcare Transformer Models
Models for Snomed Conditions, Cpt Measurements, Icd0, Rxnorm Dispositions, Posology and Deidentification from the amazing Spark NLP 3.2.2 for Healthcare Release
| nlu.load() Refrences | Spark NLP Refrence | Annotater class | Language |
|---|---|---|---|
| en.resolve.snomed_conditions | sbertresolve_snomed_conditions | SentenceEntityResolverModel | en |
| en.resolve.cpt.procedures_measurements | sbiobertresolve_cpt_procedures_measurements_augmented | SentenceEntityResolverModel | en |
| en.resolve.icdo.base | sbiobertresolve_icdo_base | SentenceEntityResolverModel | en |
| en.resolve.rxnorm.disposition.sbert | sbertresolve_rxnorm_disposition | SentenceEntityResolverModel | en |
| en.resolve.rxnorm_disposition.sbert | sbertresolve_rxnorm_disposition | SentenceEntityResolverModel | en |
| en.med_ner.posology.experimental | ner_posology_experimental | MedicalNerModel | en |
| en.med_ner.deid.subentity_augmented | ner_deid_subentity_augmented | MedicalNerModel | en |
New Notebooks
Enhancements
- Columns of the Pandas DataFrame returned by NLU will now be sorted alphabetically
Bugfixes
- Fixed a bug that caused output levels no beeing inferred properly
- Fixed a bug that caused SentenceResolver visualizations not to appear.
100+ Transformers Models in 40+ languages, 3-D Streamlit Entity-Embedding-Manifold visualizations, Multi-Lingual NER, Longformers, TokenDistilBERT, Trainable Sentence Resolvers, 7% less memory usage and much more in NLU 3.2.0
We are extremely excited to announce the release of NLU 3.2.0
which marks the 1-year anniversary of the birth of this magical library.
This release packs features and improvements in every division of NLU's aspects,
89 new NLP models with new Models including Longformer, TokenBert, TokenDistilBert and Multi-Lingual NER for 40+ Languages.
12 new Healthcare models with trainable sentence resolvers and models Adverse Drug Relations, Clinical Token Bert Models, NER Models for Radiology, Drugs, Posology, Administration Cycles, RXNorm, and new Medical Assertion models.
New Streamlit visualizations enable you to see Entities in 3-D, 2-D, and 1-D Manifolds which are applicable to Entities and their Embeddings, Detected by Named-Entity-Recognizer models.
Finally, a ~7% decrease in Memory consumption in NLU's core which benefits every computation, achieved by leveraging Pyarrow.
We are incredibly thankful to our community, which helped us come this far, and are looking forward to another magical year of NLU!
Streamlit Entity Manifold visualization
function pipe.viz_streamlit_entity_embed_manifold
Visualize recognized entities by NER models via their Entity Embeddings in 1-D, 2-D, or 3-D by Reducing Dimensionality via 10+ Supported methods from Manifold Algorithms
and Matrix Decomposition Algorithms.
You can pick additional NER models and compare them via the GUI dropdown on the left.
- Reduces Dimensionality of high dimensional Entity Embeddings to
1-D,2-D, or3-Dand plot the resulting data in an interactivePlotlyplot - Applicable with any of the 330+ Named Entity Recognizer models
- Gemerates
NUM-DIMENSIONS*NUM-NER-MODELS*NUM-DIMENSION-REDUCTION-ALGOSplots
nlu.load('ner').viz_streamlit_sentence_embed_manifold(['Hello From John Snow Labs', 'Peter loves to visit New York'])or just run
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/09_entity_embedding_manifolds.py
function parameters pipe.viz_streamlit_sentence_embed_manifold
| Argument | Type | Default | Description |
|---|---|---|---|
default_texts |
List[str] |
"Donald Trump likes to visit New York", "Angela Merkel likes to visit Berlin!", 'Peter hates visiting Paris') | List of strings to apply classifiers, embeddings, and manifolds to. |
title |
str |
'NLU ❤️ Streamlit - Prototype your NLP startup in 0 lines of code🚀' |
Title of the Streamlit app |
sub_title |
Optional[str] |
"Apply any of the 10+ Manifold or Matrix Decomposition algorithms to reduce the dimensionality of Entity Embeddings to 1-D, 2-D and 3-D " |
Sub title of the Streamlit app |
default_algos_to_apply |
List[str] |
["TSNE", "PCA"] |
A list Manifold and Matrix Decomposition Algorithms to apply. Can be either 'TSNE','ISOMAP','LLE','Spectral Embedding', 'MDS','PCA','SVD aka LSA','DictionaryLearning','FactorAnalysis','FastICA' or 'KernelPCA', |
target_dimensions |
List[int] |
(1,2,3) |
Defines the target dimension embeddings will be reduced to |
show_algo_select |
bool |
True |
Show selector for Manifold and Matrix Decomposition Algorithms |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
num_cols |
int |
2 |
How many columns should for the layout in streamlit when rendering the similarity matrixes. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
n_jobs |
Optional[int] |
3 |
False |
Sentence Entity Resolver Training
Sentence Entity Resolver Training Tutorial Notebook
Named Entities are sub pieces in textual data which are labeled with classes.
These classes and strings are still ambiguous though and it is not possible to group semantically identically entities without any definition of terminology.
With the Sentence Resolver you can train a state-of-the-art deep learning architecture to map entities to their unique terminological representation.
Train a Sentence resolver on a dataset with columns named y , _y and text. y is a label, _y is an extra identifier label, text is the raw text
import pandas as pd
import nlu
dataset = pd.DataFrame({
'text': ['The Tesla company is good to invest is', 'TSLA is good to invest','TESLA INC. we should buy','PUT ALL MONEY IN TSLA inc!!'],
'y': ['23','23','23','23'],
'_y': ['TESLA','TESLA','TESLA','TESLA'],
})
trainable_pipe = nlu.load('train.resolve_sentence')
fitted_pipe = trainable_pipe.fit(dataset)
res = fitted_pipe.predict(dataset)
fitted_pipe.predict(["Peter told me to buy Tesla ", 'I have money to loose, is TSLA a good option?'])| sentence_resolution_resolve_sentence_confidence | sentence_resolution_resolve_sentence_code | sentence_resolution_resolve_sentence | sentence | |
|---|---|---|---|---|
| 0 | '1.0000' | '23' | 'TESLA' | 'The Tesla company is good to invest is' |
| 1 | '1.0000' | '23' | 'TESLA' | 'TSLA is good to invest' |
| 2 | '1.0000' | '23' | 'TESLA' | 'TESLA INC. we should buy' |
| 3 | '1.0000' | '23' | 'TESLA' | 'PUT ALL MONEY IN TSLA inc!!' |
Alternatively you can also use non-default healthcare embeddings.
trainable_pipe = nlu.load('en.embed.glove.biovec train.resolve_sentence')Transformer Models
New models from the spectacular Spark NLP 3.2.0 + releases are integrated.
89 new models in total, with new LongFormer, TokenBert, TokenDistilBert and Multi-Lingual NER for 40+ languages.
The supported languages with their ISO 639-1 code are : af, ar, bg, bn, de, el, en, es, et, eu, fa, fi, fr, he, hi, hu, id, it, ja, jv, ka, kk, ko, ml, mr, ms, my, nl, pt, ru, sw, ta, te, th, tl, tr, ur, vi, yo, and zh
| nlu.load() Refrence | Spark NLP Refrence | Annotator Class | language |
|---|---|---|---|
| en.embed.longformer | longformer_base_4096 | LongformerEmbeddings | en |
| en.embed.longformer.large | longformer_large_4096 | LongformerEmbeddings | en |
| en.ner.ontonotes_roberta_base | ner_ontonotes_roberta_base | NerDLModel | en |
| en.ner.ontonotes_roberta_large | ner_ontonotes_roberta_large | NerDLModel | en |
| en.ner.ontonotes_distilbert_base_cased | [ner_ontonotes_distilbert_base_cased](https://nlp.john... |
Sentence Embedding Visualizations, 20+ New Models, 2 New Trainable Models, Drug Normalizer and more in John Snow Labs NLU 3.1.1
We are very excited to announce NLU 3.1.1 has been released!
It features a new Sentence Embedding visualization component for Streamlit which supports all 10+ previous dimension
reduction techniques. Additionally, all embedding visualizations now support Latent Dirichlet Allocation for dimension reduction.
Finally, 2 new trainable models for NER and chunk resolution are supported, a new drug normalizer algorithm has been added,
20+ new pre-trained models including Multi-Lingual, German,
various healthcare models and improved NER defaults when using licensed models that have NER dependencies.
Streamlit Sentence Embedding visualization via Manifold and Matrix Decomposition algorithms
function pipe.viz_streamlit_sentence_embed_manifold
Visualize Sentence Embeddings in 1-D, 2-D, or 3-D by Reducing Dimensionality via 12 Supported methods from Manifold Algorithms
and Matrix Decomposition Algorithms.
Additionally, you can color the lower dimensional points with a label that has been previously assigned to the text by specifying a list of nlu references in the additional_classifiers_for_coloring parameter.
You can also select additional classifiers via the GUI.
- Reduces Dimensionality of high dimensional Sentence Embeddings to
1-D,2-D, or3-Dand plot the resulting data in an interactivePlotlyplot - Applicable with any of the 100+ Sentence Embedding models
- Color points by classifying with any of the 100+ Document Classifiers
- Gemerates
NUM-DIMENSIONS*NUM-EMBEDDINGS*NUM-DIMENSION-REDUCTION-ALGOSplots
text= """You can visualize any of the 100 + Sentence Embeddings
with 10+ dimension reduction algorithms
and view the results in 3D, 2D, and 1D
which can be colored by various classifier labels!
"""
nlu.load('embed_sentence.bert').viz_streamlit_sentence_embed_manifold(text)
function parameters pipe.viz_streamlit_sentence_embed_manifold
| Argument | Type | Default | Description |
|---|---|---|---|
default_texts |
List[str] |
("Donald Trump likes to party!", "Angela Merkel likes to party!", 'Peter HATES TO PARTTY!!!! :(') | List of strings to apply classifiers, embeddings, and manifolds to. |
text |
Optional[str] |
'Billy likes to swim' |
Text to predict classes for. |
sub_title |
Optional[str] |
"Apply any of the 11 Manifold or Matrix Decomposition algorithms to reduce the dimensionality of Sentence Embeddings to 1-D, 2-D and 3-D " |
Sub title of the Streamlit app |
default_algos_to_apply |
List[str] |
["TSNE", "PCA"] |
A list Manifold and Matrix Decomposition Algorithms to apply. Can be either 'TSNE','ISOMAP','LLE','Spectral Embedding', 'MDS','PCA','SVD aka LSA','DictionaryLearning','FactorAnalysis','FastICA' or 'KernelPCA', |
target_dimensions |
List[int] |
(1,2,3) |
Defines the target dimension embeddings will be reduced to |
show_algo_select |
bool |
True |
Show selector for Manifold and Matrix Decomposition Algorithms |
show_embed_select |
bool |
True |
Show selector for Embedding Selection |
show_color_select |
bool |
True |
Show selector for coloring plots |
display_embed_information |
bool |
True |
Show additional embedding information like dimension, nlu_reference, spark_nlp_reference, sotrage_reference, modelhub link and more. |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
num_cols |
int |
2 |
How many columns should for the layout in streamlit when rendering the similarity matrixes. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
additional_classifiers_for_coloring |
List[str] |
['sentiment.imdb'] |
List of additional NLU references to load for generting hue colors |
show_model_select |
bool |
True |
Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click |
model_select_position |
str |
'side' |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
n_jobs |
Optional[int] |
3 |
False |
General Streamlit enhancements
Support for Latent Dirichlet Allocation
The Latent Dirichlet Allocation algorithm is now supported
for the Word Embedding Visualizations and the Sentence Embedding Visualizations
Normalization of Vectors before calculating sentence similarity.
WordEmbedding vectors will now be normalized before calculating similarity scores, which bounds each similarity between 0 and 1
Control order of plots
You can now control the order in Which visualizations appear in the main GUI
Sentence Embedding Visualization
Chunk Entity Resolver Training
Chunk Entity Resolver Training Tutorial Notebook
Named Entities are sub pieces in textual data which are labeled with classes.
These classes and strings are still ambigous though and it is not possible to group semantically identically entities without any definition of terminology.
With the Chunk Resolver you can train a state-of-the-art deep learning architecture to map entities to their unique terminological representation.
Train a chunk resolver on a dataset with columns named y , _y and text. y is a label, _y is an extra identifier label, text is the raw text
import pandas as pd
dataset = pd.DataFrame({
'text': ['The Tesla company is good to invest is', 'TSLA is good to invest','TESLA INC. we should buy','PUT ALL MONEY IN TSLA inc!!'],
'y': ['23','23','23','23']
'_y': ['TESLA','TESLA','TESLA','TESLA'],
})
trainable_pipe = nlu.load('train.resolve_chunks')
fitted_pipe = trainable_pipe.fit(dataset)
res = fitted_pipe.predict(dataset)
fitted_pipe.predict(["Peter told me to buy Tesla ", 'I have money to loose, is TSLA a good option?'])| entity_resolution_confidence | entity_resolution_code | entity_resolution | document |
|---|---|---|---|
| '1.0000' | '23' | 'TESLA' | Peter told me to buy Tesla |
| '1.0000' | '23' | 'TESLA' | I have money to loose, is TSLA a good option? |
Train with default glove embeddings
untrained_chunk_resolver = nlu.load('train.resolve_chunks')
trained_chunk_resolver = untrained_chunk_resolver.fit(df)
trained_chunk_resolver.predict(df)Train with custom embeddings
# Use BIo GLove
untrained_chunk_resolver = nlu.load('en.embed.glove.biovec train.resolve_chunks')
trained_chunk_resolver = untrained_chunk_resolver.fit(df)
trained_chunk_resolver.predict(df)Rule based NER with Context Matcher
Rule based NER with context matching tutorial notebook
Define a rule-based NER algorithm by providing Regex Patterns and resolution mappings.
The confidence value is computed using a heuristic approach based on how many matches it has.
A dictionary can be pro...
2600+ New Models for 200+ Languages and 10+ Dimension Reduction Algorithms for Streamlit Word-Embedding visualizations in 3-D
We are extremely excited to announce the release of NLU 3.1 !
This is our biggest release so far and it comes with over 2600+ new models in 200+ languages, including DistilBERT, RoBERTa, and XLM-RoBERTa and Huggingface based Embeddings from the incredible Spark-NLP 3.1.0 release,
new Streamlit Visualizations for visualizing Word Embeddings in 3-D, 2-D, and 1-D,
New Healthcare pipelines for healthcare code mappings
and finally confidence extraction for open source NER models.
Additionally, the NLU Namespace has been renamed to the NLU Spellbook, to reflect the magicalness of each 1-liners represented by them!
Streamlit Word Embedding visualization via Manifold and Matrix Decomposition algorithms
function pipe.viz_streamlit_word_embed_manifold
Visualize Word Embeddings in 1-D, 2-D, or 3-D by Reducing Dimensionality via 11 Supported methods from Manifold Algorithms
and Matrix Decomposition Algorithms.
Additionally, you can color the lower dimensional points with a label that has been previously assigned to the text by specifying a list of nlu references in the additional_classifiers_for_coloring parameter.
- Reduces Dimensionality of high dimensional Word Embeddings to
1-D,2-D, or3-Dand plot the resulting data in an interactivePlotlyplot - Applicable with any of the 100+ Word Embedding models
- Color points by classifying with any of the 100+ Parts of Speech Classifiers or Document Classifiers
- Gemerates
NUM-DIMENSIONS*NUM-EMBEDDINGS*NUM-DIMENSION-REDUCTION-ALGOSplots
nlu.load('bert',verbose=True).viz_streamlit_word_embed_manifold(default_texts=THE_MATRIX_ARCHITECT_SCRIPT.split('\n'),default_algos_to_apply=['TSNE'],MAX_DISPLAY_NUM=5)
function parameters pipe.viz_streamlit_word_embed_manifold
| Argument | Type | Default | Description |
|---|---|---|---|
default_texts |
List[str] |
("Donald Trump likes to party!", "Angela Merkel likes to party!", 'Peter HATES TO PARTTY!!!! :(') | List of strings to apply classifiers, embeddings, and manifolds to. |
text |
Optional[str] |
'Billy likes to swim' |
Text to predict classes for. |
sub_title |
Optional[str] |
"Apply any of the 11 Manifold or Matrix Decomposition algorithms to reduce the dimensionality of Word Embeddings to 1-D, 2-D and 3-D " |
Sub title of the Streamlit app |
default_algos_to_apply |
List[str] |
["TSNE", "PCA"] |
A list Manifold and Matrix Decomposition Algorithms to apply. Can be either 'TSNE','ISOMAP','LLE','Spectral Embedding', 'MDS','PCA','SVD aka LSA','DictionaryLearning','FactorAnalysis','FastICA' or 'KernelPCA', |
target_dimensions |
List[int] |
(1,2,3) |
Defines the target dimension embeddings will be reduced to |
show_algo_select |
bool |
True |
Show selector for Manifold and Matrix Decomposition Algorithms |
show_embed_select |
bool |
True |
Show selector for Embedding Selection |
show_color_select |
bool |
True |
Show selector for coloring plots |
MAX_DISPLAY_NUM |
int |
100 |
Cap maximum number of Tokens displayed |
display_embed_information |
bool |
True |
Show additional embedding information like dimension, nlu_reference, spark_nlp_reference, sotrage_reference, modelhub link and more. |
set_wide_layout_CSS |
bool |
True |
Whether to inject custom CSS or not. |
num_cols |
int |
2 |
How many columns should for the layout in streamlit when rendering the similarity matrixes. |
key |
str |
"NLU_streamlit" |
Key for the Streamlit elements drawn |
additional_classifiers_for_coloring |
List[str] |
['pos', 'sentiment.imdb'] |
List of additional NLU references to load for generting hue colors |
show_model_select |
bool |
True |
Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click |
model_select_position |
str |
'side' |
Whether to output the positions of predictions or not, see pipe.predict(positions=true) for more info |
show_logo |
bool |
True |
Show logo |
display_infos |
bool |
False |
Display additonal information about ISO codes and the NLU namespace structure. |
n_jobs |
Optional[int] |
3 |
False |
Larger Example showcasing more dimension reduction techniques on a larger corpus :

Supported Manifold Algorithms
Supported Matrix Decomposition Algorithms
New Healthcare Pipelines Pipelines
Five new healthcare code mapping pipelines:
nlu.load(en.resolve.icd10cm.umls): This pretrained pipeline maps ICD10CM codes to UMLS codes without using any text data. You’ll just feed white space-delimited ICD10CM codes and it will return the corresponding UMLS codes as a list. If there is no mapping, the original code is returned with no mapping.
{'icd10cm': ['M89.50', 'R82.2', 'R09.01'],'umls': ['C4721411', 'C0159076', 'C0004044']}
nlu.load(en.resolve.mesh.umls): This pretrained pipeline maps MeSH codes to UMLS codes without using any text data. You’ll just feed white space-delimited MeSH codes and it will return the corresponding UMLS codes as a list. If there is no mapping, the original code is returned with no mapping.
{'mesh': ['C028491', 'D019326', 'C579867'],'umls': ['C0970275', 'C0886627', 'C3696376']}
nlu.load(en.resolve.rxnorm.umls): This pretrained pipeline maps RxNorm codes to UMLS codes without using any text data. You’ll just feed white space-delimited RxNorm codes and it will return the corresponding UMLS codes as a list. If there is no mapping, the original code is returned with no mapping.
{'rxnorm': ['1161611', '315677', '343663'],'umls': ['C3215948', 'C0984912', 'C1146501']}
nlu.load(en.resolve.rxnorm.mesh): This pretrained pipeline maps RxNorm codes to MeSH codes without using any text data. You’ll just feed white space-delimited RxNorm codes and it will return the corresponding MeSH codes as a list. If there is no mapping, the original code is returned with no mapping.
{'rxnorm': ['1191', '6809', '47613'],'mesh': ['D001241', 'D008687', 'D019355']}
nlu.load(en.resolve.snomed.umls): This pretrained pipeline maps SNOMED codes to UMLS codes without using any text...
Streamlit visualizations, improved T5, models for Farsi, Hebrew, Korean, Turkish and UMLS, LOINC, HPO, Resolvers in NLU 3.0.2
This release contains examples and tutorials on how to visualize the 1000+ state-of-the-art NLP models provided by NLU in just 1 line of code in streamlit.
It includes simple 1-liners you can sprinkle into your Streamlit app to for features like Dependency Trees, Named Entities (NER), text classification results, semantic simmilarity,
embedding visualizations via ELMO, BERT, ALBERT, XLNET and much more . Additionally, improvements for T5, various resolvers have been added and models Farsi, Hebrew, Korean, and Turkish
This is the ultimate NLP research tool. You can visualize and compare the results of hundreds of context aware deep learning embeddings and compare them with classical vanilla embeddings like Glove
and can see with your own eyes how context is encoded by transformer models like BERT or XLNETand many more !
Besides that, you can also compare the results of the 200+ NER models John Snow Labs provides and see how peformances changes with varrying ebeddings, like Contextual, Static and Domain Specific Embeddings.
Install
For detailed instructions refer to the NLU install documentation here
You need Open JDK 8 installed and the following python packages
pip install nlu streamlit pyspark==3.0.1 sklearn plotly Problems? Connect with us on Slack!
Impatient and want some action?
Just run this Streamlit app, you can use it to generate python code for each NLU-Streamlit building block
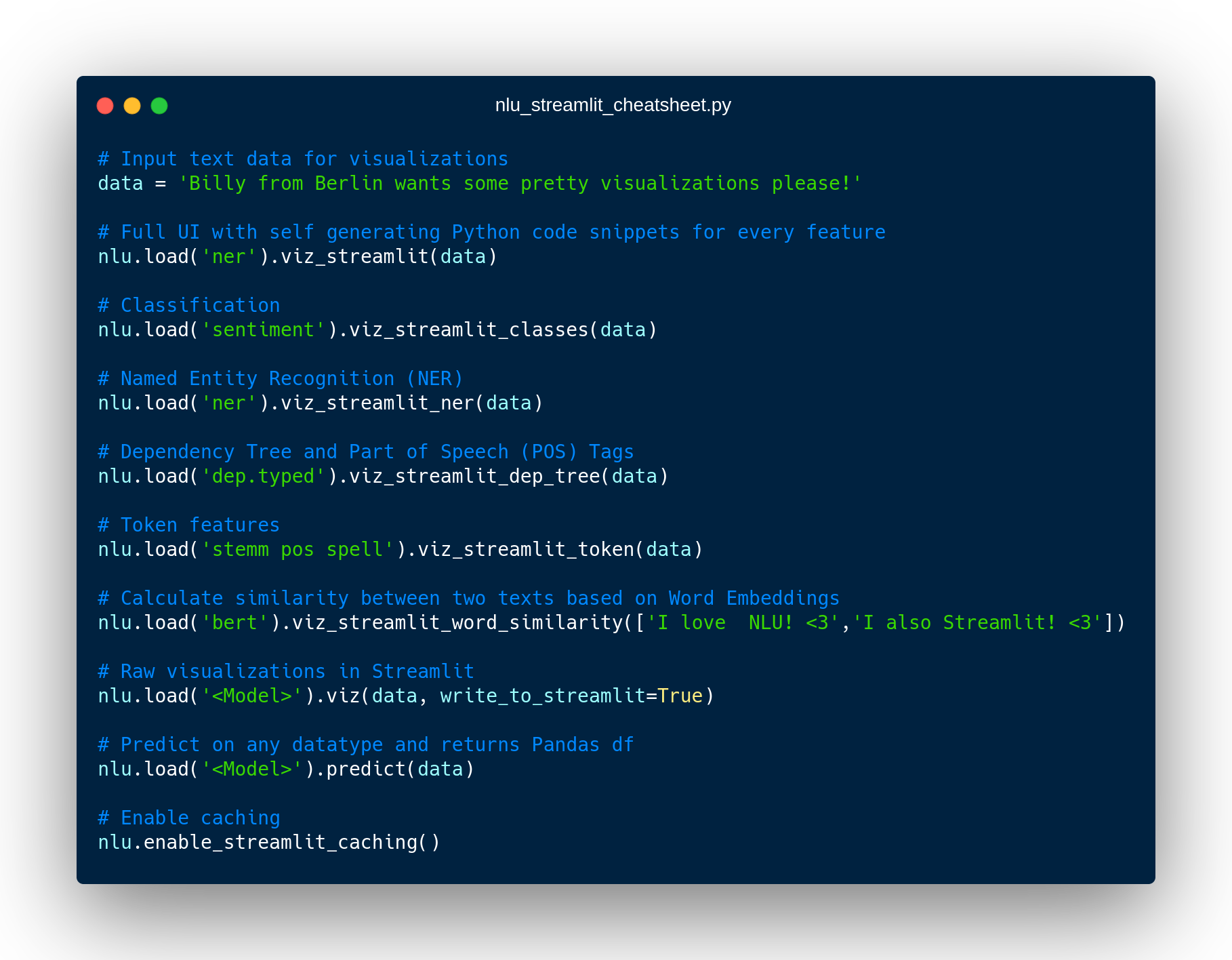
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/01_dashboard.pyQuick Starter cheat sheet - All you need to know in 1 picture for NLU + Streamlit
For NLU models to load, see the NLU Namespace or the John Snow Labs Modelshub or go straight to the source.
Examples
Just try out any of these.
You can use the first example to generate python-code snippets which you can
recycle as building blocks in your streamlit apps!
Example: 01_dashboard
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/01_dashboard.pyExample: 02_NER
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/02_NER.pyExample: 03_text_similarity_matrix
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/03_text_similarity_matrix.pyExample: 04_dependency_tree
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/04_dependency_tree.pyExample: 05_classifiers
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/05_classifiers.pyExample: 06_token_features
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/06_token_features.pyHow to use NLU?
All you need to know about NLU is that there is the nlu.load() method which returns a NLUPipeline object
which has a .predict() that works on most common data types in the pydata stack like Pandas dataframes .
Ontop of that, there are various visualization methods a NLUPipeline provides easily integrate in Streamlit as re-usable components. viz() method
Overview of NLU + Streamlit buildingblocks
| Method | Description |
|---|---|
nlu.load('<Model>').predict(data) |
Load any of the 1000+ models by providing the model name any predict on most Pythontic data strucutres like Pandas, strings, arrays of strings and more |
nlu.load('<Model>').viz_streamlit(data) |
Display full NLU exploration dashboard, that showcases every feature avaiable with dropdown selectors for 1000+ models |
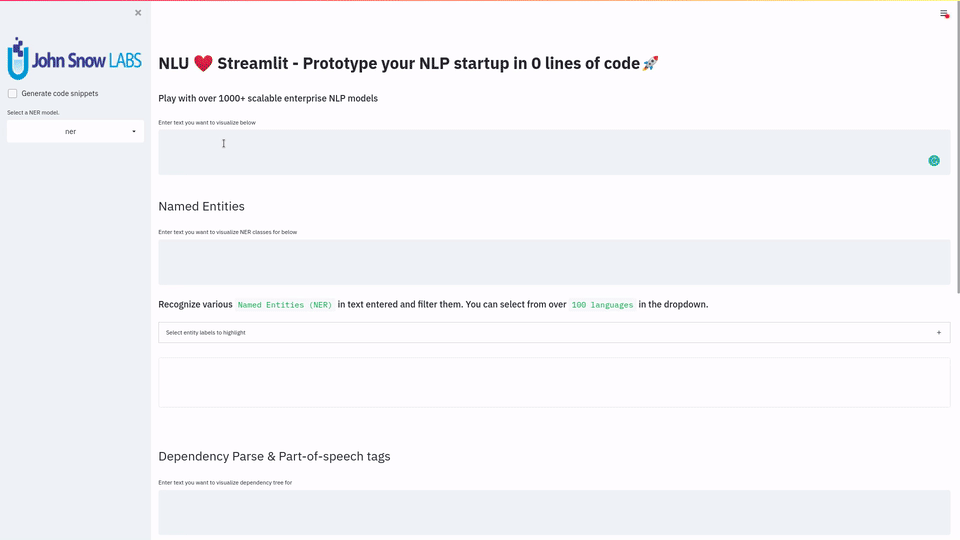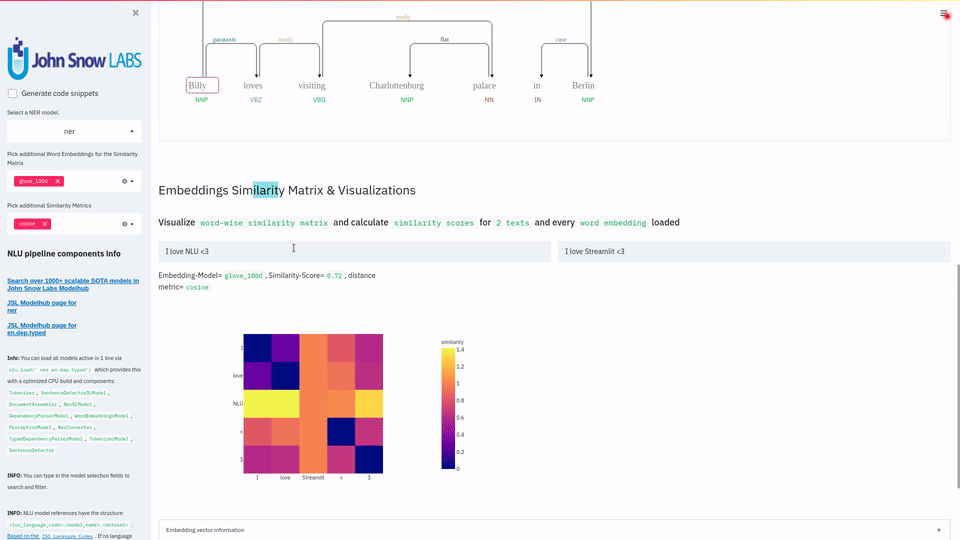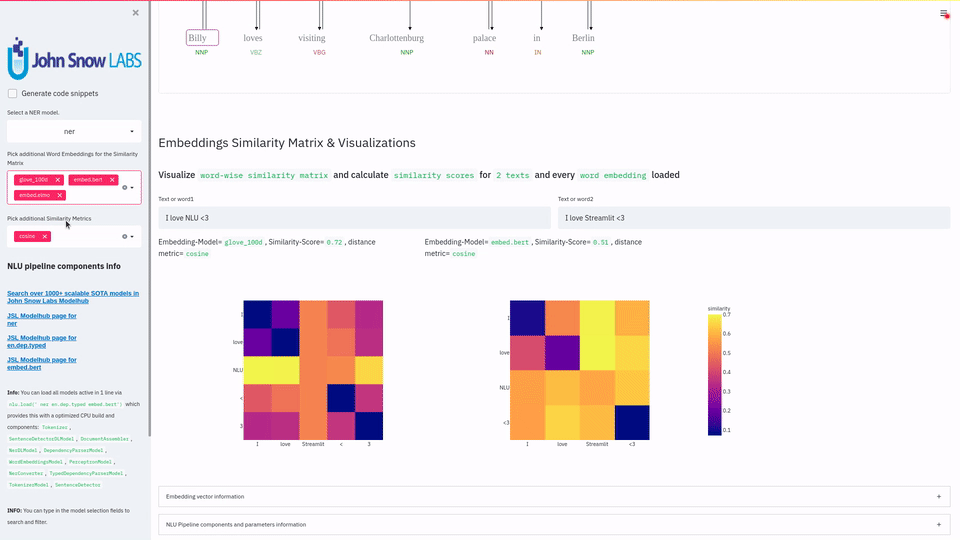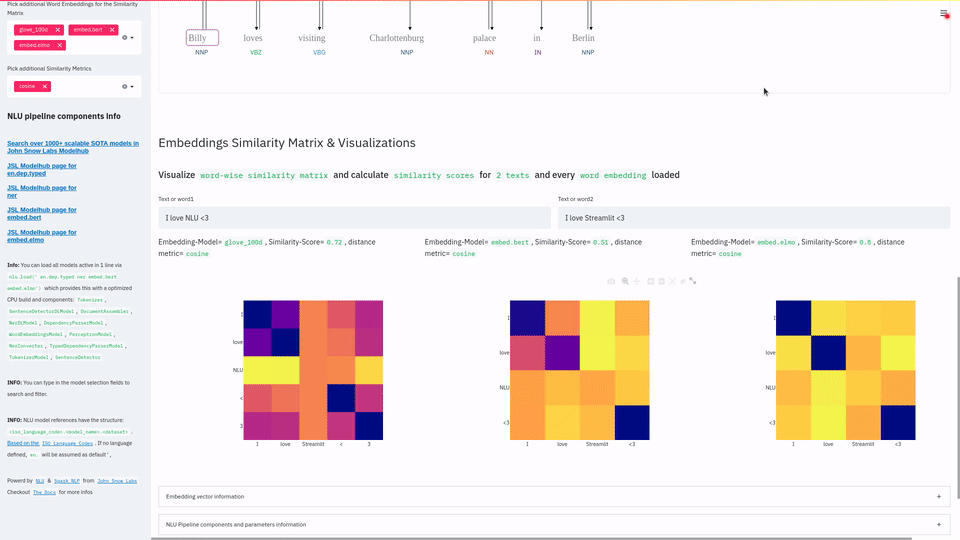
nlu.load('<Model>').viz_streamlit_similarity([string1, string2]) |
Display similarity matrix and scalar similarity for every word embedding loaded and 2 strings. |
nlu.load('<Model>').viz_streamlit_ner(data) |
Visualize predicted NER tags from Named Entity Recognizer model |
nlu.load('<Model>').viz_streamlit_dep_tree(data) |
Visualize Dependency Tree together with Part of Speech labels |
nlu.load('<Model>').viz_streamlit_classes(data) |
Display all extracted class features and confidences for every classifier loaded in pipeline |
nlu.load('<Model>').viz_streamlit_token(data) |
Display all detected token features and informations in Streamlit |
nlu.load('<Model>').viz(data, write_to_streamlit=True) |
Display the raw visualization without any UI elements. See viz docs for more info. By default all aplicable nlu model references will be shown. |
nlu.enable_streamlit_caching() |
Enable caching the nlu.load() call. Once enabled, the nlu.load() method will automatically cached. This is recommended to run first and for large peformance gans |
Detailed visualizer information and API docs
function pipe.viz_streamlit
Display a highly configurable UI that showcases almost every feature available for Streamlit visualization with model selection dropdowns in your applications.
Ths includes :
Similarity Matrix&Scalars&Embedding Informationfor any of the 100+ Word Embedding ModelsNER visualizationsfor any of the 200+ Named entity recognizersLabled&Unlabled Dependency Trees visualizationswithPart of Speech Tagsfor any of the 100+ Part of Speech ModelsToken informationspredicted by any of the 1000+ modelsClassification resultspredicted by any of the 100+ models classification modelsPipeline Configuration&Model Information&Link to John Snow Labs Modelshubfor all loaded pipelinesAuto generate Python codethat can be copy pasted to re-create the individual Streamlit visualization blocks.
NlLU takes the first model specified asnlu.load()for the first visualization run.
Once the Streamlit app is running, additional models can easily be added via the UI.
It is recommended to run this first, since you can generate Python code snippetsto recreate individual Streamlit visualization blocks
nlu.load('ner').viz_streamlit(['I love NLU and Streamlit!','I hate buggy software'])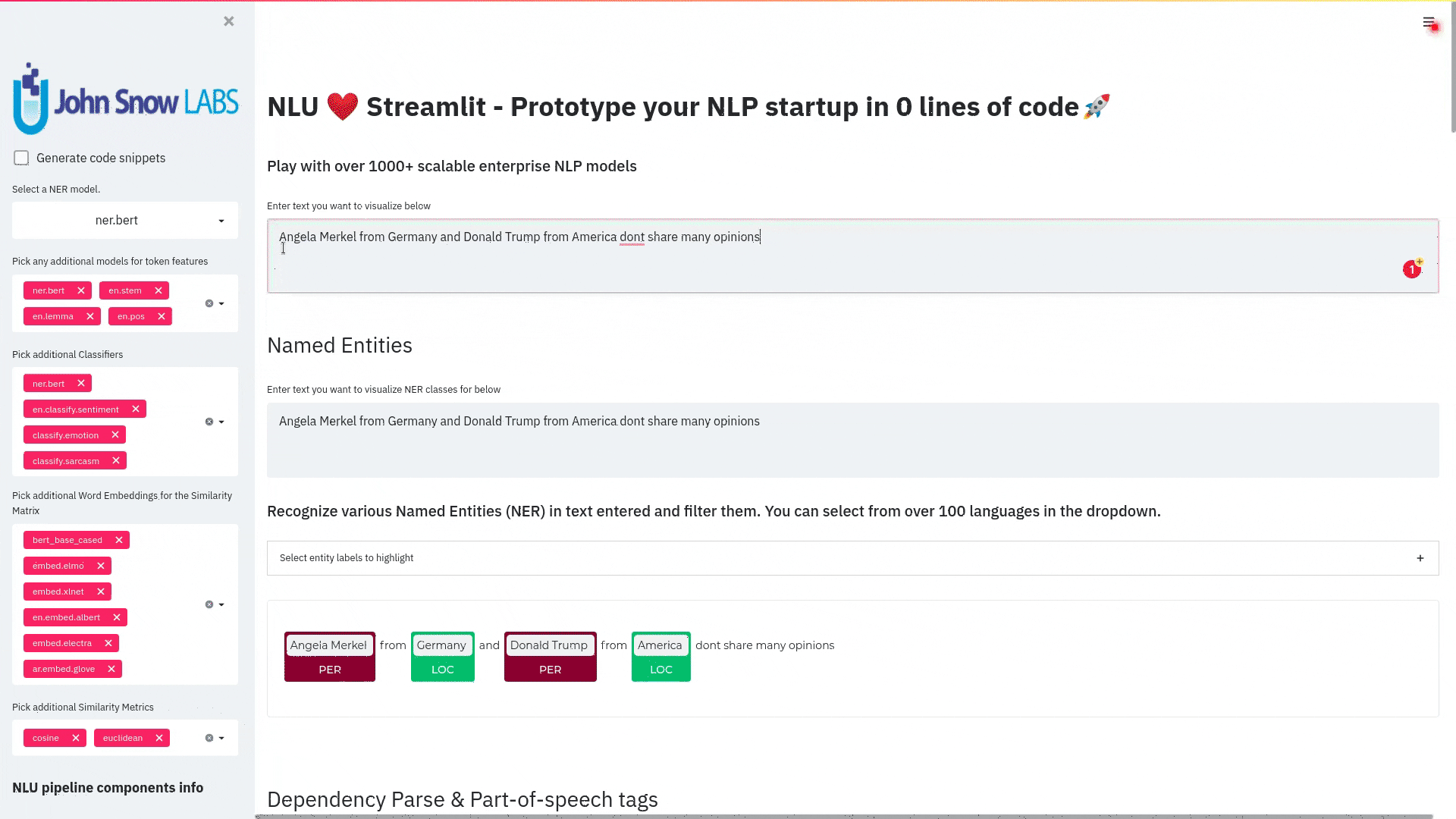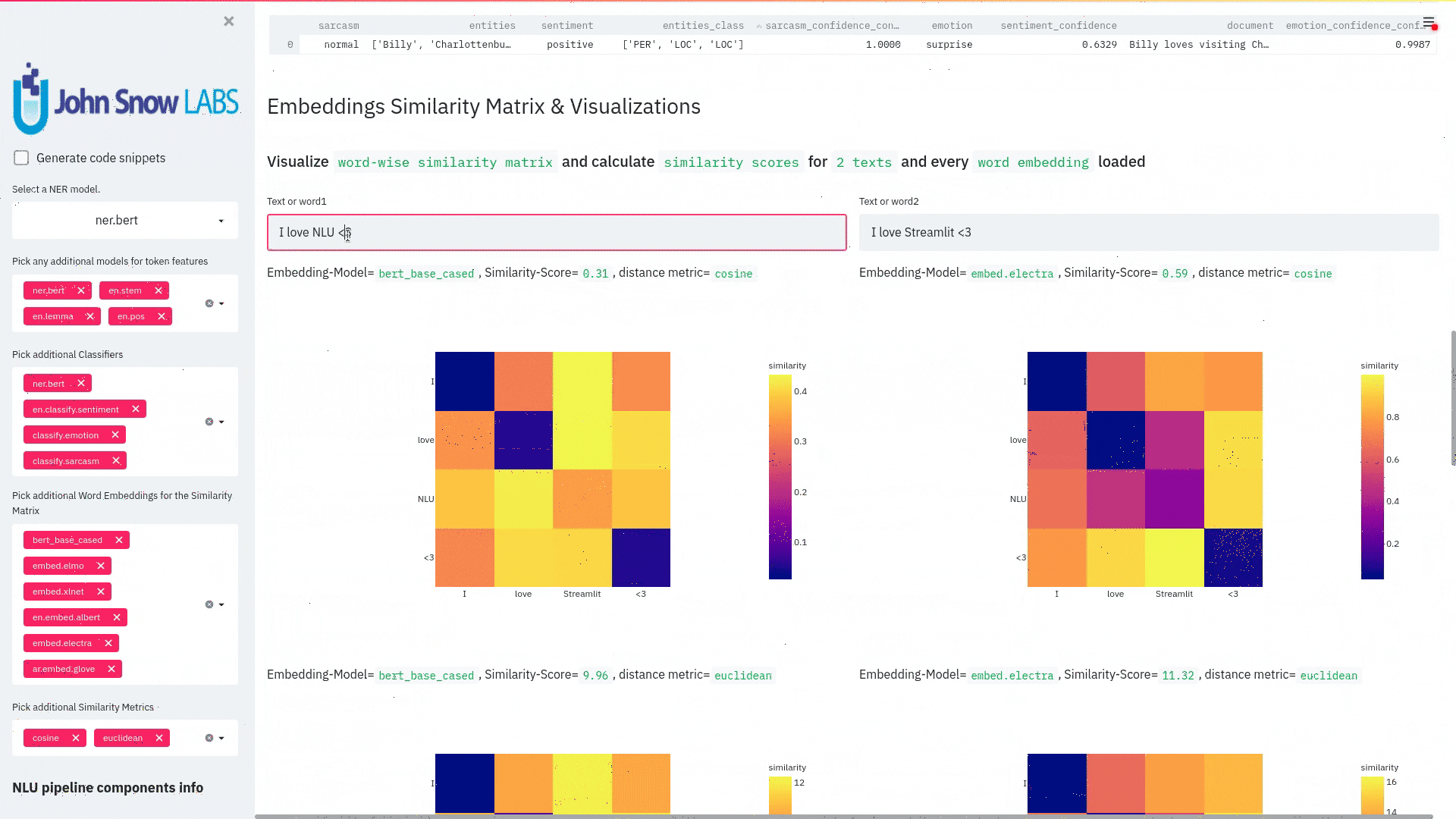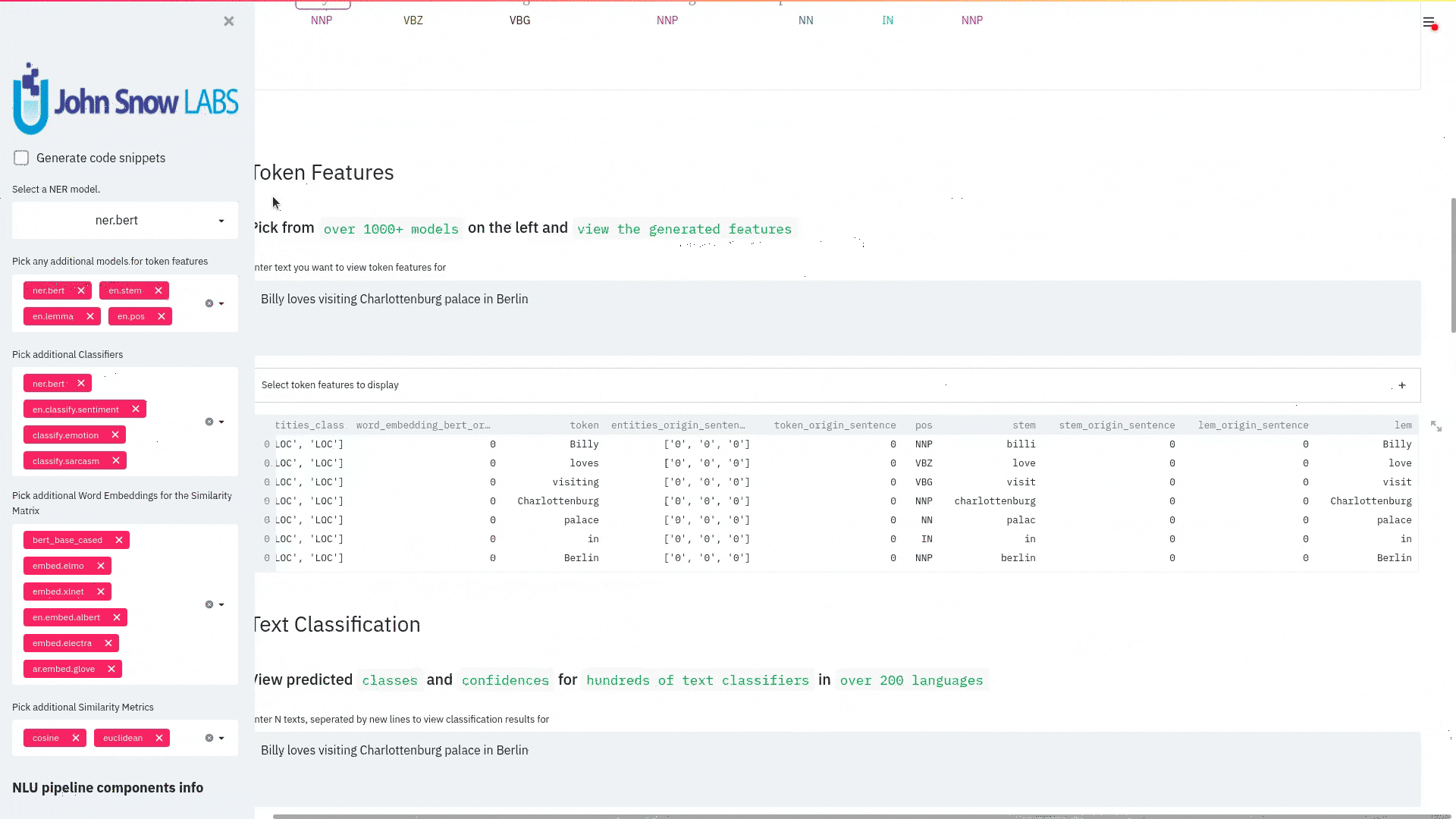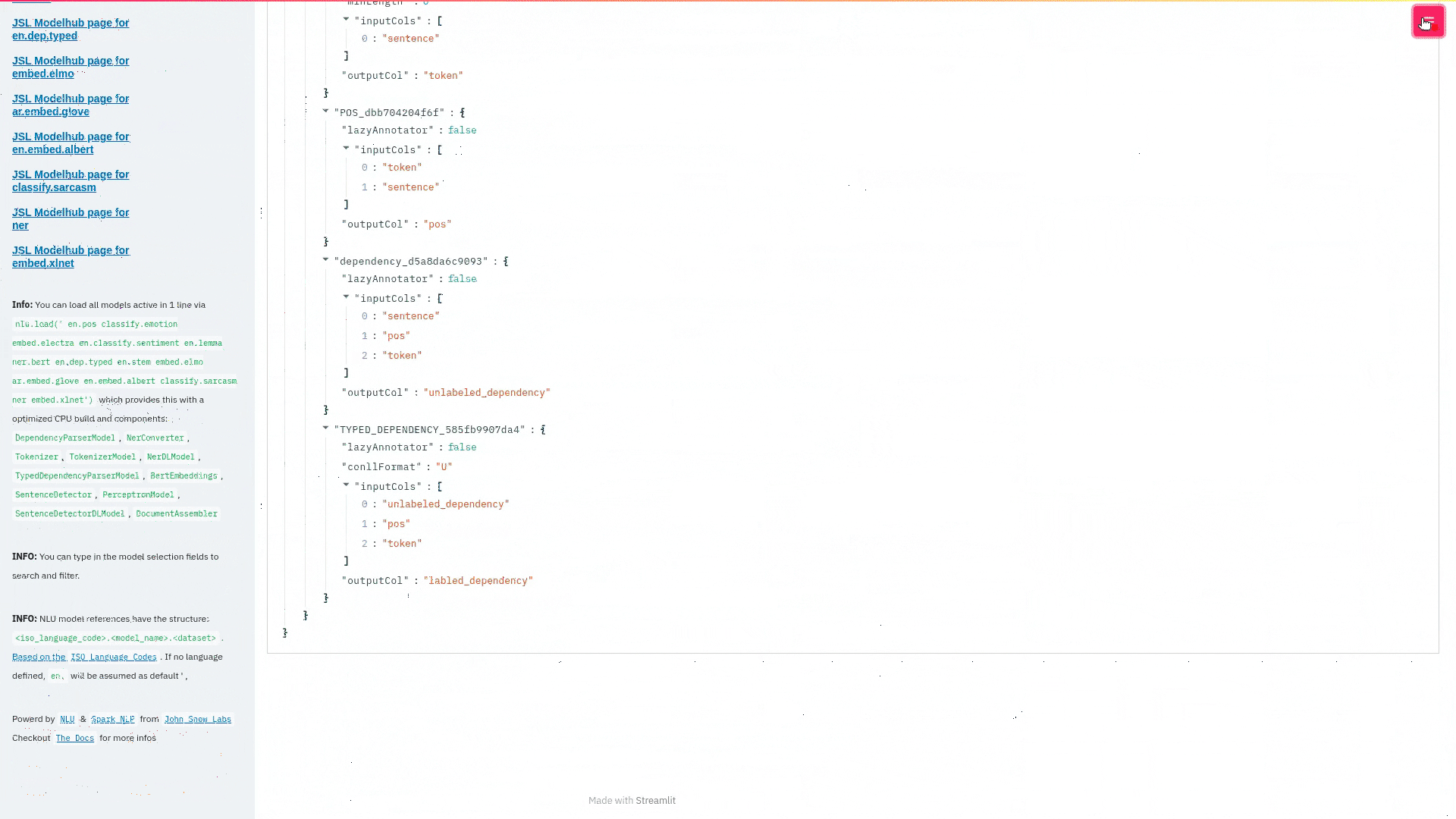
function parameters pipe.viz_streamlit
| Argument | Type | Default | Description |
|---|---|---|---|
text |
Union [str, List[str], pd.DataFrame, pd.Series] |
'NLU and Streamlit go together like peanutbutter and jelly' |
Default text for the Classification, Named Entitiy Recognizer, Token Information and Dependency Tree visualizations |
similarity_texts |
Union[List[str],Tuple[str,str]] |
('Donald Trump Likes to part', 'Angela Merkel likes to party') |
Default texts for the Text similarity visualization. Should contain exactly 2 strings which will be compared token embedding wise. For each embedding active, a token wise similarity matrix and a similarity scalar |
model_selection |
List[str] |
[] |
List of nlu references to display in the model selector, see [the NLU Namespace](https://nlu.johnsno... |