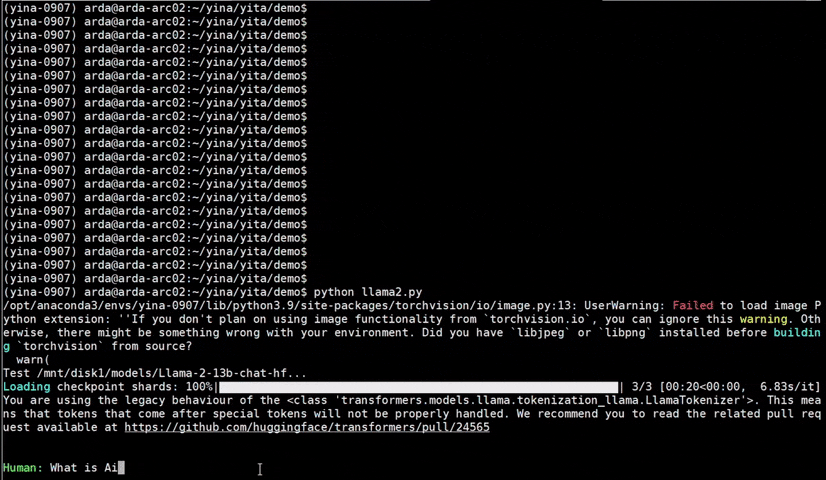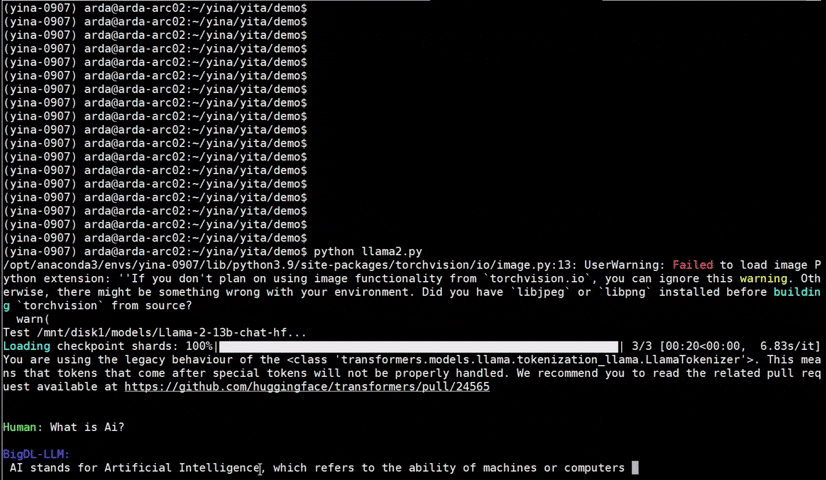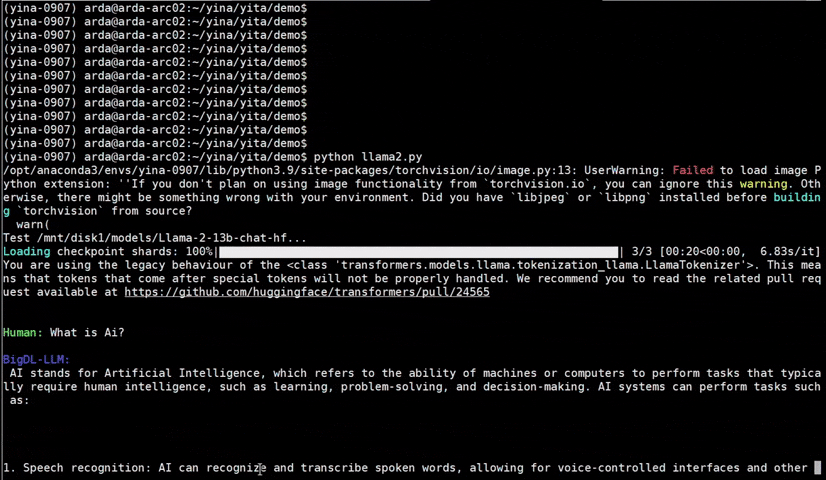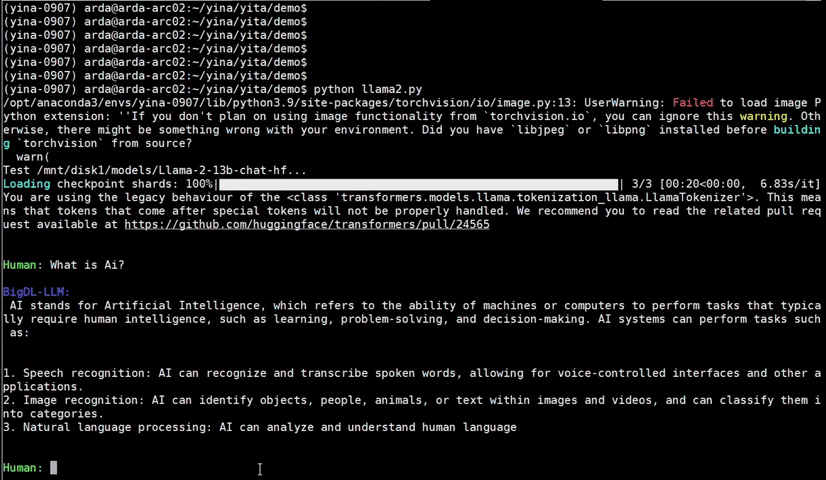
Important
bigdl-llm has now become ipex-llm (see the migration guide here); you may find the original BigDL project here.
IPEX-LLM is a PyTorch library for running LLM on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) with very low latency1.
Note
- It is built on top of Intel Extension for PyTorch (
IPEX), as well as the excellent work ofllama.cpp,bitsandbytes,vLLM,qlora,AutoGPTQ,AutoAWQ, etc. - It provides seamless integration with llama.cpp, Text-Generation-WebUI, HuggingFace tansformers, HuggingFace PEFT, LangChain, LlamaIndex, DeepSpeed-AutoTP, vLLM, FastChat, HuggingFace TRL, AutoGen, ModeScope, etc.
- 50+ models have been optimized/verified on
ipex-llm(including LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, RWKV, and more); see the complete list here.
- [2024/03]
bigdl-llmhas now becomeipex-llm(see the migration guide here); you may find the originalBigDLproject here. - [2024/02]
ipex-llmnow supports directly loading model from ModelScope (魔搭). - [2024/02]
ipex-llmadded inital INT2 support (based on llama.cpp IQ2 mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM. - [2024/02] Users can now use
ipex-llmthrough Text-Generation-WebUI GUI. - [2024/02]
ipex-llmnow supports Self-Speculative Decoding, which in practice brings ~30% speedup for FP16 and BF16 inference latency on Intel GPU and CPU respectively. - [2024/02]
ipex-llmnow supports a comprehensive list of LLM finetuning on Intel GPU (including LoRA, QLoRA, DPO, QA-LoRA and ReLoRA). - [2024/01] Using
ipex-llmQLoRA, we managed to finetune LLaMA2-7B in 21 minutes and LLaMA2-70B in 3.14 hours on 8 Intel Max 1550 GPU for Standford-Alpaca (see the blog here).
More updates
- [2023/12]
ipex-llmnow supports ReLoRA (see "ReLoRA: High-Rank Training Through Low-Rank Updates"). - [2023/12]
ipex-llmnow supports Mixtral-8x7B on both Intel GPU and CPU. - [2023/12]
ipex-llmnow supports QA-LoRA (see "QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models"). - [2023/12]
ipex-llmnow supports FP8 and FP4 inference on Intel GPU. - [2023/11] Initial support for directly loading GGUF, AWQ and GPTQ models into
ipex-llmis available. - [2023/11]
ipex-llmnow supports vLLM continuous batching on both Intel GPU and CPU. - [2023/10]
ipex-llmnow supports QLoRA finetuning on both Intel GPU and CPU. - [2023/10]
ipex-llmnow supports FastChat serving on on both Intel CPU and GPU. - [2023/09]
ipex-llmnow supports Intel GPU (including iGPU, Arc, Flex and MAX). - [2023/09]
ipex-llmtutorial is released.
See the optimized performance of chatglm2-6b and llama-2-13b-chat models on 12th Gen Intel Core CPU and Intel Arc GPU below.
| 12th Gen Intel Core CPU | Intel Arc GPU | ||
|
|
|
|
chatglm2-6b |
llama-2-13b-chat |
chatglm2-6b |
llama-2-13b-chat |
- Windows GPU: installing
ipex-llmon Windows with Intel GPU - Linux GPU: installing
ipex-llmon Linux with Intel GPU - Docker: using
ipex-llmdockers on Intel CPU and GPU - For more details, please refer to the installation guide
- llama.cpp: running ipex-llm for llama.cpp (using C++ interface of
ipex-llmas an accelerated backend forllama.cppon Intel GPU) - vLLM: running
ipex-llminvLLMon both Intel GPU and CPU - FastChat: running
ipex-llminFastChatserving on on both Intel GPU and CPU - LangChain-Chatchat RAG: running
ipex-llminLangChain-Chatchat(Knowledge Base QA using RAG pipeline) - Text-Generation-WebUI: running
ipex-llminoobaboogaWebUI - Benchmarking: running (latency and throughput) benchmarks for
ipex-llmon Intel CPU and GPU
- Low bit inference
- INT4 inference: INT4 LLM inference on Intel GPU and CPU
- FP8/FP4 inference: FP8 and FP4 LLM inference on Intel GPU
- INT8 inference: INT8 LLM inference on Intel GPU and CPU
- INT2 inference: INT2 LLM inference (based on llama.cpp IQ2 mechanism) on Intel GPU
- FP16/BF16 inference
- FP16 LLM inference on Intel GPU, with possible self-speculative decoding optimization
- BF16 LLM inference on Intel CPU, with possible self-speculative decoding optimization
- Save and load
- Low-bit models: saving and loading
ipex-llmlow-bit models - GGUF: directly loading GGUF models into
ipex-llm - AWQ: directly loading AWQ models into
ipex-llm - GPTQ: directly loading GPTQ models into
ipex-llm
- Low-bit models: saving and loading
- Finetuning
- Integration with community libraries
- Tutorials
For more details, please refer to the ipex-llm document website.
Over 50 models have been optimized/verified on ipex-llm, including LLaMA/LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM2/ChatGLM3, Baichuan/Baichuan2, Qwen/Qwen-1.5, InternLM and more; see the list below.
| Model | CPU Example | GPU Example |
|---|---|---|
| LLaMA (such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.) | link1, link2 | link |
| LLaMA 2 | link1, link2 | link |
| ChatGLM | link | |
| ChatGLM2 | link | link |
| ChatGLM3 | link | link |
| Mistral | link | link |
| Mixtral | link | link |
| Falcon | link | link |
| MPT | link | link |
| Dolly-v1 | link | link |
| Dolly-v2 | link | link |
| Replit Code | link | link |
| RedPajama | link1, link2 | |
| Phoenix | link1, link2 | |
| StarCoder | link1, link2 | link |
| Baichuan | link | link |
| Baichuan2 | link | link |
| InternLM | link | link |
| Qwen | link | link |
| Qwen1.5 | link | link |
| Qwen-VL | link | link |
| Aquila | link | link |
| Aquila2 | link | link |
| MOSS | link | |
| Whisper | link | link |
| Phi-1_5 | link | link |
| Flan-t5 | link | link |
| LLaVA | link | link |
| CodeLlama | link | link |
| Skywork | link | |
| InternLM-XComposer | link | |
| WizardCoder-Python | link | |
| CodeShell | link | |
| Fuyu | link | |
| Distil-Whisper | link | link |
| Yi | link | link |
| BlueLM | link | link |
| Mamba | link | link |
| SOLAR | link | link |
| Phixtral | link | link |
| InternLM2 | link | link |
| RWKV4 | link | |
| RWKV5 | link | |
| Bark | link | link |
| SpeechT5 | link | |
| DeepSeek-MoE | link | |
| Ziya-Coding-34B-v1.0 | link | |
| Phi-2 | link | link |
| Yuan2 | link | link |
| Gemma | link | link |
| DeciLM-7B | link | link |
| Deepseek | link | link |
Footnotes
-
Performance varies by use, configuration and other factors.
ipex-llmmay not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. ↩