Looking for the Best SQL On File Tool for Analyst
SQL is database-based. That means files need to be first loaded into the database before we can process them with the popular query language. The data loading is not always convenient. So tools that can directly execute SQL on files were designed to avoid troubles. These tools differ widely in working environment, usability, SQL execution capability and format requirement. I tried a number of them and found that esProc is the easiest and most efficient to use for data analysts. Let me explain my findings. Go to Looking for the Best SQL-On-File Tool for Analyst for more infomation.
After nearly 50 years of evolution, SQL has become a popular, mature and convenient to use query language. Its users include programmers, data analysts and scientific researchers. The language is supported by a wide variety of platforms, such as Access language on single machine, MySQL on LAN and Hadoop on cloud.
But to use the familiar language to process data stored in files of formats like CSV/TSV/XLS, we need to first load data into the database. That’s time and effort-consuming because you need to create table structure, name the fields, set data type, allocate privileges and then sit and wait while the file is being loaded. It’s terrible when there are several or more files to be loaded because the data size becomes large, even huge, and you need to deal with the insufficient table space or the repeated loading due to regular updates.
That is not the worst. Some files cannot be loaded into the database; some are unprocessable even we manage to get them in. Often they contain useless data at the beginning or at the end and illegal separators (like invisible characters and double characters), or have unstandardized text formats, such as one line corresponding to multiple records. In those cases the reasonable way is to compute them a programming language like Python or JAVA. Here’s one of the example:
name,state,trips
Smith,Colorado,2020-01-02 2020-01-05 2010-02-03
Jeff,Connecticut,2020-01-09
Smith,Indiana,2020-01-21 2020-02-10
Besides, most of the databases don’t support importing XLSX files. You need to install Excel or a third-party tool to be able to put them in. Both are hassles and headaches. With Excel an XLSX file needs to be converted into a CSV to be loaded in. With a third-party tool you can load them in directly but have to finish the complex configurations first. Sometimes the tool only supports XLS files and other times they support the lower versions of XLSX only.
All in all, loading files to database is not convenient at all.
If there is a tool that can directly execute SQL on files, data loading will be unnecessary. No loading troubles and higher efficiency. What’s more, the database will be no longer needed. It is cost-effective.
Great promise as such a tool holds, they have rolled off one after another.
But defects exist. Some are fatal. Let me walk you through them to find their true power. The lightweight command line tool is my first target.
csvsql is intrinsically compact and quick. To group a sales.csv file that has column headers by client and sum amount over each group, you just need a single line:
D:\csvkit\csvsql\bin> csvsql --query "select client, sum(amount) from'sales'group by client" salse.csv
Unfortunately csvsql has far more disadvantages. The biggest one is complex installment and configurations. As it isn’t an independent application but is only a Python script, users need to configure a Python environment and download appropriate function library to be able to use the third-party applications. It’s easy for programmers but not for data analysts.
csvsql doesn’t have its own computing engine. That’s the second biggest problem. It has a built-in SQLite database. It will start it in the IN-MEMORY mode after you finish the SQL query, create a table, load the file into SQLite, translate the SQL-on-file into SQL-on-database-table and then execute the database translation.
The lack of an independent computing engine leads to limited SQL capabilities. csvsql has to design a set of SQL syntax according to SQLite implementations and translate the SQL-on-file query into the SQL-on-database-table query. Without a solid technological foundation, the tool has no choice but follows suit. It cannot attend to every aspect in translation and thus gives up many basic features, such as the fuzzy query and date function that SQLites supports.
Other consequences are low performance and file size limitation. csvsql doesn’t truly execute SQL over the file but it imports the file into the memory for processing. Plus type conversion, this is time-consuming and performance-compromised. The file expands a lot after being imported from disk to memory. If the file size is bigger than the memory space, data loading will extremely slow and it will be very likely to have a memory overflow. So you must make sure the file is of a proper size.
Such disadvantages are due to csvsql’s weak technological position. This explains its other disadvantages.
The tool supports text files only. Even the Excel files commonly and daily used are not covered. That’s the third disadvantage.
The fourth one is that it imposes too much on text format. It can read the most basic CSV format only. To achieve features like separator definition, line skipping and column headers identification in the first row, you need to do the preprocess using a text editor. If there is useless data at the beginning or at the end, illegal separators (invisible characters and double characters) or if the file has an unstandardized format, you need to do the preprocess using programming languages like Python and JAVA.
There are many similar command line tools, such as textql, queryscv.py and q. All is essentially identical, and they share same weaknesses.
Though the command line tools don’t have their own computing engines, the database systems have. HSQLDB is such a popular SQL-on-file database.
A database system reflects its manufacturer’s technological strength. HSQLDB not only has its own computing engine but provides powerful SQL syntax from join query and subquery to fuzzy query and data functions. That’s unmatched by command line tools.
But it’s not easy to install, administer and maintain a database system. Maintenance is particularly complex. It involves allocation of privileges, disk space, memory space and buffer space and configurations of various complicated parameters. They are rather difficult for data analysts. Actually an important reason that we want to execute SQL directly over files is to avoid database maintenance.
In addition to the complicated daily maintenance and administration, the steps of executing SQL are not simple.
The format of the command for starting up the HSQLDB server and client is complicated (Of course you can choose a third-party client tool, like SQuirreL SQL, to do that).
D:\jre1.8\bin>java –Xms128m –Xmx2403m -cp d:\hsql\hsqldb.jar org.hsqldb.server.Server -database.0 file\hsql\database\demo -dbname.0 demo
D:\jre1.8\bin>java -Xms128m -Xmx2403m -cp d:\hsql\hsqldb.jar org.hsqldb.util.DatabaseManager
That’s intimidating for a Java nonspecialist.
The parameter configurations for connecting to server from the client are not simple, too.

Before executing the SQL query, a number of preprocessing statements need to be executed to delete table names that possibly already exist, create new table structure and map files onto the table. The mapping requires a lot of parameter configurations, as shown below:
SET TABLE sales SOURCE "sales.csv;fs=,;encoding=UTF-8;quoted=false;ignore_first=true; cache_scale=100";
On top of the complex procedure, HSQLDB is designed to be user-unfriendly and performance-compromised. It doesn’t support auto-parsing data type, so users have to create their own table structures. Many files, especially CSVs, record field names on the first line. That’s convenient to use. But HSQLDB requires users to specifically specify field names. That makes the ready-to-use field names completely useless. The database imposes buffering a file to the memory beforehand even its startup mode is server instead of in-memory. That affects the overall performance, particularly when the file is relatively large.
Though packaged in an independent computing engine, HSQLDB is running on the database table rather than a true file computing engine. This explains its unreasonable designs, which include the lack of support for Excel files and common and unconventional text formats.
Essentially similar database products also include H2 Database and PostgreSQL. They have same pros and cons.
In summary, there aren’t true file computing engines in databases. We only find complicated installment, administration, allocation and execution procedures. Is there a desktop tool that has real file computing engine, user-friendly interface and that is simple to use? Yes, there is.
OpenOffice Base is impressively easy to use. Its one-click installation makes it ready-to-use without doing configurations and it has user-friendly interface that is smooth and quick to respond.
It also has a true file computing engine that enables direct processing of files without extra data loading and the need of database engine. It has three noticeable improvements – automatic data type identification, big data processing capability and high performance.
It still has problems.
First, OpenOffice Base doesn’t support the commonly-used Excel files but the text files only. That limits its application scenarios.
Second, it has very limited SQL capabilities. Many basic features are absent, like the join query:
select employee.name, sales.orderdate, sales.amount from sales left join employee on sales.sellerid= employee.eid
Third, it has too many limitations on text formats.
Except for the default format, it doesn’t support data types in any other formats, such as the date of a special format below:
orderid,client,sellerid,amount,orderdate
1,UJRNP,17,392.0,01-01-2012
2,SJCH,6,4802.0,31-01-2012
It doesn’t support special separators, for example:
orderid||client||sellerid||amount||orderdate
1||UJRNP||17||392.0||2012-01-01
2||SJCH||6||4802.0||2012-01-31
It cannot handle files of complex formats, for example:
producer: allen
date:2013-11-01 // The first two lines are useless
26 // A record consisting of multiple lines
TAS 1 2142.4
2009-08-05
33
DSGC 1 613.2
2009-08-14
If you make basic queries on text files of standard formats, OpenOffice Base is the first choice. But real-world businesses are not standardized textbook scenarios. Excel files are frequently encountered and there are various text formats and SQL algorithms. Is there a flexibly way to deal with the dynamic reality? Integration components of programming languages offer a relatively perfect solution.
A powerful tool produced by a trusted vendor, Microsoft text/xls driver is almighty. It supports well of SQL syntax. From fuzzy query, date function to subqueries and join queries, it almost covers all possible algorithms. To join two CSV files, for instance:
select client.clientname, sales.orderdate, sales.amount from [sales.csv] as sales left join [client.csv] as client on sales.clientid=client.clientid
The integration component support various file types, including TXT/CVS/TVS and all versions of XLS/XLSX. That’s really considerate.
It offers excellent support for common text formats, such as separator definition, columns name identification over first lines, fixed-width column configuration and automatic data type identification. For complex text formats, it allows handling them through coding. It is intended to enable programmers to read in texts of any formats and implement any algorithms in businesses.
Microsoft text/xls drive boasts a great file computing engine. The engine is almost complete in capabilities. The only thing is that it is designed for programmers, not data analysts.
The technical threshold of using it is high. You must be familiar with a programming language, C# or VB. And you need to master one of the three programming interfaces – ODBC, OLEDB and ADO.
You need to write a lot of difficult to understand code to execute, for example, the above SQL query. Below is a simplified version:
string path= string.Empty;
path="d:/data";
if (string.IsNullOrWhiteSpace(path)) return null;
string connstring = string.Empty;
connstring = "Provider=Microsoft.ACE.OLEDB.12.0;Data Source=" + path + ";Extended Properties='text;HDR=YES;FMT=Delimited';";
DataSet ds = null;
OleDbConnection conn = null;
try
{
conn = new OleDbConnection(connstring);
conn.Open();
OleDbDataAdapter myCommand = null;
myCommand = new OleDbDataAdapter(strSql, connstring);//<strong>Begin to</strong> <strong>execute SQL</strong>
ds = new DataSet();
myCommand.Fill(ds, "table1");
}
catch (Exception e)
{
throw e;
}
finally
{
conn.Close();
}
return ds;
It is also difficult to scale. The above code applies only to text files of the standard formats. To define string format or data type, you need the schema.in configuration file. To parse texts of complex formats, you need to write a lot of extra code.
Another problem is that text driver and xls driver are independent of each other though they are similar in uses. In other words, you can’t join a text file and an Excel file directly but you need to write a large amount of extra code.
CSVJDBC/ExcelJDBC and SpatiaLite are similar-type integration components with different language environments. Both are demanding, too. But they are not as good as Microsoft text/xls driver.
Microsoft text/xls driver has a complete but difficult to use file computing engine. OpenOffice Base is easy to use but hasn’t a powerful file computing engine. So, an ideal tool is one that has merits of both and also suitable for data analysts. I find only one eligible product yet.
esProc SPL is an opensource computing engine. Same as OpenOffice Base, esProc is also an easy-to-use desktop tool, one-click installation without further configurations. It’s easier to use as it allows users writing more than one SQL statement directly in cells and it presents computing result on the same interface. You can view the result by clicking the cell holding the SQL statement.
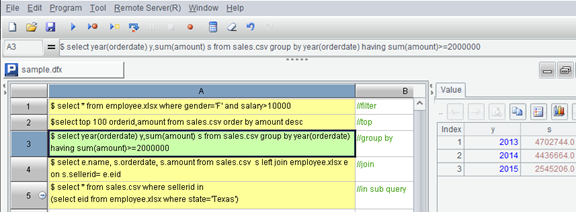
esProc SPL has a complete and powerful computing engine that supports all SQL syntax in real-world businesses (See the pic above). That make it best Microsoft text/xls driver.
esProc SPL also supports TXT/CVS/TVS and different versions of XLS/XLSX. It is more powerful because it can join a text file and an Excel file directly (See above pic).
Besides standardized file formats, SPL can handle more complex user needs through its extension functions. To parse a file containing separator "||", for instance, OpenOffice Base is helpless. Microsoft text/xls driver needs to write a large amount of code. SPL gets it done only using an extension function in the SQL query:
$select * from {file("sep.txt").import@t(;,"||")}
SPL can identify a data type automatically. To parse data of non-default format, the date mentioned in the above for instance, OpenOffice is incapable, Microsoft text/xls driver requires schema.ini plus extra code while SPL makes it seem like a piece of cake by using a simple extension function:
$select * from
{file("style.csv").import@ct(orderid,client,sellerid,amount,orderdate:date:"dd-MM-yyyy")}
To process a text file of complicated format, like one line corresponding to multiple records, OpenOffice is powerless, Microsoft text/xls driver needs a veteran programmer who writes a lot of complex code, while SPL manages it using only an extension function:
$select * from
{file("trip.csv").import@tc().news(trips.array(" ");name,state,~:trip)}
Those are my findings and here’s my conclusion. Most of SQL-on-file tools look good but lack substantial abilities. Only two stand out for their trusted capabilities. They are Microsoft text/xls driver and esProc SPL. The former is for programmers and the latter is a true friend of data analysts.