Why batch jobs are so difficult?
The detail data produced in the business system usually needs to be processed and calculated to our desired result according to a certain logic so as to support the business activities of enterprise. In general, such data processing will involves many tasks, and it needs to calculate in batches. In the bank and insurance industries, this process is often referred to as “batch job”, and batch jobs are often needed in other industries like oil and power.
Most business statistics require taking a certain day as termination day, and in order not to affect the normal business of the production system, batch jobs are generally executed at night, only then can the new detail data produced in production system that day be exported and transferred to a specialized database or data warehouse to perform operations of the batch jobs. The next morning, the result of batch job can be provided to business staff.
Unlike on-line query, batch job is an off-line task that is automatically carried out on a regular basis, and hence the situation that multiple users access one task at the same time will never occur, so there is no concurrency problem and no need to return the result in real time. However, the batch job must be accomplished within a specified time period. For example, the specified time period for batch job of a bank is from 8:00 pm the first day to 7:00 am the next day, if the batch job is not accomplished by 7:00 am, it will cause serious consequence that the business staff cannot work normally.
The data volume involved in a batch job is very large, and it is likely to use all historical data. Moreover, since the computing logic is complex and involves many computing steps, the time of batch jobs is often measured in hours. It is very common to take two or three hours for one batch job, and it is not surprising to take ten hours. As business grows, the data volume increases. The rapid increase of computational load on database that handles batch job will lead to a situation where the batch job cannot be accomplished after the whole night, and this will seriously affect the business, which is unacceptable.
To solve the prolonged time of batch job, we must carefully analyze the problem existed in the existing system architecture.
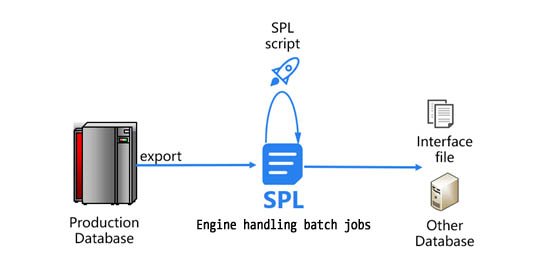
The relatively typical architecture of batch job system is roughly as follows:

As can be seen from the figure that the data needs to be exported from the production database and imported into the database handling batch jobs. The latter database is usually an RDB, you need to write stored procedure code to perform calculation of the batch jobs. The result of batch jobs will not be used directly in general, but will be exported from RDB to other systems in the form of intermediate files or imported into the database of other systems. This is a typical architecture, and the production database in the figure may be a centralized data warehouse or Hadoop, etc. Generally, the two databases in the figure are not the same database, and the data transferred between them is often in the form of file, which is conducive to reducing the degree of coupling. After the batch jobs are accomplished, the result is to be used in multiple applications, and transferred also in the form of file.
The first reason for slow batch jobs is that the data import/export speed of RDB for batch jobs is too slow. Due to closed storage and computing capacities of RDB, too many constraint verifications and security processing at data import/export are required. When the data volume is large, the data read/write efficiency will be very low, and it will take a very long time. Therefore, for the database that handles batch jobs, both the process of importing file data and the process of exporting calculation result as file will be very slow.
The second reason for slow batch jobs is that the performance of stored procedure is poor. Since the syntax system of SQL is too old, and there are many limitations, resulting in a failure in the implementation of many efficient algorithms, the computing performance of SQL statements in stored procedure is not unsatisfactory. Moreover, when the business logic is relatively complex, it is difficult to achieve within one SQL statement, and instead divide into multiple steps and use a dozen or even tens of SQL statements to implement. The intermediate result of each SQL statement needs to be stored as a temporary table for use in the SQL statements of subsequent steps. When the temporary table stores a large amount of data, the data must be stored, which will cause a large amount of data to be written. However, the performance of writing data is much worse than that of reading data, it will seriously slow down the entire stored procedure.
For more complex calculations, it is even difficult to implement directly in SQL statements. Instead, it needs to use a database cursor to traverse and fetch the data, and perform loop computing. However, the performance of database cursor traversal computing is much worse than that of SQL statements, and this method generally does not directly support the multi-thread parallel computing, and is difficult to use the computing capacity of multiple CPU cores, as a result, it will make computing performance become worse.
Then, how about using a distributed database (increase the number of nodes) to replace traditional RDB to speed up batch jobs?
No, we can't. The main reason is that the batch job logic is quite complex, and it often needs thousands or even tens of thousands of lines of code to achieve even using the stored procedures of traditional database, yet the computing capacity of stored procedures of distributed database is still relatively weak, making it difficult to implement such complex batch operations.
In addition, the distributed database also faces the problem of storing the intermediate result when a complex computing task has to be divided into multiple steps. Since the data may be stored on different nodes, it will result in heavy cross-network reads/writes whether storing intermediate result in previous steps or re-reading in subsequent steps, leading to uncontrollable performance.
In this case, using a distributed database to speed up query via data redundancy does not work as well. The reason is that although multiple copies of redundant data can be prepared in advance before querying, the intermediate results of batch job are generated temporarily, and it needs to temporarily generate multiple copies of data if the data are redundant, which will make overall performance become slower.
Therefore, the real-world batch job is usually executed within a large single database. When the computational intensity is too high, an all-in-one machine like ExaData will be used (ExaData is a multiple-database platform, and can be regarded as a super large single database as it is specially optimized in Oracle). Although this method is very slow, there is no better choice for the time being, and only such large databases have enough computing capacity for batch jobs.
SPL, an open-source professional computing engine, offers the computing capacity that does not depend on database, and directly uses the file system to compute, and can solve the problem of extremely slow data import and export of RDB. Moreover, SPL achieves more optimized algorithms, and far surpasses stored procedure in performance, and has the ability to significantly improve computing efficiency of one machine, which is very suitable for batch jobs.
The new architecture that uses SPL to implement batch jobs is shown as below:
In this new architecture, SPL solves two bottlenecks that cause slow batch jobs.
Let’s start with the first bottleneck, i.e., data import and export. SPL can perform calculation directly based on file exported from production database, and there is no need to import data into an RDB. Having finished batch jobs, SPL can directly store final result as general format such as text file and transfer it to other applications, avoiding the data export from original database that handles batch jobs. In this way, slow RDB read/write is omitted.
Now let's look at the second bottleneck, that is, the computing process. SPL provides better algorithms (many of which are pioneered in the industry), and the computing performance far outperforms that of stored procedure and SQL statement. SPL’s high-performance algorithms include:

These high-performance algorithms can be used for common calculations in batch job such as JOIN calculation, traversing, grouping and aggregating, which can effectively improve the computational speed. For example, the batch jobs often involve traversing the entire history table, and in some cases, a history table needs to be traversed many times so as to accomplish the calculations of multiple business logics. Generally, the data amount of history table is very large and each traversal will consume a lot of time. To solve this problem, we can use SPL’s multi-purpose traversal mechanism. This mechanism can accomplish multiple computations during one round of traverse on a large table, and can save a lot of time.
SPL’s multi-cursor can achieve parallel reading and computing of data. Even for complex batch job logic, the use of multiple CPU cores can implement multi-thread parallel computing. On the contrary, it is difficult for database cursor to process in parallel. Thus, the computing speed of SPL can often be several times faster than that of stored procedure.
The delayed cursor mechanism of SPL has the ability to define multiple computation steps on one cursor, and then let the data stream perform these steps in sequence to achieve chain calculation. This mechanism can effectively reduce the number of times of storing intermediate result. In situations where data must be stored, SPL can store intermediate result as its built-in high-performance format for use in the next step. SPL’s high-performance storage is based on file, and adopts many technologies such as ordered and compression storage, free columnar storage, double increment segmentation, self-owned compression code. As a result, the disk space occupation is reduced, and the read and write speed is much faster than database.
In this new architecture, SPL breaks RDB’s two bottlenecks for batch jobs, and obtains very good effect in practice. Let's take three cases to illustrate.
Case 1: Bank L adopts traditional architecture for its batch jobs, and takes RDB as the database handing batch jobs, and uses stored procedure to program to achieve batch job logic. It takes 2 hours to carry out the stored procedure of the batch job of loan agreements, yet this is merely a preparation job for many other batch jobs. Taking so long time seriously affects all batch jobs.
When using SPL, due to its high-performance algorithms and storage mechanisms such as the high-performance columnar storage, file cursor, multi-thread parallel processing, small result in-memory grouping, and multi-purpose cursor, the computing time is reduced from 2 hours to 10 minutes, the performance is improved by 12 times.
Moreover, SPL code is more concise. For the original stored procedure, there are more than 3300 lines of code, yet it only needs 500 cells of statements in SPL, reducing the code amount by more than 6 times and greatly improving development efficiency.
Visit: Open-source SPL speeds up batch operating of bank loan agreements by 10+ times for details.
Case 2: In the car insurance business of insurance company P, it needs to associate historical policies of previous years with new policies, which is called the historical policies association batch job. When RDB is used for this batch job, and using the stored procedure to associate historical policies with 10-day new policies, it will take 47 minutes, and take 112 minutes to associate 30-day new policies; if the time span increases, the computation time will be unbearably long, and it will basically become an impossible task.
When SPL is used for the calculation task, after exploiting SPL’s technologies such as high-performance file storage, file cursor, ordered merging & segmented data-fetching, in-memory association and multi-purpose traversal, it only takes 13 minutes to associate 10-day new policies, and takes 17 minutes to associate 30-day new policies, the speed is increased by nearly 7 times. Moreover, the computation time of new algorithms slightly increases as new policies grow, and does not increase in direct proportion to the number of days of new policies just like stored procedure.
Viewing from the total code volume, there are 2000 lines of code in original stored procedure, and are still more than 1800 lines after removing the comments. In contrast, SPL codes are less than 500 cells, which is less than 1/3 of original code volume.
For details, visit: Open-source SPL optimizes batch operating of insurance company from 2 hours to 17 minutes
Case 3: For the detail data of granted loans of Bank T through Internet, it requires running a batch job on a daily basis to count and aggregate all historical data as of a specified date. If this batch job is implemented in SQL statements of RDB, the total running time is 7.8 hours, which is too long, and even affects other batch jobs, and hence it is necessary to optimize.
When SPL is used, and after exploiting SPL’s technologies like the high-performance file, file cursor, ordered grouping, ordered association, delayed cursor and binary search, the running time can be reduced from 7.8 hours to 180 seconds in the case of single thread, and to 137 seconds in 2-thread, the speed is increased by 204 times.